







数据库设计理论及应用(
5
)——逻辑结构设计
作者:最后一只恐龙 发表时间:2007-6-27
该系列计划包括5部分:完整性约束理论及应用、范式理论及应用、需求分析、概念结构设计、逻辑结构设计。本文是第五部分,介绍逻辑结构设计的内容,包括E-R图向关系模型的转换、数据模型的优化、用户子模式的设计等问题。
1.逻辑设计概述
概念结构是独立于任何一种数据模型的,在实际应用中,一般所用的数据库环境已经给定(如SQL Server或Oracel或MySql),本文讨论从概念结构向逻辑结构的转换问题。
由于目前使用的数据库基本上都是关系数据库,因此首先需要将E-R图转换为关系模型,然后根据具体DBMS的特点和限制转换为特定的DBMS支持下的数据模型,最后进行优化。
2.E-R图向关系模型的转换
2.1 一个例子
E-R图如何转换为关系模型呢?我们先看一个例子。
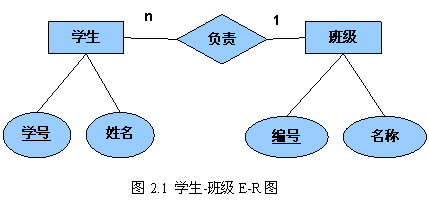
图2.1是学生和班级的E-R图,学生与班级构成多对一的联系。根据实际应用,我们可以做出这个简单例子的关系模式:
学生(学号,姓名,班级)
班级(编号,名称)
“学生.班级”为外键,参照“班级.编号”取值。
这个例子我们是凭经验转换的,那么里面有什么规律呢?在2.2节,我们将这些经验总结成一些规则,以供转换使用。
2.2 转换规则
(1)
一个实体型转换为一个关系模式
一般E-R图中的一个实体转换为一个关系模式,实体的属性就是关系的属性,实体的码就是关系的码。
(2)
一个1:1
联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。

图2.2是一个一对一联系的例子。根据规则(2),有三种转换方式。
(i) 联系单独作为一个关系模式
此时联系本身的属性,以及与该联系相连的实体的码均作为关系的属性,可以选择与该联系相连的任一实体的码属性作为该关系的码。结果如下:
职工(
工号,姓名)
产品(
产品号,产品名)
负责(
工号,产品号)
其中“负责”这个关系的码可以是工号,也可以是产品号。
(ii) 与职工端合并
职工(
工号,姓名,产品号)
产品(
产品号,产品名)
其中“职工.产品号”为外码。
(iii) 与产品端合并
职工(
工号,姓名)
产品(
产品号,产品名,负责人工号)
其中“产品.负责人工号”为外码。
(3)
一个1:n
联系可以转换为一个独立的关系模式,也可以与n
端对应的关系模式合并。
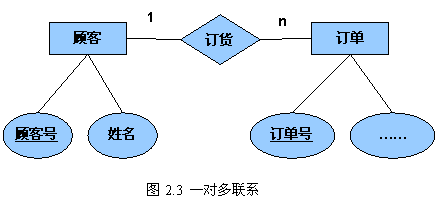
(i) 若单独作为一个关系模式
此时该单独的关系模式的属性包括其自身的属性,以及与该联系相连的实体的码。该关系的码为n端实体的主属性。
顾客(
顾客号,姓名)
订单(
订单号,……)
订货(顾客号,
订单号)
(ii) 与n端合并
顾客(
顾客号,姓名)
订单(
订单号,……,顾客号)
(4)
一个m:n
联系可以转换为一个独立的关系模式。
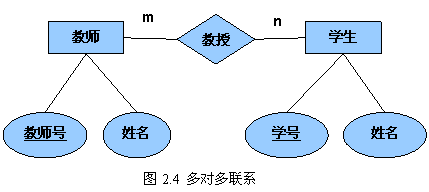
该关系的属性包括联系自身的属性,以及与联系相连的实体的属性。各实体的码组成关系码或关系码的一部分。
教师(
教师号,姓名)
学生(
学号,姓名)
教授(
教师号,
学号)
(5)
一个多元联系可以转换为一个独立的关系模式。
与该多元联系相连的各实体的码,以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分。
(6)
具有相同码的关系模式可以合并。
(7)
有些1
:n
的联系,将属性合并到n
端后,该属性也作为主码的一部分
这类问题多出现在聚集类的联系中,且部分实体的码只能在某一个整体中作为码,而在全部整体中不能作为码的情况下才出现(其它情况本人还没碰到,呵呵,欢迎指教)。
比如上篇文章介绍的管理信息系统中订单与订单细节的联系。
关于什么是聚集,2.3节介绍。
2.3 数据抽象的分类
这部分本应在概念设计中介绍的,用到了才想起来,这里补充一下。
关于现实世界的抽象,一般分为三类:
(1) 分类:即对象值与型之间的联系,可以用“is member of”判定。如张英、王平都是学生,他们与“学生”之间构成分类关系。
(2) 聚集:定义某一类型的组成成分,是“is part of”的联系。如学生与学号、姓名等属性的联系。
(3) 概括:定义类型间的一种子集联系,是“is subset of”的联系。如研究生和本科生都是学生,而且都是集合,因此它们之间是概括的联系。
例:猫和动物之间是概括的联系,《Tom and Jerry》中那只名叫Tom的猫与猫之间是分类的联系,Tom的毛色和Tom之间是聚集的联系。
订单细节和订单之间,订单细节肯定不是一个订单,因此不是概括或分类。订单细节是订单的一部分,因此是聚集。
2.4 数据模型的优化
有了关系模型,可以进一步优化,方法为:
(1) 确定数据依赖。
(2) 对数据依赖进行极小化处理,消除冗余联系(参看范式理论)。
(3) 确定范式级别,根据应用环境,对某些模式进行合并或分解。
以上工作理论性比较强,主要目的是设计一个数据冗余尽量少的关系模式。下面这步则是考虑效率问题了:
(4) 对关系模式进行必要的分解。
如果一个关系模式的属性特别多,就应该考虑是否可以对这个关系进行垂直分解。如果有些属性是经常访问的,而有些属性是很少访问的,则应该把它们分解为两个关系模式。
如果一个关系的数据量特别大,就应该考虑是否可以进行水平分解。如一个论坛中,如果设计时把会员发的主贴和跟贴设计为一个关系,则在帖子量非常大的情况下,这一步就应该考虑把它们分开了。因为显示的主贴是经常查询的,而跟贴则是在打开某个主贴的情况下才查询。又如手机号管理软件,可以考虑按省份或其它方式进行水平分解。
2.5 设计用户子模式
这部分主要是考虑使用方便性和效率问题,主要借助视图手段实现,包括:
(1) 建立视图,使用更符合用户习惯的别名。
(2) 对不同级别的用户定义不同的视图,以保证系统的安全性。
(3) 对复杂的查询操作,可以定义视图,简化用户对系统的使用。
物理设计主要工作是选择存取方法(索引),以及确定数据库的存储结构,这里就不说明了。
好了,可以在你的DBMS上建表了。















 6564
6564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









