







隐私保护的挑战
例子一
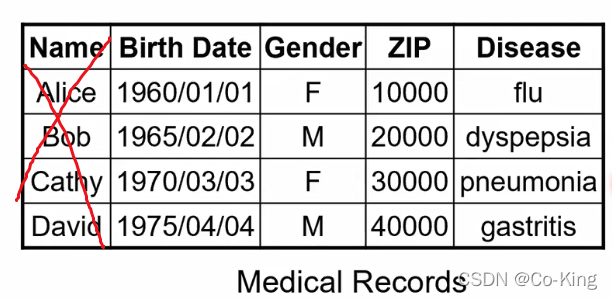
- 一个简单的做法:将数据匿名化
- 这样的做法看似合理,但其实并不能真的保护隐私
- 原因:匿名化之后的数据往往还保留着许多可能泄漏隐私的信息
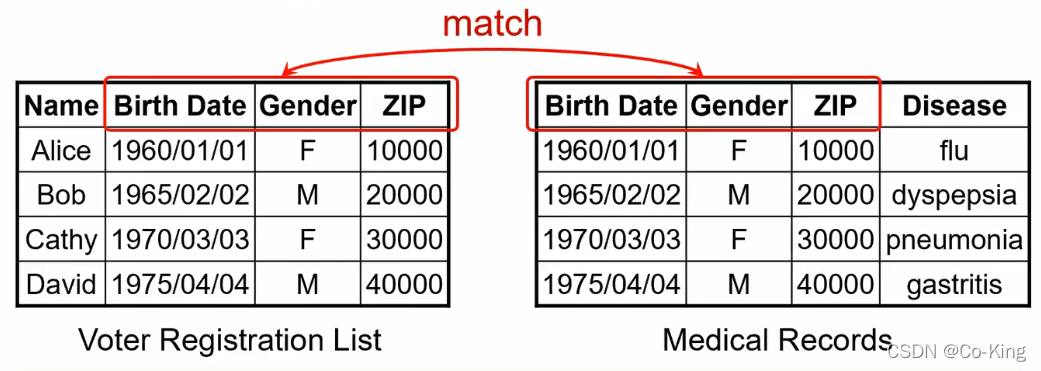
- 可能在别的地方得到一些数据以后,数据进行匹配以后,会反推出用户信息,从而破坏用户隐私
比如:
- 九十年代中期,美国马萨诸塞州一政府部门就曾遭受这样的攻击
- 他们发布了匿名化的员工医疗记录用于研究
- 后果:当时的州长的医疗记录被泄漏
- 后续研究表明,63%的美国人口有着唯一的{出生日期、性别、邮编}组合,这说明有着63%的人可能面临着暴露身份
既然匿名化容易被攻击,我们是否可以考虑不发布详细的元组,转而发布粗粒度的统计数据?
答案:统计数据也有可能泄漏隐私
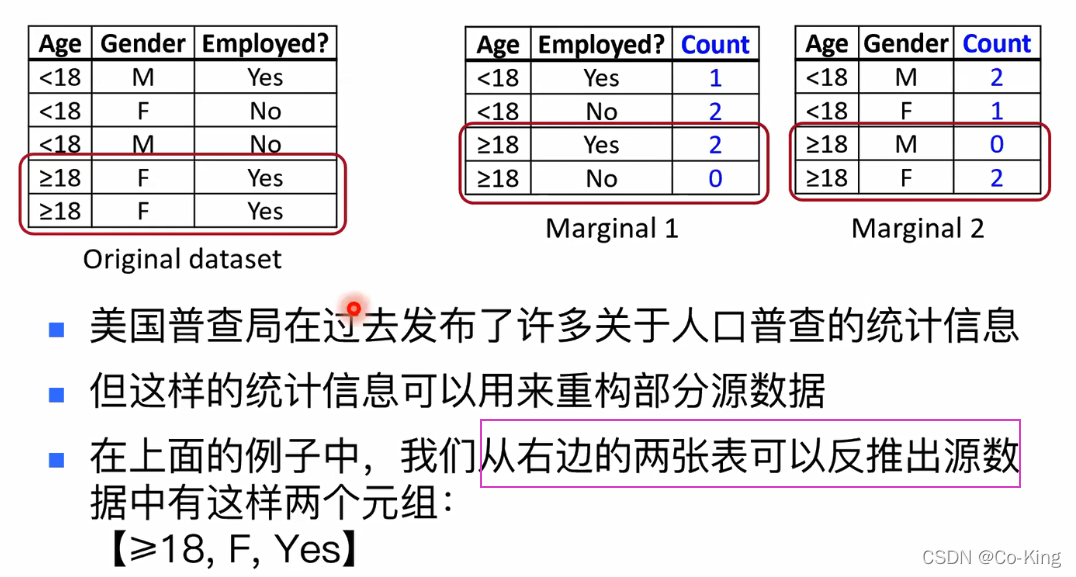
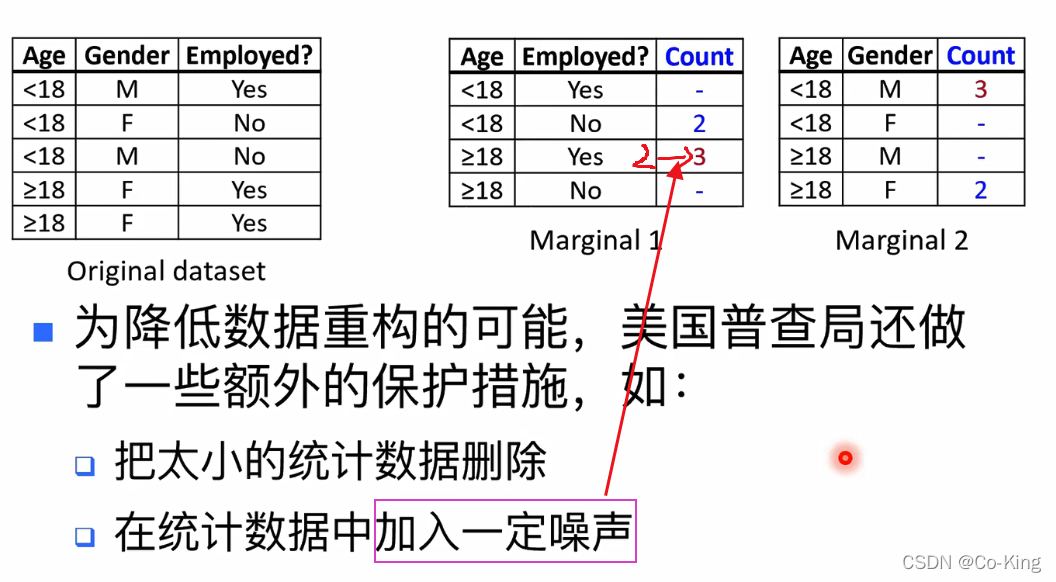
数据重构攻击
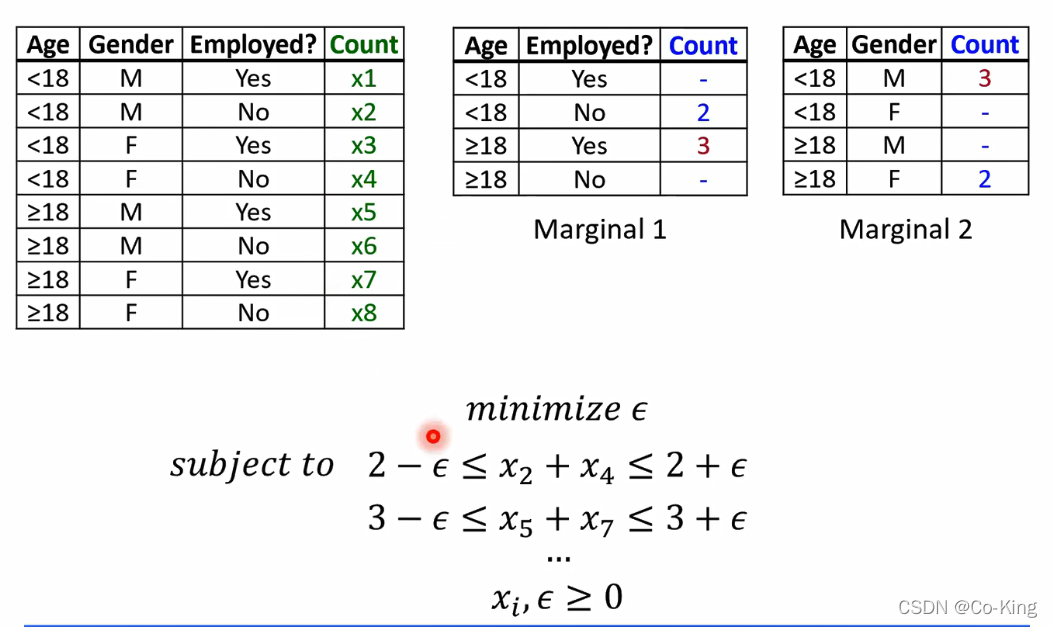
这种重构结果有多准确呢?

数据重构攻击的实际效果
- 美国普查局用他们2010年所发布的一组统 计数据试验了数据重构攻击
- 结果表明,他们能重构17%美国人口的数 据
- 为此,他们宣布将于2020年的统计数据发 布中使用差分隐私
机器学习模型发布
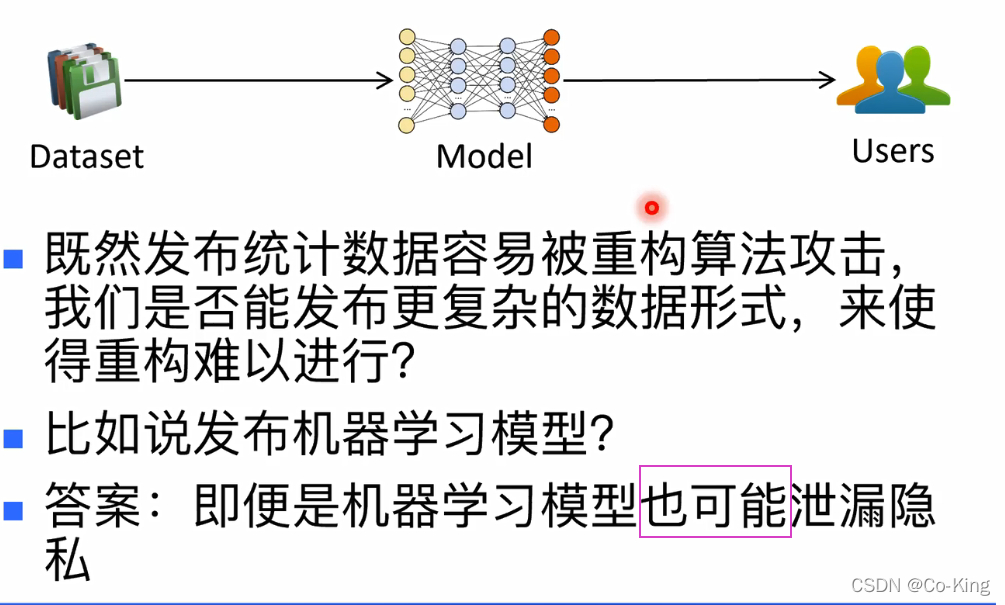
机器学习模型也可能泄露隐私 原因?
- 机器学习模型往往会不经意地“记住”源数据中的元组
- 因此,模型在那些元组上的表现可能跟在其他元组上的 表现会不一样
- 类比与:学生考试时,碰上之前做过的题和碰上没做过的题,反应是不一样的
对机器学习模型的隐私攻击
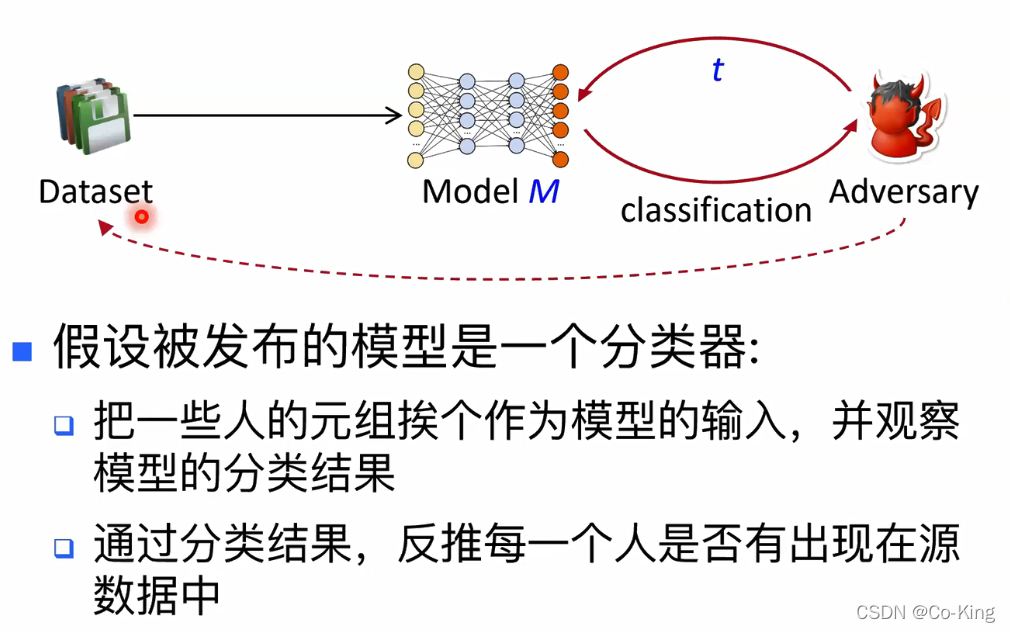
小总结:
- 总而言之,攻击者可以有很多种不同方式 来对隐私数据进行攻击
- 为防范这些可能的攻击,我们需要有一个 严谨的框架来对数据隐私进行保护
- 差分隐私正是这样的一个理论框架
差分隐私:定义及原理
差分隐私的直观原理
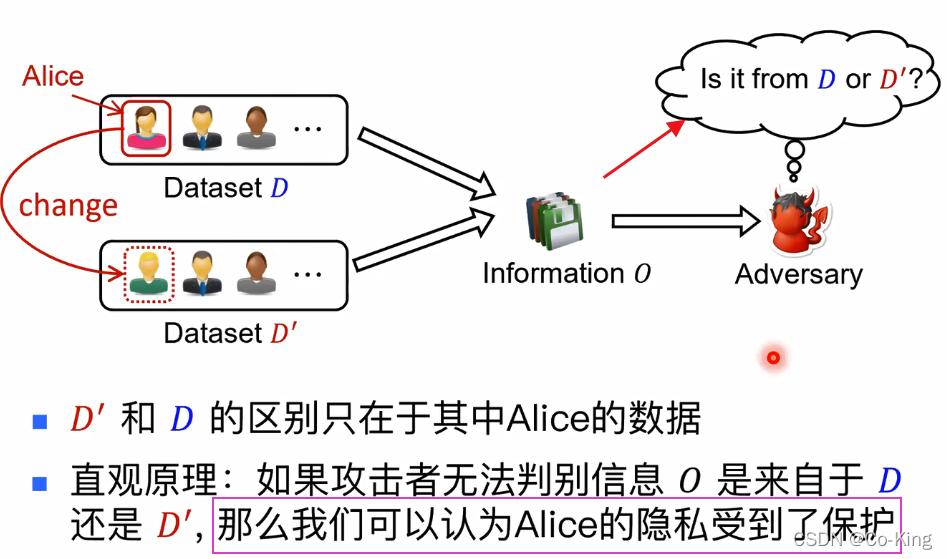
- 差分隐私要求任何被发布的信息都应当与上图中的信息0类似: 应当避免让攻击者分辨出任何具体的个人数据
- 为此,差分隐私要求被发布的信息需经一个随机算法所处理, 且该随机算法会对信息做一些扰动
差分隐私的定义
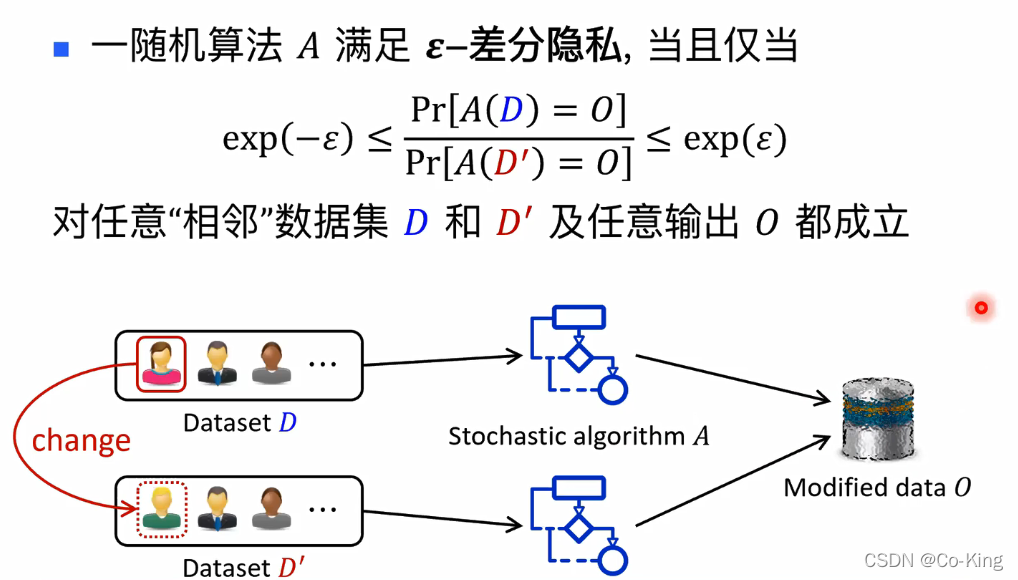
差分隐私定义的图示
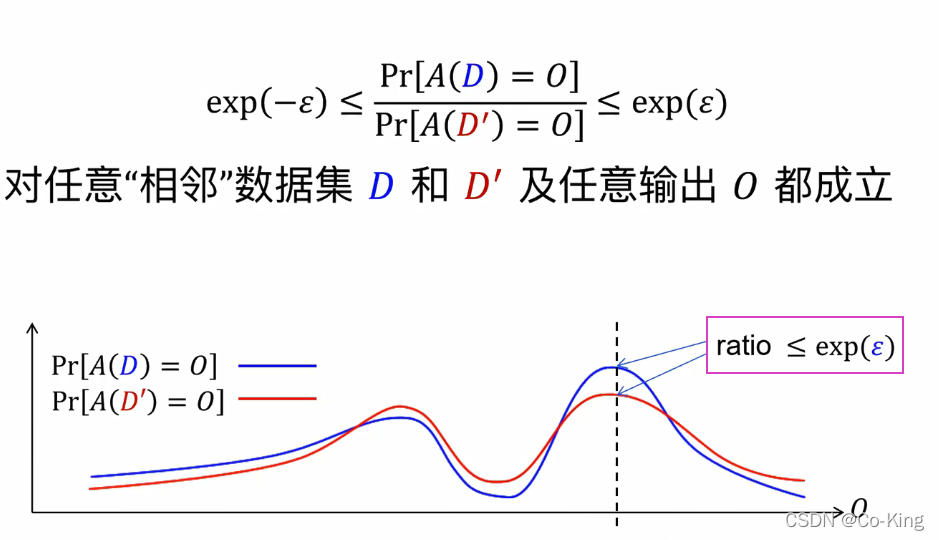
- 攻击者并不能观察到,某一个元素对结果输出的影响,从而保证了用户的隐私
差分隐私算法
如何设计满足差分隐私的算法

拉普拉斯机制




- 因为对个体依赖程度变为3了
敏感度

其他噪声机制

随机化回答
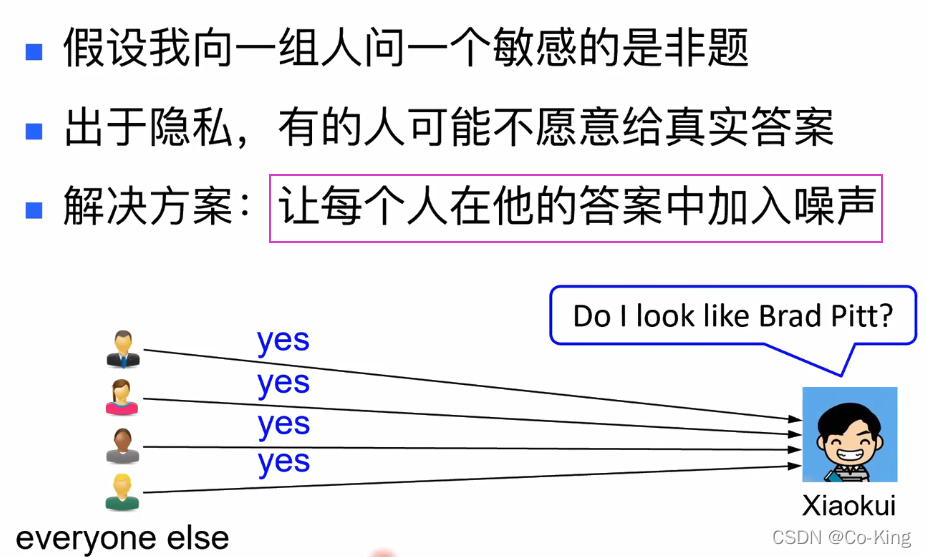

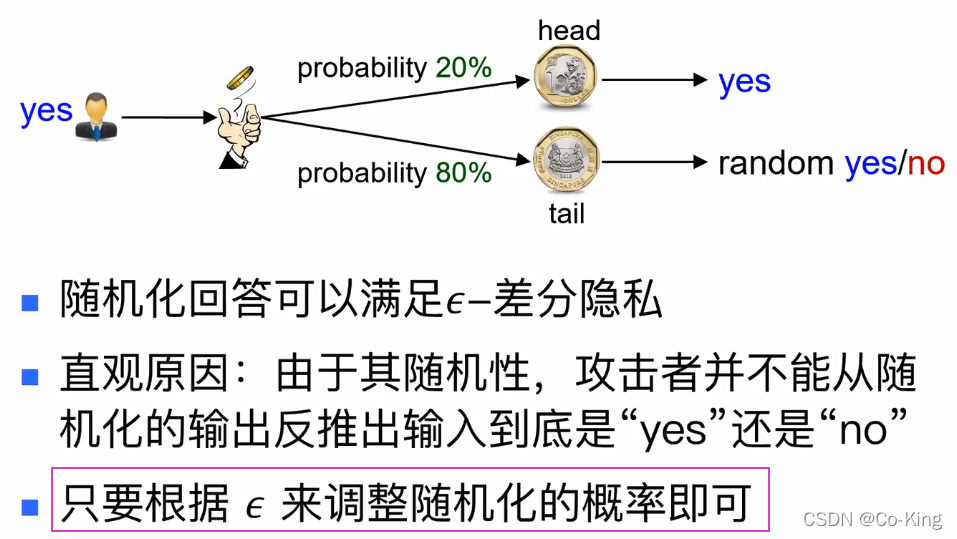
采用这一类随机方式进行估算的话,不会对原来真实的结果的估算产生重大影响吗?
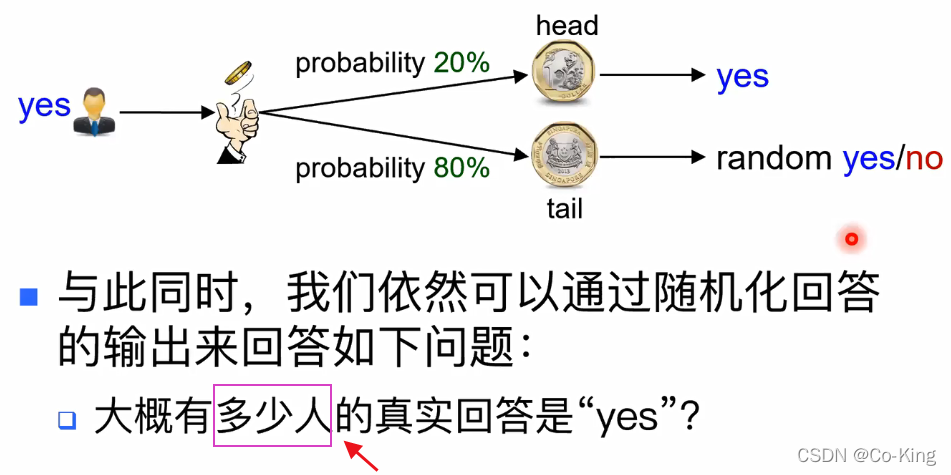
从随机化回答获得统计信息
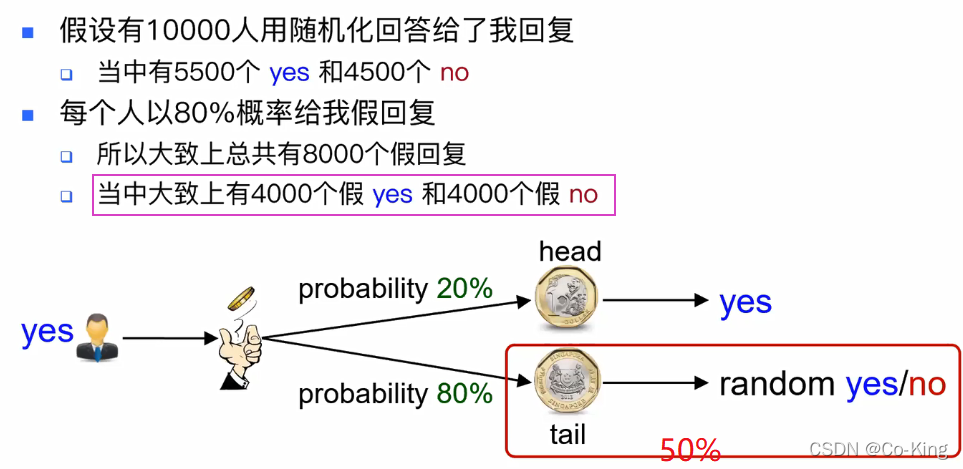

随机化回答:总结

只能推出有多少个是yes,有多少个是no,只能知道yes和no的比例,而不是知道具体谁投了yes,谁投了no
- 拉普拉斯机制和随机化回答是两个经典的差分隐私算法,还有许多其他不同的算法,一般而言,不同的应用场景、不同的数据集、不同的输出往往需要不同的算法设计,如何根据应用来设计差分隐私方法是不少领域的学者都感兴趣的问题
差分隐私:应用
差分隐私数据库
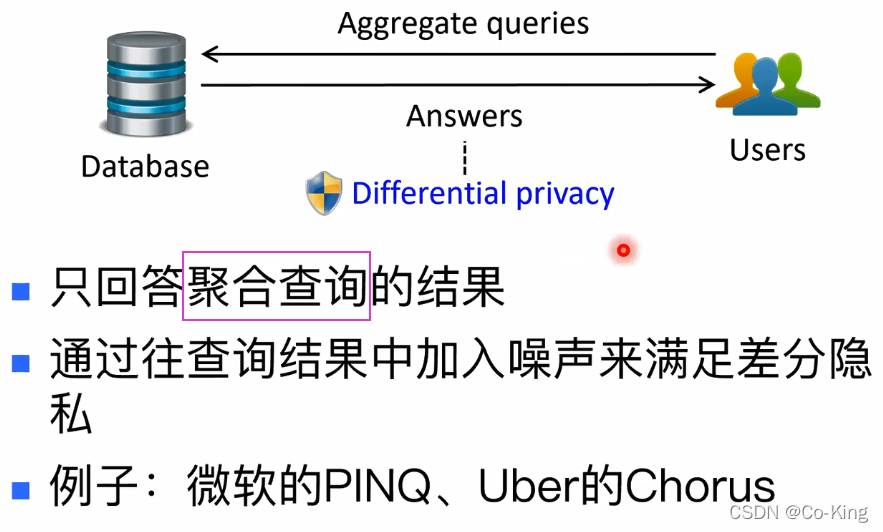
技术难点

差分隐私机器学习
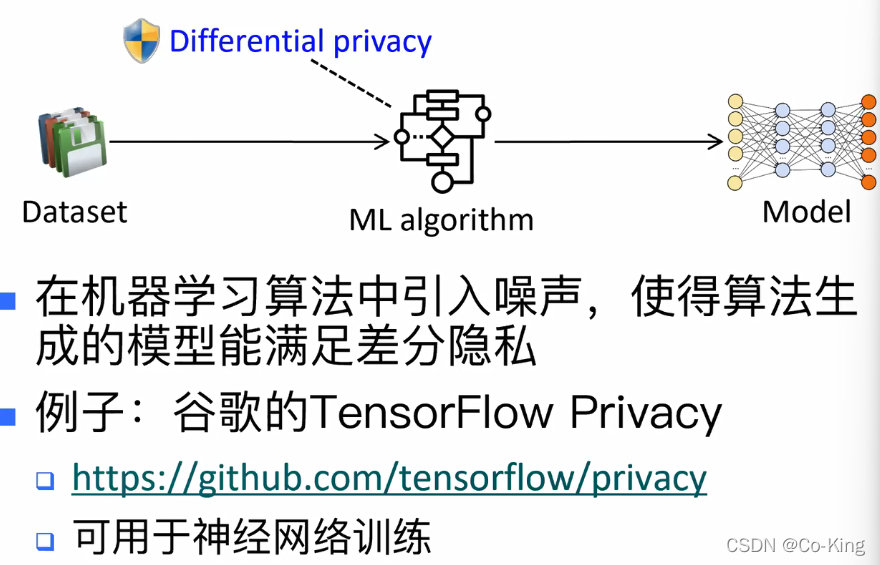
TensorFlow Privacy 的基本原理

差分隐私数据采集
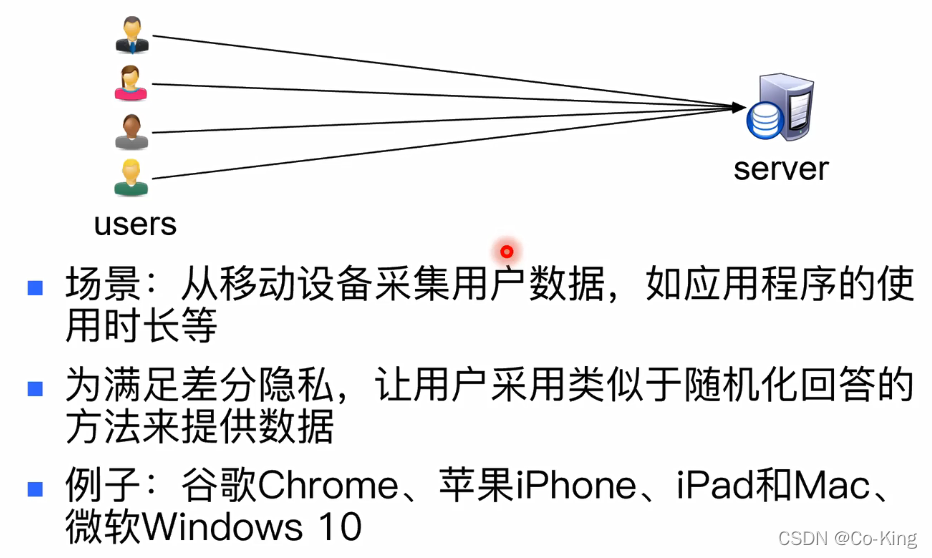
技术难点

差分隐私数据合成

技术难点

前景展望
差分隐私的新方向
- 联邦学习
- 与多方安全计算的结合
总结
- 差分隐私是近年来受到较多关注的一个隐 私保护模型
- 有着较强的理论保证,并在不少场景中得 到了应用
- 但仍有许多有待解决的问题















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









