







Sql函数记录
- 0 数据库基础知识
- 1 group_concat
- 2 @i:=@i+1 (Mysql独有)
- 3 order by 排序问题
- 4 DATE_FORMAT
- 5 CONCAT
- 6 EXCEPT、INTERSECT、UNION
- 7 Sql中关于批量操作
- 8 流程控制函数case/when
- 9 保留两位小数
- 10 IF函数条件判断
- 11 with...as函数
- 12 IFNULL(VALUE,0)函数/COALESCE(VALUE,0)
- 13 SQL中大于和等于写法
- 14 SQL中时间比较相关问题
- 15 SQL中在SELECT查询列表中使用if条件查询
- 16 SQL中if条件查询时等于和不等于格式
- 17 SQL中Escape用法和MyBatis模糊查询特殊字符无效问题
- 18 SQL中大于小于的常用表达方式
- 19 FIND_IN_SET的使用
- 20 在数据库BLOB字段转String的方法
- 21 SQL中in大于1000报错问题
- 22 instr函数使用 (Oracle中模糊查询实现方案)
记录日常中常用的函数,想记录成为函数百科.持续更新ing
0 数据库基础知识
0 Sql执行顺序
| 关键字 | 顺序 |
|---|---|
| FROM | 1 |
| ON | 2 |
| JOIN | 3 |
| WHERE | 4 |
| GROUP BY | 5 |
| WITH | 6 |
| HAVING | 7 |
| SELECT | 8 |
| DISTINCT | 9 |
| ORDER BY | 10 |
| LIMIT | 11 |
(8) SELECT (9)DISTINCT<select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE|ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>
(11) LIMIT <limit_number>
1 查询数据库版本
select VERSION()

1 group_concat
功能: 将group by产生的同一个分组中的值连接起来,返回一个字符串结果
语法: group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
tips: []内为可选, 分隔符不默认是逗号,
应用场景: 常见一对多表结构关系,将根据一表方分组,查询对应多表某列数据,以规定的格式拼接成字符串
eg:
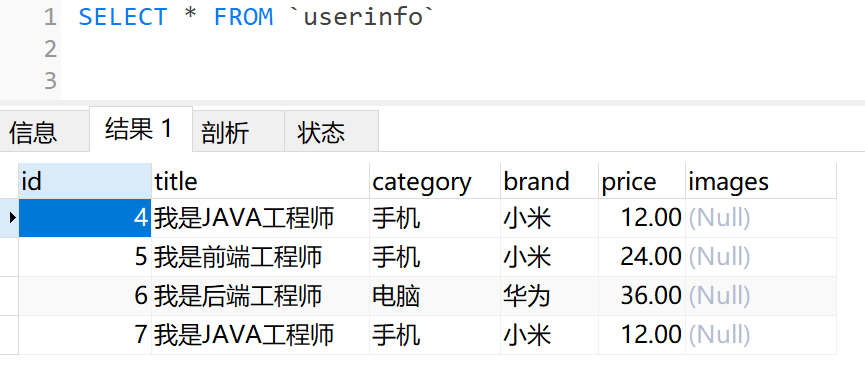
# 查询用户表所有信息
SELECT * FROM `userinfo`
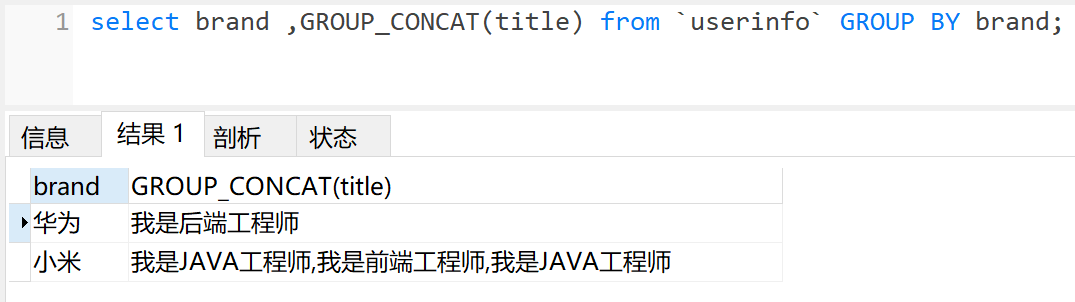
# 根据brand分组, 查询每个brand的title,并以逗号,拼接
select brand ,GROUP_CONCAT(title) from `userinfo` GROUP BY brand;
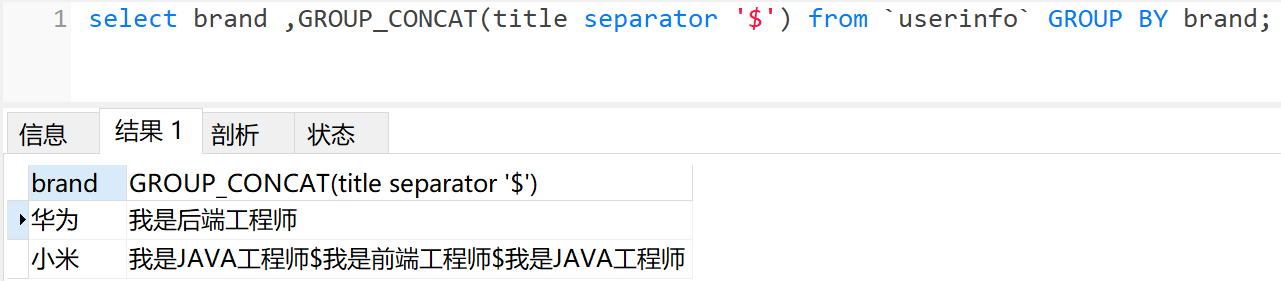
# 根据brand分组, 查询每个brand的title,并以美元符号$拼接
select brand ,GROUP_CONCAT(title separator '$') from `userinfo` GROUP BY brand;
2 @i:=@i+1 (Mysql独有)
Oracle中有一个伪列rownum,在查询结果时生成一组递增的序列号,可以用于分页截断等作用.
Mysql中没有该伪列,可通过上述模拟生成一列自增序号.
功能: 在查询结果时生成一组递增的序列号
语法: SELECT (@i:=@i+1) as rownum , 查询字段 FROM 查询表名 ,(select @i:=0) as a
tips:
(select @i:=0)定义初始序号为0(可更换为其他如10,20,…),且必须起别名,别名无规定,不与查询表名相同即可.(@i:=@i+1)定义递增规则,每次递增为1(可更换为5,10,…)
# 查询用户表所有信息
SELECT * FROM `userinfo`
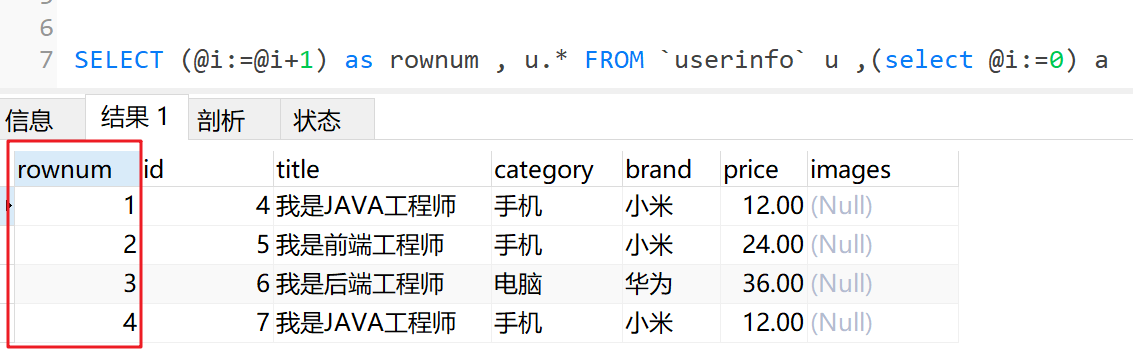
# 添加自增序列号 初始为0,每次递增1
SELECT (@i:=@i+1) as rownum , u.* FROM `userinfo` u ,(select @i:=0) a
# 添加自增序列号 初始为10,每次递增5
SELECT (@i:=@i+5) as rownum , u.* FROM `userinfo` u ,(select @i:=10) a

在多表联查,在有分组和排序中,若想order by某字段之后再添加序号列,必须把原sql用括号套起来,放到from后面 和, ( select @i := 0 ) init
错误示范:
SELECT
( @i := @i + 1 ) as rownum,
A.*
FROM
userinfo A
LEFT JOIN `user` B ON A.id = B.id,
( select @i := 0 ) init
GROUP BY
A.id
ORDER BY
A.price DESC
 正确示范:
正确示范:
SELECT
( @i := @i + 1 ) as rownum,
c.*
FROM
(
SELECT
A.*
FROM
userinfo A
LEFT JOIN `user` B ON A.id = B.id
GROUP BY
A.id
ORDER BY
A.price DESC
) c,
( select @i := 0 ) init

3 order by 排序问题
功能: 将查询结果,按照指定的规则排序
语法: order by colum [asc | desc]
常见排序,升序(ASC,查询默认为ASC),降序(DESC)
tips:遇到需要和Null一起排序:
# null默认被放在最前 oracle相反
order by colum asc
# null被强制放在最前,不为null的按声明顺序[asc|desc]进行排序
ORDER BY IF(ISNULL(update_date),0,1)
4 DATE_FORMAT
功能: 用于以不同的格式显示日期/时间数据
语法: DATE_FORMAT(date,format)
date 参数是合法的日期,format 规定日期/时间的输出格式.
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
| eg: |
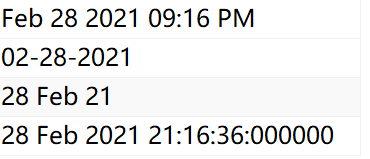
# DATE_FORMAT(NOW(),'%b %d %Y %h:%i %p')
# DATE_FORMAT(NOW(),'%m-%d-%Y')
# DATE_FORMAT(NOW(),'%d %b %y')
# DATE_FORMAT(NOW(),'%d %b %Y %T:%f')
select
DATE_FORMAT( NOW(), '%b %d %Y %h:%i %p' ) UNION ALL
select
DATE_FORMAT( NOW(), '%m-%d-%Y' ) UNION ALL
select
DATE_FORMAT( NOW(), '%d %b %y' ) UNION ALL
select
DATE_FORMAT( NOW(), '%d %b %Y %T:%f' )
5 CONCAT
功能: 多个字符合并为一个字符串
语法: CONCAT(s1,s2...sn)
字符串 s1,s2 等多个字符串合并为一个字符串
CONCAT_WS(x, s1,s2…sn)
功能: 将多个字符合并为一个字符串,.每个字符用x分隔
语法: CONCAT_WS(x, s1,s2...sn)
同 CONCAT(s1,s2,…) 函数,但是每个字符串之间要加上 x,x 可以是分隔符.
e.g:
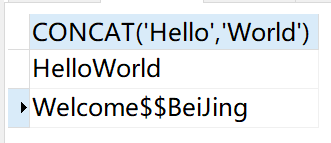
select
CONCAT('Hello','World')
union all
select
CONCAT_WS('$$','Welcome','BeiJing')
6 EXCEPT、INTERSECT、UNION
EXCEPT返回两个结果集的差INTERSECT返回 两个结果集的交集UNION返回两个结果集的并集
语法:
{ (<SQL-查询语句1>) }
{ EXCEPT | INTERSECT| UNION}
{ (<SQL-查询语句2> )}
问题:
# 有些版本sql不支持EXCEPT函数 可按照下列查询
select name from tableA a where name not in (select name from tableB b )
union
select name from tableB b where name not in (select name from tableA a )
7 Sql中关于批量操作
更新
方法一: 遍历更新,发送多条更新sql,虽然共用一个事务,但是依然性能较低.
<update id="updateBatch">
<foreach separator=";" collection="list" item="c" index="index">
update t_user
<set>
status = 1
</set>
where id = #{c}
</foreach>
</update>
方法二: 使用case when,把所有情况列举,一个sql完成.
<update id="updateBatch" parameterType="list">
update t_user
<trim prefix="set" suffixOverrides=",">
<trim prefix="path =case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.id!=null">
when id=#{i.id} then #{i.path}
</if>
</foreach>
</trim>
<trim prefix="address =case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.address!=null">
when id=#{i.address} then #{i.address}
</if>
</foreach>
</trim>
</trim>
where id in
<foreach collection="list" item="i" index="index" open="(" separator="," close=")">
#{i.id}
</foreach>
</update>
解释: 使用case when 将更新的内容列举出来,进行批量更新.
UPDATE t_user
SET path =
CASE id
WHEN '10800537' THEN '/api/ids/10800537'
WHEN '10800118' THEN '/api/ids/10800118'
END ,
address=
CASE id
WHEN '10800537' THEN '武汉'
WHEN '10800118' THEN '上海'
END
WHERE id IN ('10800537','10800118')
新增
<!-- 批量新增 用户表List -->
<insert id ="insertBatch" parameterType="java.util.List" >
insert INTO `t_user` (id, 'name') VALUES
<foreach collection ="userList" item="user" separator =",">
(
'${user.id}',
'${user.name}'
)
</foreach >
</insert >
8 流程控制函数case/when
语法:
if(条件表达式,表达式1,表达式2):如果条件表达式成立,返回表达式1:否则表达式2
实例数据:

情况一:
case 变量或表达式或字段
when 常量1 then 值1
when 常量2 then 值2
...
else 值n
end

情况二:
case
when 条件1 then 值1
when 条件2 then 值2
...
else 值n
end

9 保留两位小数
Mysql之保留两位小数:
| 方法 | 说明 |
|---|---|
| Round(number,2) | param2表示保留两位有效数字,不负责截断,后面如有数据用0补充 |
| Convert(decimal(10,2),number) | param2表示保留两位有效数字,会截断数据 |
| cast(number as decimal(10,2)) | param2表示保留两位有效数字,会截断数据 |
SELECT ROUND(123.9994, 3) --123.9990
SELECT ROUND(151.75, 0,0) --152.00 舍入
SELECT ROUND(151.75, 0,1) --151.00 截断
SELECT CONVERT(DECIMAL(13,2),13.123) --13.12
SELECT CAST(13.123 as DECIMAL(13,2)) --13.12
总结: 推荐使用第三种方法,使用CAST函数保留两位小数.
Oracle之保留两位小数
- ROUND(A/B,2) 函数是会将计算结果进行四舍五入的, 参数一是计算表达式, 参数二是保留的小数位.
- TRUNC(A/B,2) 不会进行四舍五入, 参数一是计算表达式, 参数二是保留的小数位.
- TO_CHAR(A/B,‘FM99990.99’) 格式化函数,参数一是计算表达式,参数二是指定格式化的格式. (如果保留两位小数则小数点后写两个99,表示占位符)
-- 特殊情况下,可使用下列表示
-- 如 1/10 上面的结果为0.1 而下面的结果是0.10
select to_char(a/b,'FM9990.00') AS result from dual;
10 IF函数条件判断
Mysql:
语法: IF(expr1,expr2,expr3)
说明: expr1是判断条件,expr2和expr3是符合expr1条件的返回结果.
使用场景: 将数据库查询的结果进行自定义替换

tips:
判断一个字段为null,使用is null,而不是= null ;

Oracle:
oracle中没有if函数,但是有想使用条件三元表达式怎么办?
可以使用sign和decode函数组合.
sign函数:
语法: sign(n)
说明: (n可以是表达式)
- n>0, 返回1
- n=0, 返回0
- n<0, 返回-1
** decode函数:**
语法: decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
说明: 根据条件的值,返回不同的值.
e.g:
-- 值1-值2 如果结果小于0,则结果0,否则结果为值1-值2
SELECT
DECODE(sign(值1-值2),1,(值1-值2),0)
FROM
DUAL
以上,是oracle中使用sign和decode函数组合,达到IF(expr1,expr2,expr3)函数的效果.
11 with…as函数
语法: with ... as ...
用法: 与子查询相识,生成临时表.
使用场景: 常在报表统计时使用,提高多次重用效率和可读性.
案例:
WITH ids AS
select
id
from
user
select
id
from
user
where id IN (select *from ids)
上面sql和下面表达式效果相同:
select
id
from
user
where
id IN (select id from user)
tips:
- mysql5版本不支持,mysql8版本支持
12 IFNULL(VALUE,0)函数/COALESCE(VALUE,0)
语法: IFNULL(字段,0)
用法: 字段为null,则设为0.(也可设为其他值)
使用场景: 常在计算时转换,因为做加减乘除时,左右数据都不能为null.(计算左右如有为null,计算结果为null)
IFNULL(VALUE,0)仅在Mysql中使用.
在Oracle中使用COALESCE(VALUE,0)函数,效果相同.
13 SQL中大于和等于写法
写法一:
大于等于:
<![CDATA[ >= ]]>
小于等于:
<![CDATA[ <= ]]>
写法二:
大于等于:
>=
小于等于:
<=
14 SQL中时间比较相关问题
比较大小问题
Oracle:
表中数据
日期一: 2021-04-10 12:30:01
日期二: 2021-04-11 00:00:00
要根据年月日比较大小, 要使用to_char函数.
格式: to_char(date,‘format’)
说明:
- 1 参数
date,可以是任意有效的日期格式 - 2 参数
format,必须包含单引号且大小写敏感.(常见'yyyy-mm-dd hh24:mi:ss')
案列
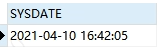
Oracle中查询当前系统时间:
SELECT
SYSDATE
FROM
dual
大于等于比较:
SELECT
SYSDATE ,
CASE
WHEN to_char(SYSDATE,'yyyy-mm-dd') >='2021-04-10' THEN 'YES'
ELSE 'NO'
END
FROM
dual

大于等于比较: (验证说明)
SELECT
SYSDATE ,
CASE
WHEN to_char(SYSDATE,'yyyy-mm-dd') >='2021-04-11' THEN 'YES'
ELSE 'NO'
END
FROM
dual

计算时间相差的天数
Oracle:
在Oracle中计算两个时间相差天数,直接相减.但如果,两个日期的时分秒不同,计算结果出现小数.
在计算中要使用to_date()函数.
格式:to_date(string,‘format’)
说明:用来将字符串转换成date类型的数据.
SELECT
to_date('2021-04-11 00:00:00','yyyy-mm-dd hh24:mi:ss') - to_date('2021-04-10 12:30:01','yyyy-mm-dd hh24:mi:ss')
FROM
dual

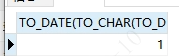
解决方法一:
1 先用to_char,把两个日期变成字符串-年月日 即 2021-04-10 和 2021-04-11
2 再用to_date,把两个字符串变成日期-年月日 即 2021-04-10 00:00:00 和 2021-04-11 00:00:00
3 再把两个日期进行相减 日期二减日期一 等于 1天
因为是模拟日期,所以伪代码多了一层转换:
SELECT
to_date(to_char(to_date( '2021-04-11 00:00:00', 'YYYY-MM-DD HH24:MI:SS'),'yyyy-mm-dd'),'YYYY-MM-DD HH24:MI:SS') - to_date(to_char(to_date( '2021-04-10 12:30:01', 'YYYY-MM-DD HH24:MI:SS' ) ,'yyyy-mm-dd'),'YYYY-MM-DD HH24:MI:SS')
FROM
dual;
解决方法二:
使用trunc()函数.
格式
SELECT
to_date( '2021-04-11 00:00:00', 'YYYY-MM-DD HH24:MI:SS'),
to_date( '2021-04-10 12:30:01', 'YYYY-MM-DD HH24:MI:SS' ),
trunc(to_date( '2021-04-11 00:00:00', 'YYYY-MM-DD HH24:MI:SS')) - trunc(to_date( '2021-04-10 12:30:01', 'YYYY-MM-DD HH24:MI:SS' ))
FROM
dual;

trunc()函数.
作用: 用于截取时间或者数值,返回指定的值.
日期处理:
TRUNC(date,[format])
date 为必要参数,是输入的一个date日期值.
format参数可忽略,指定日期格式,缺省时表示指定日期的0点.
数值处理:
TRUNC(number,[decimals])
number 为必要参数,是输入的一个number数值.
decimals 参数可忽略,指定截取的位数,缺省时表示截掉小数点后边的值.
15 SQL中在SELECT查询列表中使用if条件查询
select
<if test='tag="0"'>
id
</if>
<if test='tag="1"'>
name
</if>
from
user
说明: 当传入的tag='0’时,查询学生的id,当传入的tag='1’时,查询学生的姓名,因为二者其他查询条件一样,所以,可以采用该方法.
16 SQL中if条件查询时等于和不等于格式
1 不等于
<if test="tag!= null and tag != ''">
2 等于
<if test='tag!= null and tag == ""'>
总结:
在不等于判断时,最外层使用双引号,里面使用单引号; 在等于判断时,最外层使用单引号,里面使用双引号.
17 SQL中Escape用法和MyBatis模糊查询特殊字符无效问题
在mybatis中使用模糊查询特殊字符,如%,_,[ ]等,会被当成通配符,造成sql查询异常.
关于上述问题:
1 可由前端过滤掉特殊字符,再调用接口
2 后台直接做过滤去掉特殊字符,再查询
以上两种办法只能做简单的环境下使用.如果数据库中确实存在特殊字符,那么上述方案则不成立.
关于特殊字符查询解决方法:
1 使用SQL中的Escape字段,该字段指明数据库转义的字段
案列:
-- 测试学生表
CREATE TABLE `user` (
`id` bigint(20) NOT NULL COMMENT '主键ID',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`),
KEY `index_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 添加数据
INSERT INTO `test`.`user`(`id`, `name`, `age`, `email`) VALUES (1, 'Jone', 1, 'test1@baomidou.com');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `email`) VALUES (2, 'Jack', 20, '5%st2@baomidou.com');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `email`) VALUES (3, 'Tom', 28, '5est3@baomidou.com');
INSERT INTO `test`.`user`(`id`, `name`, `age`, `email`) VALUES (4, 'Sandy', 21, '5$1111@qq.com');
测试一:
SELECT * FROM `user` where email LIKE '%5%%'

测试二:
SELECT * FROM `user` where email LIKE '%5/%%' escape '/'

综上分析: Escape字段指明了/为转义字符,所以后面的%是一个字符,模糊查询按照5%去查询,案列一种,模糊查询是以5作为条件查询
18 SQL中大于小于的常用表达方式
1 使用转义符号包裹:
- 小于
<![CDATA[ < ]]> - 大于
<![CDATA[ > ]]> - 大于等于
<![CDATA[ >= ]]> - 小于等于
<![CDATA[ <= ]]>
2 使用特殊语法
- 小于
< - 大于
> - 小于等于
<= - 大于等于
>=
19 FIND_IN_SET的使用
FIND_IN_SET(str,strlist)函数
- 可以是字段也可以是字段中的一个数据
- 字段集合或以英文逗号作为分割根据的字符串
-- 测试用户表
CREATE TABLE `userinfo` (
`id` varchar(20) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`age` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 测试数据
INSERT INTO `test`.`userinfo`(`id`, `name`, `age`) VALUES ('1', '1,2', '12');
SELECT
*
FROM
`userinfo`
where FIND_IN_SET('1',name)
-- 运行结果
-- 1 1,2 12
应用场景: 数据库中数据为使用单引号分隔的数据, 根据其中单个数据进行精确查询匹配
20 在数据库BLOB字段转String的方法
1 Mysql
select CONVERT(GROUP_CONCAT(‘Xxx’) USING utf8 from usertable;
2 Oracle
blob长度小于2000
SELECT
UTL_RAW.CAST_TO_VARCHAR2(DBMS_LOB.SUBSTR(字段名称))
FROM
表名
blob长度小大2000, 小于4000
SELECT
UTL_RAW.CAST_TO_VARCHAR2(UTL_RAW.CONVERT(DBMS_LOB.SUBSTR(字段名称, 2000, 1),'SIMPLIFIED CHINESE_CHINA.ZHS16GBK', 'AMERICAN_THE NETHERLANDS.UTF8'))
|| UTL_RAW.CAST_TO_VARCHAR2(UTL_RAW.CONVERT(DBMS_LOB.SUBSTR(字段名称, 2000, 2001),'SIMPLIFIED CHINESE_CHINA.ZHS16GBK', 'AMERICAN_THE NETHERLANDS.UTF8'))
FROM
表名
blob长度大于4000
SELECT
UTL_RAW.CAST_TO_VARCHAR2(UTL_RAW.CONVERT(DBMS_LOB.SUBSTR(字段名称, 2000, 1),'SIMPLIFIED CHINESE_CHINA.ZHS16GBK', 'AMERICAN_THE NETHERLANDS.UTF8')) COLUME_NAME1,
UTL_RAW.CAST_TO_VARCHAR2(UTL_RAW.CONVERT(DBMS_LOB.SUBSTR(字段名称, 2000, 2001),'SIMPLIFIED CHINESE_CHINA.ZHS16GBK', 'AMERICAN_THE NETHERLANDS.UTF8')) COLUME_NAME2,
UTL_RAW.CAST_TO_VARCHAR2(UTL_RAW.CONVERT(DBMS_LOB.SUBSTR(字段名称, 2000, 4001),'SIMPLIFIED CHINESE_CHINA.ZHS16GBK', 'AMERICAN_THE NETHERLANDS.UTF8')) COLUME_NAME3
FROM
表名
21 SQL中in大于1000报错问题
在oracle中查询数据, 使用in条件,条件后面的数据大于1000时,会报错,超过长度限制. 记录解决方法
1 通过截取List (单个查询)
即将List 变成 List<List>, 在sql.xml文件中进行拼接,达到a in(…)or a in(…)效果
1 切割集合
方法一:
List<Integer> list =new ArrayLiat();
List<List<Integer>> list1 = ListUtils.partition(list, 999);
方法二:
private List<List<Integer>> splitList(List<Integer> list, int len) {
List<List<Integer>> result = new ArrayList<List<Integer>>();
int size = list.size();
int count = (size + len - 1) / len;
for (int i = 0; i < count; i++) {
List<String> subList = list.subList(i * len, ((i + 1) * len > size ? size : len * (i + 1)));
result.add(subList);
}
return result;
}
2 组装集合
WHERE id IS NOT NULL
<if test="userids!=null and userids.size()>0" >
and
<foreach collection="userids" item="userid" open="(" separator="or" close=")">
id in
<foreach collection="userid" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</foreach>
</if>
2 通过mybatis拦截器 (全局查询)
通过mybatis框架拦截查询, 对in语句自动转化in or in.
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.cache.CacheKey;
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.SqlCommandType;
import org.apache.ibatis.mapping.SqlSource;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.springframework.stereotype.Component;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Intercepts({
@Signature( // 普通查询
type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}
),
@Signature( // 缓存中查询
type = Executor.class,
method = "query",
args = {
MappedStatement.class, Object.class, RowBounds.class,
ResultHandler.class, CacheKey.class, BoundSql.class
}
)
})
@Component
@Slf4j
public class MbInInterceptor implements Interceptor {
private final Pattern EXEGESIS = Pattern.compile("-- .*\n");
private final Pattern PATTERN = Pattern.compile("\\s+|\t|\r|\n");
private final Pattern IN = Pattern.compile("[A-z0-9._]+ [IN|in]+ \\([, ?]+\\)");
/**
* 返回插件
*/
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
/**
* 设置参数
*/
@Override
public void setProperties(Properties properties) {}
/**
* 拦截执行器,解决 oracle 数据库 sql 语句 in 1000 上限问题
*/
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
if (SqlCommandType.SELECT.equals(ms.getSqlCommandType())) {
Object parameterObject = args[1];
BoundSql boundSql = args.length == 6 ? (BoundSql) args[5] : ms.getBoundSql(parameterObject);
MappedStatement statement = (MappedStatement) args[0];
MappedStatement newStatement = newMappedStatement(statement, new BoundSqlSqlSource(boundSql));
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, buildInSql(boundSql.getSql()));
args[0] = newStatement;
}
return invocation.proceed();
}
/**
* 初始化新的 MappedStatement,替换原本 args 中的第一个元素
*/
private MappedStatement newMappedStatement(MappedStatement ms, SqlSource newSqlSource) {
MappedStatement.Builder builder = new MappedStatement.Builder(
ms.getConfiguration(), ms.getId(), newSqlSource, ms.getSqlCommandType());
builder.resource(ms.getResource());
builder.fetchSize(ms.getFetchSize());
builder.statementType(ms.getStatementType());
builder.keyGenerator(ms.getKeyGenerator());
if (ms.getKeyProperties() != null && ms.getKeyProperties().length != 0) {
StringBuilder keyProperties = new StringBuilder();
for (String keyProperty : ms.getKeyProperties()) {
keyProperties.append(keyProperty).append(",");
}
keyProperties.delete(keyProperties.length() - 1, keyProperties.length());
builder.keyProperty(keyProperties.toString());
}
builder.timeout(ms.getTimeout());
builder.parameterMap(ms.getParameterMap());
builder.resultMaps(ms.getResultMaps());
builder.resultSetType(ms.getResultSetType());
builder.cache(ms.getCache());
builder.flushCacheRequired(ms.isFlushCacheRequired());
builder.useCache(ms.isUseCache());
return builder.build();
}
/**
* 替换超过 1000 的 IN 语句为 ( IN OR IN ) 结构
* @param sql 原 sql 语句
*/
private String buildInSql(String sql) {
sql = EXEGESIS.matcher(sql).replaceAll(""); // 删掉注释
sql = PATTERN.matcher(sql).replaceAll(" "); // 格式化为单行
Matcher matcher = IN.matcher(sql);
while (matcher.find()) {
String inSql = matcher.group();
String[] strs = inSql.split("\\(");
String str0 = strs[0];
String str1 = strs[1].replaceAll("\\)", "").replaceAll(" ", "");
int count = str1.split(",").length;
if (count <= 1000) continue;
List<String> inStr = new ArrayList<>();
int start = 0, end = 0, offset = 1000;
while (end < count) {
end = start + offset;
end = Math.min(end, count);
String str = str1.substring(2 * start, 2 * end - 1);
inStr.add(str0 + "(" + str + ")");
start = end;
}
String newSql = String.join(" OR ", inStr);
newSql = "(" + newSql + ")";
sql = sql.replace(inSql, newSql);
}
return sql;
}
/**
* 声明自己的 SqlSource
*/
private static class BoundSqlSqlSource implements SqlSource {
private final BoundSql boundSql;
public BoundSqlSqlSource(BoundSql boundSql) {
this.boundSql = boundSql;
}
@Override
public BoundSql getBoundSql(Object parameterObject) {
return boundSql;
}
}
}
22 instr函数使用 (Oracle中模糊查询实现方案)
语法:
instr( string1, string2, start_position,nth_appearance )
- string1:源字符串,要在此字符串中查找。
- string2:要在string1中查找的字符串 。
- start_position:代表string1 的哪个位置开始查找。此参数可选,如果省略默认为1. 字符串索引从1开始。如果此参数为正,从左到右开始检索,如果此参数为负,从右到左检索,返回要查找的字符串在源字符串中的开始索引。
- nth_appearance:代表要查找第几次出现的string2. 此参数可选,如果省略,默认为 1.如果为负数系统会报错
使用说明:
instr(name,'李明’)>0 相当于like
instr(name,'李明’)=0 相当于not like
Update information
| Update Time | Update instructions |
|---|---|
| 2021-03-12 22:21:27 | 9 保留两位小数 |
| 2021-03-21 10:58:59 | 10/11 |
| 2021-04-09 22:58:59 | 12/13 |
| 2021-04-10 17:58:59 | 14 |
| 2021-04-29 07:58:59 | 15 |
| 2021-05-19 07:58:59 | 16 |
| 2021-08-30 07:58:59 | 17 |
| 2021-09-22 07:58:59 | 18 |
| 2022-09-25 07:58:59 | 19/20 |
| 2023-05-24 16:58:59 | 21 |
| 2023-05-30 17:22:59 | 22 |















 3660
3660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









