






前言
主要介绍使用 Enhanced Deep Residual Networks for Single Image Super-Resolution(EDSR)模型完成图像超分修复。
模型介绍
Enhanced Deep Residual Networks for Single Image Super-Resolution(EDSR)是一种用于单图像超分辨率(Single Image Super-Resolution,SISR)的深度学习模型,其目标是通过从低分辨率图像生成高分辨率图像来改善图像质量。有如下特点:
- 深度残差网络(Deep Residual Network) :EDSR 模型基于
深度残差网络的架构,来学习图像的残差映射,从而使得模型能够更轻松地学习到复杂的映射关系,减轻了梯度消失和梯度爆炸等训练问题。 - 增强的深度残差网络(Enhanced Deep Residual Network) :EDSR 通过对传统深度残差网络进行改进,包括
更深的网络结构、更多的残差块、更大的过滤器大小等,以增加模型的表示能力和学习能力。 - 超分辨率任务(Super-Resolution Task) :EDSR 主要用于单图像超分辨率任务,即从低分辨率输入图像生成高分辨率输出图像。在训练阶段,模型通过学习输入图像与对应的高分辨率目标图像之间的映射关系来进行训练。在推理阶段,模型可以根据输入的低分辨率图像生成对应的高分辨率图像。
数据准备
我们使用 DIV2K 数据集,这是一个著名的单图像超分辨率数据集,包含 1000 张具有各种场景的图像,其中 800 张图像用于训练,100 张图像用于验证,100 张图像用于测试。 其中低分辨率有 x2 倍、x3 倍、x4 倍三种缩小因子的低分辨率图像,我们这里选用 x4 的图像作为低分辨率图像。
下面是三个辅助函数:
flip_left_right(lowres_img, highres_img):这个函数用于实现图像的左右翻转操作。 首先通过 tf.random.uniform() 生成一个随机数 rn,范围在 0 到 1 之间。接着通过 tf.cond() 条件函数,当 rn 小于 0.5 时,返回原始的 lowres_img 和 highres_img ;当 rn 大于等于 0.5 时,对 lowres_img 和 highres_img 分别进行左右翻转操作。最终返回处理后的图像数据。random_rotate(lowres_img, highres_img):这个函数用于实现随机旋转图像的操作。首先通过 tf.random.uniform() 生成一个随机整数 rn,范围在 0 到 3 之间(旋转次数)。然后分别对 lowres_img 和 highres_img 使用 tf.image.rot90 函数,将图像顺时针旋转90度的次数等于 rn 。最终返回处理后的图像数据。random_crop(lowres_img, highres_img, hr_crop_size=96, scale=4):这个函数用于实现随机裁剪图像的操作,同时保持低分辨率图像和高分辨率图像的对应关系。首先根据给定的高分辨率裁剪尺寸 hr_crop_size 和放大倍数 scale 计算出低分辨率图像的裁剪尺寸 lowres_crop_size 。然后通过 tf.random.uniform() 生成两个随机整数 lowres_width 和 lowres_height,分别表示低分辨率图像裁剪区域的左上角坐标。接着根据裁剪区域坐标,从原始的 lowres_img 和 highres_img 中分别裁剪出对应的低分辨率图像和高分辨率图像。最终返回处理后的图像数据。
这个函数的作用是用上面三个辅助函数创建一个用于训练或测试的数据集对象。它从输入的 dataset_cache 数据集开始,如果是训练阶段则进行 random_crop 、random_rotate、flip_left_right、repeate 等数据处理和增强操作,如果是测试阶段则只进行 random_crop 的数据处理操作。
ini
复制代码
def dataset_object(dataset_cache, training=True):
ds = dataset_cache.map(lambda lowres, highres: random_crop(lowres, highres, scale=4), num_parallel_calls=AUTOTUNE)
if training:
ds = ds.map(random_rotate, num_parallel_calls=AUTOTUNE)
ds = ds.map(flip_left_right, num_parallel_calls=AUTOTUNE)
ds = ds.batch(16)
if training:
ds = ds.repeate()
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
模型搭建
这段代码定义了一个基于残差块的超分辨率模型EDSR(Enhanced Deep Super-Resolution),其中包含了训练步骤、预测步骤以及用于构建模型的辅助函数。
-
EDSRModel类:train_step方法: 该方法重写了tf.keras.Model的train_step方法,用于定义训练步骤。在每个训练步骤中,输入数据data就是x和y,然后使用梯度带(GradientTape)计算模型预测y_pred,并计算损失。最后,更新模型的权重和度量指标,并返回度量指标的结果。predict_step方法: 该方法重写了tf.keras.Model的predict_step方法,用于定义预测步骤。在每个预测步骤中,输入x被转换为float32类型,并经过模型进行预测得到超分辨率图像。然后,对预测结果进行裁剪、取整、转换为uint8类型,并返回超分辨率图像。
-
辅助函数:
ResBlock函数: 定义了一个残差块,包括两个卷积层和一个跳跃连接(通过Add层实现)。这个函数用于构建模型中的残差块。Upsampling函数: 定义了一个上采样函数,使用卷积层进行上采样,并通过tf.nn.depth_to_space函数实现深度到空间的转换。这个函数用于模型中的上采样操作。make_model函数: 该函数用于构建整个EDSR模型。首先定义了输入层,然后进行图像缩放处理。接着定义了一系列残差块,并通过跳跃连接将它们连接起来。最后进行上采样和输出处理,得到最终的超分辨率图像。函数返回一个EDSR模型对象。
ini
复制代码
class EDSRModel(tf.keras.Model):
def train_step(self, data):
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
trainable_vars = self.trainable_varibales
gradients = tape.gradient(loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
self.compiled_metrics.update_state(y, y_pred)
return {m.name: m.result() for m in self.metrics}
def predict_step(self, x):
x = tf.cast(tf.expand_dims(x, axis=0).tf.float32)
super_resolution_img = self(x, training=False)
super_resolution_img = tf.clip_by_value(super_resolution_img, 0, 255)
super_resolution_img = tf.round(super_resolution_img)
super_resolution_img = tf.squeeze(tf.cast(super_resolution_img, tf.uint8), axis=0)
return super_resolution_img
def ResBlock(inputs):
x = layers.Conv2D(64, 3, padding="same", activation="relu")(inputs)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.Add()([inputs, x])
return x
def Upsampling(inputs, factor=2, **kwargs):
x = layers.Conv2D(64 * (factor ** 2), 3, padding="same", **kwargs)(inputs)
x = tf.nn.depth_to_space(x, block_size=factor)
x = layers.Conv2D(64 * (factor ** 2), 3, padding="same", **kwargs)(x)
x = tf.nn.depth_to_space(x, block_size=factor)(x)
return x
def make_model(num_filters, num_of_residual_blocks):
input_layer = layers.Input(shape=(None, None, 3))
x = layers.Rescaling(scale=1.0 / 255)(input_layer)
x = x_new = layers.Conv2D(num_filters, 3, padding="same")(x)
for _ in range(num_of_residual_blocks):
x_new = ResBlock(x_new)
x_new = layers.Conv2D(num_filters, 3, padding="same")(x_new)
x = layers.Add()([x, x_new])
x = Upsampling(x)
x = layers.Conv2D(3, 3, padding="same")(x)
output_layer = layers.Rescaling(scale=255)(x)
return EDSRModel(input_layer, output_layer)
模型训练
early_stopping_callback:创建一个 EarlyStopping 回调对象,如果指标在设定的 10 次 epoch 内没有改善,则停止训练。model_checkpoint_callback:创建一个 ModelCheckpoint 回调对象,它用于在训练过程中保存模型的权重,并且只保存在验证集上性能最好的模型。
ini
复制代码
early_stopping_callback = keras.callbacks.EarlyStopping(monitor="loss", patience=10)
model_checkpoint_callback = keras.callbacks.ModelCheckpoint(filepath="EDSR/checkpoint.keras", save_weights_only=False, monitor="loss", mode="min", save_best_only=True, )
model = make_model(num_filters=64, num_of_residual_blocks=16)
optim_edsr = keras.optimizers.Adam(learning_rate=keras.optimizers.schedules.PiecewiseConstantDecay(boundaries=[5000], values=[1e-4, 5e-5]))
model.compile(optimizer=optim_edsr, loss="mae", metrics=[PSNR])
model.fit(train_ds, epochs=50, steps_per_epoch=200, validation_data=val_ds, callbacks=[early_stopping_callback, model_checkpoint_callback])
日志打印:
arduino
复制代码
Epoch 1/50
200/200 [==============================] - 7s 20ms/step - loss: 26.4669 - PSNR: 19.8638 - val_loss: 14.3105 - val_PSNR: 23.2535
Epoch 2/50
200/200 [==============================] - 3s 13ms/step - loss: 12.8289 - PSNR: 25.4992 - val_loss: 11.6453 - val_PSNR: 26.0368
...
Epoch 46/50
200/200 [==============================] - 2s 12ms/step - loss: 7.2581 - PSNR: 32.2279 - val_loss: 7.3768 - val_PSNR: 31.8386
Epoch 47/50
200/200 [==============================] - 2s 12ms/step - loss: 7.3122 - PSNR: 32.0149 - val_loss: 7.2080 - val_PSNR: 31.2420
Epoch 48/50
200/200 [==============================] - 2s 12ms/step - loss: 7.2122 - PSNR: 33.6319 - val_loss: 7.1458 - val_PSNR: 31.3648
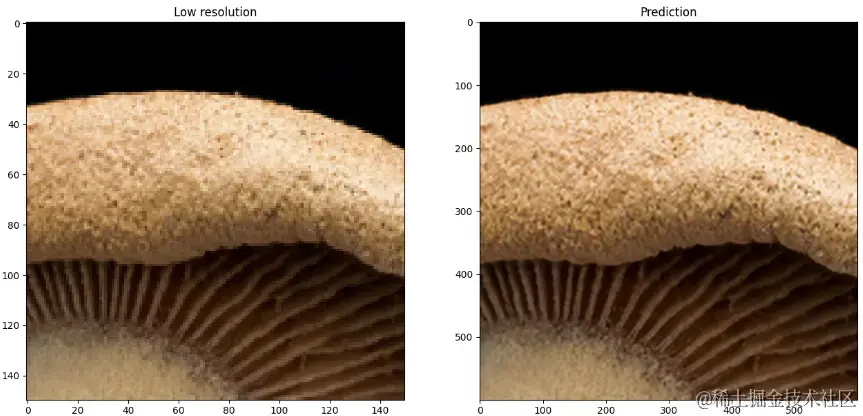
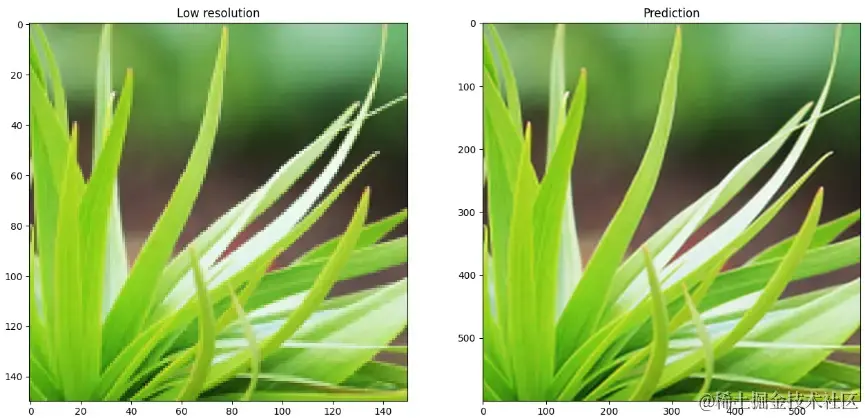
效果展示
从下面的展示样例中可以看出来。模型确实拥有了将图像超分的能力。

大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
整理了我入门大模型的学习路线和自用资料,在全民LLM时期,多输入一些就多一重安全感。
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。


😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









