









当前流行的数据流计算平台是twitter的storm,yahoo的s4等, 这些流计算平台采用record-at-a-time模型: 记录流式达到计算节点, 计算节点依据当前记录进行一定计算,更新节点内部状态,最后输出新记录给下游计算节点。 record-at-a-time模型存在如下问题:
• 故障处理不足。 有复制和数据回放两种容错方式, 但是这两种方式各有不足。 复制方法消耗两倍资源, 且不能容忍两节点同时故障。 数据回放方法处理故障的方式是, 备份节点回放数据, 重构故障节点的状态, 数据恢复过于慢是这种方法的主要缺点。
• 慢节点的影响。 流处理速度受限于最慢节点, 当集群增加到一定规模时, 慢节点出出现概率较大, 最终拖慢整体集群整体处理速度。
• 一致性。 每个计算节点独立工作, 找不到全局一致点。 比如说, 一个节点计算UV,另一个计算PV, 由于节点按照各自的节奏处理数据, 输出的UV和PV并不对应到同一时刻。
• 实时计算和离线计算不统一。 实时计算和离线数据两套代码,两套实现, 开发和维护代价高。 数据也无法打通, 离线和实时难以实现联合计算。
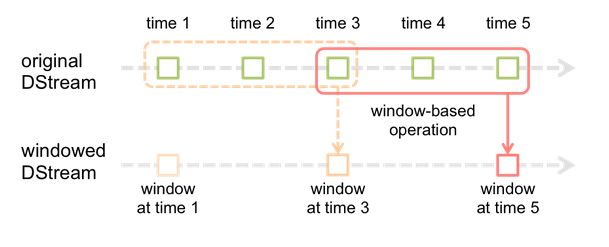
Spark Streaming的提出就是为了解决这些问题。 如上图所示, 它的数据模型是D-Stream, 按照时间(比如1秒)切分数据流为连续的小批量数据, 每批数据都是Spark中 的RDD结构。 在D-Stream模型下, 数据流处理就转换为针对连续RDD的数据处理。
先来看一段word count例子:

// 每个1秒产生1个RDD
val ssc = new StreamingContext(sc, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream(“localhost”, 9999)
// Split each line into words
val words = lines.flatMap(_.split(” “))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
wordcount例子非常简洁,与普通spark程序差别不大, 运行效果是每隔1秒输出这1秒内出现的词及其出现次数。 可以看到D-Stream支持RDD常见操作, 比如map/groupby/reduce等,这些操作作用于D-Stream下面的每个RDD, 将一个D-Stream转换为新的D-Stream。
除此之外, spark streaming 窗口计算操作符, 譬如countByWindow/reduceByKeyAndWindow等, 这些操作符作用于一个滑动窗口内所有RDD。 基于窗口计算操作符, 我们很容易算出过去任意时间段内的wordcount结果。
流计算很多时候依赖全局状态, spark streaming在这方面也提供了支持。 updateStateByKey操作为每个key维护和更新全局状态, 状态可以是任意类型, updateStateByKey会根据前序状态和业务自定义函数维护全局状态, 其典型的应用场景是用户session分析。 全局状态依赖于D-Stream当前RDD以及前一个全局状态计算得开, 因此计算的开销较大, 尽量避免维护大量全局状态。
D-Stream模型的优点
• 延时较低。 RDD模型支持单副本内存存储, 支持较大吞吐率和较低的延迟, D-Stream能做到亚秒级延迟。
• 容错较强。 record-at-a-time模型容错不足的根本问题在于计算状态和计算本身的耦合, spark streaming做的是把状态和计算本身分离, 使得计算本身无状态, 增强计算弹性。 RDD模型基于血缘关系保证数据可恢复, 正常运行时不需要投入冗余资源, 出现故障时, spark steaming可利用整个集群资源并行恢复数据, 恢复速度快。 此外, 亦不用担心慢节点拖慢在整个集群, 因为无状态计算是可复制的, 通过复制计算到多个节点, 慢节点问题迎刃而解。
• 一致性保证。 D-Stream每个RDD代表某段时间内所有的数据, D-Stream上各种计算结果都针对相同快照, 保证exact-once语义。
• 离线处理和实时处理深度融合。 实时的spark streaming和离线spark计算使用相同的数据模型, 具有互操作性。 (1) spark streaming实时处理可以直接利用到离线计算出来的结果。 (2) 可在历史数据之上跑实时计算程序, 在历史数据基础上也能做数据流计算。(3)实时数据库流支持交互式查询, 方面诊断问题。
总结
spark streaming以小批量计算方式解决数据流计算问题, 相比record-at-a-time模型改进了容错性和一致性, 而最重要的是, 实时计算、离线计算、交互式计算可融为一体, 大幅降低开发和维护代价。 小批量方式势必带来更多延迟, 不过streaming号称能做到亚秒级延迟。 若果真能如此,应用场景非常广泛。















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









