






在艺术创作中,保持人物角色的一致性至关重要。然而,如何从不同视角创造一致的人物角色往往是一项挑战。如今,借助Stable
Diffusion的ControlNet功能和InstantID插件,你可以轻松实现这一目标。本文将带你深入了解如何使用InstantID插件,实现人物角色的一致性。

Stable
Diffusion是一款基于深度学习的图像生成模型,它能够在没有任何人类指导的情况下生成高质量、逼真的图像。与传统的图像生成技术相比,Stable
Diffusion具有更高的生成质量和更快的生成速度。
一.InstantID介绍
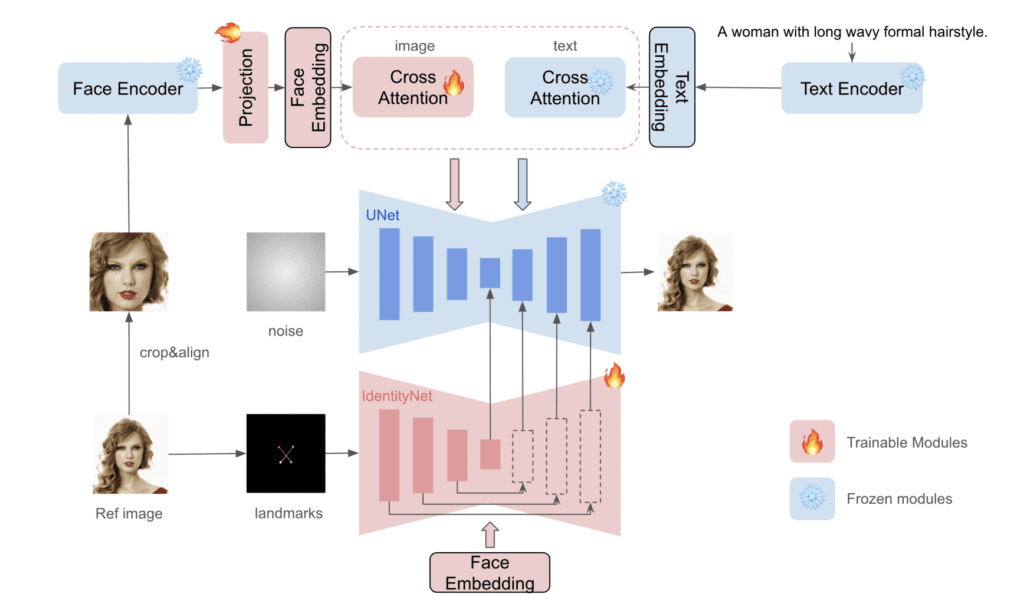
InstantID 使用 InsightFace 从参考人脸中检测、裁剪和提取人脸embedding 。然后embedding与 IP-
Adapter一起使用来控制图像生成。这部分与 IP-Adapter Face ID 非常相似。不过,它还使用 ControlNet
检测并修复多个面部标志(眼睛、鼻子和嘴巴)。
结合使用IP-Adapter Face ID 和 ControlNet,可以高保真度地复制我们提供的参考图像,从而最终实现人物角色的一致性。
注意:InstantID需要使用SDXL大模型,目前还没有Stable Diffusion 1.5对应的版本。
二.InstantID插件的安装
首先将controlnet升级到最新的版本,最好是在V1.1.440版本及以上。
下载InstantID的IP-adapter模型。
(相关模型插件及安装包文末可自行扫描获取)
将下载的文件重命名为ip-adapter_instant_id_sdxl.bin。
下载 InstantID ControlNet模型。
(相关模型插件及安装包文末可自行扫描获取)
将下载的文件重命名为control_instant_id_sdxl.safetensors。
将上面下载下来的2个文件都放在stable-diffusion-webui > models >
ControlNet文件夹目录下。具体情况大家可以按照自己的目录来。
然后重启我们的SD工具,可以看到在控制选项中多了一个Instant_ID选项,表示InstantID安装好了。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

三.InstantID插件在SD 1.5中的使用
使用InstantID模型时需要注意一些事项:
-
大模型只能使用SDXL大模型
-
提示词引导系数 (CFG Scale)要比通常设置的参数值低(3-5)
-
需要使用2个ControlNet作为InstantID
-
减少两个ControlNet的控制权重(Control Weights)和引导终止时机(Ending Control Steps)
下面我们来具体体验一下InstantID插件的使用。
【第一步】:大模型的选择
这里我们使用Dreamshaper SDXL Turbo大模型。VAE大模型选择None。

【第二步】:提示词的编写
正向提示词:
Prompt:watercolors portrait of a woman (happy
laughing:1.15),masterpiece,artistry,提示词:一个女人的水彩肖像(快乐地笑:1.15),杰作,艺术
反向提示词:
Prompt:low quality, blurry, malformed, distorted
提示词:低质量、模糊、畸形、扭曲
文生图相关参数设置
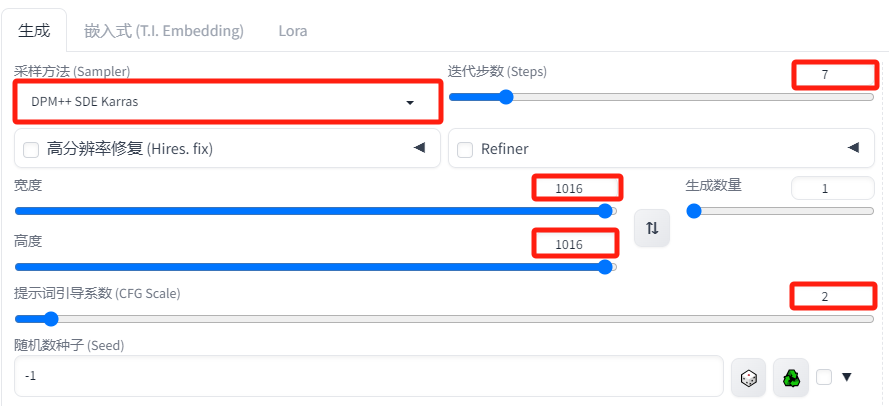
-
采样器:DPM++SDE Karras
-
采样迭代步数:7
-
图片宽高:1016*1016 (默认图像尺寸 1024×1024 不适用于 Instant ID。使用接近但不完全是 1024×1024 的分辨率)。
-
提示词引导系数(CFG):2(CFG 比例必须设置得相当低,InstantID 才有效)
【第三步】:ControlNet插件InstantID模型设置
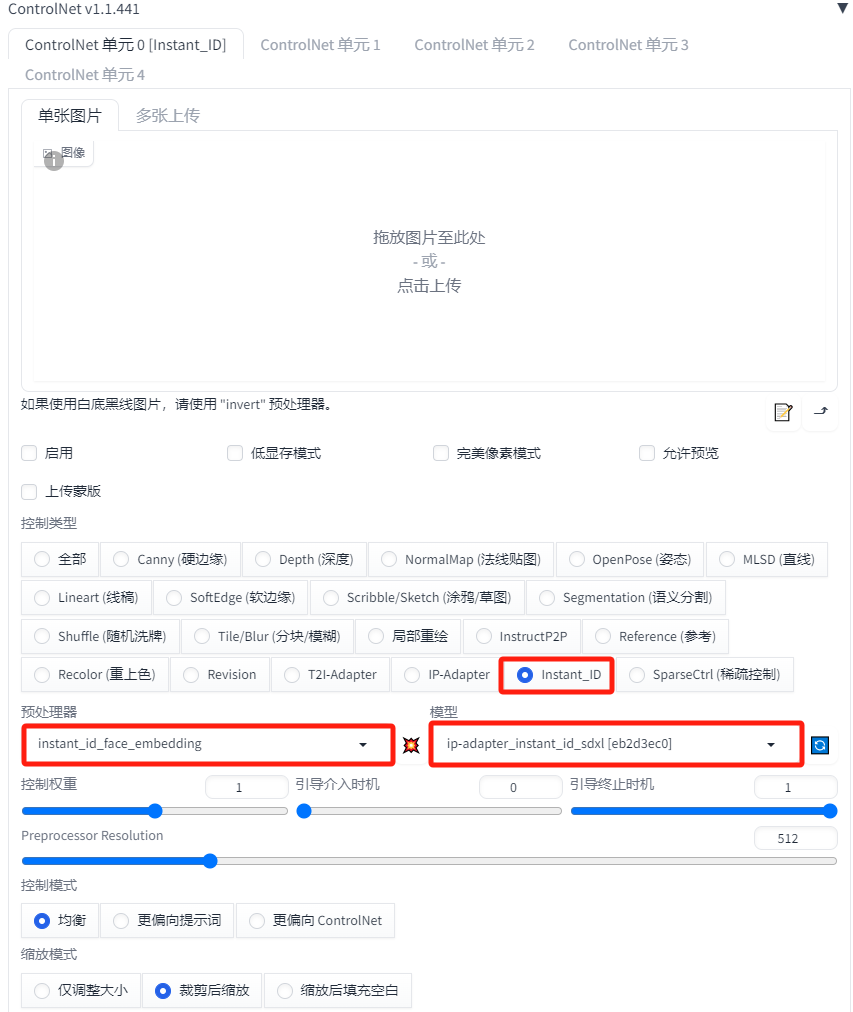
需要使用两种 InstantID 模型。换句话说,需要使用两个ControlNet。
ControlNet单元0设置
第一个ControlNet主要使用InsightFace来提取人物的面部特征。
这里我们使用紫霞仙子的图片作为参考图像。
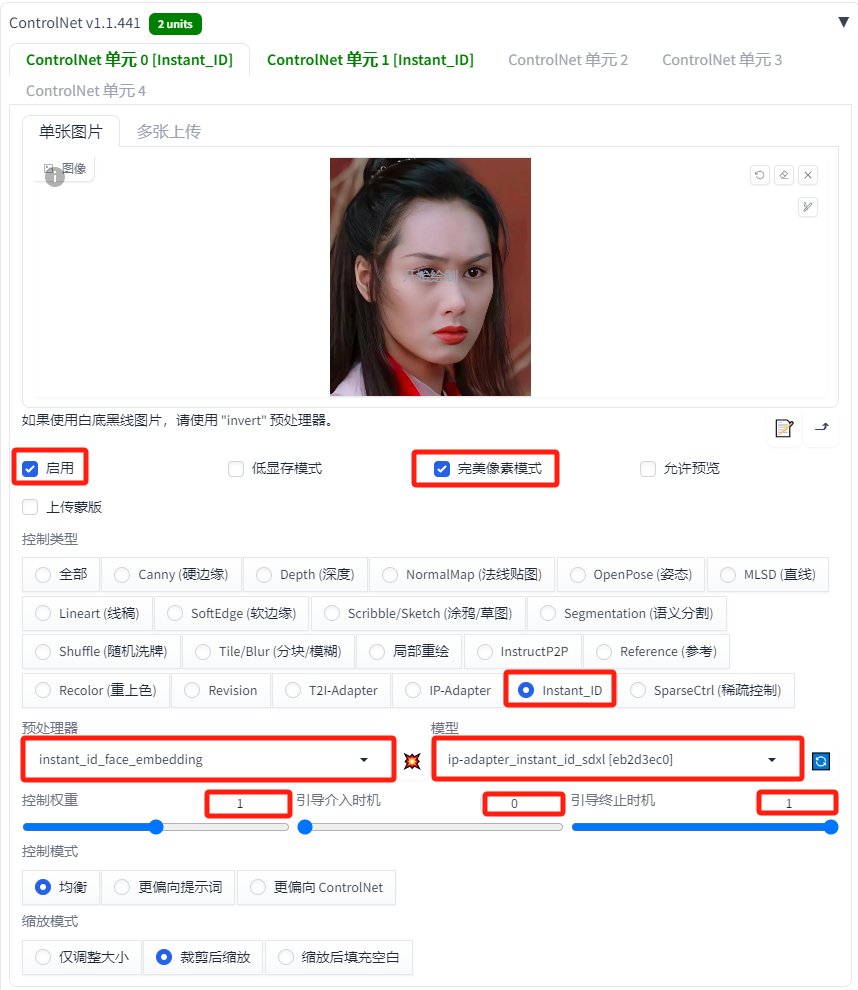
-
启用:选中
-
完美像素模式:选中
-
控件类型:Instant_ID
-
预处理器:instant_id_face_embedding
-
模型:ip-adapter_instant_id_sdxl
-
控制权重:1
-
引导介入时机:0
-
引导终止时机:1
ControlNet单元1设置
第二个ControlNet用于提取面部关键点,例如眼睛、鼻子和嘴巴的位置。您可以使用不同的图像,但建议使用相同的图像。这里我们仍然使用第一个ControlNet上传的图片。
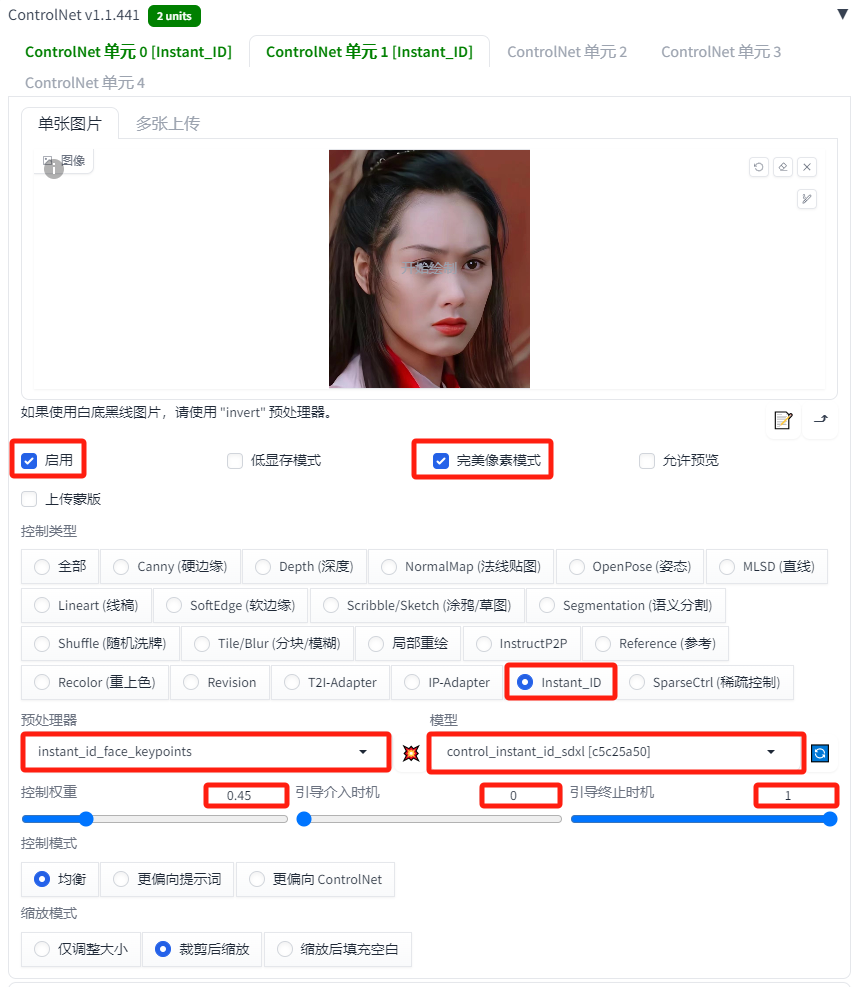
-
启用:选中
-
完美像素模式:选中
-
控件类型:Instant_ID
-
预处理器:instant_id_face_keypoints
-
模型:control_instant_id_sdxl
-
控制权重:0.45
-
引导介入时机:0
-
引导终止时机:1
【第四步】:生成图片
点击【生成】按钮,最终生成的图片效果如下。


四. 图片 风格样式****
图片的风格样式是由提示词来控制。您可以使用SDXL的提示词优化图片的展示内容和背景元素。
1. 人物肖像
Prompt :high quality,masterpiece,rich details,realistic
photography,8k,high-definition image quality,portrait of a woman,(happy laughing:1.15),
提示词 :高品质,杰作,细节丰富,摄影逼真,8k,高清画质,
一个女人的肖像,(快乐地的笑:1.15),


2. 赛博朋克风格
Prompt :high quality,masterpiece,rich details,realistic
photography,8k,high-definition image quality,Cyberpunk style,portrait of a woman,(happy laughing:1.15),
提示词 :高品质,杰作,细节丰富,摄影逼真,8k,高清画质,
赛博朋克风格,一个女人的肖像,(快乐的笑:1.15),

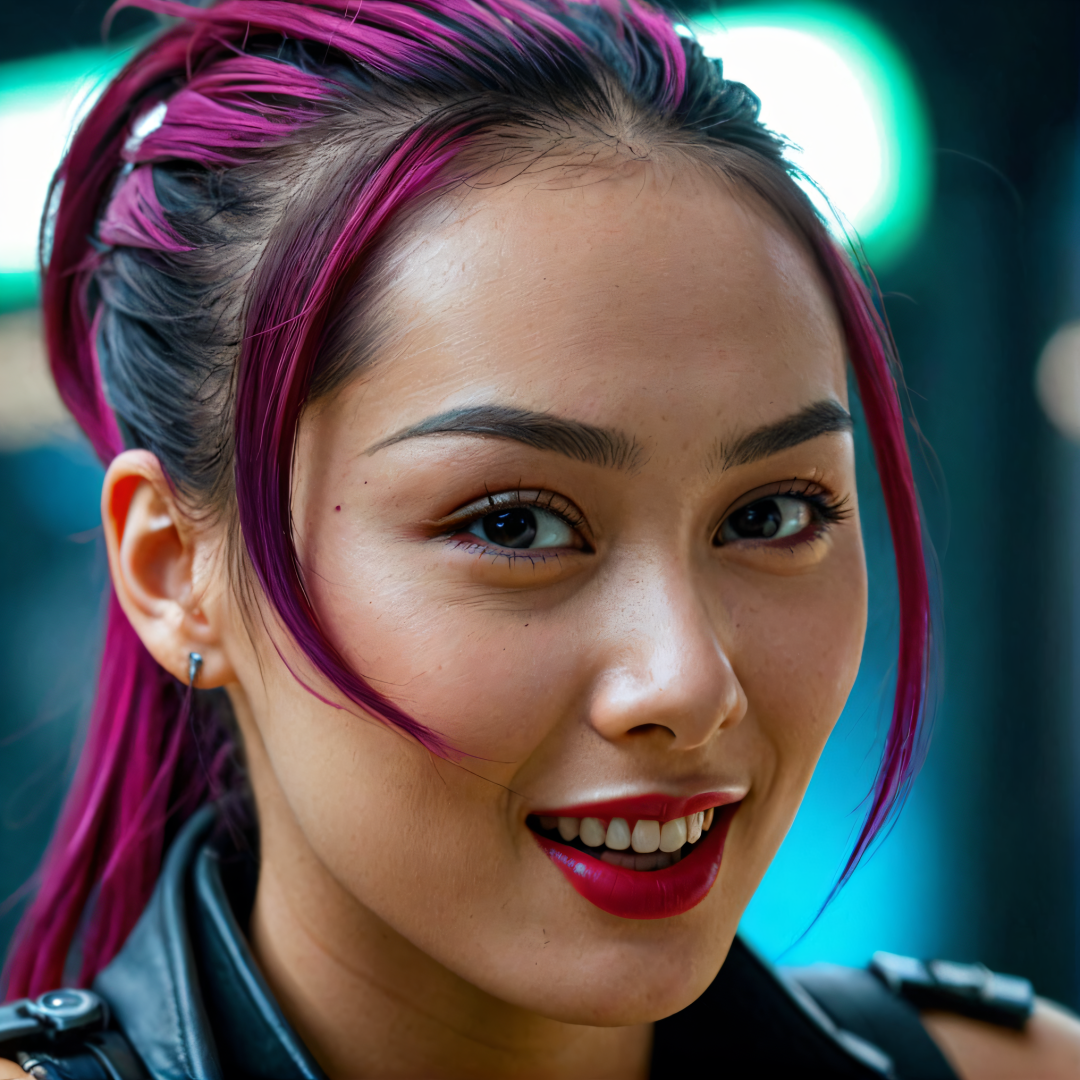
3. 线条艺术风格
Prompt :high quality,masterpiece,rich details,realistic
photography,8k,high-definition image quality,line art style,portrait of a woman,(happy laughing:1.15),
提示词 :高品质,杰作,细节丰富,摄影逼真,8k,高清画质,
线条艺术风格,一个女人的肖像,(快乐的笑:1.15),


这里的测试示例中,我改变了原图片中的人物表情(微笑),总体来看,Instant_ID插件在实现人物换脸保持人物角色一致性上还是不错的。
写在最后
全套AI实用插件已打包,有需要的小伙伴可以自取,无偿分享。


AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
若有侵权,请联系删除

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









