







我们都知道可重复读隔离级别可以解决脏读、不可重复读。那么具体是如何解决的呢?
下面先通过实验来演示可重复读能够解决脏读、不可重复读问题,然后解释具体的原因。
环境搭建
1. 建立两个session连接MySQL,session1和session2
关闭session1和session2的事务自动提交。
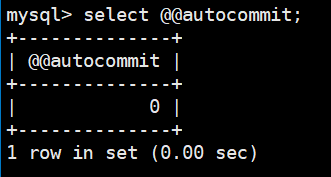
set autocommit=0; // 关闭自动提交
select @@autocommit; // 查看当前session的自动提交状态
2. 将session1和session2的隔离级别设置为可重复读。
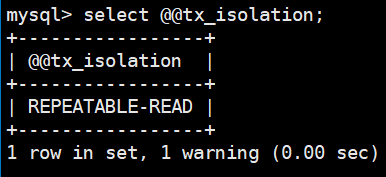
set tx_isolation='repeatable-read'; // 设置当前session的隔离级别为可重复读
select @@tx_isolation; //查看当前session的隔离级别
3. 随便创建一张表,我这里是user。
这里是user中的数据:
开始实验
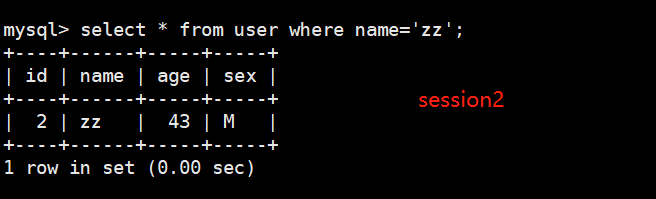
1. 首先在session2中查询name='zz’的数据。
select * from user where name='zz';
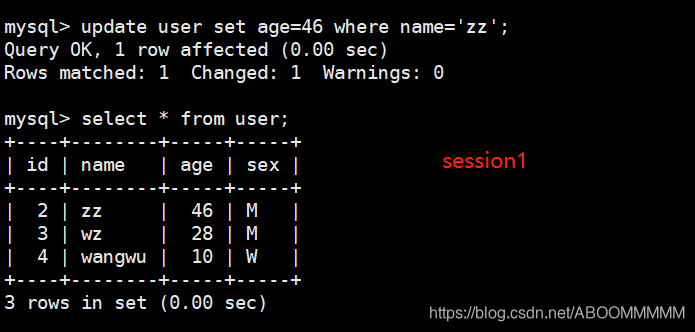
2. 在session1中开启事务,然后改变name='zz’的age字段为46。
begin; // 开启事务
update user set age=46 where name='zz'; //更新数据
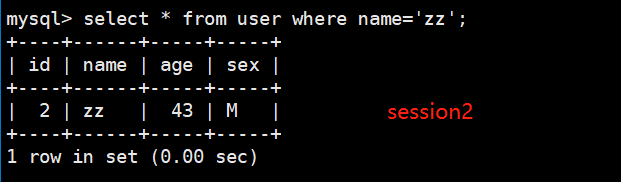
这时候session2中肯定是查不到数据的更改的,也就解决了脏读的问题:
3.将session1中的事务进行提交,再次到session2中查询该字段。
commit; // session1中提交事务
select * from user where name='zz'; //session2中再次查询该字段
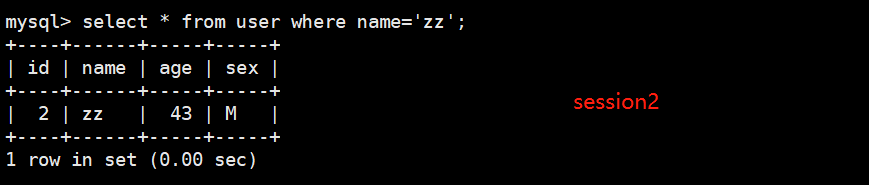
这就解决了不可重复读的问题。
底层解释
1. 在InnoDB中,解决事务的隔离性(Isolation)是通过多版本并发控制(MVCC)和锁(lock)机制来实现的。
2.表(user)中的数据是有两个状态的,prepare和commit。其中prepare是事务提交之前数据的状态,而commit是事务提交之后的状态。
3.数据通过MVCC控制是具有多个版本的,其原理是:MVCC会在每行数据上增加两个字段,事务ID(DB_TRX_ID)和指向前一个数据的指针(DB_ROLL_PTR),根据指针和事务ID,就可以实现行数据的多版本。
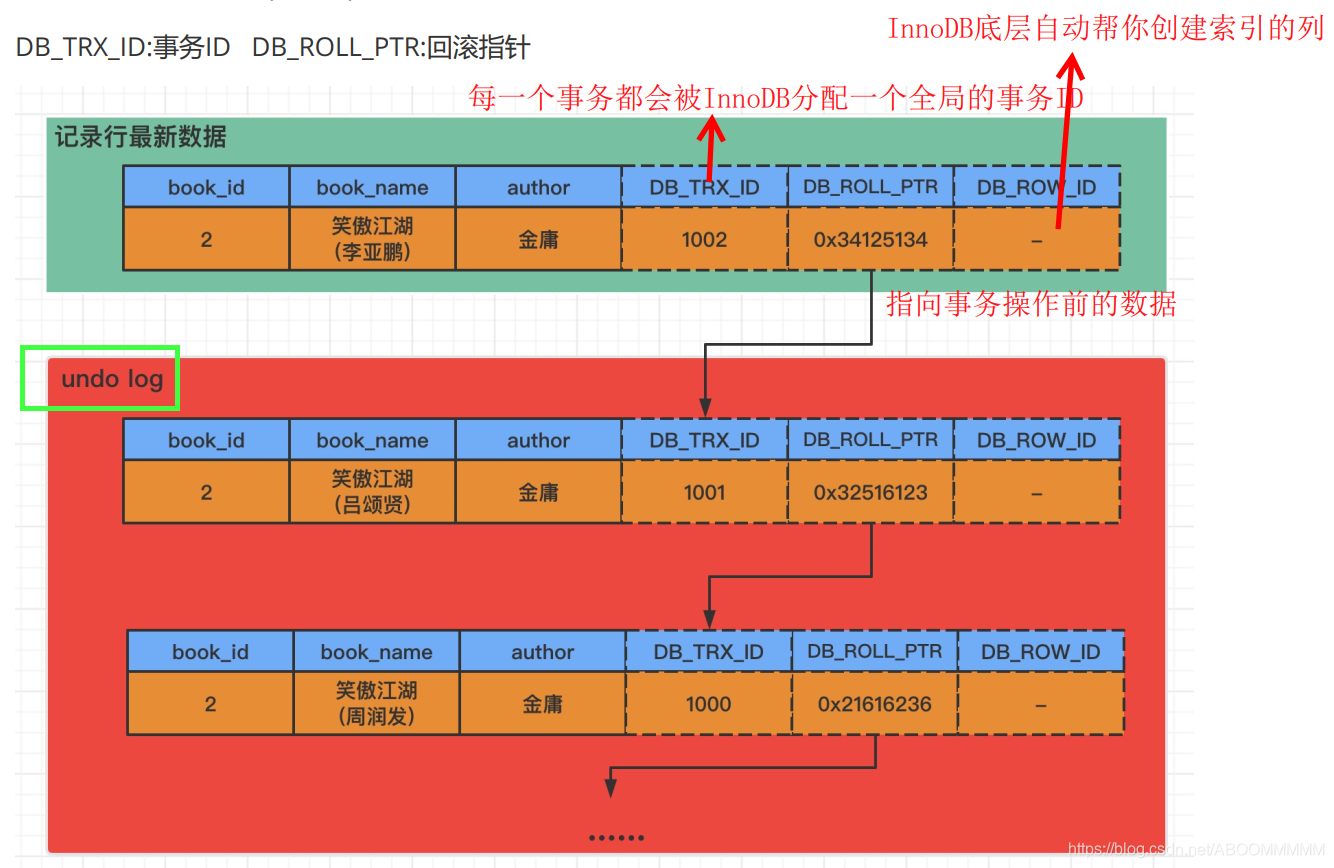
4.在可重复读的隔离级别下,InnoDB每次进行select查询语句,只有第一次执行select语句会产生数据快照(整张表的快照),之后执行相同的select语句,不再产生数据快照,那么下次使用相同语句查询时,访问的快照仍然是第一次产生的数据快照。那么即使当session1提交(commit)事务之后,session2访问的仍然是事务提交之前的即数据处于prepare状态的数据快照。这就解决了不可重复读的问题。














 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









