







KNN算法介绍(最邻近规则分类算法)
1.1 Cover和Hart在1968年提出了最初的邻近算法
1.2
分类(classification)算法
1.3 输入
基于实例的学习(instance-based learning),
懒惰学习(lazy learning)
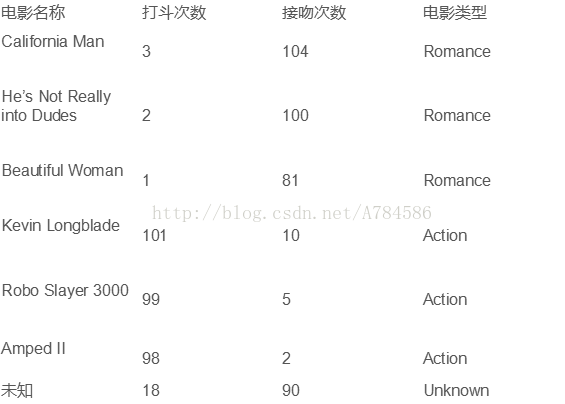
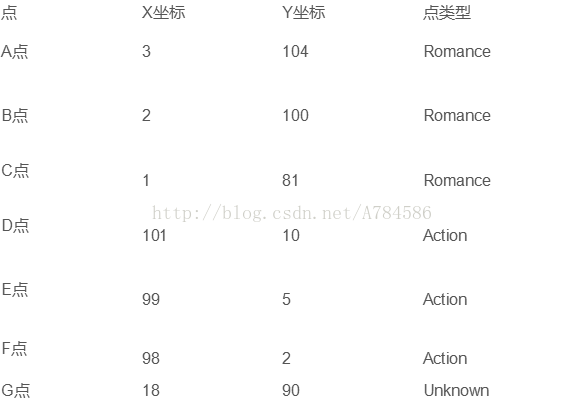
未知电影属于什么类型?将样例坐标化;
3. 算法详述
3.1 步骤:
为了判断未知实例的类别,以所有已知类别的实例作为参照
选择参数K
计算未知实例与所有已知实例的距离
选择最近K个已知实例
根据少数服从多数的
投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
3.2 细节:
关于K
关于距离的衡量方法:
3.2.1
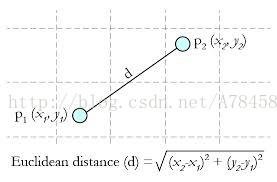
Euclidean Distance 定义
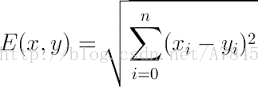
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
3.3 举例:
K的选取至关重要,如下图,选K=1,位置绿色点则属于正方形,K=4,则属于三角形;
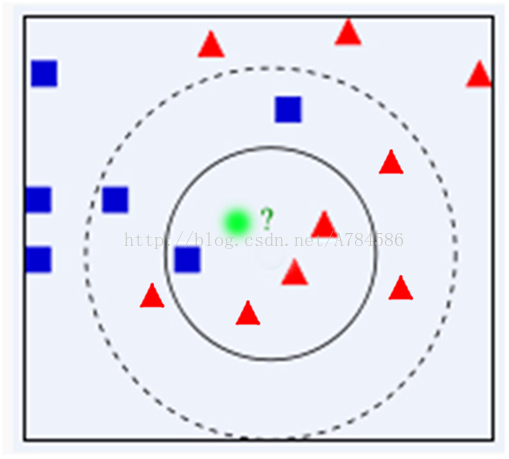
4. 算法优缺点:
4.1 算法优点
简单
易于理解
容易实现
通过对K的选择可具备丢噪音数据的健壮性
4.2 算法缺点:
下图中分布不均,蓝色点占主导地位,K取K=13时,影响了Y点的预测。
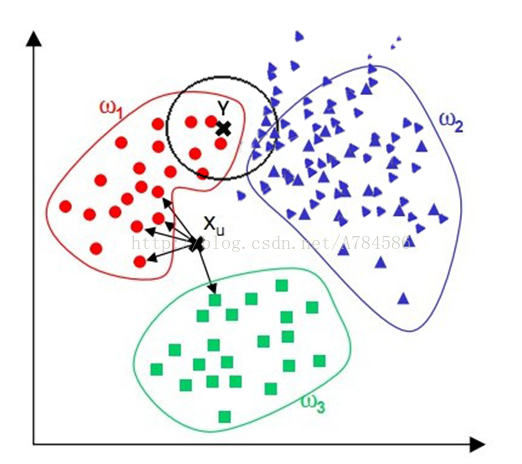
需要
大量空间储存所有已知实例
算法复杂度高(需要比较所有已知实例与要分类的实例)
当其
样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并没接近目标样本。
5. 改进版本
考虑距离,
根据距离加上权重
比如: 1/d (d: 距离)















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









