







精准圈层式营销的本质是通过大数据技术将消费者划分为具有共同特征的群体(圈层),并针对性地设计营销策略,从而解决信息过载时代"群体性懒"导致的决策效率低下问题。这种营销模式以数据驱动的精准触达和圈层传播效率为核心,具体可从以下角度解读:
- 数据驱动的群体细分机制
大数据通过抓取用户兴趣标签(如社交媒体行为、消费记录、地理位置等),结合聚类算法实现圈层划分。例如,秒针系统基于社媒兴趣圈层+广告互动数据构建人群包,实现"可规模化的精准"。这种细分突破了传统人口统计学分类的局限,使圈层划分维度从静态属性升级为动态行为图谱。
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 假设有一个包含用户兴趣标签的DataFrame
data = {
'user_id': [1, 2, 3, 4, 5],
'social_media_activity': [5, 3, 4, 2, 1],
'purchase_history': [100, 200, 150, 50, 300],
'location': [1, 2, 1, 3, 2]
}
df = pd.DataFrame(data)
# 选择用于聚类的特征
features = ['social_media_activity', 'purchase_history', 'location']
X = df[features]
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 使用KMeans进行聚类
kmeans = KMeans(n_clusters=3, random_state=42)
df['cluster'] = kmeans.fit_predict(X_scaled)
# 输出聚类结果
print(df)
- 群体认知惰性的破解逻辑
圈层营销利用KOL/KOC作为传播节点,通过"社交货币"和情感共鸣机制,将产品信息转化为圈层内部的共识性认知。消费者无需主动筛选信息,圈层内部的强关系传播天然具备信任背书,这正是对"群体性懒"的针对性解决方案。如房地产行业通过业主圈层实现口碑裂变,降低新客户的决策成本。
class Consumer:
def __init__(self, name, is_kol=False):
self.name = name
self.is_kol = is_kol
self.trusted_by = []
def receive_info(self, info):
if self.is_kol:
print(f"{
self.name} (KOL) 接收到信息: {
info}")
self.spread_info(info)
else:
print(f"{
self.name} 接收到信息: {
info}")
def spread_info(self, info):
for consumer in self.trusted_by:
consumer.receive_info(info)
def add_trusted_consumer(self, consumer):
self.trusted_by.append(consumer)
# 创建消费者和KOL
consumer1 = Consumer("消费者1")
consumer2 = Consumer("消费者2")
kol = Consumer("KOL1", is_kol=True)
# 建立信任关系
consumer1.add_trusted_consumer(kol)
consumer2.add_trusted_consumer(kol)
# KOL传播信息
kol.receive_info("新产品发布,限时优惠!")
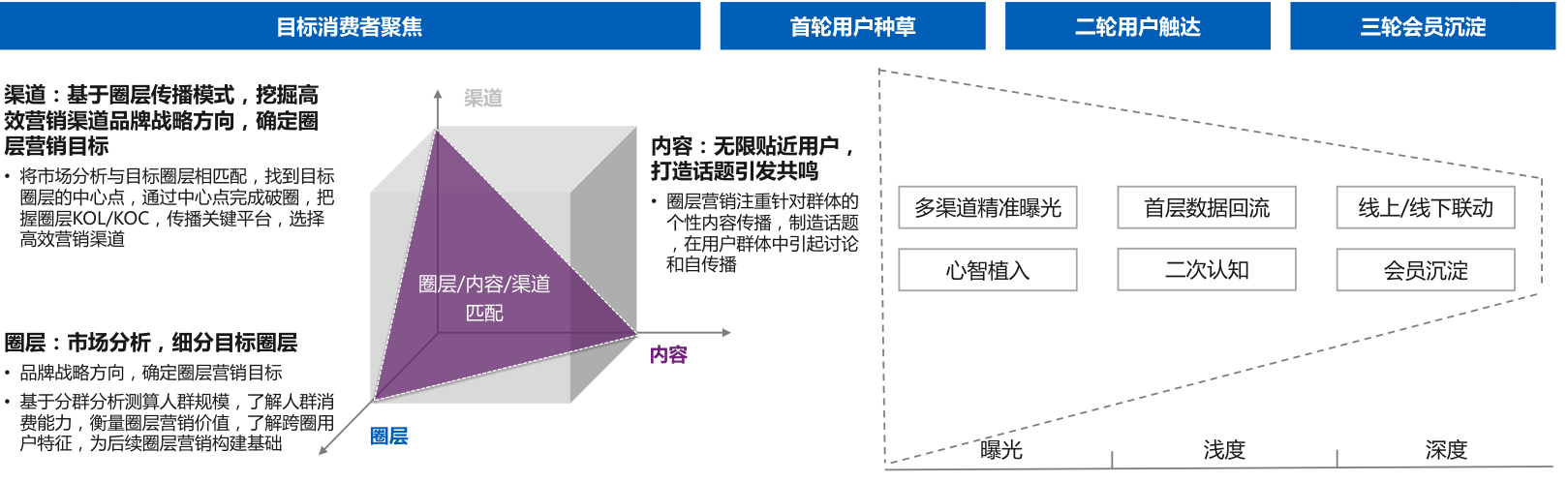
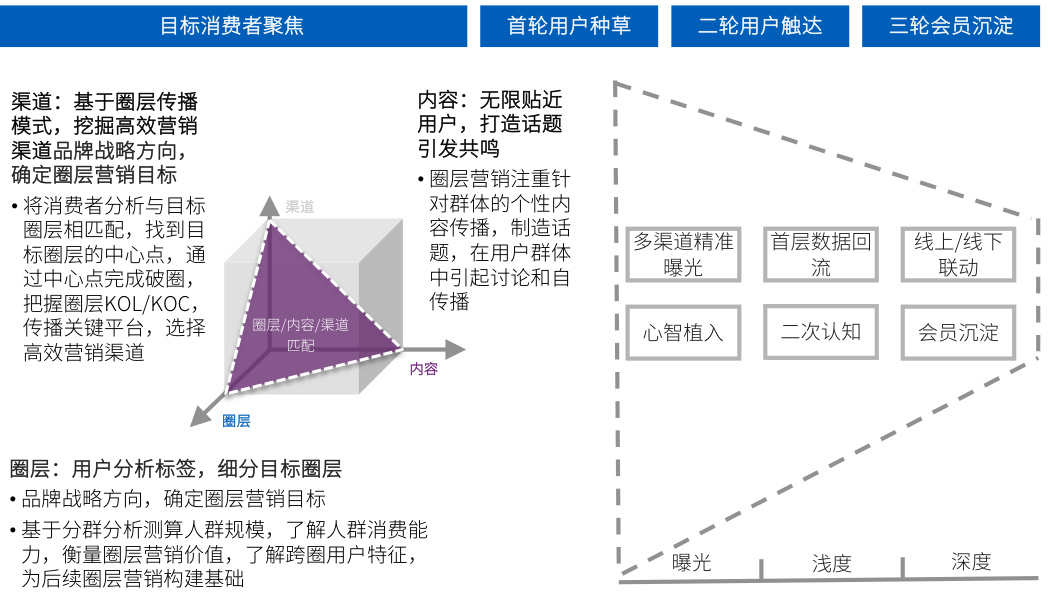
3. 传播路径的精准预判
传统精准营销往往只实现"人群"和"目的"精准,而圈层营销通过大数据分析圈层浓度TGI、内容偏好和关键传播平台,可预判最高效的传播路径。例如针对Z世代不同兴趣圈层(如电竞、二次元),定制差异化内容并通过B站、TapTap等垂直平台精准投放。
- 动态优化的闭环系统
基于实时数据回流,圈层营销形成"定位-触达-沉淀-破圈"的动态循环。每季度进行分层模型审计,通过策略疲劳指数监测效果衰减。这种机制确保营销策略始终与圈层演变同步,避免静态分群导致的失效。
以下是一个基于 Python 的代码示例,用于实现基于实时数据回流的圈层营销动态循环,并每季度进行分层模型审计和策略疲劳指数监测。
import pandas as pd
from sklearn.cluster import KMeans
from datetime import datetime, timedelta
# 模拟实时数据回流
def fetch_real_time_data():
# 这里可以替换为实际的数据获取逻辑
data = pd.DataFrame({
'user_id': range(1000),
'feature1': np.random.rand(1000),
'feature2': np.random.rand(1000)
})
return data
# 圈层定位
def cluster_users(data):
kmeans = KMeans(n_clusters=5)
data['cluster'] = kmeans.fit_predict(data[['feature1', 'feature2']])
return data
# 触达策略
def reach_out_strategy(data):
# 这里可以替换为实际的触达策略逻辑
for cluster in data['cluster'].unique():
print(f"触达圈层 {
cluster} 的用户")
return data
# 沉淀用户行为
def user_behavior_analysis(data):
# 这里可以替换为实际的用户行为分析逻辑
data['behavior_score'] = np.random.rand(len(data))
return data
# 破圈策略
def break_circle_strategy(data):
# 这里可以替换为实际的破圈策略逻辑
for cluster in data['cluster'].unique():
print(f"破圈策略应用于圈层 {
cluster}")
return data
# 分层模型审计
def model_audit(data):
# 这里可以替换为实际的模型审计逻辑
print("进行分层模型审计")
return data
# 策略疲劳指数监测
def fatigue_index_monitoring(data):
# 这里可以替换为实际的疲劳指数监测逻辑
print("监测策略疲劳指数")
return data
# 主循环
def main():
while True:
data = fetch_real_time_data()
data = cluster_users(data)
data = reach_out_strategy(data)
data = user_behavior_analysis(data)
data = break_circle_strategy(data)
# 每季度进行分层模型审计和策略疲劳指数监测
if datetime.no 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











