




1、前沿
传统的机器人学习范式通常依赖于为特定机器人和任务收集的大规模数据,但由于现实机器人硬件固有的局限性,采集用于通用任务的数据既费时又昂贵。如果能够预训练一个基于异构机器人数据的通用机器人策略,并仅需极少监督进行微调,那么这将对实现真正泛化的VLA模型具有重要意义。
本文提出了 Dita,一种扩散Transformer策略 (Dita)。Dita充分利用了 Transformer 架构,从而确保了在大规模跨机体数据集上的可扩展性。它融合了上下文条件机制和因果 Transformer,能够自发对动作序列进行去噪,从而实现以图像标记直接作为条件的动作去噪。
最核心的创新在于动作生成模块。传统方法通常是将视觉信息和语言信息融合成一个抽象的表示,然后用一个小型网络来生成具体的动作。但Dita采用了完全不同的策略:它让一个大型的Transformer网络直接处理所有信息,包括视觉观察、语言指令、时间信息以及需要生成的动作,利用上下文条件,使得去噪后的动作能够与历史观测中原始的视觉token实现细粒度对齐,从而明确建模了细微的动作变化和环境差别。
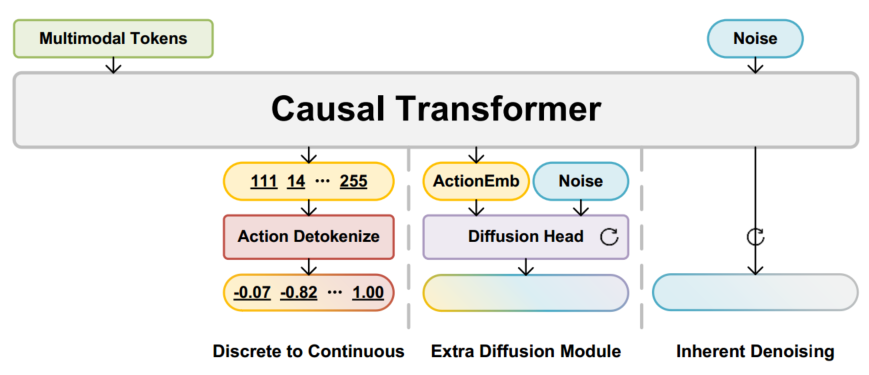
-
左图:具有离散化动作的常见机器人Transformer架构,例如robot Transformer和OpenVLA。
例如,OpenVLA将连续的7 维动作维度离散化为 256 个区间(bin)。将256个动作bin映射到LLM词表中的"空闲token"位置,从而让 LLM 能把动作预测当作“生成 token”的过程,然后对每个动作维度执行区间→连续值的映射转换。
action_value = bin_id / 255.0 * action_range + action_min -
中间头:具有扩散动作头的Transformer架构,它在因果Transformer的每个嵌入上用小网络条件对单个连续动作进行去噪,例如Octo和π0。π0采用预训练的VLM处理图像和文本(比如人类指令)输入,采用Diffusion Head处理机器人特定的输入(比如机器人的状态),和输出(比如预测的机器人动作)
-
右图:Dita架构,上下文动作去噪。
2、 方法与架构设计
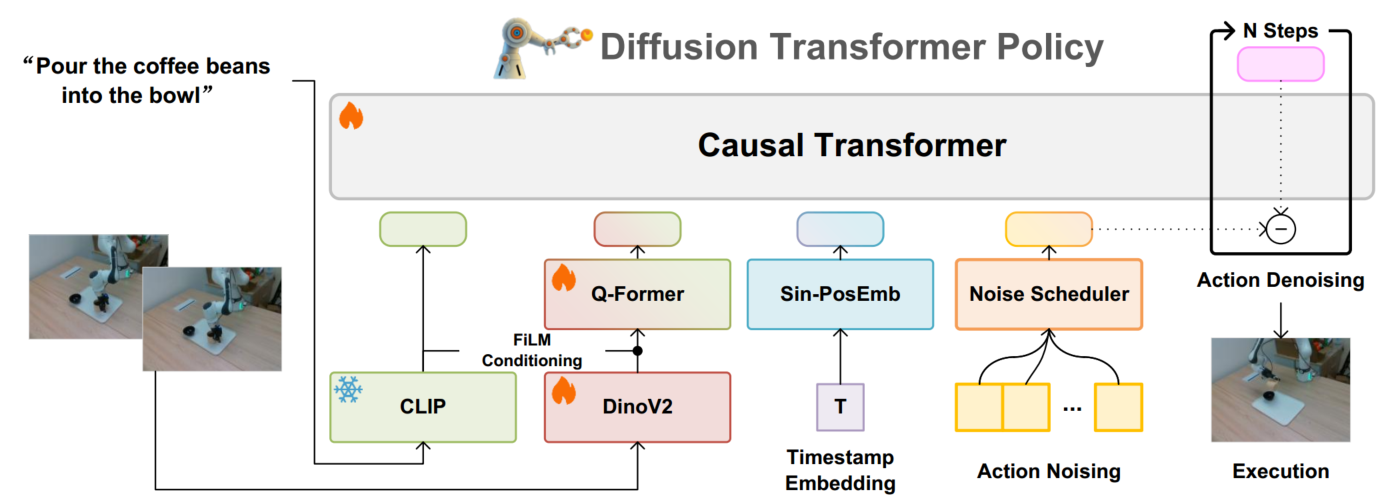
2.1 多模态输入与特征提取
- 语言输入:利用预训练且冻结的CLIP模型对自然语言指令进行编码。
- 图像输入:第三人称相机图像作为输入,大小被调整为224×224,通过预训练的 DINOv2 模型提取图像特征。由于DINOv2是在网络数据上训练的,以端到端的方式与Dita一起共同优化DINOv2参数。采用从头开始训练的深度为4的Q-Former模型,它将图像特征的维数降低到32维;在每个块内,注入文本token作为FiLM条件,用语言信息增强图像特征
2.2 动作预处理与表示
- 将末端执行器的动作表示为7维向量(3维平移、3维旋转、1维夹爪状态)。
- 使用零填充使动作向量与图像和语言特征维度对齐。
- 在训练过程中,仅对7维动作向量加入噪声,通过扩散去噪优化模型
2.3 Transformer架构的扩散模型
- 核心思想:利用Transformer架构的扩散模型对连续域上的动作序列进行去噪,而不是使用小型的去噪头网络或是单独对动作token进行去噪
- 上下文条件化:将语言、图像及时间戳嵌入与噪声化动作序列拼接,输入因果 Transformer 模型。
- 模型结构:采用类似 LLaMA 风格的结构,共 12 个自注意力层。模型总参数量334M,其中可训练参数约 221M。
- 训练目标:最小化噪声预测的均方误差(MSE),使模型学会从历史观察中恢复正确的动作变化(action delta)。
2.4 扩散过程与训练目标
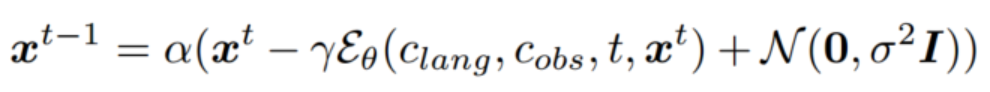
去噪网络Eθ(Clang,cobs,t,xt)E_θ(C_{lang},c_{obs},t,x^t)Eθ(Clang,cobs,t,xt)基于因果transformer构建,其中cobsc_{obs}cobs表示图像观察,clangc_{lang}clang表示语言指令。Dita的优化目标是使 xtx^txt 和 x^t\hat{x}^tx^t 之间的均方误差(MSE)损失最小化
- 训练时采用 DDPM 扩散目标,共加噪1000步。
- 推理时采用 DDIM 加速,仅需20步去噪即可获得准确动作预测。
- 每次去噪过程中,模型根据当前带噪动作和条件信息预测噪声向量,并按照预设噪声调度器更新动作,从而兼顾去噪效果与实时性。
2.5 数据集与预训练细节
- 采用Open X-Embodiment(OXE)跨平台数据集进行预训练,数据涵盖不同机器人平台、摄像头视角和任务场景。
- 通过动作归一化与过滤处理保证数据质量。
- 使用AdamW优化器,在32块NVIDIA A100 GPU上进行,总训练步数10万步,每块GPU的批大小为256。
3、结论与展望
Dita 提出了一种全新的通用机器人策略架构,利用 Transformer 扩散模型和上下文条件化方法,有效解决了多模态输入条件下机械臂的连续动作生成的问题。其主要优势体现在以下几个方面:
- 模型设计简单高效:仅需单一第三人称摄像头输入,通过联合多模态特征提取与扩散去噪,模型结构紧凑(334M 参数)且易于扩展。
- 强大的泛化能力:利用跨平台、跨任务的大规模数据(OXE 数据集)进行预训练,模型在SimplerEnv、LIBERO、CALVIN、ManiSkill2 等仿真平台上均取得领先表现;通过 10-shot微调,在真实机器人实验中展现出优异的适应能力。
- 对长程任务的优秀建模:采用扩散模型直接对连续动作序列进行去噪,能够捕捉动作变化的细微差异,在多步骤、复杂操作任务上明显优于传统方法。
- 鲁棒性与扩展性:大量消融实验表明,模型对输入观测长度、轨迹长度及去噪步数等关键参数具有良好的鲁棒性。架构设计允许方便地融合更多传感器输入(如腕部摄像头、机器人状态、触觉反馈等),为未来研究提供了较大灵活性。
总的来说,Dita 为通用机器人策略学习提供了一个干净、轻量且开源的基线模型,其优异的少样本适应能力与长程任务处理能力预示着未来在机器人控制、视觉语言交互等方向上具有广阔的应用前景。该方法不仅在仿真环境中取得显著进展,也在实际机器人平台上通过 10-shot 微调成功转移到复杂任务场景,展现了跨域泛化能力。

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









