






AI一天,人间一年。今天这期日报比较特别,又称特别加长版AI最新大事件合集,来看看昨晚到现在,大洋彼岸的AI卷王们又有哪些重要更新——
【1分钟速看版】
🎯 Claude 3.5 Sonnet推出Computer Use功能,可以像人一样使用计算机
🎨 Stable Diffusion 3.5全家桶上新,可免费商用
💥 Genmo发布 “最强开源视频生成模型”Mochi 1
🖼 Ideogram推出Canvas 画布、魔法填充和一键扩图功能
✨ Runway推出一键表情复制功能Act-One
🧠 Perplexity推出推理模式Reasoning Mode
👨 微软亚研院前首席研究经理谭旭加入月之暗面,研发类GPT-4o端到端语音模型
💰 OPPO收购大模型创业公司波形智能
📄 工信部赛迪研究院发布《AI搜索行业发展报告》
海外资讯
1. Claude 3.5 Sonnet推出Computer Use功能,可以像人一样使用计算机
北京时间10月23日凌晨,Claude发布重磅消息:升级版Claude 3.5 Sonnet和新模型Claude 3.5 Haiku来了,在编码和复杂推理方面变得更强了,甚至超过OpenAI的o1模型。

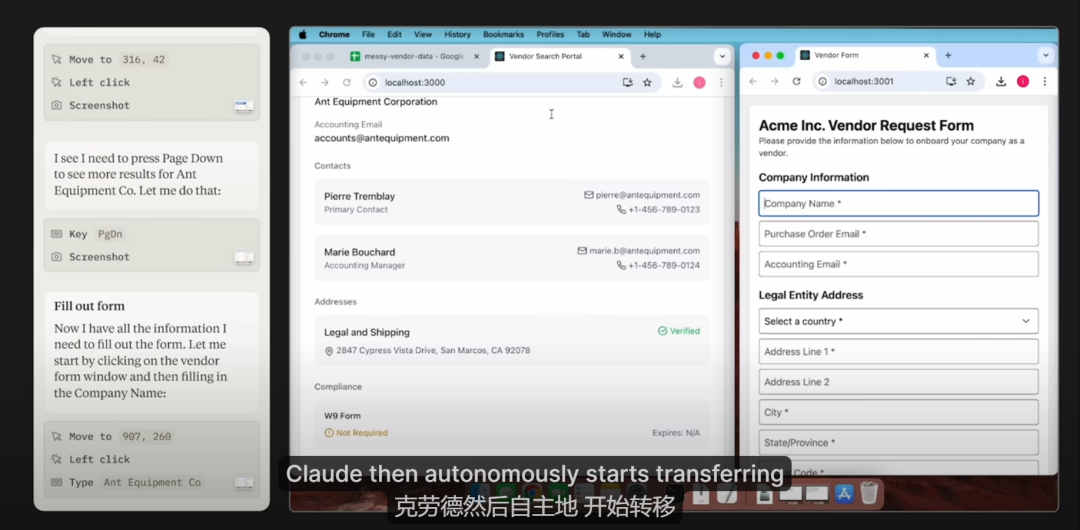
最大的亮点则是新功能Computer Use(计算机使用),顾名思义,这是让Claude像人一样使用计算机,比如查看屏幕、移动光标、单击按钮和输入文本。
据官方演示视频,当你在工作中需要填写一个供应商申请表时,Claude会根据指示自动截取屏幕,移动光标,在计算机上搜索对应的信息,找到分散在各个地方的数据后,它还会自主复制数据到表格里,最后提交表格。
 https://www.youtube.com/watch?v=ODaHJzOyVCQ
https://www.youtube.com/watch?v=ODaHJzOyVCQ
这就是真正的智能体吗?AI自动帮我打工指日可待就从今天开始!
Claude表示他们教AI通用的计算机技能,允许它使用为人类设计的各种标准工具和软件程序。从今天起,开发人员可以通过API使用Computer Use来自动化重复流程、构建和测试软件,以及开展开放式任务,例如研究。
部分企业Asana、Canva、Cognition、DoorDash、Replit和The Browser Company已经用上这项新功能,来执行需要数十步甚至数百步才能完成的任务了。
不过Claude 3.5 Sonnet目前处于公开测试阶段,Computer Use可能有时用起来很繁琐且容易出错,Claude会征求开发人员的反馈,迅速改进这项功能。
除了Computer Use,升级后的Claude 3.5 Sonnet也敢和OpenAI o1叫嚣了。
测试数据显示,Claude 3.5 Sonnet在编码任务SWE-bench Verified上的性能从33.4%提高到49.0%,得分高于所有公开可用的模型,包括OpenAI o1-preview。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

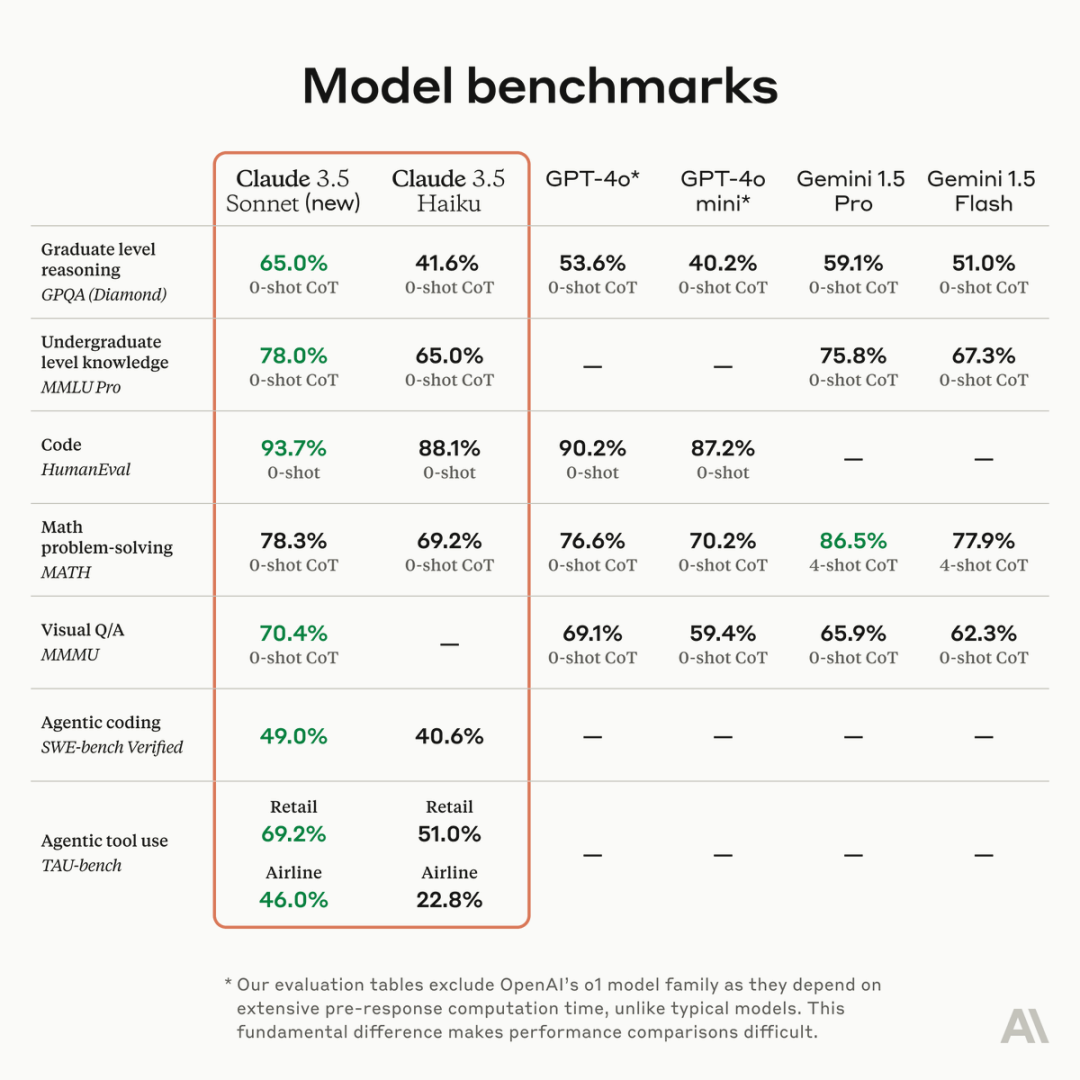
而Claude 3.5 Haiku的性能与之前最大的型号Claude 3 Opus相当,价格相同,速度与上一代Haiku相近。
目前升级版Claude 3.5 Sonnet已面向所有用户开放,Claude 3.5 Haiku将于本月晚些时候发布。
看来我们正在进入AI推理时代,以后AI都会主动干活了,那我岂不是可以提前退休 ……
……
Claude官网:
https://claude.ai/new
Claude官方博客:
https://www.anthropic.com/news/3-5-models-and-computer-use
Computer Use使用指南:
https://docs.anthropic.com/en/docs/build-with-claude/computer-use
2. Stable Diffusion 3.5全家桶上新,可免费商用

AI图像生成领域也有新模型发布:时隔4月,Stability AI带来Stable Diffusion 3.5全家桶,共有三个不同大小的开放版本——Large、Large Turbo和Medium,可在消费级硬件上运行。
官方称这是“迄今为止最强大的模型”,旨在满足科研人员、业余爱好者、初创企业和企业的多种需求。
Stable Diffusion 3.5 Large:拥有80亿个参数,质量卓越,响应迅速,是Stable Diffusion系列中最强大的型号,适合100万像素分辨率的专业用例。
Stable Diffusion 3.5 Large Turbo:Stable Diffusion 3.5 Large的精简版,仅需4个步骤即可生成高质量图像,且具有出色的提示依从性,速度比Large快得多。
Stable Diffusion 3.5 Medium(将于10月29日发布): 拥有25亿个参数,采用改进的MMDiT-X架构和训练方法,可在消费级硬件上“开箱即用”,在质量和定制易用性之间取得平衡。它能生成分辨率在0.25到200万像素之间的图像。
目前Large和Large Turbo版本可以从Hugging Face下载使用,并在GitHub上下载推理代码,Medium则将于10月29日发布。
根据最新的社区政策,Stable Diffusion 3.5支持免费用于商业和非商业用途,商用的话有一定限制,年总收入最高100万美元,超出100万美元需联系官方获得企业许可证。
那么Stable Diffusion 3.5到底表现如何呢?
官方称在多样性上做了优化,无需大量提示,就能生成不同肤色和特征的人像图片。

同时支持3D、摄影、绘画、线条艺术等多种视觉风格。

闻讯赶来的创作者们迅速在X上放出了第一波测试图,有没有惊艳到你呢——
 X@cubiq
X@cubiq
 X@cubiq
X@cubiq
 X@makeitrad1
X@makeitrad1
 X@ClaireSilver12
X@ClaireSilver12
拿Stable Diffusion 3.5 Large与FLUX1.1 [pro]对比来看,写实风格的建筑表现不错。

 X@markopolojarvi
X@markopolojarvi
提示词“Brutalist architecture in a lush jungle setting, juxtaposition of man-made and natural(葱郁丛林中的野蛮主义建筑,人工与自然的并置)”
我们也浅浅在Hugging Face上测了一下,发现手部生成效果还是有问题。

An orange cat dressed as a pumpkin for Halloween, bedroom background, horror atmosphere, realistic style, pet photography(万圣节打扮成南瓜的一只橘猫,卧室背景,惊悚氛围,写实风格,宠物摄影)

An old Asian woman looking at the camera, holding her face with her gnarled hands, with a sad expression, oil painting style(一位苍老的亚洲女性看着镜头,用粗糙的手托着脸,表情悲伤,油画风格)
StabilityAI官方博客:
https://stability.ai/news/introducing-stable-diffusion-3-5
Stable Diffusion 3.5在线使用:
https://huggingface.co/collections/stabilityai/stable-diffusion-35-671785cca799084f71fa2838
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
3. Genmo发布“最强开源视频生成模型”Mochi 1
今年AI视频生成领域突飞猛进,大部分产品都是闭源收费的,而就在今天凌晨,Genmo发布Mochi 1预览版,宣称是“最强开源视频生成模型”。

可能很多玩家对Genmo不太熟悉,Genmo是由伯克利大学AI博士和前谷歌研究员Paras Jain与Ajay Jain于2022年底创立的,创始人Ajay Jain是为当今图像生成模型奠定基础的三位伯克利研究人员之一。据官方介绍,他们的团队包括DDPM、DreamFusion和Emu Video的核心成员,可以说是全明星阵容。
在发布Mochi 1之前,去年Genmo已经推出了文生图模型、图生视频模型、3D生成模型、Genmo Chat、文生视频模型Replay等等,其Discord频道已有超6万名用户。
 https://discord.com/invite/genmo
https://discord.com/invite/genmo
Mochi 1预览版是Genmo首个开源视频生成模型,根据Apache 2.0许可,可供个人和商业使用。Genmo同时还宣布获得了2840万美元的A轮融资,由NEA领投。(怪不得舍得开源呢 偷笑.jpg)
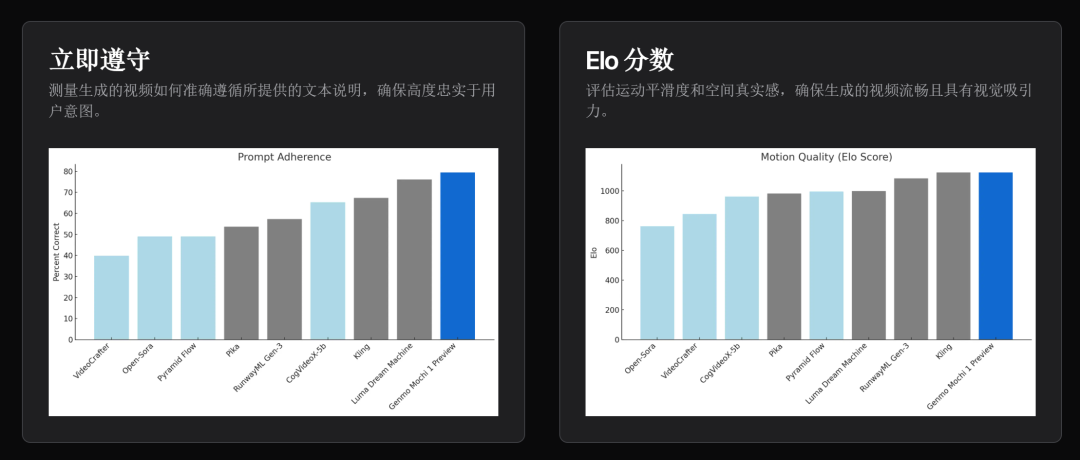
Mochi 1强在哪呢?官方强调了两个优势:高保真运动和出色的提示遵从。从测试数据来看,Mochi 1在这两方面都超越了Pika、可灵、Runway、Luma等领先的封闭模型。
提示遵从:Mochi 1表现出卓越的与文本提示的一致性,确保生成的视频准确反映给定的说明。允许用户对角色、设置和动作进行详细控制。按照OpenAI DALL-E 3中的协议,使用视觉语言模型作为判断标准,使用自动指标对提示遵从进行基准测试。使用Gemini-1.5-Pro-002评估生成的视频。
运动质量: Mochi 1以每秒30帧的速度生成流畅的视频,时长达5.4秒,具有高时间连贯性和逼真的运动动态。Mochi模拟流体动力学、毛发和头发模拟等物理现象,并表现一致、流畅的人类动作,这种动作能跨越恐怖谷。评分者被要求关注运动而不是帧级美学(标准包括运动的趣味性、物理合理性和流畅性)。根据LMSYS Chatbot Arena协议计算Elo分数。
目前Genmo仅放出了Mochi 1 480P基础版本,提供在线试用。完整版本包括Mochi 1 HD将在今年年底前发布,支持720P视频生成,具有更强的保真度和更流畅的动作,可以解决复杂场景中的扭曲等边缘情况。
 https://www.genmo.ai/play
https://www.genmo.ai/play
来看看新鲜的测试视频——
 史密斯吃面get√ X@noonescente
史密斯吃面get√ X@noonescente
 完美的蜜蜂飞行镜头 X@aziz4ai
完美的蜜蜂飞行镜头 X@aziz4ai

Against a rural landscape with Mexican volcanoes as a background, a panda bear drinking water from a transparent orange sports bottle(在以墨西哥火山为背景的乡村风景中,一只熊猫正在用透明的橙色运动水壶喝水)
难得的开源AI视频模型,由于高需求和服务器容量有限,现在官网的免费用户每天只能生成2个视频。
我们尝试生成了Sora同款狗狗打字视频,需要等待几分钟,提示遵从性一般,穿着不符,也没有出现打字的动作。

a computer hacker labrador retreiver wearing a black hooded sweatshirt sitting in front of the computer with the glare of the screen emanating on the dog’s face as he types very quickly.(一只身穿黑色连帽运动衫的拉布拉多猎犬坐在电脑前,电脑屏幕的强光照射在它的脸上,它飞快地打字)
简单的运动镜头相对稳定一些。

Fly through tour of a museum with many paintings and sculptures and beautiful works of art in all styles(飞越博物馆,参观众多绘画、雕塑和各种风格的精美艺术品)
Genmo官网:
https://www.genmo.ai/
Genmo官方博客:
https://www.genmo.ai/blog
Mochi 1下载:
https://github.com/genmoai/models
4. Ideogram推出Canvas画布、魔法填充和一键扩图功能
今天,Ideogram推出了Canvas无限创意画布,还新增了魔法填充(Magic Fill)和一键扩图(Extend)功能,支持API调用,但需要订阅才能使用。
Canvas是一个全新的AI原生设计界面,你可以上传图像或者直接在Canvas中生成图像,然后用Magic Fill和 Extend工具无缝地编辑、扩展或合成图像。
这有点类似于Figma和Canva等设计平台中的“自由画板”概念,但不同的是,Ideogram把AI生成元素和传统设计元素整合到了一起,比Midjourney等AI图像生成平台提供了更多灵活编辑的空间,在设计行业还是很有吸引力的。
根据官方Demo,Magic Fill可以在图片的特定区域替换对象、添加文本、修复瑕疵、更改背景等。可以将多张图片上传到画板上,然后使用Magic Fill将它们组合成一个统一的作品。
只需要选择要编辑的区域,根据需要调整生成窗口以聚焦于特定区域,输入文本提示进行引导即可。
Extend可以将图片扩展到原始边界之外,同时保持与原图风格一致。可以调整图像构图和纵横比以适应任何屏幕尺寸,而不影响原始内容。
5. Runway推出一键表情复制功能Act-One
以前,要想让一个虚拟角色表现出生动的情感,可能需要专业的动作捕捉设备、复杂的面部动画技术,还得经历繁琐的手动调整。
现在,只需要用你自己真实的面部表情作为参考,AI就能把你的每一个微表情、眼神甚至脸部肌肉的细微运动“复制”到虚拟角色身上。
这就是Runway最新推出的Act-One功能。
通过Act-One,用户可以用手机摄像头捕捉自己的面部表情,并将这些表情应用到任意虚拟角色脸上,这个过程不再需要昂贵的动作捕捉设备或复杂的面部绑定技术,就可以为虚拟角色注入逼真的情感和个性。
而且,Act-One支持捕捉极为细致的面部动画,从官方Demo来看,虚拟角色的微表情和眼神移动都栩栩如生。
对于独立电影制片人、游戏开发者和动画师来说,Act-One无疑极大简化了面部动画制作流程,降低了制作成本。而对于普通用户来说,则大大降低了动画制作的技术门槛。
值得一提的是,Runway内置了许多防止滥用的措施,比如防止未经许可生成公众人物的形象。
6. Perplexity推出推理模式Reasoning Mode
继OpenAI推出高级推理模型o1-preview和o1-mini,Kimi推出“探索版”后,10月23日,Perplexity也推出了推理模式(Reasoning Mode)。
这是一种旨在增强AI推理能力的新型交互模式,突破了传统基于信息检索的AI回答方式,能够通过综合多方面的信息进行深度分析与推理,从而生成更加复杂、准确的回答。
简单来说,在推理模式下,模型不仅仅是在“回答问题”,而是帮你进行深层次的思考和分析。
 Perplexity官网:https://www.perplexity.ai/
Perplexity官网:https://www.perplexity.ai/
下面让我们将视角转向国内AI界——
国内资讯
7. 微软亚研院前首席研究经理谭旭加入月之暗面,研发类GPT-4o端到端语音模型
10月23日,据“晚点Auto”报道,微软亚洲研究院前首席研究经理谭旭于8月加入大模型创业公司月之暗面,主要负责研发端到端语音模型。
报道称,月之暗面的整个多模态研究早在去年10月就已开始。接近月之暗面的知情人士称,目前有10人左右的团队在研发视频模型,为确保产品更具差异性,对外发布计划仍在推迟。
资料显示,谭旭在离开微软研究院前担任首席研究经理,方向是生成式AI、语音 / 音频 / 视频内容生成,论文引用量达上万次,他也曾担任NeurIPS等学术会议期刊的审稿人,多项语言、语音、音乐、视频生成成果已应用在Azure、Bing等微软的产品与服务中。
谭旭加入月之暗面后的主要目标之一,可能即是帮助月之暗面打造“类似GPT-4o”的语音体验。
此前,主流的语音方案是ASR(自动语音识别)+LLM(大语言模型)+TTS(语音合成):输入端识别语音、转化成文本;大模型处理内容生成新文本;文本合成为语音、最终输出。
但上述方案的不足在于机器响应时间较长、人类无法随时打断,与人类的自然聊天状态存在差距。相比之下,端到端省去了“语音转文字再转语音”的中间过程,可以压缩机器响应时间,人类也可随时打断机器。同时,端到端还可帮助改善“幻觉”,用户可立即打断输出并给出新的提示词。(来源:IT之家)
8. OPPO收购大模型创业公司波形智能
10月22日,据波形智能内部知情人士透露,该公司将被手机厂商OPPO收购,CEO姜昱辰将入职OPPO。“我们只是被收购,产品仍在正常运营,不是网传的关张。”上述人士表示。
天眼查APP显示,杭州波形智能科技有限公司成立于2023年,注册资本134万元,实缴资本24万元。2024年1月,波形智能完成千万元级Pre-A轮融资,由蓝驰创投领投,西湖科创投、蚂蚁金服董事长井贤栋等跟投。同期,波形智能发布自主研发中文创作垂域大模型“Weaver”,及由其驱动的面向用户写作类Agent产品“蛙蛙写作1.0”。(来源:界面新闻)
9. 工信部赛迪研究院发布《AI搜索行业发展报告》
近日,工信部赛迪研究院发布《AI搜索行业发展报告》,围绕核心竞争力、产品形态、搜索场景、核心用户人群、行业生态环境等角度,总结了AI搜索行业五大发展趋势。
该报告指出,简约化产品设计、一站式服务和多端一体能力迎来爆发,搜索场景趋向垂直化、专业化,具备系统级AI能力的PC端产品有望成为入口级应用。整体来看,AI搜索行业已进入高速发展期,未来随着新产品、新模式、新场景不断涌现,AI搜索行业将迎新一轮变局。

写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









