







X-Mdeusa 参数分析
抖音25.0.0六神参数X-Medusa算法还原。首先使用unidbg完成对六神参数的模拟,后面的分析全部基于unidbg模拟执行。
详细分析过程
通过unidbg生成一份指令trace日志,所有分析都是为了还原日志中的结果。下面是需要还原的结果:
| 1 |
|
从最后的结果可以看出是一个base64字符串,利用ida插件获取到base64相关函数,然后使用unidbg断点hook base64输入数据和base64结果来判定是否是标准的base64算法。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|

利用上面hook结果验证base64是标准的,并且得到了base64之前medusa结果存储的内存地址,方便后面traceWrite分析。将medusa解base64的到如下字节:
| 1 |
|
接下来则需要分析上面字节的来源,通过之前的线索直接traceWrite内存区域得到如下结果:


从上图中可以看出trace内存指示的位置和LR都不是直接写内存的地方,之前没遇到过这种情况,不知道这里是unidbg的缺陷还是app的什么策略,不过问题不大,既然trace不到具体的写内存过程,那就写hook函数时刻判断内存找到内存变化的瞬间,然后利用unidbg单步调试,数据绝对不会凭空出现在内存里。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|


trace之后确认不是unidbg的问题,traceWrite结果是准确的,并且从上面的trace结果可以可以看出从pc地址有个变化,接着内存数据就发生了变化,在trace 日志中也能找到证明,接下来则是想办法让unidbg在这里断下

很简单保持前面的代码不动,计数调用次数断下即可:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
断下之后开始单步调试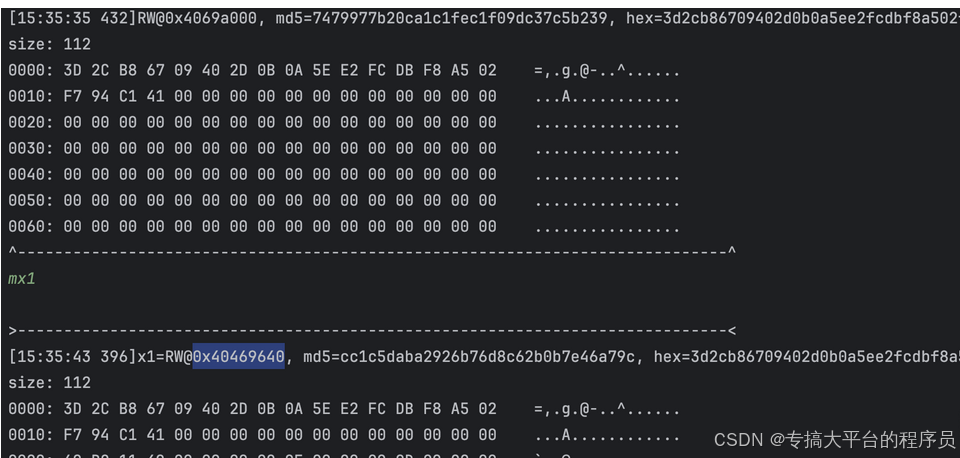
从上图中可以看出先拷贝进去了20字节并且来源的地址也都知道了,其实将之前的trace长度更改到全长326 或者是大于22字节也同样能看出medusa base64输入参数的分布。medusa base64输入是三部分拷贝进来的,第一部分是20字节,第二部分是2字节,第三部分则是剩下的所有。 具体分析方式也是重复上面的步骤而已。
| 1 2 3 4 5 |
|
将上面的部分按照前面分析完成分割,接下来先追主体数据来源,将之前的trace中内存首字节变化程序退出的语句注释掉,并将前面count == 159 的条件更改为count >= 159 那么接下来的第三个X1对应的地址就是主体部分的来源0x40695280。接下来开始分析此处内存数据的来源, 还是traceWrite得到如下结果: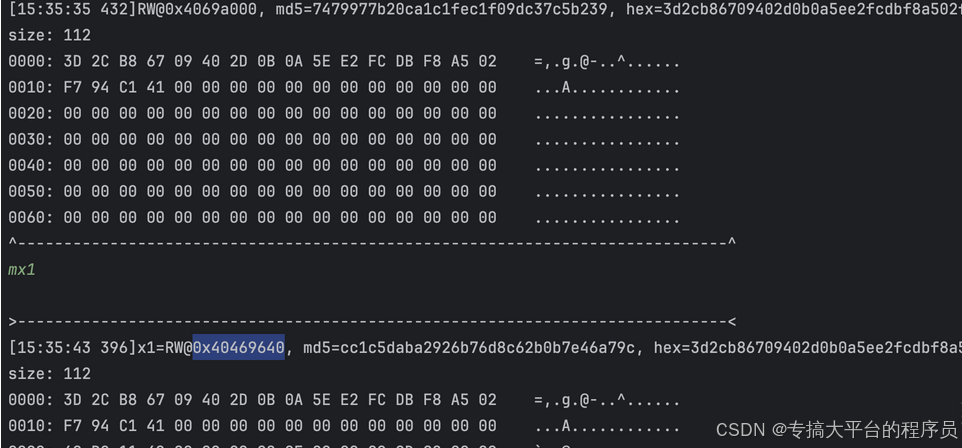
对应的是libc中的函数,通过LR地址发现是memcpy系统调用,这里直接偷懒到日志文件中搜索,如果有足够耐心前面也可以不调试,单个字节在trace日志里搜索。这里直接搜索对应内存地址: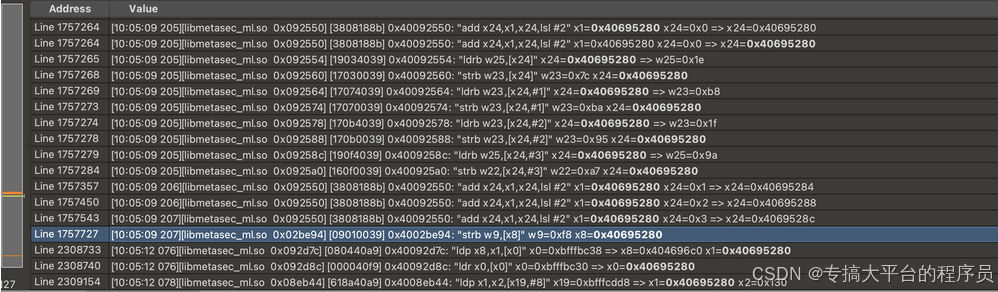
从上面可以看出只有127个结果,倒着看在上图位置发现首字节,搜索那句pc值: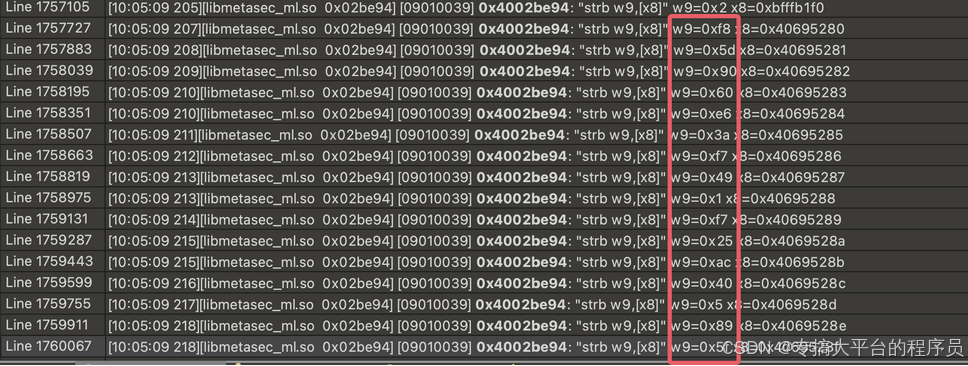
查看这句附近的汇编指令能发现下面规律: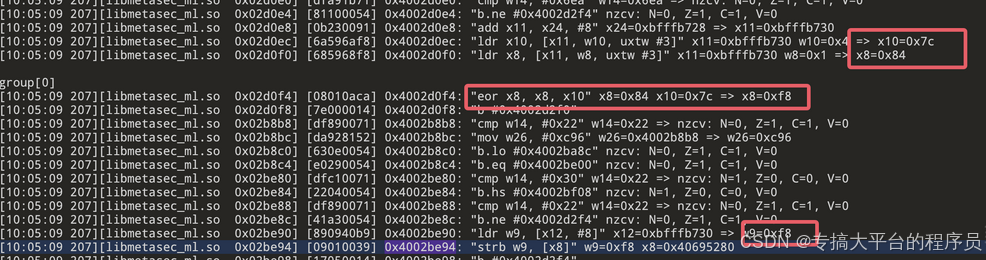
第三部分的数据是通过异或得到的:
将搜索结果拿出来部分进行分析
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
|
从上面可以看出呈现出一定的规律,都是同一个16字节数组异或后得到最后结果,先分析每组变化的字节来源。直接在附近搜索0x7c: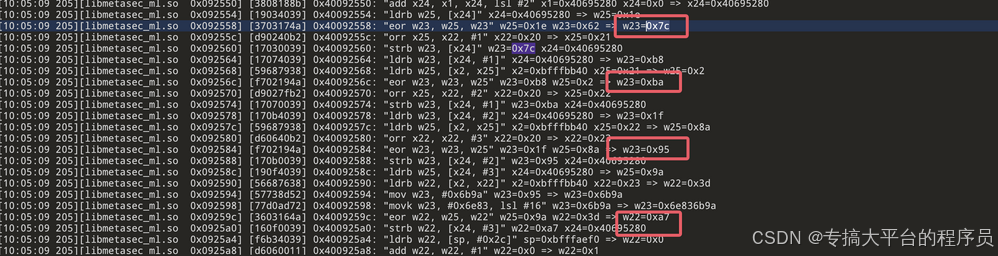
在临近位置发现上图所示的计算过程,继续向下翻能发现会出现和上图所示差不多的模式,都是每四个字节一组的计算,这里可能是有个循环或是是什么规律,根据之前traceWrite第三部分地址得到的数据往前一层开始大致确定带有上面模式的开始,然后拿出来单独分析。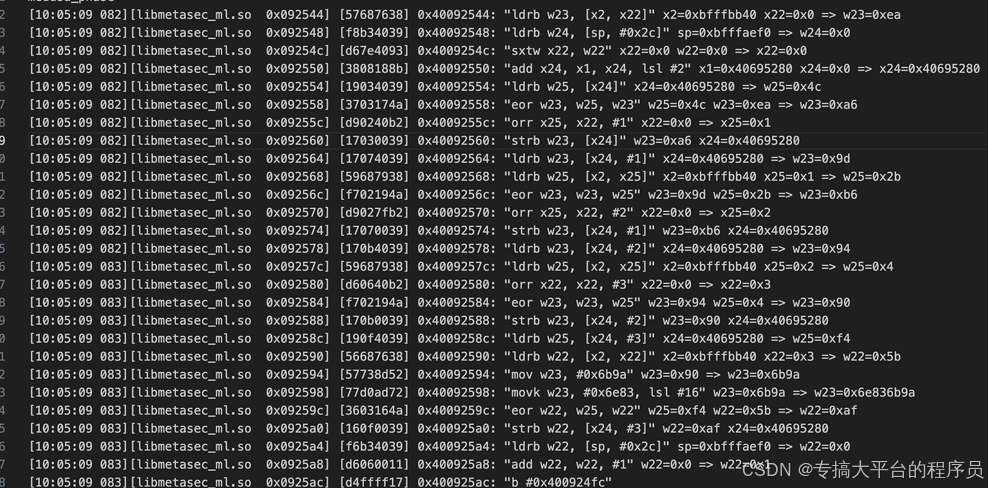
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
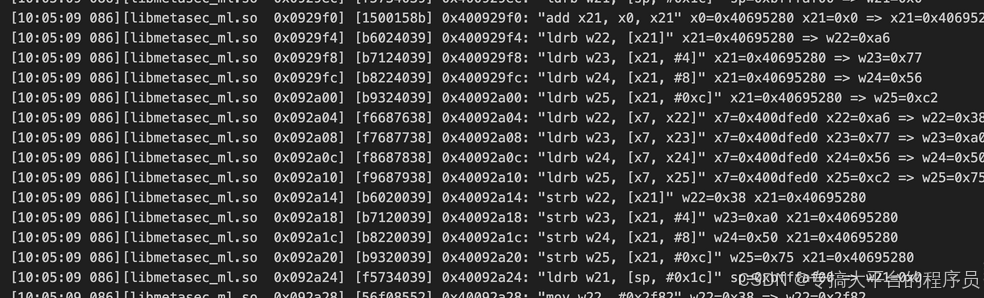

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
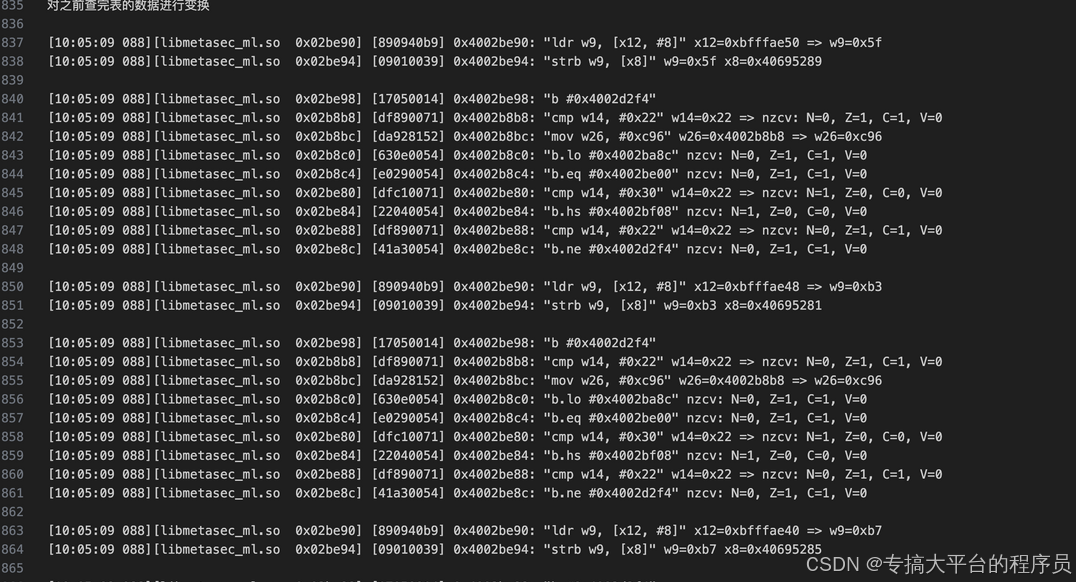
| 1 2 3 4 5 6 7 8 9 10 11 |
|
通过上面的日志分析,这部分已经看着非常像是的aes了,但是字节代换部分表是固定的,更可能是个aes算法的变种魔改。如果是aes的魔改那么行变换之后就是列混淆部分了。下面部分日志通过脚本筛选出读取内存和一些数学运算: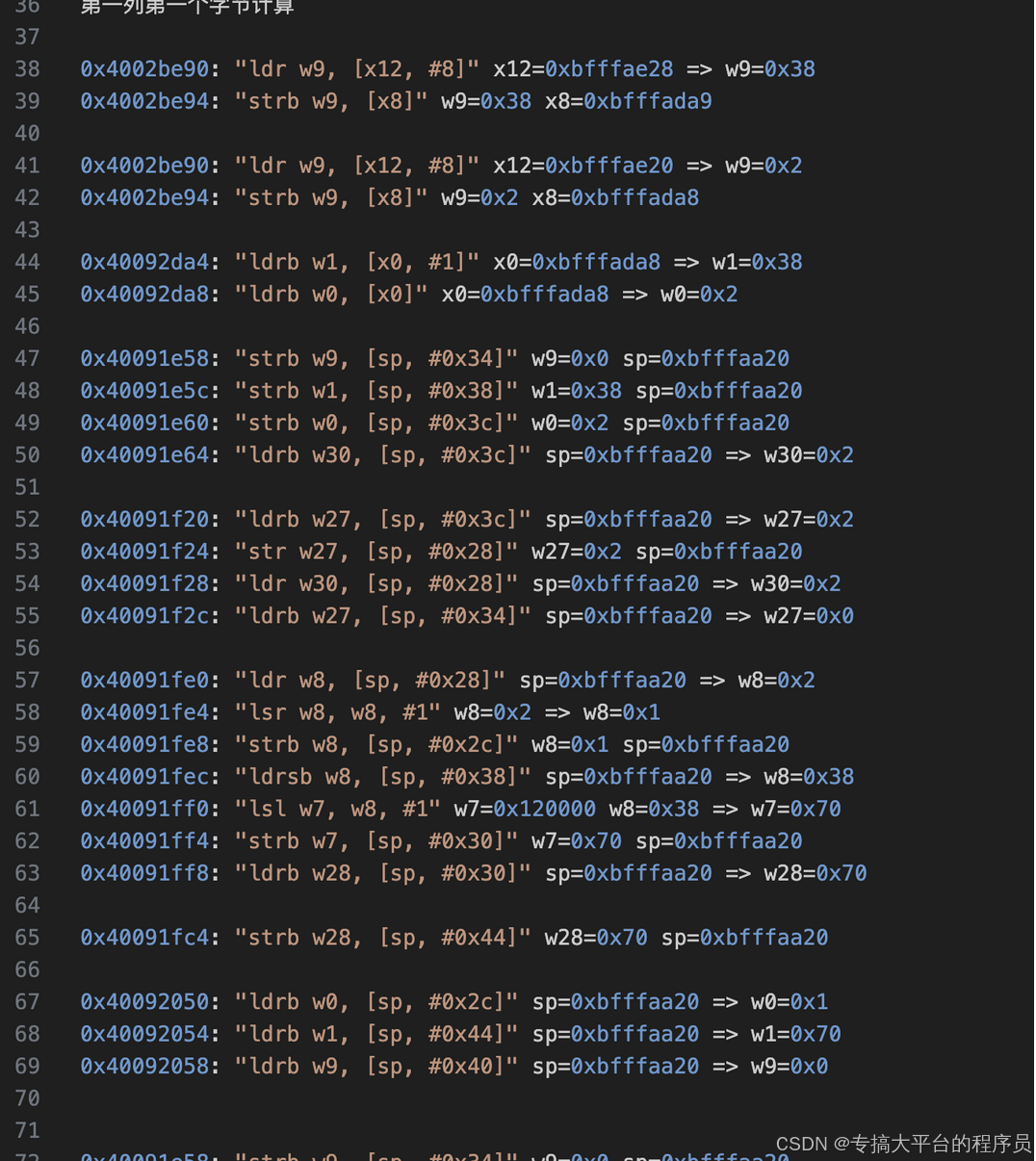
上面只是部分被筛选出来的日志,选择其中一部分进行分析:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
根据上面的计算分析,多分析几组日志中的数据就更能确定是aes中列混淆的计算了。直接上网或者是利用大模型搞个列混淆代码,连着之前的逻辑一起写个python代码测试:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
|
验证之后更加确定是aes魔改的算法了,后面的日志都可以带入aes计算逻辑了,而且发现只是计算的轮数被减少了,只保留了3轮计算,并且加密使用的密钥和iv是固定的,并且是固定字节的md5的结果这里和X-Argus AES部分类似,而且和海外版也保持一致所以还原算法时,轮钥和初始化向量可以固定。下面给出随手还原验证代码, 是分析过程脚本,部分注释不准确:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 |
|
到此关于aes部分相关还原完成,接下来则是继续向上看,aes相关输入数据来源,并且这部分也能从前面的traceWrite中看出蛛丝马迹。下面是整理出来的需要继续追踪的数据:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
从上面的数据,可以继续使用前面介绍的利用unidbg调试和定位内存变换定位,也可以直接去trace日志中搜索字节找线索,也可以利用经验从末尾开始看起,除去填充字节0c和忽略末尾两个字节,尾部 fd 77 e6 ff fd 77 e6 ff 这几个字节实在是太有规律了。同时这里的数据在本文中也只分析主体部分。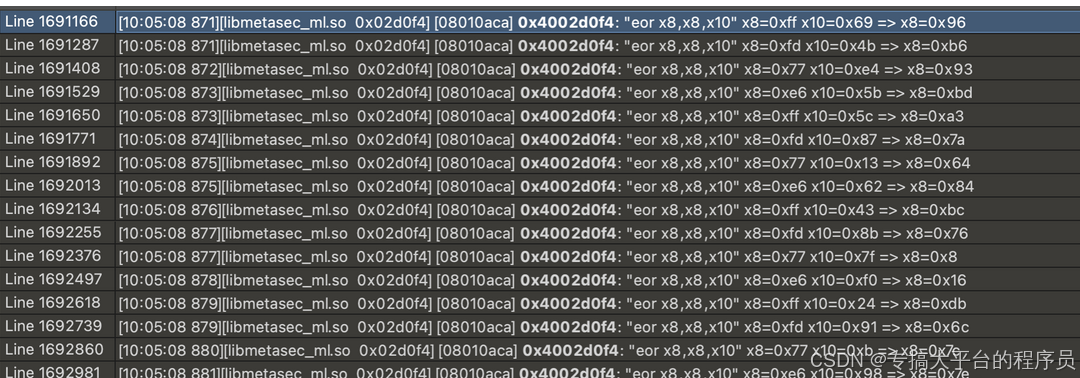
从上图可以看出这部分的计算规律了,接着是这四字节简单计算分析如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
上面对四字节生成日志做了初步的分析,接下来则是查找异或之前的数据来源,还是重复的trace内存定位重复操作。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
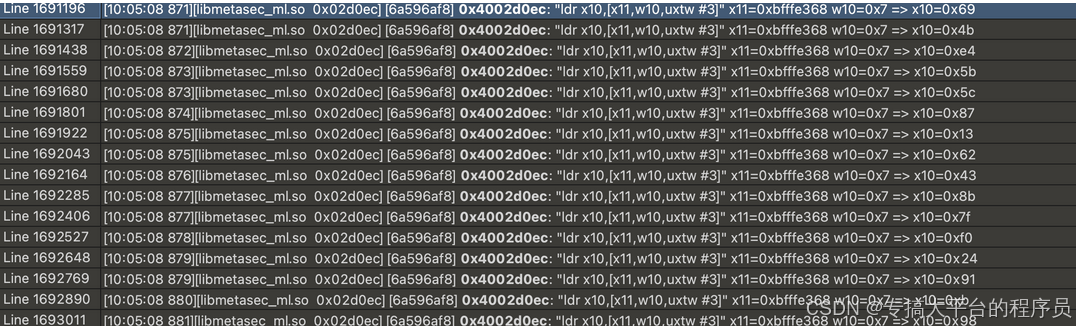
当然这还不是最初生成的位置,继续查找: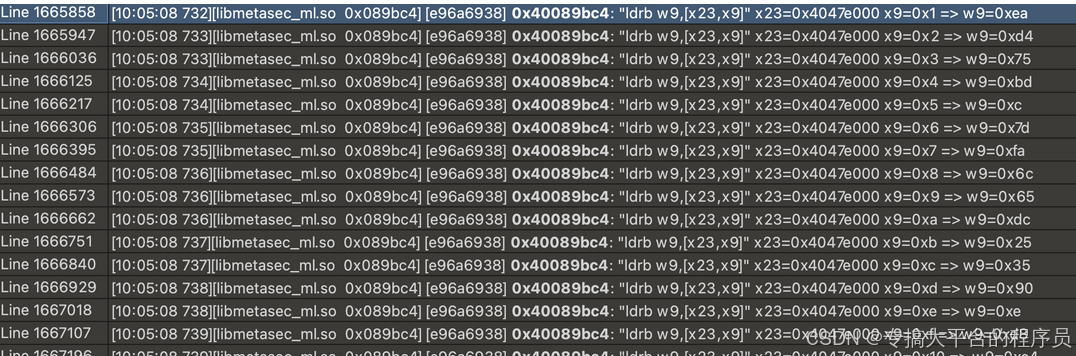
发现是逆序的,并且相关计算都是在函数0x89824 中完成,这里是处理最初输入数据的函数,并且混淆也不是很严重只需要照着静态代码还原即可。
通过调试获取输入数据是protobuf
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
到这里X-Medusa算法的主体部分就都完成了,下面给出简单的整体粗略验证代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 |
|
部分补充
base64输入参数中的第一部分是一个时间戳也是X-Khronos与protobuf编号1对应字节的异或: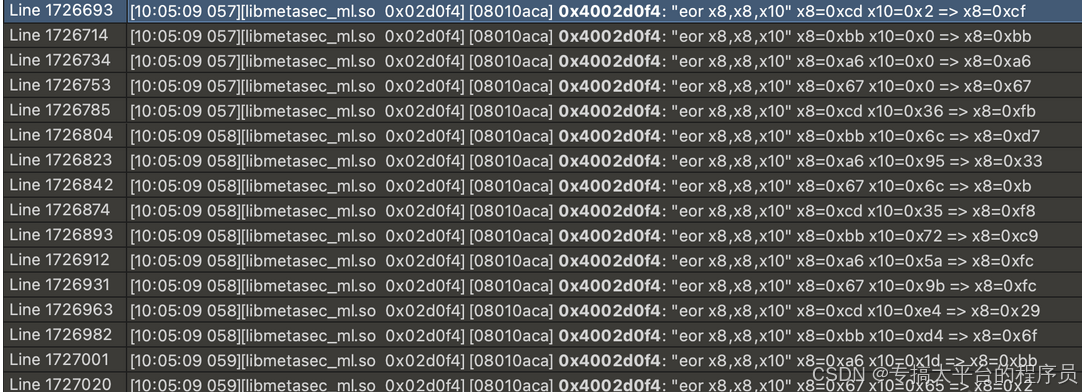
中间的两个字节留意出现的随机字节。
总结
- 上面只记录了主体加密部分,部分细节缺失,但是不需要那么高还原度也可以通过接口校验。
- 除了部分魔改之后,大部分算法细节和X-Argus流程几乎一致,protobuf输入数据都打部分相似。
- 使用unidbg0.9.8发现调用过程中总是缺失部分关键信息,但是由于之前分析过太多次了,就没有详细分析原因。
- 本文只是粗略的分析练手学习,部分算法细节也不够精确。

















 4058
4058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









