









上面内容介绍了Eureka并写了demo案例,这篇继续深入研究一下它。
一:高可用的Eureka Server
Eureka Server 即服务的注册中心,在上篇的案例中,我们只有一个Eureka Server ,事实上EurekaServer也可以是一个集群,形成高可用的Eureka中心。
服务同步:
多个Eureka Server之间也会互相注册成服务,当服务提供者注册到Eureka Server集群中的某个节点时,该节点会把服务的信息同步到集群中的每个节点,从而实现数据同步。因此,无论客户端访问到EurekaServer集群中的任一个节点,都可以获取到完整的服务列表信息。
我们接着上篇博客的内容(博文地址)来演示注册中心集群相互注册的场景,当然我们这边并不是真正的集群,只是模拟,效果是一样的。
1:启动一个Eureka Server服务,服务的配置如下:
spring:
application:
name: eureka-server
server:
port: 8010
eureka:
client:
service-url:
defaultZone: http://localhost:8009/eureka/
instance:
prefer-ip-address: true
instance-id: 127.0.0.1:8010注意!这里和之前比做了一些改动,就是注册的地址变了(端口号变了),defaultZone的属性变了,因为我们这一次不是自己注册自己而是向另外一个注册中心注册自己。改好之后我们启动,会一直报如下错,这是正常的,因为我们8009端口 的注册中心还没启动,当前注册中心一直在尝试注册不成功。
com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
************************************
com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: connect
******************************2:我们在idea中再配置一个启动服务。注意我们只是再配置一个启动服务,但是代码我们还是使用的同一个eurekaserver模块的代码。

只是把图中的Eureka Server注册中心配置两个启动服务。
1)在idea中右上角找到如下内容,点击Edit Configurations.....。
2)点进去之后我们发现这里显示了我本地配置了四个启动服务,EurekaApplication-1是我刚才启动的服务。

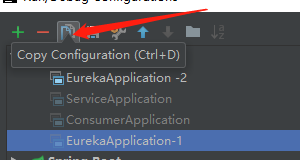
复制之后命名为EurekaApplication-2,看下,启动类配置都是同一个:
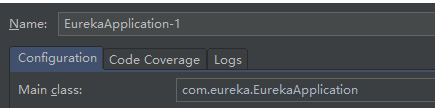
我们刚才用EurekaApplication-1启动了一个服务,我们把配置文件改一下,再用EurekaApplication-2启动一下:
spring:
application:
name: eureka-server
server:
port: 8009
eureka:
client:
service-url:
defaultZone: http://localhost:8010/eureka/
instance:
prefer-ip-address: true
instance-id: 127.0.0.1:8009
我们访问一下服务:


3:启动了两个Eureka注册中心,我们就需要把Eureka客户端注册到这里,注册多个EurekaServer需要用逗号隔开。
生产者producer模块配置如下:
eureka:
client:
service-url:
defaultZone: http://localhost:8010/eureka/,http://localhost:8009/eureka/
instance:
prefer-ip-address: true
instance-id: 127.0.0.1:8011
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/db_1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
application:
name: eureka-service.producer
server:
port: 8011
mybatis:
type-aliases-package: com.eureka.entity
消费者consumer模块的配置如下:
server:
port: 8012
eureka:
client:
service-url:
defaultZone: http://localhost:8010/eureka/,http://localhost:8009/eureka/
instance:
prefer-ip-address: true
instance-id: 127.0.0.1:8012
spring:
application:
name: eureka-service.consumer我们两个注册中心之间会同步数据,原则上来说我们客户端也可以只向一个注册中心(EurekaServer)注册即可,但是我们并不能保证我们只注册的那一个EurekaServer还活着,所以最好是每个EurekaServer都配置上去。这样即时某个服务挂了也没事。
同样的,如果我们的注册中心(EurekaServer)超过了两个,这三个注册中心也需要都互相注册。
上面配置完,我请求我们consumer是能够正常访问的,即时我们停掉注册中心(EurekaServer)中的其中一个服务,也是可以正常访问的。假如我们停掉EurekaApplication-2这个启动服务。这个EurekaApplication-1就会报错,因为注册找不到服务了。

但是这个时候我们访问consumer,还是能够得到结果的。

二:关于时长配置属性
服务注册:
从上篇demo实践中,可以看出,无论注册中心还是服务的消费者或生产者都会在本身服务启动的时候去注册中心注册自己,包括注册中心自己。
这是因为服务在启动时候都会检查一个属性配置:
eureka:
client:
register-with-eureka: true如果这个属性设置为true,服务注册中心也会将自己作为客户端来尝试注册自己,为true(默认)时自动生效。我们从
所以一般情况下,当我们设置服务为注册中心时,需要关闭它,如果要做集群的话,需要在做注册中心集群的时候,register-with-eureka必须打开,因为需要进行相互注册,不然副本无法可用。就像我们上面的启动两个注册中心一样,默认都是会注册自己,页面上显示了两个EurekaServer服务。
服务续约:
在注册完成之后,服务提供者会维持一个心跳(定时向EurekaServer发起Rest请求),告诉EurekaServer自己还活着,我们称这为服务的续约(renew):
改变续约行为可以通过下面两个属性:
eureka:
instance:
#最小的过期时长,多久没有发送消息,就认为这台服务挂了
lease-expiration-duration-in-seconds: 90
#心跳周期,多久向服务发起请求告知是否存活的状态,不易过高,不然影响性能
lease-renewal-interval-in-seconds: 30服务消费者模块属性:
在服务消费者启动后,会向服务注册中心请求一份服务清单,该清单记录了已经注册到服务中心的服务实例。该请求动作不会仅限于启动的时候,因为消费者需要访问正确的、健康的服务实例,因此会定时发送请求。间隔时间通过配置参数:
eureka:
client:
#要不要拉取服务列表,默认为true
fetch-registry: true
# 多久拉取一次
registry-fetch-interval-seconds: 3三:失效剔除和自我保护
服务下线:
当服务进行正常关闭操作时,它会触发一个服务下线的REST请求给EurekaServer,告诉服务注册中心:"我准备下线了"
服务中心接受到请求之后,将该服务置为下线状态。
失效剔除:
有时我们的服务可能由于某种原因不能正常工作比如:代码内部异常,网络故障等。而服务注册中心并没有收到服务下线的通知。相对于服务提供者的“服务续约”操作,服务注册中心在启动的时候会创建一个定时任务,默认每隔一段时间(60s)将清单中超时(默认90s)没有续约的服务剔除,这个操作称为失效剔除。可以在服务注册中心配置如下属性对剔除周期进行修改,单位是毫秒:
eureka:
server:
eviction-interval-timer-in-ms: 60000自我保护:
我们关停一个服务,就会在Eureka面板看到一条警告:

这就触发了Eureka的自我保护机制,当服务未按时进行心跳续约时,Eureka会统计服务实例最近15分钟心跳续约的比例是否低于85%,在生产环境下,因为网络延迟等原因,心跳失败实例比例很有可能超标,但是此时就把服务剔除并不妥当,因为服务可能没有宕机。Eureka在这段时间内不会剔除任何服务实例。直到网络回复正常。生产环境下这很有效,保证了大多数服务依然可用,不过也有可能获取到失败的服务实例,因此服务调用者必须做好失败容错。
可以通过如下属性来关闭自我保护:默认为true开启。一般我们也让它开启。
eureka:
server:
enable-self-preservation: false四:负载均衡Ribbon使用
在上一篇实践中,我们启动一个eureka-service.produce,然后使用DiscoveryClient来获取服务实例信息,然后获取ip和端口号来访问。
但是在实际环境中,我们往往启动很多个eureka-service.produce集群。此时我们获取的服务列表中就会有多个,到底该访问哪一个呢?这个时候就要用到负载均衡的算法了,在Eureka中已经为我集成了负载均衡组件:Ribbon,简单修改代码即可。
1: Ribbon介绍:
是Netflix发布的负载均衡器,它有助于控制HTTP和TCP客户端的行为。为Ribbon配置服务提供者地址列表后,Ribbon就可以基于某种负载均衡算法,自动地帮助服务消费者去请求。Ribbon默认为我们提供了很多负载均衡算法,例如轮询,随机等。当然,也可以自定义。
Ribbon和Nginx区别:
Nginx服务器负载均衡: 客户端所有请求都会交给nginx,然后由nginx实现转发请求,即负载均衡是由服务端实现。nginx服务负载均衡适合于针对服务器端,比如:tomcat、jetty等

Ribbon本地负载均衡 :在调用接口的时候、会在eureka注册中心上获取注册信息服务列表,获取到之后,缓存在jvm本地,使用本地实现rpc远程技术进行调用,即是客户端实现负载均衡。ribbon本地负载均衡适合微服务rpc远程调用,比如:dubbo,springcloud等

2:Ribbon的使用
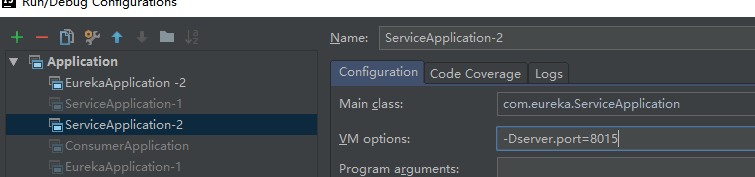
在使用之前,我把服务的提供方改一下端口再启动一个服务,这样就有两个可以提供服务的ip地址:
http://localhost:8015/getProducts,http://localhost:8011/getProducts
我们也可以使用命令行改变端口号启动:-Dserver.port=8015 它可以覆盖配置文件里面的配置。
1)我们在上次实例中使用Ribbon,首先我们在我们消费者服务模块引入依赖:但是Ribbon是和Eureka配合使用的,所以Eureka客户端的依赖包里已经有Rbbon的依赖了。

2)在RestTemplate配置类上加上注解: @LoadBalanced
加上这个注解之后,Ribbon就会拦截http请求,对它进行处理起到负载均衡的效果。
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}3)把我们的请求路径改为服务id。
@GetMapping("/getAllProduct")
public String getAllProduct(){
//使用Ribbon请求第一种方式: 我们把地址换成服务id即可
String uri="http://EUREKA-SERVICE.PRODUCER/getProducts";
String vos = restTemplate.getForObject(uri, String.class);
return vos;
}访问一下还是有结果的:

这种方式,Ribbon底层会用一个拦截器LoadBalancerInterceptor对http请求进行拦截:处理过程如下:


这一次我们看到根据服务id获取的ip地址为:169.254.58.139:8011,并不是127.0.0.1,这是因为它直接取的是我本机在局域网中的地址:
我第二次请求的时候地址就会变化:

默认的算法是轮询的。
我们可以通过配置来改变获取服务的算法:
EUREKA-SERVICE.PRODUCER: #服务的id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #算法的实现类Ribbon的算法都是由IRule接口而来的,它的实现类有下面几种,配置不同的算法实现类实现不同的算法。默认的算法是RandRobinRule:轮询算法。

我们按如下配置启动之后,debug可以看到选择服务的方法已经使用了RandomRule,随机算法。

















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











