






Web应用防火墙(Web Application Firewall,简称WAF)日志是记录和分析网络流量及安全事件的重要工具,对于识别潜在威胁、进行安全审计和确保合规性至关重要。然而,当WAF日志容量达到上限时,会导致日志数据无法记录,进而影响到安全监控和事件响应的能力。本文将为您介绍日志容量达到上限后的常用解决方法。
背景信息
WAF日志记录了对Web应用的所有访问请求及防火墙的响应情况。这些日志包含了攻击检测、过滤、阻断等详细信息,充足的日志容量可以确保所有安全事件被完整记录,帮助管理员进行详细分析和审计。如果日志容量达到上限,可能会产生以下影响:
-
日志丢失
当日志使用量达到日志存储总量上限后,新的日志数据将无法记录,导致重要的安全事件信息丢失。
-
安全威胁无法及时检测
无法记录新日志,如果您有其他安全分析类的服务依赖WAF日志,则可能会使得潜在的安全威胁无法被及时检测和响应,增加了安全风险。
-
合规性问题
某些行业和法规要求企业保留日志数据以供审计,日志使用量达到日志存储总量上限后无法记录新的日志,可能导致合规性问题。
日志容量达到上限如何处理
WAF日志容量达到上限后,通常采用以下四种方法进行处理:
-
升级日志存储容量
升级日志存储容量是最直接的解决方案。通过配置更大的存储空间可以确保WAF有足够的容量来记录所有的安全事件和网络流量数据。具体操作请参见升级日志存储空间
-
细粒度配置减少存储空间使用量
通过针对不同业务的重要性,精细化地配置日志记录策略。例如对于非重要业务,仅记录攻击日志和必选字段,或者少量可选字段降低存储空间占用量。具体操作请参见细粒度配置减少存储空间使用量
-
减少日志存储时长
优化日志存储时长也是一种有效的方法。根据业务需求,缩短日志保留的时间,可以减少存储空间的占用。例如,将日志保留期限从原来的30天缩短为7天,能够在不丢失关键数据的前提下,节省大量的存储空间。具体操作请参见减少日志存储时长
-
减少日志索引字段
关闭“索引自动更新”功能,并删除部分不需要的字段索引,可以显著减少索引空间的占用。索引虽然有助于快速查询和分析日志,但也会消耗大量的存储空间。通过优化索引配置,可以在保证查询效率的同时,减少存储空间的使用。具体操作请参见减少日志索引字段
升级日志存储空间
重要
仅针对包年包月高级版、企业版、旗舰版的实例,支持查看和升级日志存储容量。按量付费实例按实际用量结算费用,并由日志服务统一出账,因此没有容量限制,无需单独设置日志容量。
-
登录Web应用防火墙3.0控制台,在左侧导航栏,选择检测与响应 > 日志服务,单击右上角的升级容量。

-
选择更大的日志存储容量规格,并完成购买。
细粒度配置减少存储空间使用量
日志投递字段设置允许对单个防护对象进行精细化字段配置和日志存储类型设置,如果针对某个防护对象进行了特定的字段和日志存储类型配置,设置后的字段优先级高于默认字段设置。
-
登录Web应用防火墙3.0控制台,在左侧导航栏,选择检测与响应 > 日志服务,单击右上角的日志设置 > 投递设置。
-
在投递设置页签中,单击目标防护对象的SLS投递字段列的字段配置,完成如下表所示的配置操作。
配置项
配置说明
必选字段
必选字段表示WAF日志中一定包含的字段,目前不支持您对必选字段进行编辑,字段详情请参见必选日志字段说明。
可选字段
可选字段表示您可以手动选择是否在WAF日志中包含这些字段。WAF日志只会记录您已启用的可选字段,字段详情请参见可选日志字段说明。
说明
启用更多可选字段将会增加WAF日志的存储容量使用。如果您有足够的日志存储容量,建议启用更多可选字段以便更全面地进行日志分析。
存储类型
存储类型配置支持您根据您购买的日志存储容量,选择不同的日志存储选项:全量日志、拦截日志、拦截与观察日志。选择合适的存储类型有助于平衡安全监控与日志存储成本。
-
全量日志:记录所有请求,包括正常请求、可疑请求及被拦截的攻击请求。适用于需要全面审计和深入分析的场景。
-
拦截日志:仅记录被WAF拦截的攻击请求。适合关注安全事件并希望减少非关键日志存储资源消耗的用户。
-
拦截与观察日志:记录被WAF标记为可疑的请求和被拦截的攻击请求。适用于希望监测潜在威胁的同时控制日志存储使用量的用户。
对于非重要业务,您只需记录攻击日志和必选字段,或少量可选字段,以降低存储空间占用。在完成日志投递字段的配置后,单击确定并看到操作成功提示后,代表当前配置已对单个防护对象生效。
-
减少日志存储时长
-
登录Web应用防火墙3.0控制台,在左侧导航栏,选择检测与响应 > 日志服务,单击右上角的存储时长设置,此时进入日志服务控制台。

-
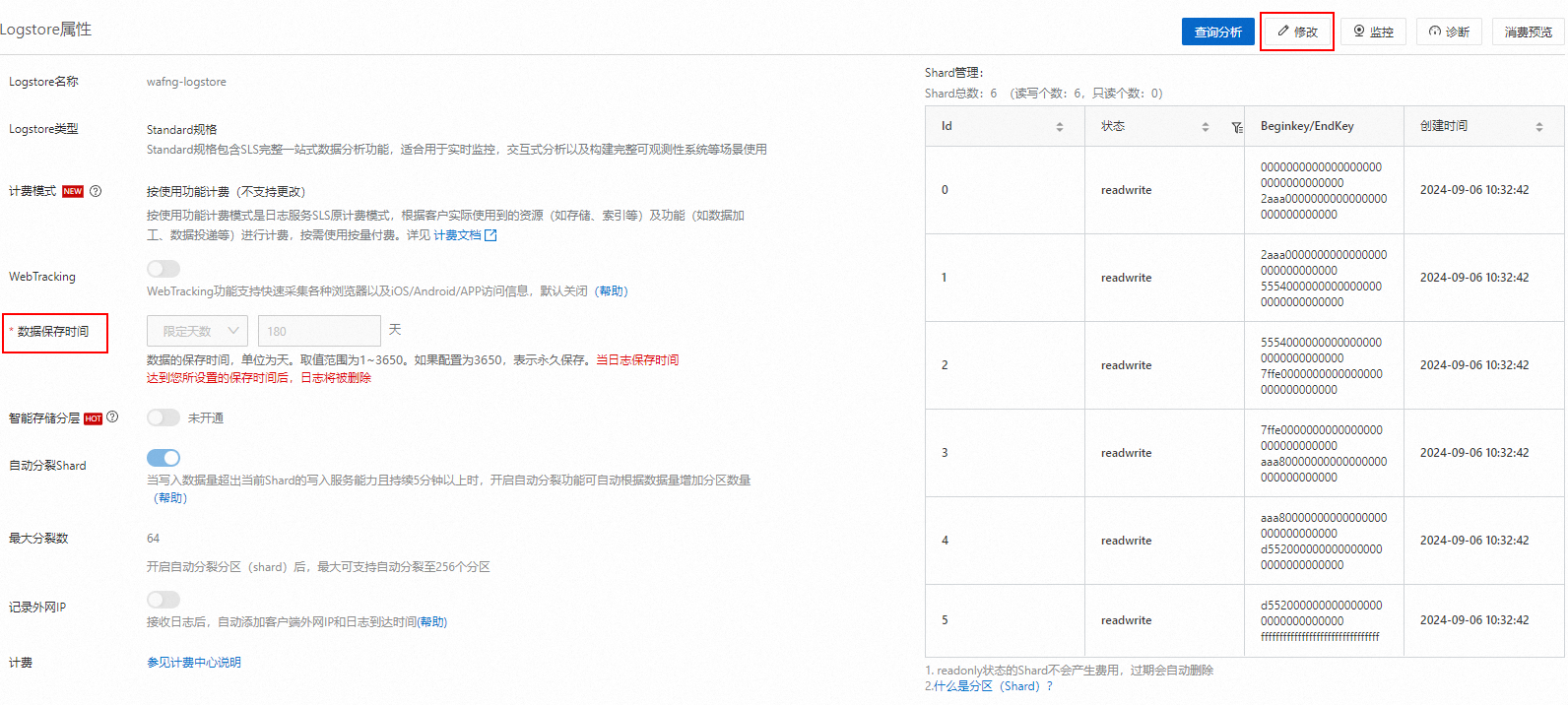
在Logstore属性面板中单击右上角的修改,减少数据保存时间后,单击保存。
重要
-
在调整日志保存时间时,务必确保符合相关法规和合规性要求,以避免因数据保留不足而导致的合规性问题。
-
当日志保存时间达到您所设置的限定天数时后,超期的日志将会自动删除。
-
减少日志索引字段
-
登录日志服务控制台,在Project列表区域,单击以
wafng开头的目标Project。
-
在左侧导航栏,单击日志存储

,在日志库列表中单击目标Logstore。

-
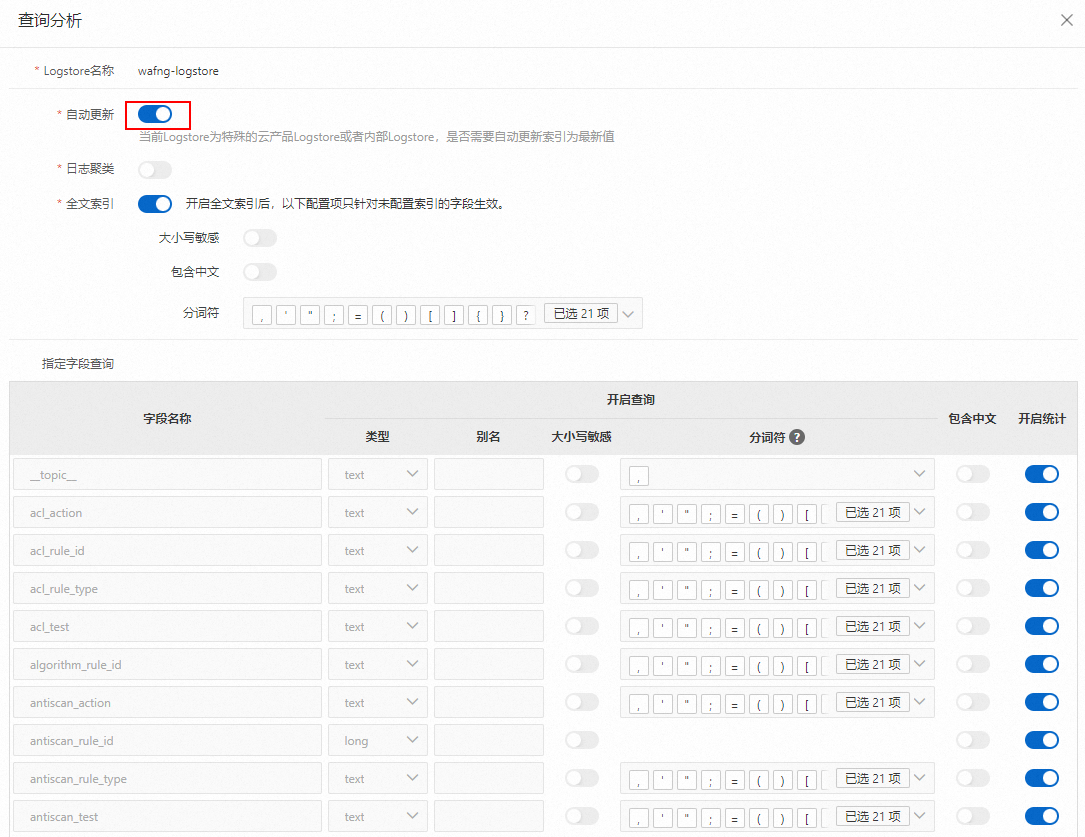
在Logstore的查询和分析页面,选择查询分析属性 > 属性。

-
关闭自动更新索引。当前Logstore为特殊的云产品Logstore或者内部Logstore时,默认打开索引自动更新开关,此时指定字段查询区域为不可操作状态,在查询分析面板中,关闭自动更新开关。
警告
如果您在SLS配置了自定义报表和告警功能,删除WAF产品专属Logstore的索引,可能会影响自定义报表和告警功能,请谨慎操作
-
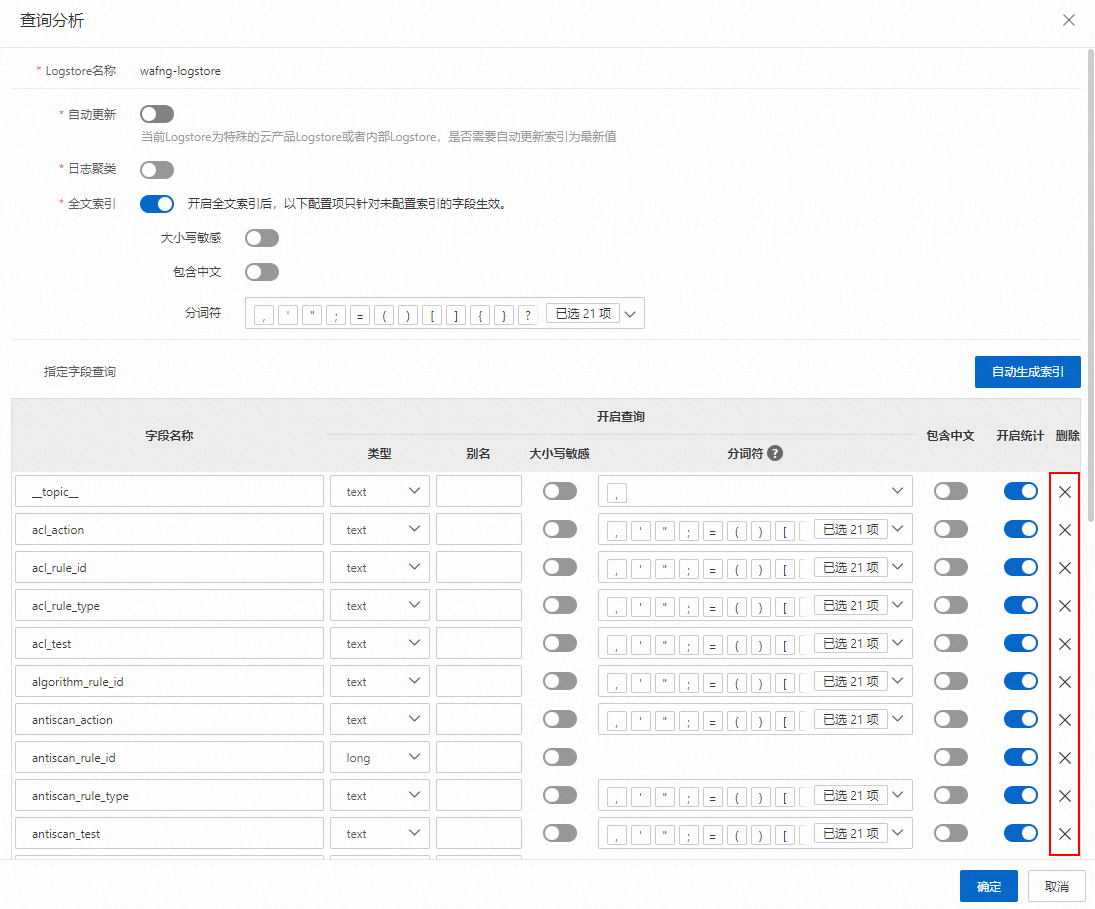
删除索引。关闭自动更新开关后,您可以在指定字段查询区域删除不需要的字段索引,删除索引后单击确认。

















 6359
6359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









