







一、map基本操作
1.声明与初始化
// 声明
var hash map[T]T
// 初始化,第二个参数表示长度,默认为0
var hash = make(map[T]T,L)
// 也可以采用字面量方式初始化
var hasj = map[string]string{
"name":"zhangsan",
"addr":"beijing",
"phone":"0101234567",
}
2.访问
v:=hash[key]
v,ok:=hash[key]//第二个参数表示是否存在这个值
map不支持并发读写。如果需要并发读写map可以用sync.Map代替。
3.赋值与删除
可以采用hash[key]=val的方式赋值。
删除采用delete(hash,key)的方式,当key不存在时不报错。
注意hash赋值时key应该是可比较的。
布尔值、整数值、浮点值、负数值、字符串是可比较的;指针值是可比较的,如果两个指针指向同一个变量或同时为nil,则他们相等;管道是可比较的,如果两个管道有同一个make函数创建,或同时为nil,则他们相等;接口是可比较的,如果两个接口具有相同的动态类型和相等的动态值,或都为nil,则他们相等;如果结构体的所有字段可比较,则他们的值可比较;如果数组的值可比较,则他们可比较。
切片、函数、map是不可比较的。
二、map底层结构
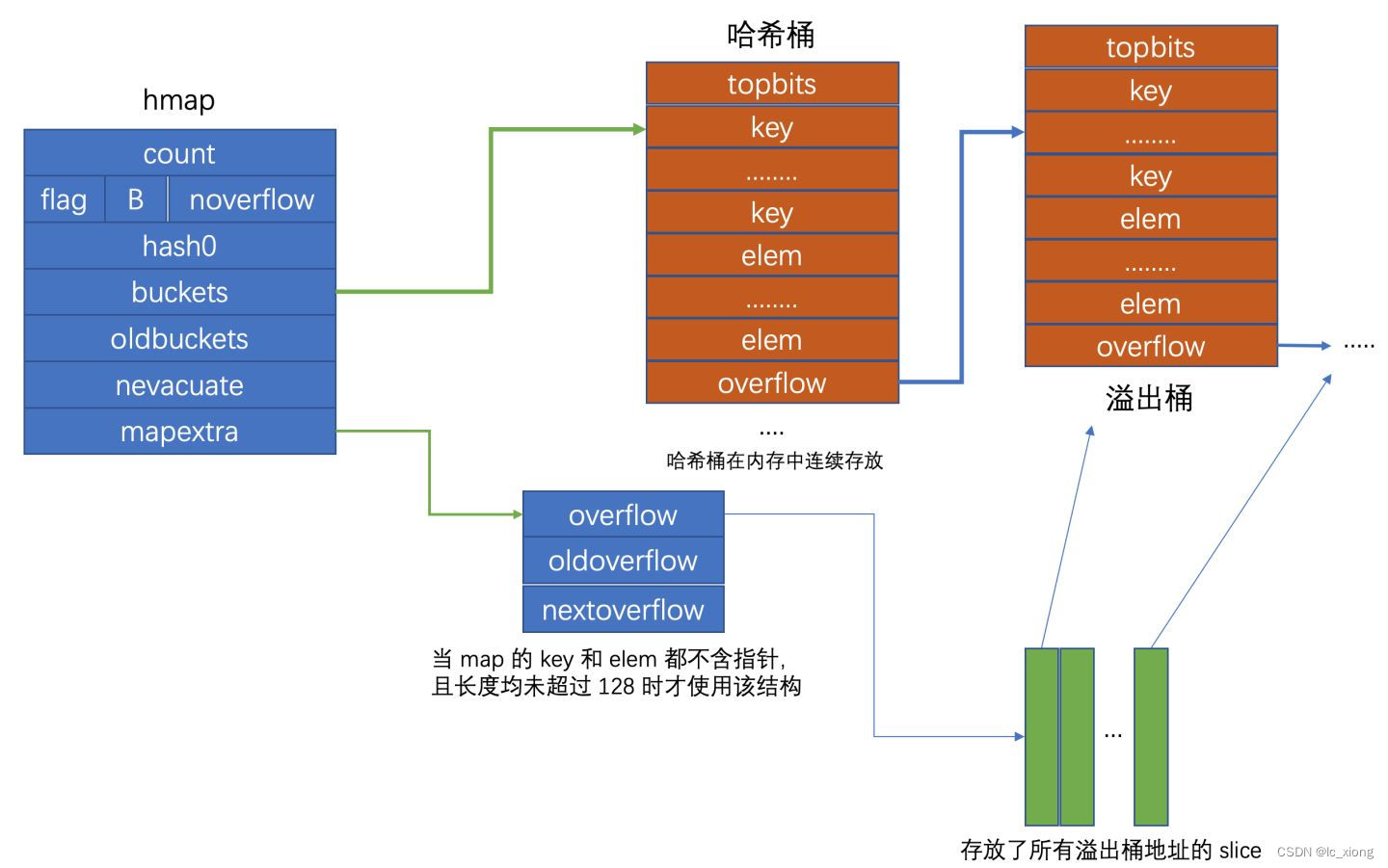
Go 语言使用 hmap结构体来表示哈希表
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
其中,
count表示当前哈希表中的元素数量。flags表示当前哈希表状态。B表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是len(buckets) == 2^B。noverflow表示溢出通的数量。hash0是哈希的种子。buckets是指向当前哈希表对应桶的指针。oldbuckets是map在扩容时用于保存之前buckets的字段,当所有旧桶的数据都保存到新桶时则清空。nevacuate在扩容时使用,表示当前旧桶中小于nevacuate的数据都已经转移到了新桶中。extra存储溢出桶。
桶的结构体 bmap 在 在运行时只包含一个 tophash 字段,tophash 存储了键的哈希的高 8 位,通过比较不同键的哈希的高 8 位可以减少访问键值对次数以提高性能:
type bmap struct {
tophash [bucketCnt]uint8
}
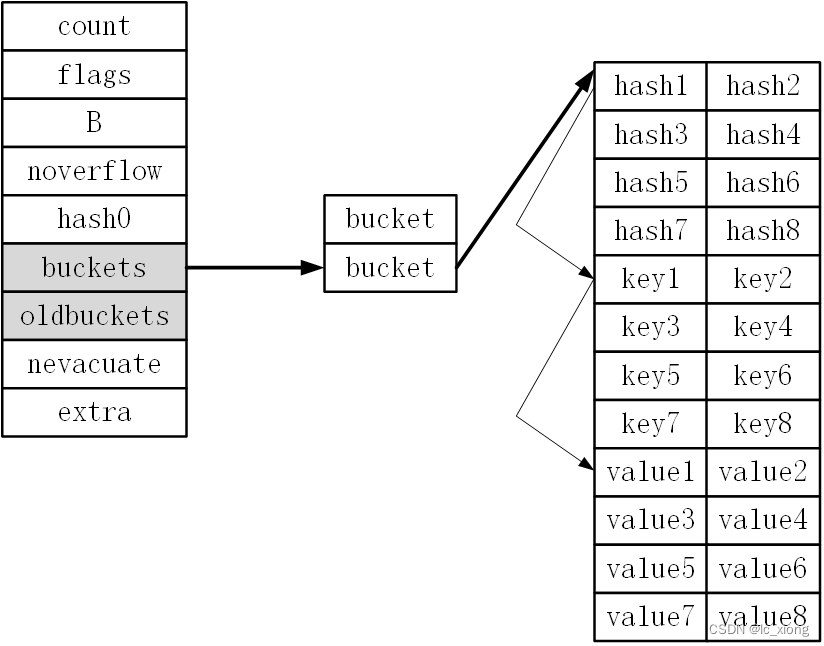
bmap 结构体其实不止包含 tophash 字段,map在编译阶段就确定了key和value以及桶的大小,所以通过指针操作就可以找到某个位置的值。
type bmap struct {
tophash [8]uint8
keys [8]keytype
values [8]valuetype
...
}
三、map底层原理
1.查找
Go语言的哈希表将key与value分开存储,以便在字节对齐时压缩空间。
在访问操作时,会通过hash & m的方式先找到桶的位置,然后计算hash值的高8位,接着遍历tophash数组,如果值相同,会比对key值是否相同,如果key也相同,则返回value。
在hash[key]=val赋值时,当桶中的数据超过8个时并不会开辟新桶,而是将数据放在溢出桶里。所以当查找时,在桶中tophash数组不存在,需要遍历溢出桶中的数据。只有当溢出桶用完了才会新建溢出桶。
当桶的数量小于 2^4 时,由于数据较少、使用溢出桶的可能性较低,这时就会省略创建的过程以减少额外开销;当桶的数量多于 2^4 时,就会额外创建 2^{B-4}个溢出桶,并且正常桶和溢出桶在内存中的存储空间是连续的,只是被 hmap 中的不同字段引用。
2.赋值
赋值操作会先计算key的hash值,标记当前map为写入状态,如果没有桶,会先创建一个桶,如果map正在重建,会先完成重建。然后计算tophash,开始寻找是否有对应的值,如果有判断key值是否相等,如果相等则会找到value进行更新。如果没找到tophash,还会去溢出桶中寻找。如果没找到,会向第一个空元素位置插入数据。
// 赋值过程
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if !alg.equal(key, k) {
continue
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
3.扩容
以下两种情况之一发生时触发哈希的扩容:
-
装载因子已经超过 6.5;
-
哈希使用了太多溢出桶。
扩容的入口是 runtime.hashGrow函数:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
h.extra.nextOverflow = nextOverflow
}
该函数中只是创建了新的桶,并没有对数据进行拷贝和转移,在扩容期间访问哈希表时会使用旧桶,向哈希表写入数据时会触发旧桶元素的分流。
4.删除
哈希表的删除逻辑与写入逻辑非常相似,只是触发哈希的删除需要使用关键字,如果在删除期间遇到了哈希表的扩容,就会对即将操作的桶进行分流,分流结束之后会找到桶中的目标元素完成键值对的删除工作。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
if h.growing() {
growWork(t, h, bucket)
}
...
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if !alg.equal(key, k2) {
continue
}
*(*unsafe.Pointer)(k) = nil
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
*(*unsafe.Pointer)(v) = nil
b.tophash[i] = emptyOne
...
}
}
}
参考文献:
链接: 哈希表















 2178
2178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









