




大数据概述
大数据
是指无法通过常规软件工具在合理时间内完成采集、存储、管理和分析的庞大数据集合。这类数据需要借助新型处理模式,才能有效提升决策能力、洞察发现效率以及流程优化水平,具有海量规模、高速增长和多样形态的特征。
核心特征(4V):
- 数据体量巨大(Volume)
- 数据类型多样(Variety)
- 价值密度较低(Value)
- 处理速度要求高(Velocity)
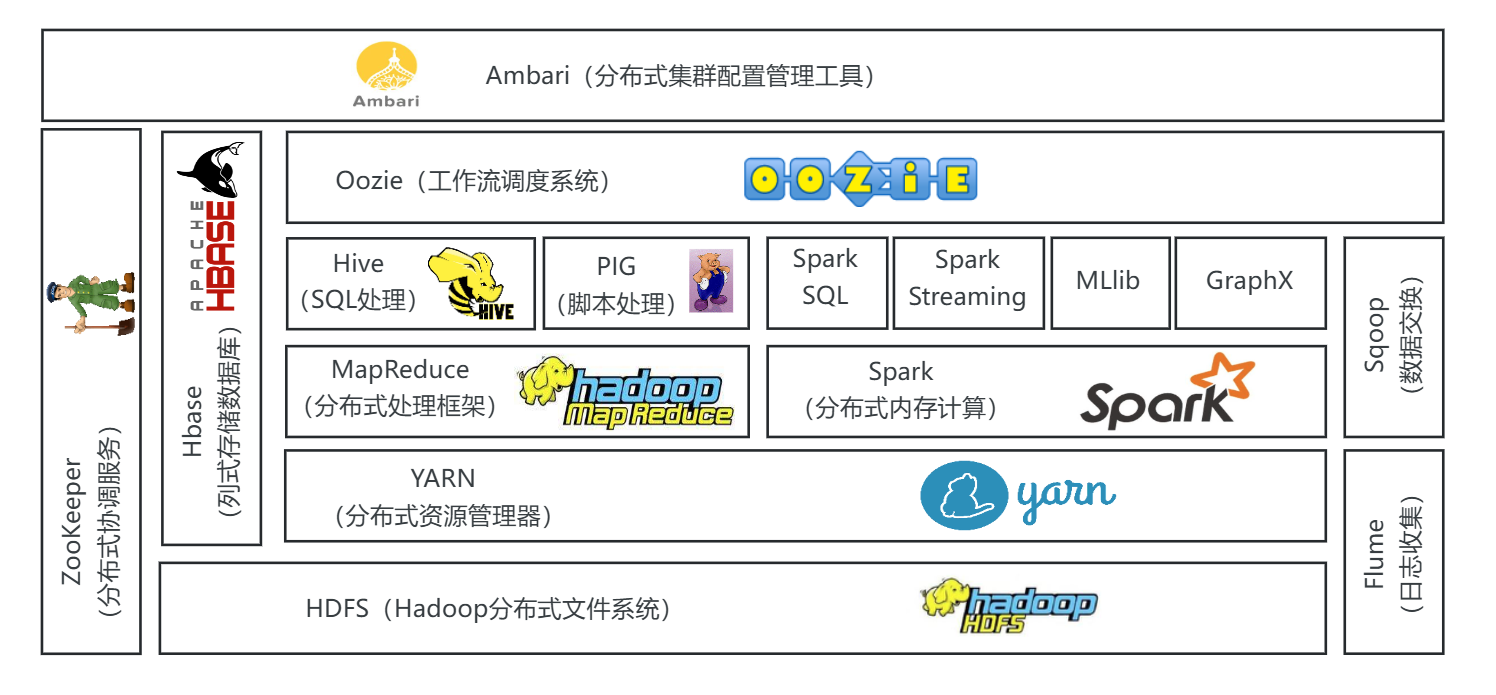
Hadoop
概述
- 一个开源的软件框架,用于在计算机集群上存储数据并运行应用程序。
- 提供解决大数据运算的框架方案。
- 支持大规模数据存储与计算。
- 针对大型作业具有高效处理能力。
- 支持多种处理引擎。
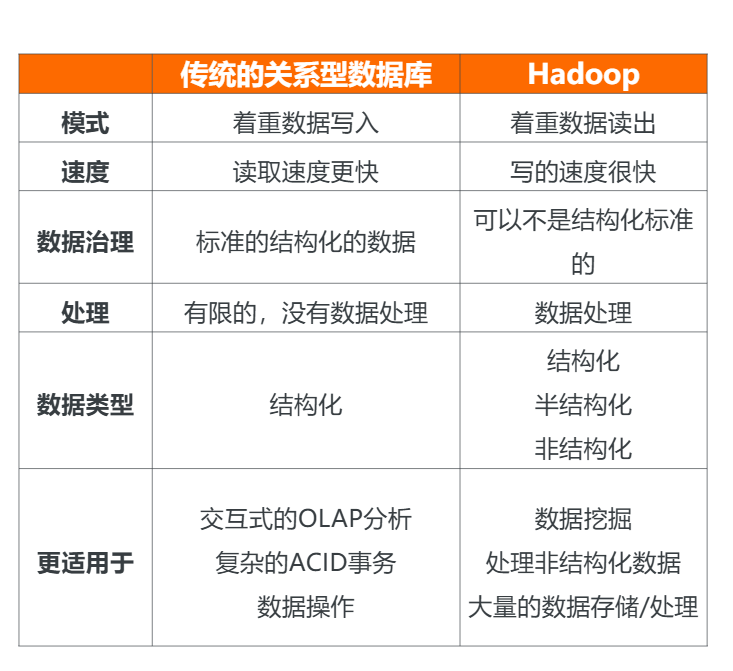
- 和传统关系型数据库的对比。
特点
- 高可靠性:采用按位存储和处理机制,确保数据安全稳定。
- 高扩展性:支持集群分布式计算,可轻松扩展至数千节点规模。
- 高效性:具备动态数据迁移能力,实现快速数据处理。
- 高容错性:自动维护数据多副本存储,智能重新分配故障任务。
- 低成本:开源架构显著降低软件成本,相比传统商业解决方案更具价格优势。
HDFS 文件系统核心特性
- 专为海量数据存储设计
- 支持大数据批量处理
- 采用一次写入、多次读取模式
- 确保数据强一致性
- 通过多副本机制保障高可靠性
MapReduce(分布式离线计算框架)
- 源自Google的MapReduce框架
- 是一种适用于海量数据(超过1TB)并行计算的编程模型,特别适合大规模数据处理场景
- 数据处理完成后,结果会直接存储在对应的计算节点上
- 每个MapReduce任务都包含两个核心处理阶段:Map阶段和Reduce阶段
Hive
- 基于Hadoop构建的数据仓库工具,支持数据提取、转换和加载(ETL)操作
- 提供类SQL查询接口(HQL),语法简单易学
- 无需编写复杂MapReduce程序,显著提升开发效率
- 专为海量数据的结构化分析而设计
- 典型应用场景包括WEB访问日志分析
- 常用于构建企业级离线数据仓库
HBase
- 作为谷歌BigTable的开源实现,HBase是一个高可靠、高性能的列式分布式数据库,具有出色的可扩展性,特别适合存储非结构化和半结构化的松散数据。
- 提供海量数据存储能力,采用列式存储结构,支持高并发访问。
- 具备极强扩展性,可通过横向增加RegionServer节点实现水平扩展。
- 专为高并发键值查询场景优化设计。
- 同时支持实时和批量数据更新操作。
ZooKeeper
- 作为分布式服务框架,ZooKeeper专门用于解决分布式应用中常见的数据管理问题。
- 在Hadoop生态中,它主要承担高可用性(HA)的实现功能,包括HDFS的NameNode和YARN的ResourceManager的高可用方案。
- 同时,ZooKeeper还负责存储YARN中应用程序的运行状态信息。
- 此外,该框架还支持负载均衡、数据发布与订阅等多种应用场景。
Spark
- 由加州大学伯克利分校AMP实验室(UC Berkeley AMP Lab)开源,是一个类似Hadoop MapReduce的通用并行计算框架。
- 特别适用于处理海量数据时的迭代计算任务。
大数据分析概述
大数据分析概念
数据分析是指基于商业等特定目标,系统性地收集、整理、加工和分析数据,从中提炼有价值信息的过程。
大数据分析则专门针对海量、多样化的数据集合进行处理。
大数据分析方法分类
-
描述性分析(发生了什么?)
- 覆盖广泛且精确的实时数据
- 提供有效的可视化呈现
-
诊断型分析(为什么会发生?)
- 深入挖掘数据核心
- 从复杂信息中提取关键因素
-
预测型分析(可能发生什么?)
- 运用算法建立历史模型,预测特定结果
- 采用自动化技术辅助决策生成
-
指令型分析(下一步怎么做?)
- 基于测试结果选择最优行动方案
- 应用高级分析技术辅助决策制定
大数据分析流程
数据预处理技术:数据清洗详解
数据清洗概述
数据清洗是指对原始数据集中的噪声数据进行处理的过程,包括修复、平滑或剔除异常数据。这一步骤在数据分析流程中至关重要,通常占据整个数据分析流程60%-80%的时间。数据质量直接影响后续建模和分析的准确性,常见的数据质量问题包括:
- 数据不完整(缺失值)
- 数据不一致(异常值)
- 数据重复
- 数据格式错误
- 数据噪声(随机误差)
主要处理内容
1. 异常值处理
检测方法:
- 箱线图法:通过四分位数(Q1, Q3)和IQR(四分位距)识别异常值,通常将小于Q1-1.5IQR或大于Q3+1.5IQR的值视为异常
- Tukey's test:基于分位数的稳健异常值检测方法
- Z-score法:计算数据点与均值的标准差距离,通常|Z|>3视为异常
- 聚类方法:通过聚类算法识别远离主要簇的数据点
处理方式:
- 删除:直接移除异常记录(适用于明显错误且占比小的数据)
- 视为缺失值:将异常值标记为缺失,后续进行缺失值处理
- 忽略:在某些鲁棒性强的算法中可保留
- 修正:根据业务逻辑调整到合理范围
分箱技术:
- 均匀分箱:将数据等分为N个区间(如年龄分为0-20,20-40,40-60等)
- 中位数分箱:每个箱中的数据量相同
- 边界分箱:根据数据分布的自然断点划分
- 数据平滑:包括箱均值平滑(用箱均值代替原始值)、箱边界平滑等
2. 缺失值处理
统计值填充:
- 均值填充:适用于近似正态分布的连续变量(如身高、体重)
- 众数填充:适用于分类变量(如性别、产品类别)
- 中位数填充:适用于偏态分布的连续变量(如收入)
固定值填充:
- 使用特定业务逻辑确定的固定值(如用"未知"填充缺失的客户职业)
邻近值填充:
- 前向填充(ffill):用前一个有效值填充
- 后向填充(bfill):用后一个有效值填充
- K近邻填充:基于相似样本的值进行填充
模型预测填充:
- 回归模型:建立其他特征与缺失特征的回归关系
- 随机森林:利用多棵决策树进行预测填补
- 深度学习:使用自编码器等神经网络模型
插值方法:
- 拉格朗日插值:通过多项式拟合已知数据点
- 牛顿插值:使用差商构造插值多项式
- 样条插值:分段低次多项式插值,保证光滑性
3. 重复记录处理
- 精确去重:所有字段完全相同的记录
- 模糊去重:关键字段相同即视为重复(如身份证号相同)
- 时间窗口去重:在一定时间范围内出现的相似记录
4. 错误记录修正
- 格式标准化(如日期统一为YYYY-MM-DD格式)
- 数据类型转换(如字符串"123"转为数值123)
- 逻辑校验(如年龄不应大于150岁)
无效数据过滤
根据业务需求过滤特定行或列:
- 过滤特定条件的行(如删除测试账户数据)
- 删除缺失率过高的列(如某字段缺失率>80%)
- 删除低方差特征(对模型无贡献的列)
- 删除高度相关的特征(避免多重共线性)
实际应用场景示例
电商数据分析:
- 处理异常订单金额(如1元买iPhone的异常订单)
- 填充缺失的用户年龄(基于购买行为模式预测)
- 合并同一用户的多个账号(基于设备ID、收货地址等)
医疗数据分析:
- 修正明显错误的生理指标(如血压300mmHg)
- 处理临床试验中的脱落病例数据
- 使用多重插补法处理缺失的随访数据
金融风控建模:
- 识别并处理欺诈交易中的异常模式
- 填充客户征信报告中的缺失字段
- 标准化不同渠道采集的客户信息格式
数据存储与管理
大数据的存储方式
单硬盘存储
- 基本概念:使用单一硬盘进行数据存储,是最简单的存储方式
- 特点:
- 成本低廉,安装简单
- 存储容量受限于单个硬盘的物理限制
- 可靠性较低,一旦硬盘损坏可能导致数据完全丢失
- 适用场景:
- 个人用户的小规模数据存储
- 非关键性数据的临时存储
- 测试环境中的简易存储方案
磁盘阵列(RAID)
- 基本概念:在单台机器上通过多块磁盘实现数据均衡存储
- 主要类型:
- RAID 0:条带化存储,提高性能但无冗余
- RAID 1:镜像存储,提供数据冗余
- RAID 5:带分布式奇偶校验的条带化存储
- RAID 10:RAID 1+0的组合,兼具性能和冗余
- 优势:
- 提高存储性能(读写速度)
- 增强数据可靠性(冗余保护)
- 增加存储容量(多盘组合)
- 应用场景:
- 企业级服务器的存储系统
- 需要高性能和高可靠性的应用环境
- 数据库服务器等关键业务系统
分布式存储
- 基本概念:基于网络连接,利用多台机器协同存储数据
- 核心特征:
- 数据被分割存储在多个节点上
- 通过网络协议实现节点间通信
- 具备自动数据复制和故障转移能力
- 优势:
- 理论上可无限扩展存储容量
- 高可用性(节点故障不影响整体服务)
- 支持地理分布式部署
- 典型应用:
- 云计算平台的基础存储设施
- 大规模互联网服务的数据存储
- 跨地域部署的企业存储系统
数据存储技术
分布式文件系统
- 定义:一种允许通过网络在多台计算机上共享文件的系统
- 关键技术:
- 元数据管理:集中式或分布式元数据服务
- 数据分片:将大文件分割存储在多个节点
- 一致性协议:保证多副本数据的一致性
- 典型系统:
- HDFS(Hadoop分布式文件系统):
- 适合大文件存储
- 采用主从架构
- 默认3副本机制
- Ceph:
- 无单点故障
- 支持对象、块和文件三种存储接口
- 采用CRUSH算法实现数据分布
- HDFS(Hadoop分布式文件系统):
- 应用优势:
- 处理PB级甚至EB级数据
- 支持高并发访问
- 自动处理节点故障
- 成本效益优于传统存储方案
数据处理技术在现代信息系统中扮演着关键角色,主要分为两种处理范式:
批量计算(Batch Processing)
工作方式:采用周期性处理模式,系统会先将数据集中存储在数据仓库或分布式文件系统(如HDFS)中,待达到预设条件(如时间窗口、数据量阈值)后,由调度系统(如Apache Oozie)触发批量作业执行。
核心特征:
- 批量处理模式:典型代表是MapReduce框架,通过分而治之策略处理海量数据
- 响应延迟较高:处理周期通常以小时/天为单位,如银行T+1对账系统
- 需主动触发执行:依赖外部调度指令,常见触发条件包括:
- 定时触发(每日凌晨2点)
- 数据量触发(累计100GB数据)
- 人工手动触发
典型应用场景:
- 离线数据分析:电商平台的用户行为分析(昨日UV/PV统计)
- 报表生成:金融机构的月度财务报表自动生成
- 数据挖掘任务:电信运营商基于历史通话记录的客户分群
流式计算(Stream Processing)
工作方式:采用持续处理架构,计算服务常驻内存运行(如Flink作业),数据源(如Kafka消息队列)中的每条记录到达后立即触发处理逻辑,实现端到端的流水线运算。
核心特征:
- 持续处理机制:7×24小时不间断运行,典型框架包括Spark Streaming/Flink
- 毫秒级低延迟:从数据产生到处理完成通常在500ms以内
- 事件驱动执行:每个数据事件(如传感器读数)都会立即触发处理流水线
典型应用场景:
- 实时推荐系统:短视频平台根据用户当前观看行为即时调整推荐内容
- 业务状态监控:
- 金融反欺诈:信用卡交易实时风控(每秒处理数万笔交易)
- 工业物联网:生产线设备状态实时预警
- 交通调度:网约车平台实时供需匹配计算
数据应用
数据可视化
商业智能(BI):运用数据仓库技术、在线分析处理(OLAP)、数据挖掘及数据展现技术进行商业数据分析,实现价值转化。
工具:阿里云Quick BI、Tableau、QlikView
大数据分析的技术工具与统计基础
数据库基础 数据库系统由以下要素构成:
- 支持数据库运行的软硬件环境
- 数据库本身
- 数据库管理系统(DBMS)
- 用户
数据库设计遵循三范式原则:
- 第一范式(1NF):确保数据的原子性
- 第二范式(2NF):保证数据的唯一性
- 第三范式(3NF):实现数据的独立性
关系模型核心概念:
- 关系:具有特定名称的二维表结构
- 元组:表中水平方向的行数据
- 属性:表中垂直方向的列字段
- 域:属性允许的取值范围
- 主键:能唯一标识元组的属性或属性组合
- 外键:在当前表中作为普通属性,在其他表中作为主键的字段
关系模型包含五大约束:
- 主键约束
- 外键约束
- 唯一性约束
- 检查约束
- 默认值约束
数据仓库基础 定义:面向主题、集成化、时变性的不可更新数据集合,主要用于支持管理决策。
核心特征:
- 主题导向:围绕特定业务主题组织数据
- 集成性:整合多源数据,统一命名、格式和编码
- 时变性:记录历史数据变化,支持趋势分析
- 稳定性:数据只读不可修改,定期更新
数据仓库模型详解
星形模型(Star Schema)
星形模型是最基础且广泛应用的维度建模方式,其核心特点包括:
-
基本结构:
- 由一个中央事实表(Fact Table)和多张维度表(Dimension Table)构成
- 事实表存储业务过程的可量化数据(如销售额、订单量等)
- 维度表存储描述性属性(如时间、地点、产品等)
-
关联方式:
- 维度表仅与事实表建立关联关系
- 维度表之间不存在直接的关联关系
- 采用外键约束实现关联,维度表主键存储在事实表中
-
设计特点:
- 各维度表采用单列主键设计(通常为代理键)
- 模型呈现明显的星形拓扑结构,事实表为中心,维度表呈放射状分布
- 典型示例:销售事实表关联产品、时间、客户、商店等维度表
-
优势:
- 结构简单,易于理解和实现
- 查询性能高,减少表连接数量
- 适合OLAP分析和报表生成
雪花模型(Snowflake Schema)
雪花模型是星形模型的规范化扩展,主要特点包括:
-
结构演变:
- 在星形模型基础上,允许维度表继续关联其他子维度表
- 将星形模型中的大维度表拆分为多个小维度表
- 形成类似雪花形状的多级关联结构
-
设计原理:
- 遵循数据库规范化理论,消除冗余数据
- 通过外键关系建立多级维度关联
- 示例:产品维度表可拆分为产品类别表、产品品牌表等
-
应用现状:
- 实际应用较为少见,主要因为:
- 增加了查询复杂度,需要更多表连接
- 降低了查询性能
- 数据仓库通常允许适当冗余以提高性能
- 开发维护难度增加
- 实际应用较为少见,主要因为:
-
适用场景:
- 当维度表包含大量属性且存在明显层次关系时
- 对存储空间有严格限制的环境
- 需要高度规范化的数据管理场景
两种模型的选择应基于具体业务需求、性能要求和开发资源综合考虑,在大多数数据仓库项目中,星形模型因其简单高效而成为首选方案。
ETL 数据处理流程
数据抽取(Extract)
支持从多种异构数据源获取原始数据:
- 关系型数据库:MySQL、Oracle、SQL Server等,支持JDBC/ODBC连接方式
- Hadoop生态系统:HDFS、Hive、HBase等大数据存储系统
- 结构化文件:CSV、Excel、XML等格式文件
- 非结构化文件:PDF、Word、日志文件等,支持文本解析和正则表达式提取
典型应用场景:
- 定时增量抽取:通过时间戳或增量标识获取新增数据
- 全量抽取:首次数据迁移时获取完整数据集
- 实时流式抽取:对接Kafka等消息队列获取实时数据
数据清洗(Transform)
提供专业的数据清洗能力:
-
自定义清洗函数:
- 支持Python/Java等语言编写UDF
- 提供字符串处理、数值转换等常用函数库
- 示例:手机号格式校验、地址标准化处理
-
文件处理能力:
- 文件编码转换(如GBK转UTF-8)
- 文件内容过滤(按正则表达式提取关键信息)
- 文件格式转换(如PDF转TXT)
清洗规则配置:
- 空值处理策略(填充默认值或丢弃记录)
- 异常值检测(基于统计规则或业务规则)
- 数据去重(根据主键或业务键值)
数据转换(Transform)
提供丰富的数据转换方式:
-
单表关联:
- 行转列/列转行
- 字段拆分与合并
- 数值计算(如金额单位转换)
-
多表关联:
- 支持Join、Union等SQL标准操作
- 提供Lookup查找表功能
- 支持缓慢变化维(SCD)处理
-
其他转换方式:
- 数据聚合(Group By+聚合函数)
- 窗口函数计算(如移动平均)
- 自定义业务逻辑转换
数据加载(Load)
支持将处理后的数据加载到多种目标系统:
-
关系型数据库加载:
- 批量插入和更新
- 支持事务处理
- 提供upsert(存在则更新)操作
-
Hadoop加载:
- 支持HDFS文件写入
- 支持Hive表数据加载
- 支持ORC/Parquet等列式存储格式
加载策略:
- 全量覆盖模式
- 增量追加模式
- 合并更新模式
数据质量监控
完善的监控告警体系:
-
检查规则配置:
- 字段级规则:非空检查、格式校验等
- 记录级规则:业务逻辑校验
- 统计规则:记录数波动检测
-
实时告警机制:
- 邮件/SMS/企业微信通知
- 分级告警(警告/严重/致命)
- 支持自定义告警阈值
-
中断式告警功能:
- 关键错误自动停止任务
- 提供错误恢复机制
- 生成详细错误报告
监控指标示例:
- 数据量波动率
- 空值率/异常值比例
- 处理时效性(延迟时间)
OLTP与OLAP系统详解
OLTP (Online Transaction Processing)
在线交易处理系统,是面向业务操作的数据库系统,主要用于日常事务处理。
主要特征
- 处理大量短小、原子性的交易操作
- 支持高并发读写
- 强调数据的一致性和完整性
- 响应时间通常在毫秒级别
典型应用场景
- 银行ATM交易处理
- 电商订单处理系统
- 航空订票系统
- 库存管理系统
- 信用卡交易处理
数据结构特点
- 采用高度规范化的关系模型
- 大量使用索引提高查询效率
- 通常采用行存储方式
OLAP (Online Analytical Processing)
在线分析处理系统,是面向数据分析的数据库系统,主要用于决策支持。
主要特征
- 处理复杂查询和分析操作
- 主要面向读操作
- 强调查询性能和分析能力
- 响应时间通常在秒到分钟级别
典型应用场景
- 销售趋势分析
- 客户行为分析
- 财务报告生成
- 市场细分研究
- 预测建模
数据结构特点
- 采用星型或雪花型schema
- 大量使用预计算和聚合
- 通常采用列存储方式
- 支持多维数据模型
系统对比
| 特性 | OLTP | OLAP |
|---|---|---|
| 主要目的 | 日常业务操作 | 决策支持分析 |
| 数据特性 | 当前、详细数据 | 历史、汇总数据 |
| 查询类型 | 简单查询 | 复杂分析查询 |
| 并发性 | 高并发 | 低并发 |
| 数据量 | 相对较小 | 通常较大 |
| 更新频率 | 频繁更新 | 批量加载 |
大数据分析相关的统计基础
基本概念
总体与样本
- 总体:研究对象的全部个体组成的集合。例如:全国所有大学生的平均身高。
- 样本:从总体中抽取的部分个体组成的子集。例如:从全国大学生中随机抽取1000人测量身高。
- 参数:描述总体特征的数值指标(如总体均值μ)。通常是未知的,需要通过样本推断。
- 统计量:描述样本特征的数值指标(如样本均值x̄)。是已知的,用于估计参数。
变量类型
- 分类变量:表示类别(如性别、产品类型)
- 有序变量:有顺序的类别(如满意度等级)
- 数值变量:
- 离散型(如客户购买次数)
- 连续型(如温度、收入)
频率与概率
- 频率:某事件在已观察数据中出现的相对次数
- 概率:某事件在理论上发生的可能性
- 关系:当样本量足够大时,频率趋近于概率(大数定律)
数据的概括性度量
集中趋势指标
-
众数(Mode):出现次数最多的值
- 适用性:适用于所有测量尺度的数据
- 示例:销售数据中最畅销的产品型号
-
中位数(Median):将数据排序后位于中间位置的值
- 计算方法:n为奇数时取第(n+1)/2个值;n为偶数时取中间两个数的平均值
- 特点:不受极端值影响
-
平均数(Mean):所有数值的和除以数量
- 计算公式:x̄ = (Σx)/n
- 特点:对极端值敏感
-
分位数(Quantile):将数据分为若干等份的点
- 常用分位数:四分位数(Q1=25%, Q2=50%, Q3=75%)
- 应用:构建箱线图
离散趋势指标
-
极差(Range):最大值与最小值之差
- 局限性:只考虑两个极端值
-
四分位差(IQR):Q3-Q1
- 优点:消除了极端值影响
- 应用:识别异常值(通常定义为<Q1-1.5IQR或>Q3+1.5IQR)
-
方差(Variance):各数据点与均值差的平方的平均
- 计算公式:σ² = Σ(x-μ)²/N (总体)
- 样本方差通常使用n-1作为分母(无偏估计)
-
标准差(Standard Deviation):方差的平方根
- 单位与原数据一致
- 应用:68-95-99.7规则(正态分布)
-
变异系数(CV):标准差与均值的比值
- 计算公式:CV = σ/μ
- 特点:无量纲,适用于比较不同量纲数据的离散程度
常见的概率分布
离散型分布
-
二项分布(Binomial)
- 参数:n(试验次数)、p(单次成功概率)
- PMF:P(X=k) = C(n,k)p^k(1-p)^(n-k)
- 应用场景:n次独立伯努利试验中的成功次数(如质检抽样)
-
泊松分布(Poisson)
- 参数:λ(单位时间/空间内事件的平均发生次数)
- PMF:P(X=k) = (λ^k e^-λ)/k!
- 应用场景:罕见事件计数(如客服电话呼入量)
连续型分布
-
正态分布(Normal)
- 参数:μ(均值)、σ(标准差)
- PDF:f(x) = (1/√(2πσ²))e^(-(x-μ)²/(2σ²))
- 特点:对称、钟形曲线
- 标准正态:μ=0, σ=1
-
均匀分布(Uniform)
- 参数:a(下限)、b(上限)
- PDF:f(x) = 1/(b-a) (a≤x≤b)
- 应用:随机数生成
-
指数分布(Exponential)
- 参数:λ(速率参数)
- PDF:f(x) = λe^(-λx) (x≥0)
- 应用:等待时间建模(如设备故障间隔)
假设检验
基本流程
- 提出原假设(H0)和备择假设(H1)
- 选择显著性水平α(通常0.05)
- 计算检验统计量
- 确定P-value或临界值
- 做出统计决策
核心概念
-
P-value:在原假设为真时,观察到当前或更极端结果的概率
- P<α:拒绝H0
- P≥α:不拒绝H0
-
两类错误:
- 第一类错误(α):错误拒绝H0(假阳性)
- 第二类错误(β):错误接受H0(假阴性)
- 功效(power)=1-β:正确拒绝H0的概率
-
置信区间:参数的可能取值范围
- 95%置信区间:重复抽样时,95%的区间会包含真实参数
- 计算方法:估计值±临界值×标准误
常见检验类型
- Z检验(大样本,σ已知)
- t检验(小样本,σ未知)
- χ²检验(分类数据)
- F检验(方差比较)

















 6082
6082



 到【灌水乐园】发言
到【灌水乐园】发言








