









广州大学学生实验报告
开课学院及实验室: 计算机科学与网络工程学院 电子楼418B 2022年 9月 26日
| 学院 | 计算机科学与网络工程学院 | 年级/专业/班 | 计科 | 姓名 | Great Macro | 学号 |
|
| 实验课程名称 | Unix/Linux 操作系统分析实验 | 成绩 | |||||
| 实验项目名称 | 进程控制与进程通信 | 指导 老师 | 张*玲 | ||||
实验一 进程控制与进程互斥(1)
- 实验目的
1、理解Linux下进程的结构;
2、理解Linux下产生新进程的方法(系统调用—fork函数);
3、掌握如何启动另一程序的执行;
4、理解Linux下线程的结构;
5、理解Linux下产生新线程的方法;
6、理解Linux系统下多进程与多线程的区别
- 实验内容和任务
1、利用fork函数创建新进程,并根据fork函数的返回值,判断自己是处于父进程还是子进程中;
2、在新创建的子进程中,使用exec类的函数启动另一程序的执行;分析多进程时系统的运行状态和输出结果;
3、利用最常用的三个函数pthread_create,pthread_join和pthread_exit编写了一个最简单的多线程程序。理解多线程的运行和输出情况;
4、利用信号量机制控制多线程的运行顺序,并实现多线程中数据的共享;
5、分析Linux系统下多进程与多线程中的区别。
- 实验涉及的系统调用函数
1、fork( ) 创建一个新进程。
系统调用格式: pid=fork( )
参数定义:int fork( )
fork( )返回值意义如下:
0:在子进程中,pid变量保存的fork( )返回值为0,表示当前进程是子进程。
>0:在父进程中,pid变量保存的fork( )返回值为子进程的id值(进程唯一标识符)。
-1:创建失败。
2、exec类的函数: 启动另一程序的执行;

3、pthread_create函数:创建一个线程
它的原型为:
extern int pthread_create __P ((pthread_t *__thread, __const pthread_attr_t *__attr,void *(*__start_routine) (void *), void *__arg));
第一个参数为指向线程标识符的指针,第二个参数用来设置线程属性,第三个参数是线程运行函数的起始地址,最后一个参数是运行函数的参数。
4、函数pthread_join:等待一个线程的结束。函数原型为:
extern int pthread_join __P ((pthread_t __th, void **__thread_return));
第一个参数为被等待的线程标识符,第二个参数为一个用户定义的指针,它可以用来存储被等待线程的返回值。
这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回。一个线程的结束有两种途径,一种是函数结束了,调用它的线程也就结束了;另一种方式是通过函数pthread_exit来实现。
5、函数sem_init()用来初始化一个信号量。它的原型为:
extern int sem_init __P ((sem_t *__sem, int __pshared, unsigned int __value));
sem为指向信号量结构的一个指针;pshared不为0时此信号量在进程间共享,否则只能为当前进程的所有线程共享;value给出了信号量的初始值。
6、函数sem_post( sem_t *sem )用来增加信号量的值。当有线程阻塞在这个信号量上时,调用这个函数会使其中的一个线程不在阻塞,选择机制同样是由线程的调度策略决定的。
函数sem_wait( sem_t *sem )被用来阻塞当前线程直到信号量sem的值大于0,解除阻塞后将sem的值减一,表明公共资源经使用后减少。函数sem_trywait ( sem_t *sem )是函数sem_wait()的非阻塞版本,它直接将信号量sem的值减一。
8、函数sem_destroy(sem_t *sem)用来释放信号量sem。
- 实验步骤
1、利用fork函数编写一个简单的多进程程序,用ps命令查看系统中进程的运行状况,并分析输出结果。
#include <stdio.h> #include <unistd.h> #include <sys/types.h> void do_something(long t) { int i = 0; for(i = 0; i < t; i++) { for(i = 0; i < t; i++) { for(i = 0; i < t; i++); } } } int main(void) { pid_t pid; // 此时仅有一个进程 printf("PID before fork() : %d\n", getpid()); pid = fork(); // 此时已经有两个进程在同时运行 pid_t npid = getpid(); if(pid < 0) { perror("fork error\n"); } // pid == 0 表示子进程 else if(pid == 0) { while(1) { printf("I am child process, PID is %d\n", npid); do_something(1000000); } } // pid >= 0 表示父进程 else if(pid >= 0) { while(1) { printf("I am father process, PID is %d\n", npid); do_something(1000000); } } return 0; }
运行截图
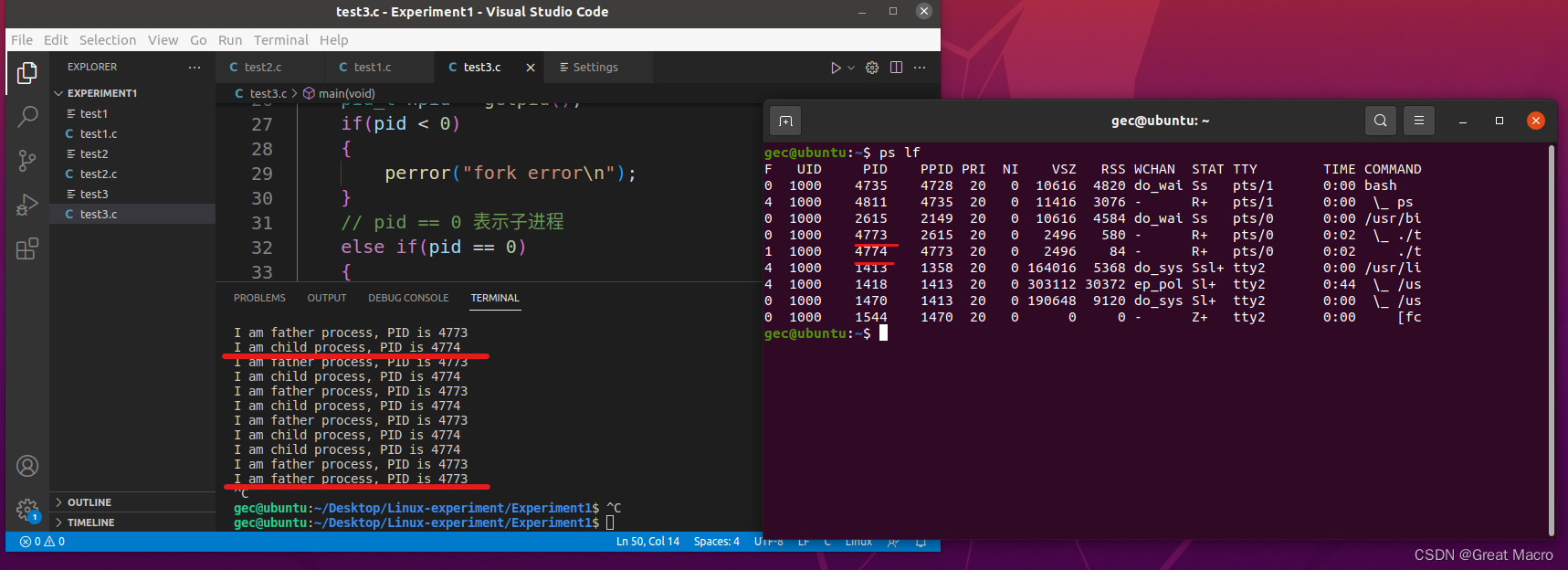
结果分析:
该程序中有一个fork()来创建子进程,同时用getpid()来获取进程的pid号,然后通过一个忙等待do_something()来延迟,在另外一个终端内输入ps -lf 来查看程序执行情况,通过输出可知,父进程pid = 4773, 子进程pid = 4774, 说明用fork()创建的子进程的pid一般是跟父进程pid紧挨着的。而且无法确定谁先执行,一般来说,系统默认子进程先执行。
一个程序调用fork函数,系统就为一个新的进程准备了前述三个段,首先,系统让新的进程与旧的进程使用同一个代码段,因为它们的程序还是相同的,对于数据段和堆栈段,系统则复制一份给新的进程,这样,父进程的所有数据都可以留给子进程,但是,子进程一旦开始运行,虽然它继承了父进程的一切数据,但实际上数据却已经分开,相互之间不再有影响了,也就是说,它们之间不再共享任何数据了。
- 在上面的多进程程序中利用exec函数,启动另一个程序的执行。用ps命令显示本机运行的所有进程的详细列表,并分析列表中不同进程的内存占用情况。
#include <stdio.h> #include <unistd.h> #include <sys/types.h> void do_something(long t) { int i = 0; for(i = 0; i < t; i++) { for(i = 0; i < t; i++) { for(i = 0; i < t; i++); } } } int main(void) { pid_t pid; // 此时仅有一个进程 printf("PID before fork() : %d\n", getpid()); pid = fork(); // 此时已经有两个进程在同时运行 pid_t npid = getpid(); if(pid < 0) { perror("fork error\n"); } // pid == 0 表示子进程 else if(pid == 0) { while(1) { printf("I am child process, PID is %d\n", npid); execl("/bin/ls","ls","-1","-color",NULL); printf("exec fail!\n"); do_something(1000000); } } // pid >= 0 表示父进程 else if(pid >= 0) { while(1) { printf("I am father process, PID is %d\n", npid); do_something(1000000); } } return 0; }
运行截图:
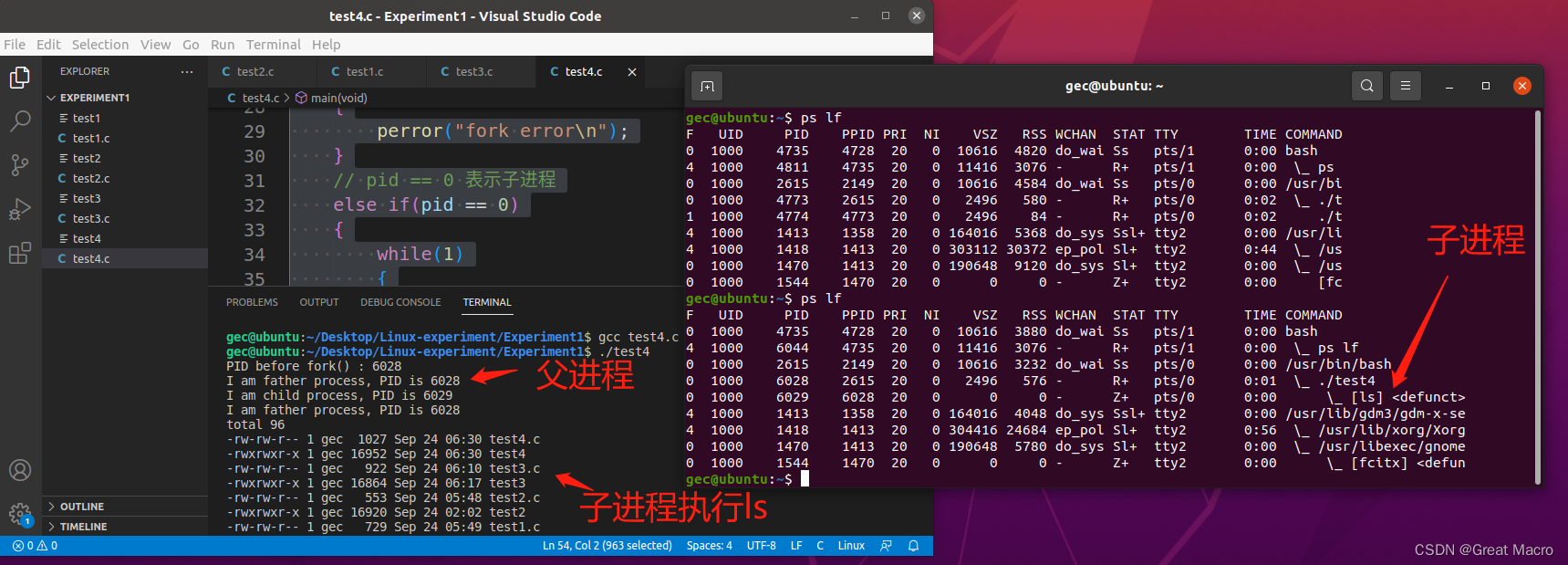
结果分析:
父进程pid = 6028, 子进程pid = 6029, 子进程用exec( )装入命令ls ,exec( )后,子进程的代码被ls的代码取代,这时子进程的PC指向ls的第1条语句,开始执行ls的命令代码。子进程开始执行语句execl("/bin/ls","ls","-1","-color",NULL); 即ls语句,罗列当前目录下的信息,在另外一个终端用ps -lf 命令看出子进程利用exec函数,启动另一个程序(ls命令)的执行。
在Linux中要使用exec类的函数来启动另一程序的执行,exec类的函数不止一个,但大致相同,在Linux中,它们分别是:execl,execlp,execle,execv,execve和execvp。一个进程一旦调用exec类函数,它本身就“死亡”了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。(不过exec类函数中有的还允许继承环境变量之类的信息)。那么如果我的程序想启动另一程序的执行但自己仍想继续运行的话,怎么办呢?那就是结合fork与exec的使用。
- 编写一个最简单的多线程程序。理解多线程的运行和输出情况;
#include<stdio.h> #include<stdlib.h> #include<unistd.h> #include<pthread.h> void thread(void) { int i; for(i=0;i<3;i++) { printf("This is a pthread.\n"); } } int main(void) { pthread_t id; int i,ret; ret=pthread_create(&id,NULL,(void *) thread,NULL); if(ret!=0){ printf ("Create pthread error!\n"); exit (1); } //sleep(0.1); for(i=0;i<3;i++) { printf("This is the main process.\n"); } pthread_join(id,NULL); return (0); }
运行截图:
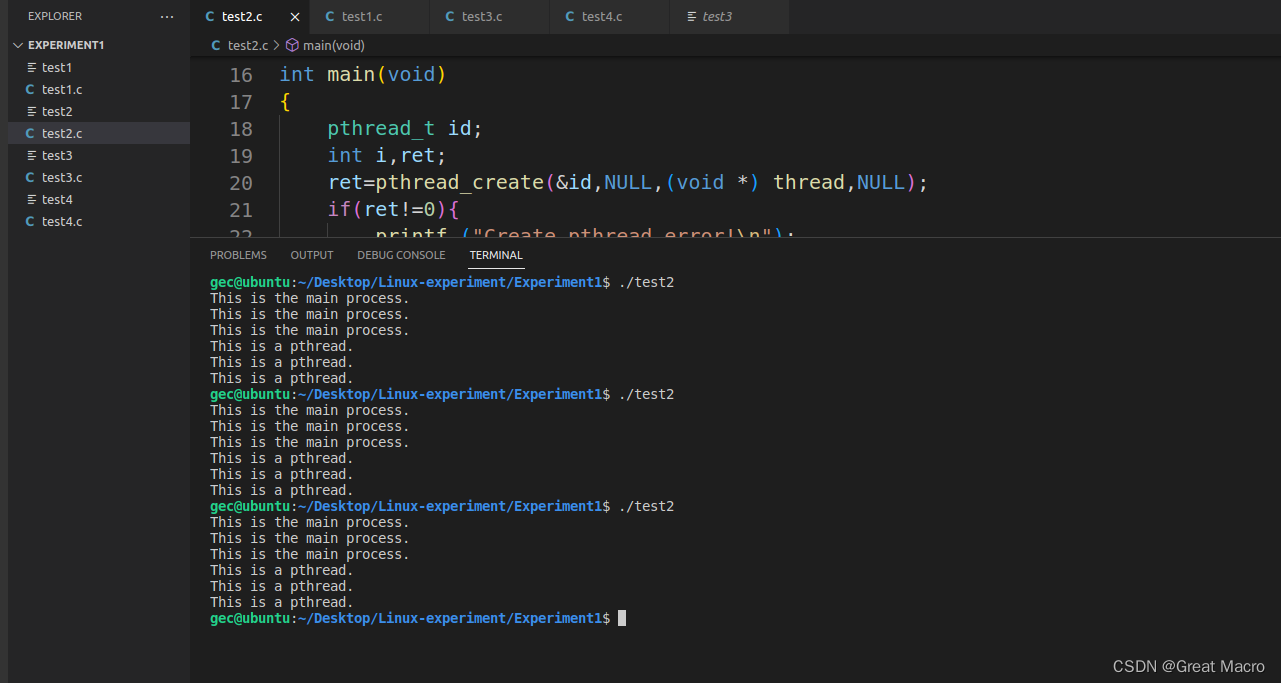
结果分析:
每次执行程序,发现结果都是一样的,先运行父进程然后在执行子线程,跟实验指导书上的结果不一样,为什么呢?因为在创建子线程时需要时间,而创建完后,由调度策略决定是先执行子线程还是父进程。初步分析是由于CPU频率太快,一会儿就执行完成了,所以每次都是父进程执行完才到子线程执行。修改sleep(0.1)使父进程睡眠,来测试是否符合结果。
运行截图:
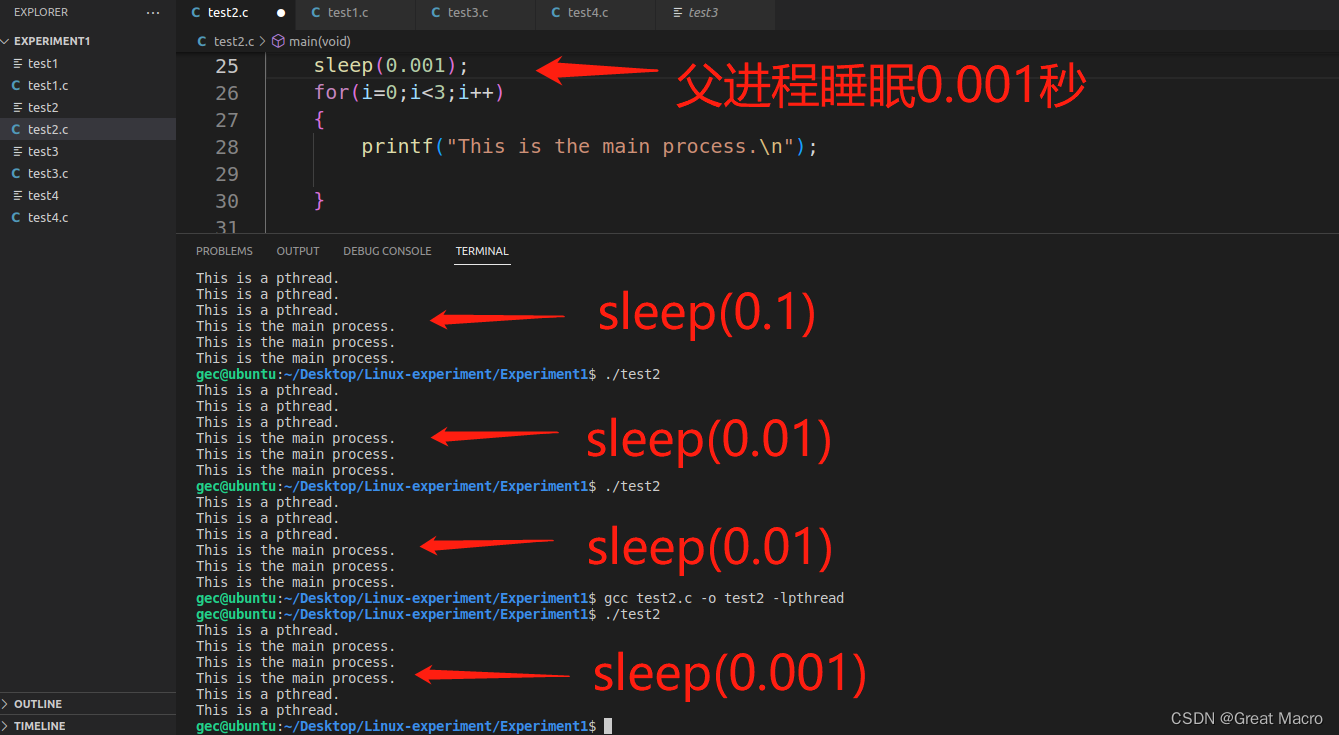
结果分析:
通过不断调整父进程中的sleep(0.1)值,来测试子线程的运行情况,发现真的如初步分析结果那样。当然也可以用信号量机制来调整情况。
多线程和进程相比,它是一种非常"节俭"的多任务操作方式。在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种"昂贵"的多任务工作方式。而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间,而且,线程间彼此切换所需的时间也远远小于进程间切换所需要的时间。据统计,总的说来,一个进程的开销大约是一个线程开销的30倍左右,当然,在具体的系统上,这个数据可能会有较大的区别。
- 利用信号量机制控制多线程的运行顺序,分析多线程中数据的共享情况;
#include <stdio.h> #include <pthread.h> #include <semaphore.h> #define MAXSTACK 100 int stack[MAXSTACK][2]; int size=0; sem_t sem; /* 从文件1.dat读取数据,每读一次,信号量加一*/ void ReadData1(void) { FILE *fp=fopen("1.dat","r"); while(!feof(fp)) { fscanf(fp,"%d %d",&stack[size][0],&stack[size][1]); sem_post(&sem); ++size; } fclose(fp); } /*从文件2.dat读取数据*/ void ReadData2(void) { FILE *fp=fopen("2.dat","r"); while(!feof(fp)) { fscanf(fp,"%d %d",&stack[size][0],&stack[size][1]); sem_post(&sem); ++size; } fclose(fp); } /*阻塞等待缓冲区有数据,读取数据后,释放空间,继续等待*/ void HandleData1(void) { while(1) { sem_wait(&sem); printf("Plus:%d+%d=%d\n",stack[size][0],stack[size][1], stack[size][0]+stack[size][1]); --size; } } void HandleData2(void) { while(1) { sem_wait(&sem); printf("Multiply:%d*%d=%d\n",stack[size][0],stack[size][1], stack[size][0]*stack[size][1]); --size; } } int main(void) { pthread_t t1,t2,t3,t4; sem_init(&sem,1,1); pthread_create(&t1,NULL,(void *)HandleData1,NULL); pthread_create(&t2,NULL,(void *)HandleData2,NULL); pthread_create(&t3,NULL,(void *)ReadData1,NULL); pthread_create(&t4,NULL,(void *)ReadData2,NULL); /* 防止程序过早退出,让它在此无限期等待*/ pthread_join(t1,NULL); }
运行截图:
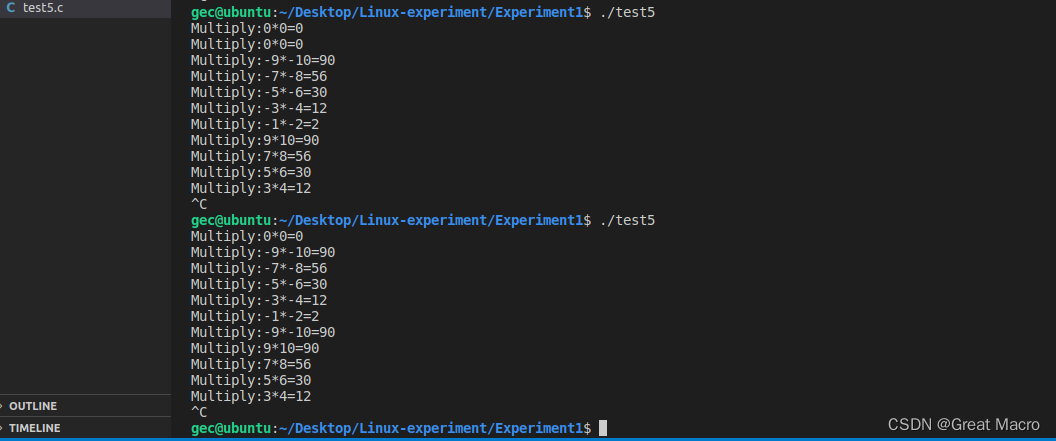
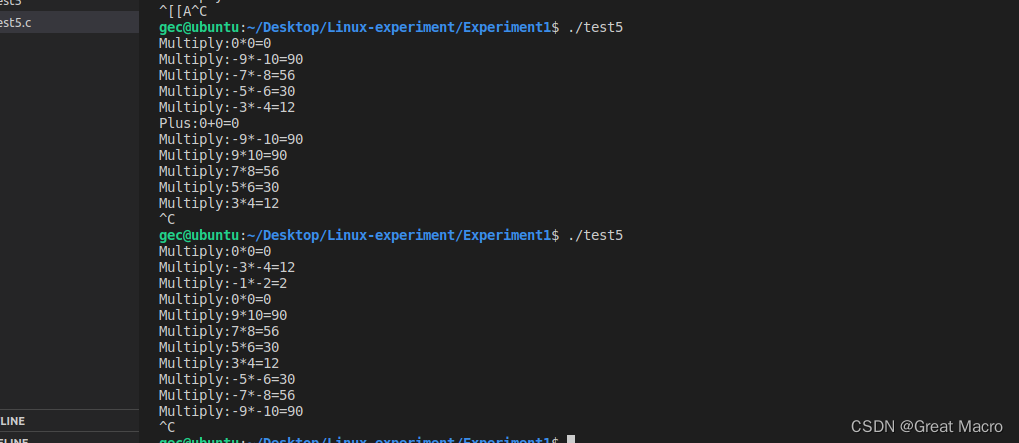
结果分析:
在Linux下,用命令gcc -lpthread sem.c -o sem生成可执行文件sem。 我们事先编辑好数据文件1.dat和2.dat,假设它们的内容分别为1 2 3 4 5 6 7 8 9 10和 -1 -2 -3 -4 -5 -6 -7 -8 -9 -10 ,我们运行sem。在这个例子中,一共有4个线程,其中两个线程负责从文件读取数据到公共的缓冲区,另两个线程从缓冲区读取数据作不同的处理(加和乘运算)。
从中我们可以看出各个线程间的竞争关系。而数值并未按我们原先的顺序显示出来,这是由于size这个数值被各个线程任意修改的缘故。同时每次运行结果都不一样,跟系统调度有密切关系,这也往往是多线程编程要注意的问题。
- 分析Linux系统下多进程与多线程中的区别。
现在,多线程技术已经被许多操作系统所支持,包括Windows/NT,当然,也包括Linux。
使用多线程的理由之一是和进程相比,它是一种非常"节俭"的多任务操作方式。在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种"昂贵"的多任务工作方式。而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间,而且,线程间彼此切换所需的时间也远远小于进程间切换所需要的时间。据统计,总的说来,一个进程的开销大约是一个线程开销的30倍左右,当然,在具体的系统上,这个数据可能会有较大的区别。
使用多线程的理由之二是线程间方便的通信机制。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其它线程所用,这不仅快捷,而且方便。当然,数据的共享也带来其他一些问题,有的变量不能同时被两个线程所修改,有的子程序中声明为static的数据更有可能给多线程程序带来灾难性的打击,这些正是编写多线程程序时最需要注意的地方。
除了以上所说的优点外,多线程程序作为一种多任务、并发的工作方式,还有以下的优点:
1) 提高应用程序响应。这对图形界面的程序尤其有意义,当一个操作耗时很长时,整个系统都会等待这个操作,此时程序不会响应键盘、鼠标、菜单的操作,而使用多线程技术,将耗时长的操作(time consuming)置于一个新的线程,可以避免这种尴尬的情况。
2) 使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
3) 改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序会利于理解和修改。
- 实验思考题
- 多进程并发执行时各个进程的内存分配情况如何?如何监测其分配情况?
Linux下一个进程在内存里有三部份的数据,就是“数据段”,“堆栈段”和“代码段”,一个程序调用fork函数,系统就为一个新的进程准备了前述三个段,首先,系统让新的进程与旧的进程使用同一个代码段,因为它们的程序还是相同的,对于数据段和堆栈段,系统则复制一份给新的进程,这样,父进程的所有数据都可以留给子进程,但是,子进程一旦开始运行,虽然它继承了父进程的一切数据,但实际上数据却已经分开,相互之间不再有影响了,也就是说,它们之间不再共享任何数据了。
采用以下命令可以监测内存分配情况:top, free, vmstat, /proc/meminfo, /proc/<pid>/statm, /proc/<pid>/status
- 多线程中数据是如何共享的?
运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,用信号量机制来控制数据的共享,只有当信号量值大于0时,才能使用公共资源,共享资源存放在一个临界区。
在函数中声明的静态变量常常带来问题,函数的返回值也会有问题。因为如果返回的是函数内部静态声明的空间的地址,则在一个线程调用该函数得到地址后使用该地址指向的数据时,别的线程可能调用此函数并修改了这一段数据。在进程中共享的变量必须用关键字volatile来定义,这是为了防止编译器在优化时(如gcc中使用-OX参数)改变它们的使用方式。为了保护变量,我们必须使用信号量、互斥等方法来保证我们对变量的正确使用。
- Linux系统下多进程与多线程中的区别是什么?
多线程和多进程相比,它是一种非常“节俭”的多任务操作方式。在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种“昂贵”的多任务工作方式。而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间,而且,线程间彼此切换所需的时间也远远小于进程间切换所需要的时间。据统计,总的说来,一个进程的开销大约是一个线程开销的30倍左右。
多线程和多进程相比,线程间方便的通信机制。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其它线程所用,这不仅快捷,而且方便。
除了以上所说的优点外,多线程程序作为一种多任务、并发的工作方式,还有以下的优点:
1) 提高应用程序响应。这对图形界面的程序尤其有意义,当一个操作耗时很长时,整个系统都会等待这个操作,此时程序不会响应键盘、鼠标、菜单的操作,而使用多线程技术,将耗时长的操作(time consuming)置于一个新的线程,可以避免这种尴尬的情况。
2) 使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
3) 改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序会利于理解和修改。
- 补充实验
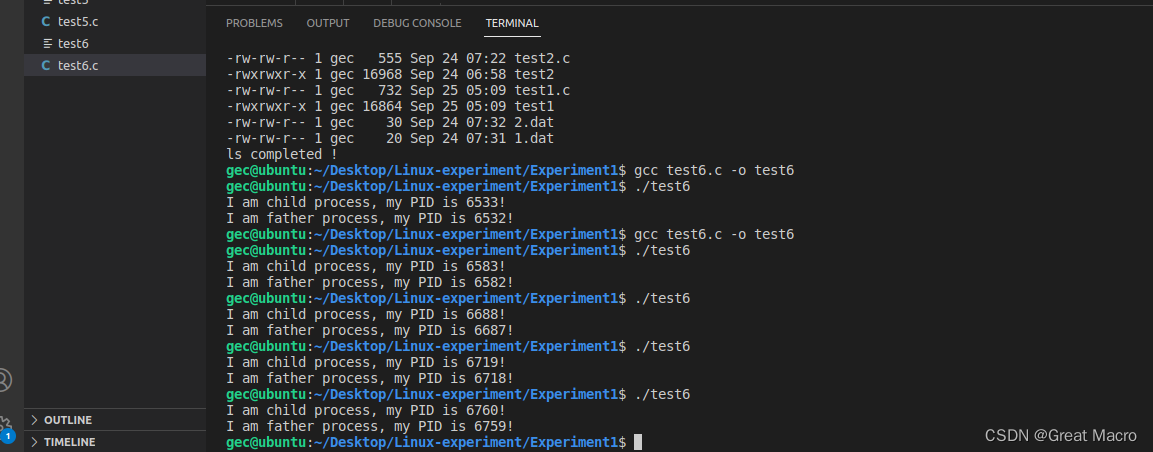
- 用fork写一个测试程序,从父进程和子进程中打印出各自的PID,并把wait(), exit()系统调用加进去,使子进程返回退出状态给父进程,并将它包含在父进程的打印信息中。对运行结果进行分析,并通过dmesg命令查看系统创建进程过程。
#include<stdio.h> #include<stdlib.h> #include<unistd.h> #include<sys/types.h> #include<wait.h> int main( ) { int pid; pid = fork(); /*创建子进程*/ pid_t npid = getpid(); switch(pid) { case -1: /*创建失败*/ printf("fork fail!\n"); exit(0); case 0: /*子进程*/ printf("I am child process, my PID is %d!\n", npid); exit(0); default: /*父进程*/ wait(NULL); /*同步*/ printf("I am father process, my PID is %d!\n", npid); exit(0); } return 0; }
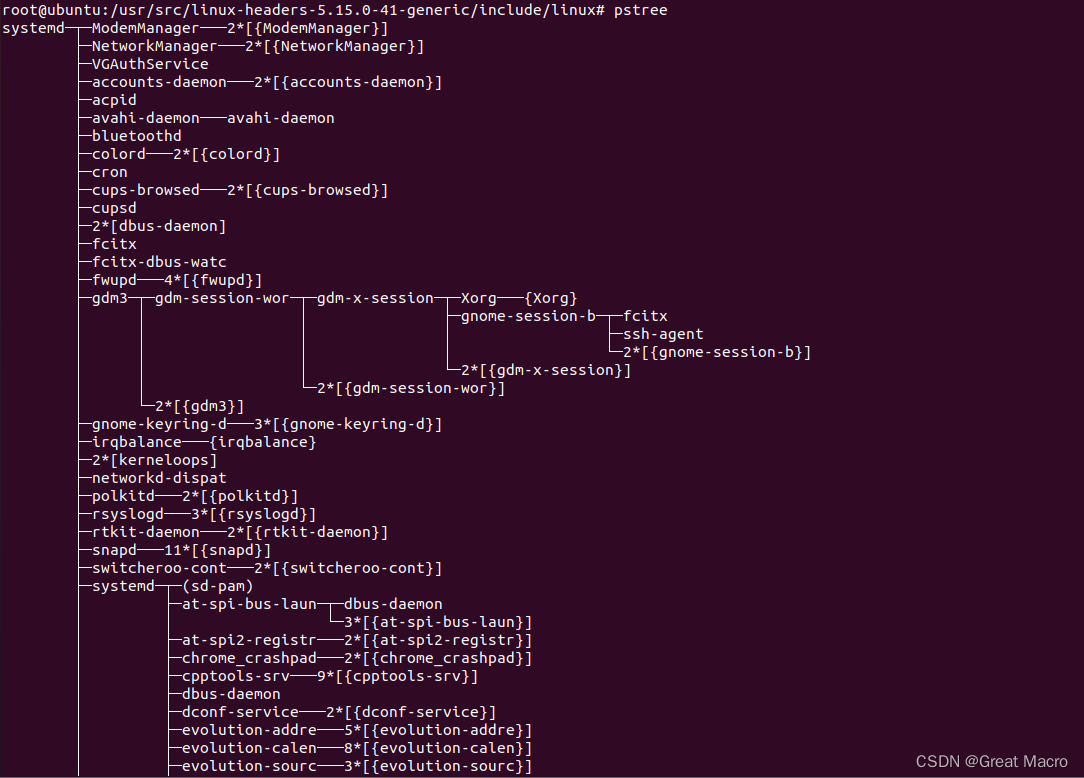
- 用sublime命令查看自己计算机上的内核源代码中的include/linux/sched.h 文件中的task_struct 结构,列出类型为list_head 的字段,并说明哪几个字段可以形成进程的树结构,通过pstree 命令查看自己机子上的进程树结构。
struct list_head rcu_node_entry;
struct list_head rcu_tasks_holdout_list;
struct list_head trc_holdout_list;
struct list_head tasks;
struct list_head children;
struct list_head sibling;
struct list_head ptraced;
struct list_head ptrace_entry;
struct list_head thread_group;
struct list_head thread_node;
struct list_head cg_list;
struct list_head pi_state_list;
struct list_head perf_event_list;
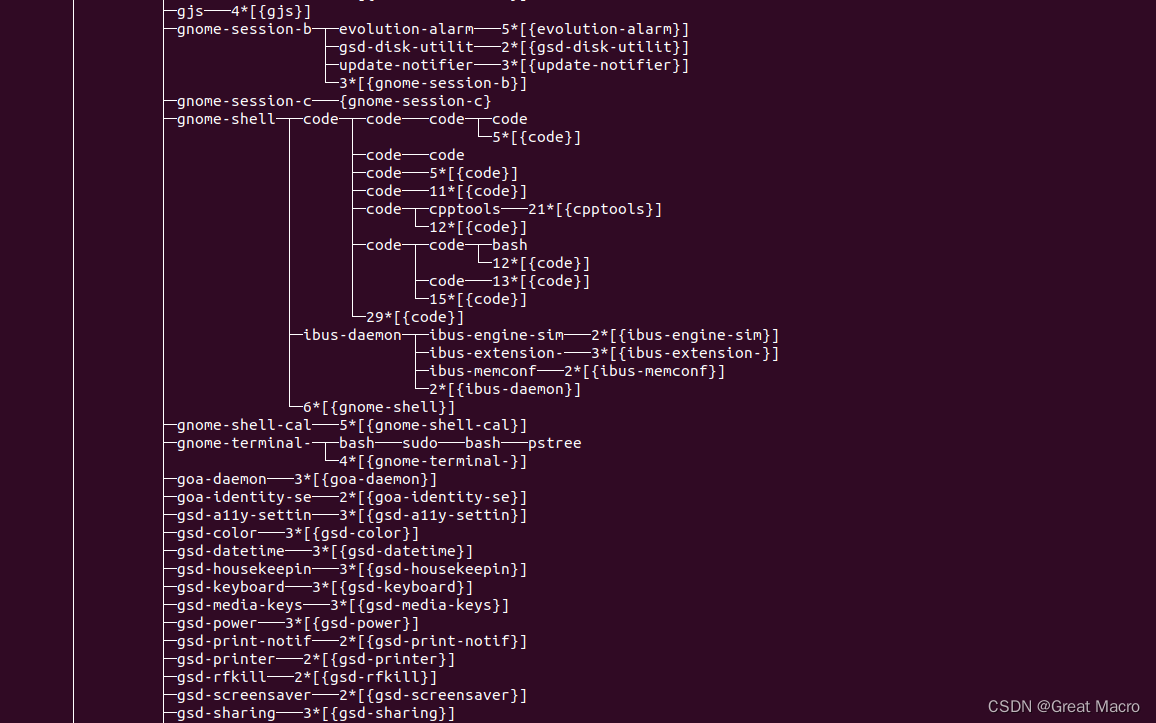
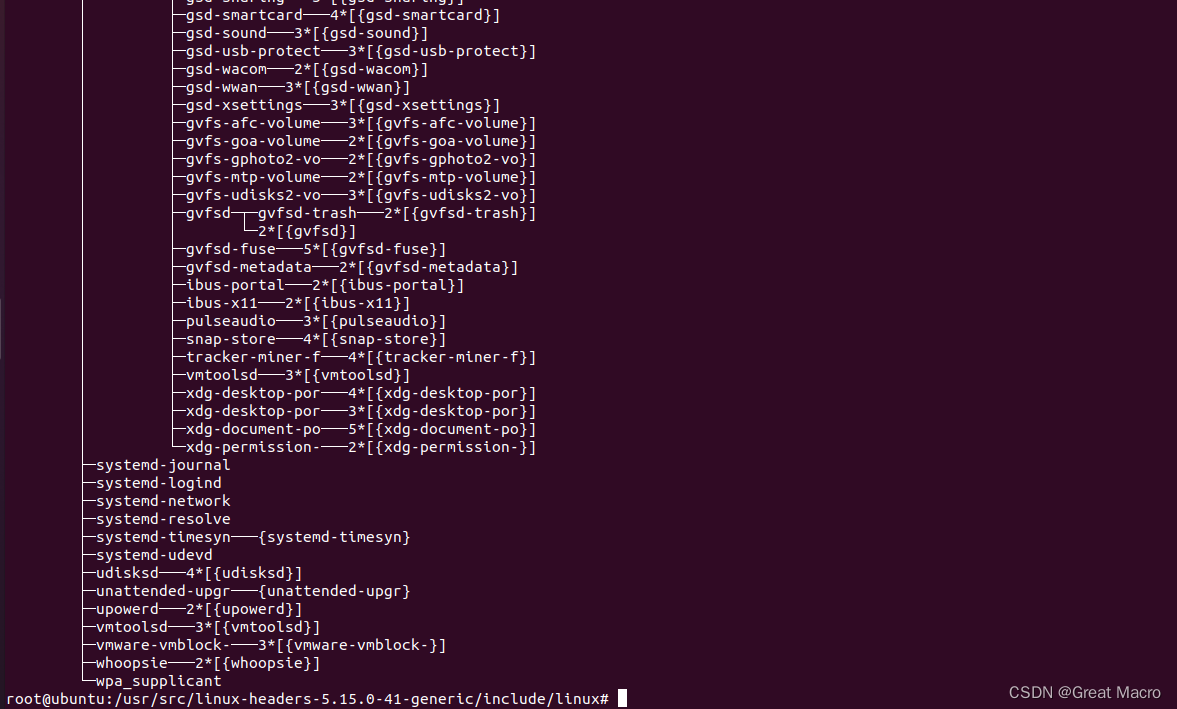
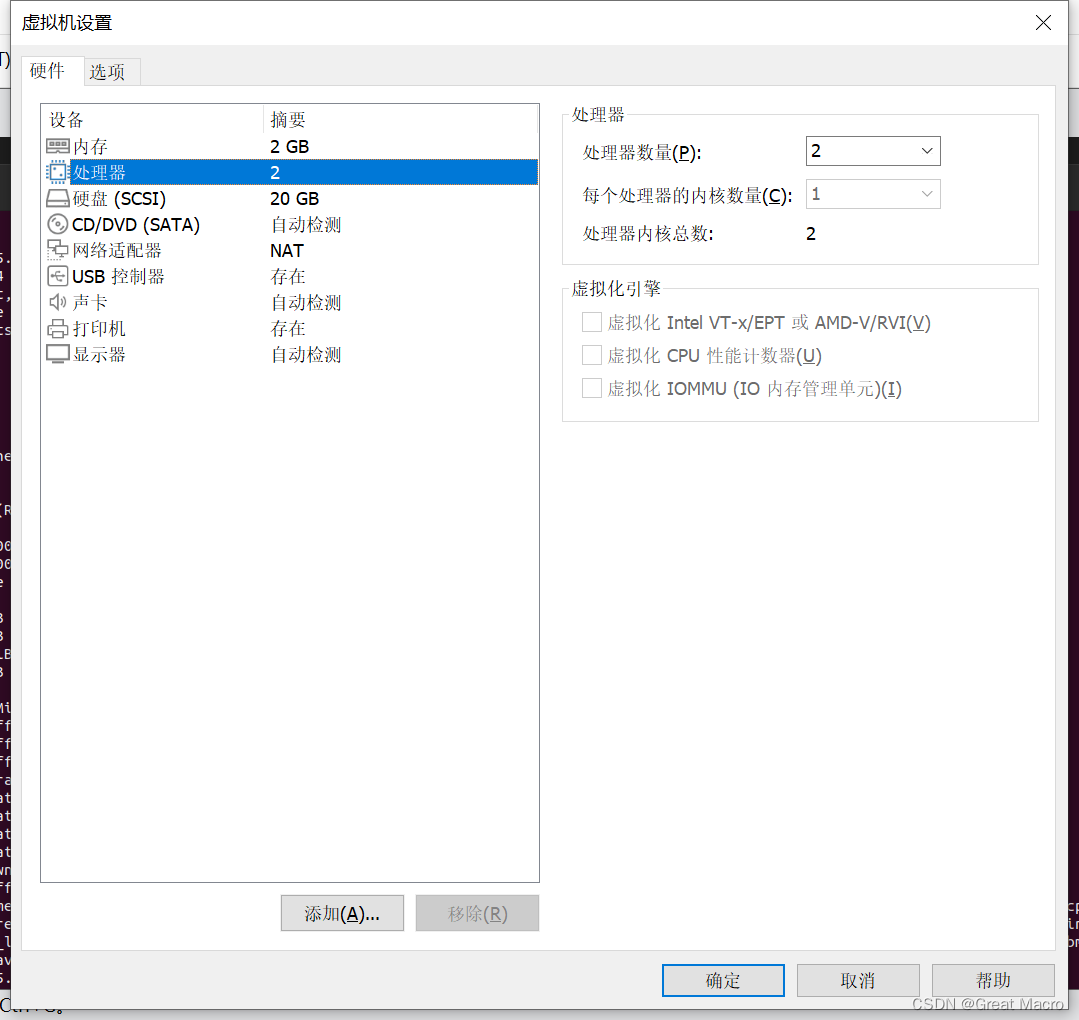
- 在Linux中用nproc或者lscpu 命令来查看CPU 核心数和CPU内的存储层次结构,多个核心数就意味着系统可以在同一时间处理多个进程。

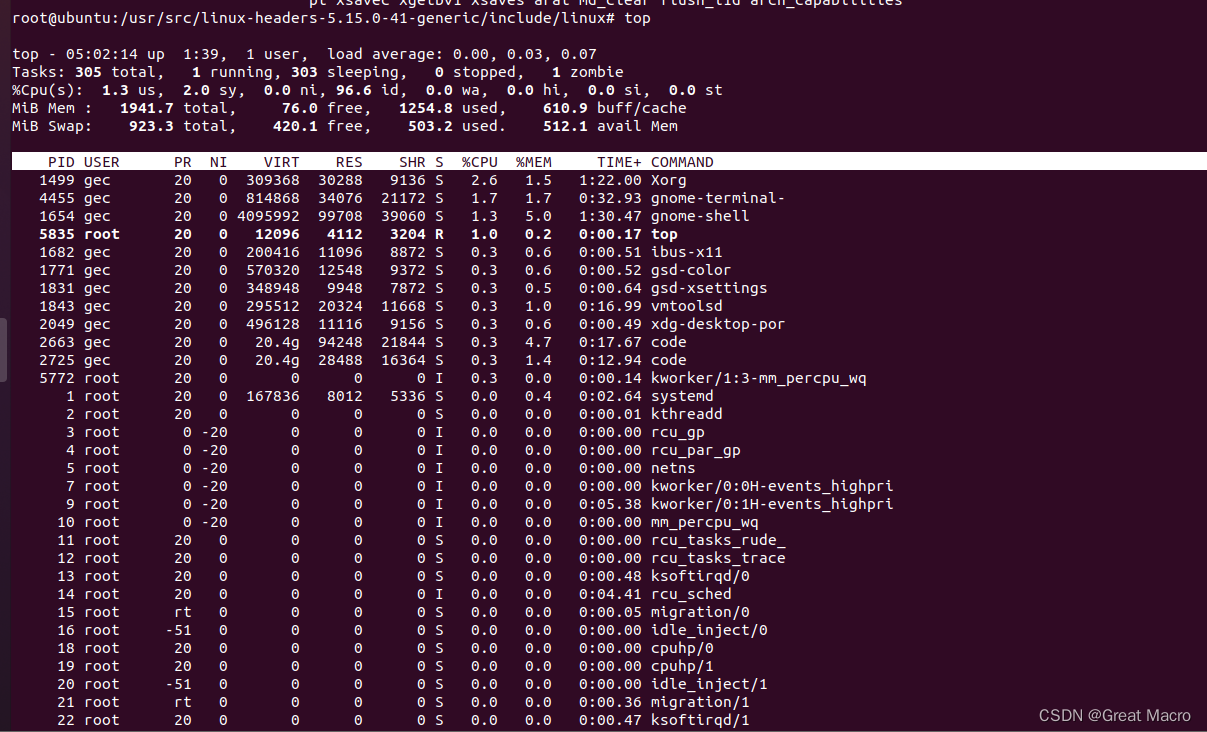
4、在Linux中用top或者uptime 命令来查看系统负载情况,返回的load average的3个数字表示的系统在1分钟、5分钟、15分钟内平均负载情况。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









