






项目地址及数据来源Titanic - Machine Learning from Disaster | Kaggle
1.数据探索
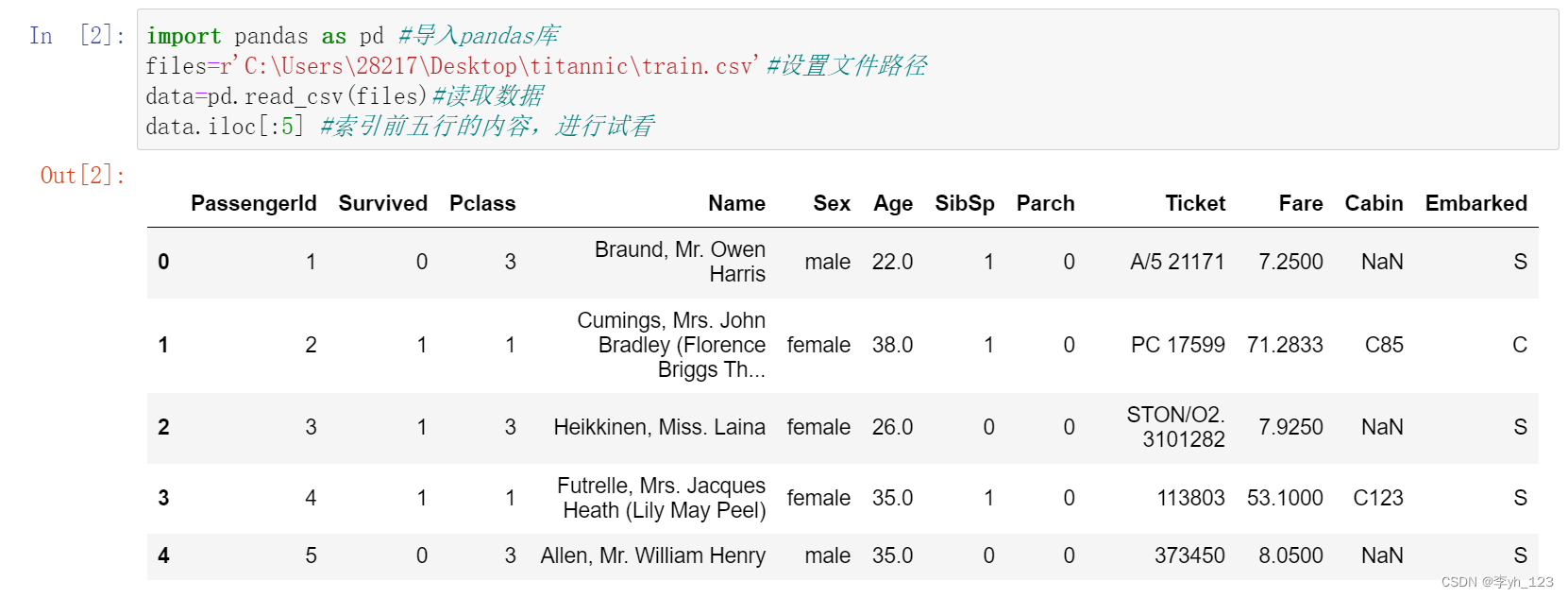
进一步,查看每一列的数据类型及缺失值情况
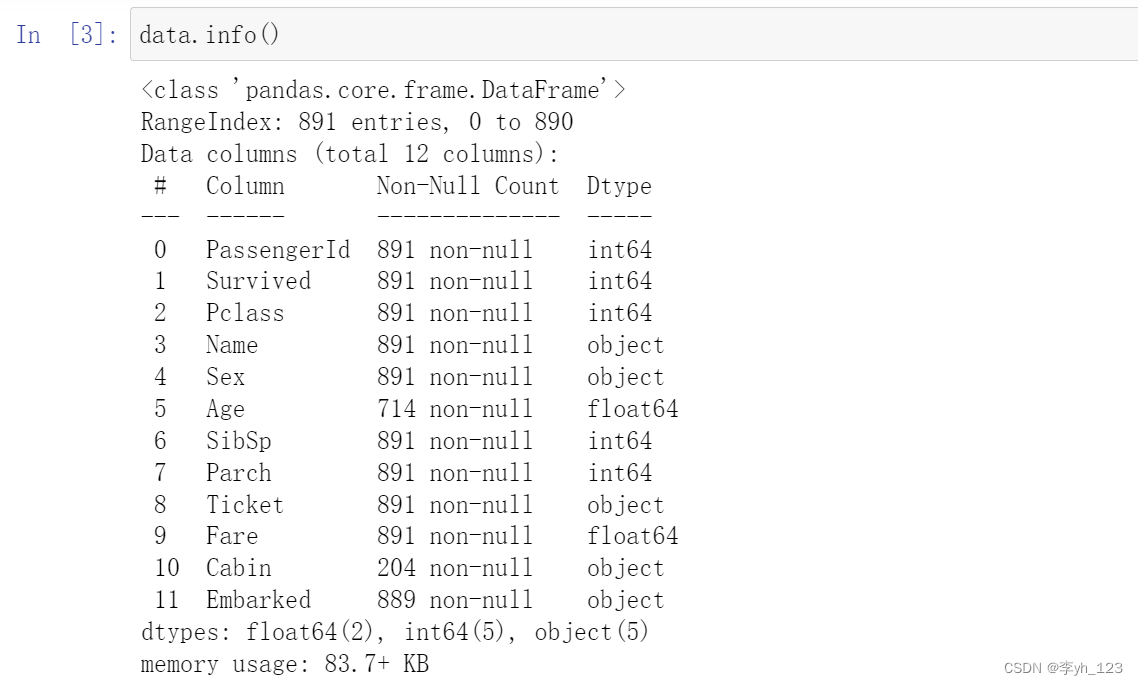
数据类型:
1.PassengerId:用于记录乘客id,891个非空整数值
2.Survived:用于记录乘客最终的存活情况,死亡为0,存活为1,891个非空整数值
3.Pclass:用于记录船票等级,有891个非空整数值,分了1,2,3三个等级
4.Name:用于记录乘客姓名,有891个非空整数值
5.Sex:用于记录乘客性别,有891个非空整数值
6.Age:用于记录乘客年龄,有714个非空浮点数,有177个缺失值
7.SibSp:用于记录同行的兄弟姐妹/配偶数量,有891个非空整数值
8.Parch:用于记录同行的父母/孩子数量,有891个非空整数值
9.Ticket:用于记录船票号码,有891个非空字符串
10.Fare:用于记录船票费用,有891个非空浮点数
11.Cabin:用于记录船舱号码,仅有204个非空字符串,缺失值较多,直接排除该变量的影响。
12.Embarked:用于记录登船港口,有889个非空字符串,有2个缺失值
2.数据预处理
定义数据预处理函数,用于将字符串类型的数据转换为整数或浮点数(如果有必要的话),填补缺失值,并删除cabins列

利用数据预处理函数对读取的数据集做预处理,并再次查看数据的缺失情况
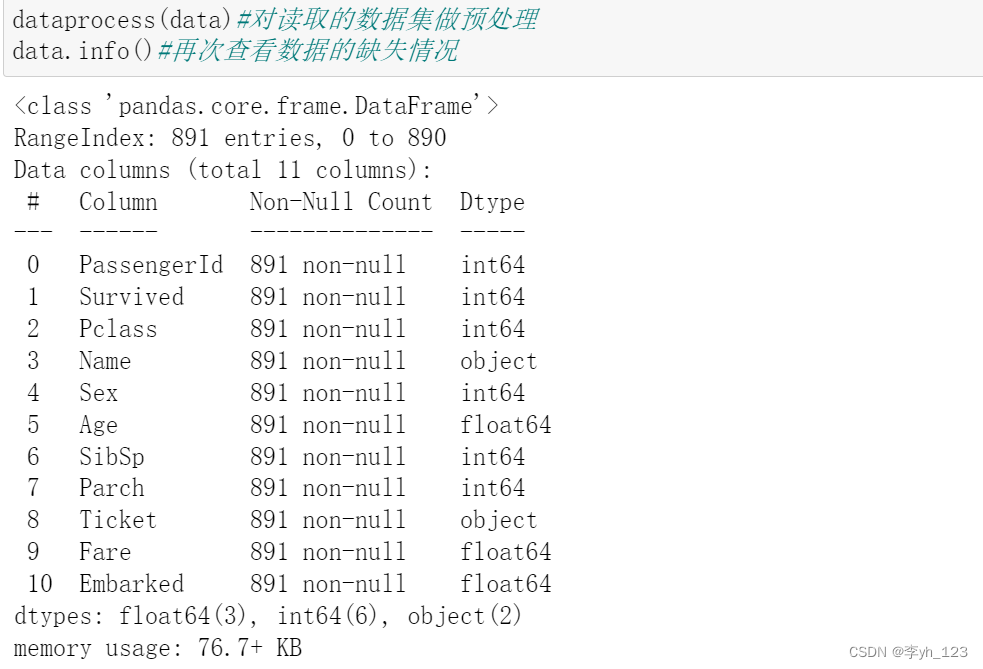
可以看出,除了由于缺失值过多被我们抛弃的Cabin列以及无法转换的name列以外,其他的列已经成功填补了缺失值并转换为整数或者浮点数类型

可以看出,PassengerId与生还特征的相关性相当低,因此,在构建决策树模型的时候考虑舍去。
3.寻找最优参数
首先提取出训练集的特征数据与预测目标

构建决策树预测模型,创建决策树分类的实例

使用多条件网格搜索找到最佳参数
 输出结果为
输出结果为

4.模型预测
根据网格搜索所得出的最优参数编写决策树分类器,并根据训练集进行训练

再利用训练好的模型,预测测试集中的数据,并保存至CSV文件,上传至Kaggle官网

最终结果
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









