







一、问题背景
数字支付正在发展,但网络犯罪也在发展。电信诈骗案件持续高发,消费者 受损比例持续走高。报告显示,64%的被调查者曾使用手机号码同时注册多个账 户,包括金融类账户、社交类账户和消费类账户等,其中遭遇过电信诈骗并发生 损失的比例过半。用手机同时注册金融类账户及其他账户,如发生信息泄露,犯 罪分子更易接管金融支付账户盗取资金。随着移动支付产品创新加快,各类移动支付在消费群体中呈现分化趋势,第三方支付的手机应用丰富的场景受到年轻人群偏爱,支付方式变多也导致个人信息也极易被不法分子盗取。根据数据泄露指数,每天有超过 500 万条记录被盗,这一令人担忧的统计数据表明 对于有卡支付和无卡支付类型的支付,欺诈仍然非常普遍。在今天的数字世界,每天有数万亿的银行卡交易发生,检测欺诈行为的发生 是一个严峻挑战。
二、问题分析
问题属于二分类问题,数据共有七个特征和一列类标签,
➢ distance_from_home:银行卡交易地点与家的距离;
➢ distance_from_last_transaction:与上次交易发生的距离;
➢ ratio_to_median_purchase_price:近一次交易与以往交易价格中位数的比率;
➢ repeat_retailer:交易是否发生在同一个商户;
➢ used_chip:是通过芯片(银行卡)进行的交易;
➢ used_pin_number:交易时是否使用了 PIN 码;
➢ online_order:是否是在线交易订单;
➢ fraud:诈骗行为(分类标签);
三、代码
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
import re
import pandas as pd
from catboost import CatBoostRegressor
import lightgbm as lgb
import xgboost as xgb
import numpy as np
from sklearn.metrics import roc_auc_score, precision_recall_curve, roc_curve, average_precision_score
from sklearn.model_selection import StratifiedKFold,KFold
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
train = pd.read_csv('./card_transdata.csv')
# 查看数据的基本信息
train.info()
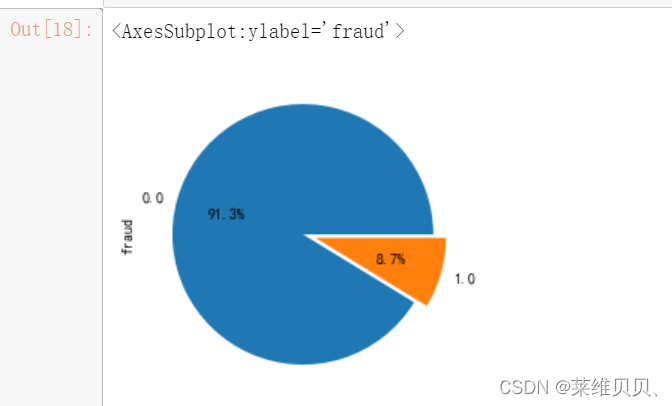
# 标签比例
train['fraud'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%')
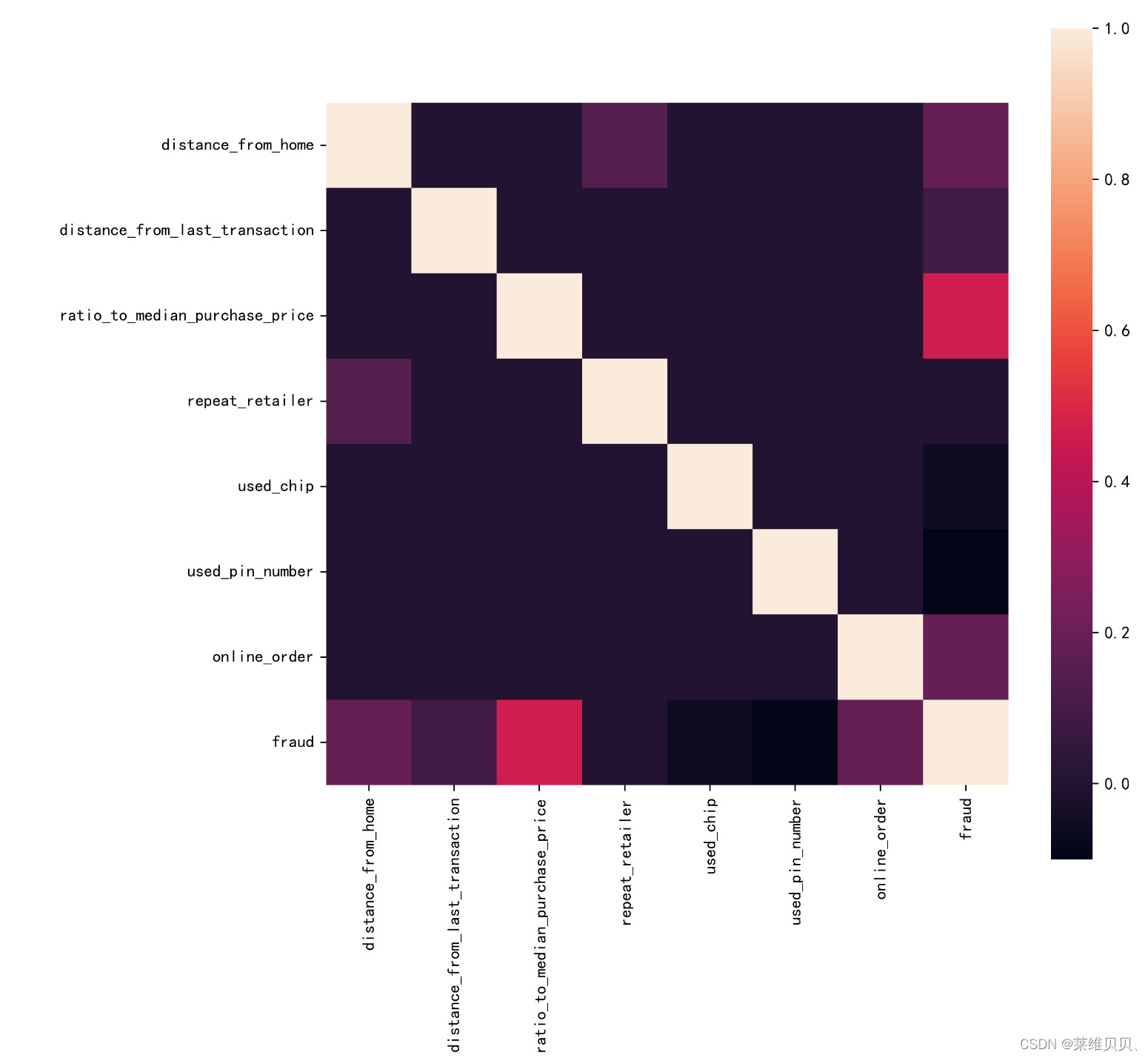
# 变量之间的相关性
plt.subplots(figsize=(9,9),dpi=1080,facecolor='w')# 设置画布大小,分辨率,和底色
sns.heatmap(train.corr(),annot=False, vmax=1, square=True, fmt='.2g')#annot为热力图上显示数据;fmt='.2g'为数据保留两位有效数字,square呈现正方形,vmax最大值为1
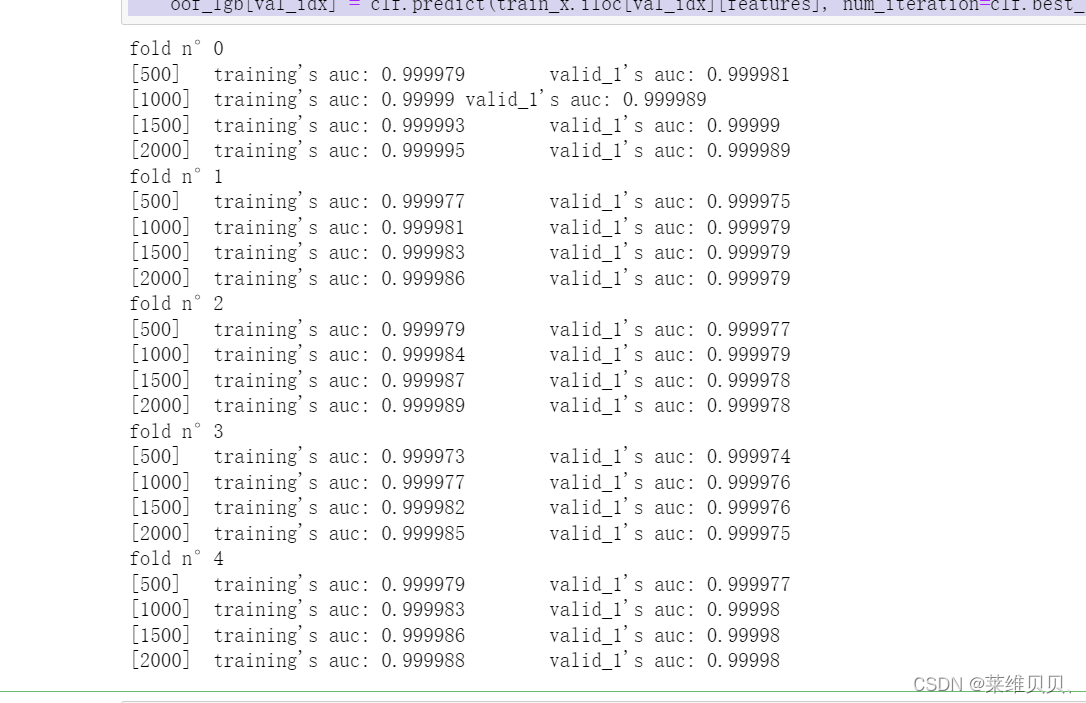
# 五折交叉验证
features = [i for i in train.columns if i not in ['fraud']]
train_x = train
train_y = train['fraud']
# 开始训练
KF = StratifiedKFold(n_splits=5, shuffle=True, random_state=2021)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'auc'},
'num_leaves': 32,
'max_depth': 5,
'learning_rate': 0.01,
'feature_fraction': 0.8, # 建树的特征选择比例
'bagging_fraction': 0.75, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'lambda_l2': 1, # 越小l2正则程度越高
"verbose": -1,
}
oof_lgb = np.zeros(len(train_x))
for fold_, (trn_idx, val_idx) in enumerate(KF.split(train_x.values, train_y.values)):
print("fold n°{}".format(fold_))
trn_data = lgb.Dataset(train_x.iloc[trn_idx][features], label=train_y.iloc[trn_idx])
val_data = lgb.Dataset(train_x.iloc[val_idx][features], label=train_y.iloc[val_idx])
num_round =2000
clf = lgb.train(
params,
trn_data,
num_round,
valid_sets=[trn_data, val_data],
verbose_eval=500,
)
oof_lgb[val_idx] = clf.predict(train_x.iloc[val_idx][features], num_iteration=clf.best_iteration)
4. 总结
这题唯一好的是数据量组,可以得到充分训练,无需进行特征交叉就接近满分!!!!!!!!!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









