







由于原理较枯燥以及博主水平有限,故本文直接开始实战,需要补原理的读者还请谅解。
背景概述
假设你有一个包含数百个特征的数据集,却对该数据所属领域几乎没有什么了解,并且你需要去探索数据中存在的隐模式。那可谓是数无形时少直觉,根本无从下手,当数据各特征间存在高度的线性相关,这时你可能首先会想到使用 PCA 对数据进行降维处理,但是PCA 是一种线性算法,它不能解释特征之间的复杂多项式关系,而t-SNE (t-distributed stochastic neighbor embedding)是一种用于挖掘高维数据的非线性降维算法,它能够将多维数据映射到二维或三维空间中,因此 t-NSE非常适用于高维数据的可视化操作。
其实说数百维度的数据有些夸张,但是日常生活中10个左右的维度数据很常见,就比如说手写数字数据集,作为机器学习乃至深度学习的启蒙数据集,很多人进行研究,它有10个分类,分别是数字0-9。还有经典的鸢尾花数据集也有3个分类。
本文就以这两个数据集为例,这两个数据集都是经典数据集,具有代表意义,本文不会分开进行介绍,而是采用对比的方法,一起通过代码实现观察2种模型的不同和优缺点。
实战
首先就是导入我们这次实战所需要的一些库。
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris,load_digits
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import time
from sklearn.preprocessing import MinMaxScaler
import seaborn as sns
TSNE和PCA就是今天的主角了。load_iris,load_digits是鸢尾花数据集和手写数字数据集。而MinMaxScaler是一个专门负责数据归一化的库。归一化有很多好处,让数据计算起来快捷,画图方便,本文最后会介绍归一化和matplotlib结合起来画方便得多。
def prepocessing_tsne(data, n):
starttime_tsne = time.time()
dataset = TSNE(n_components=n, random_state=33).fit_transform(data)
endtime_tsne = time.time()
print('cost time by tsne:', endtime_tsne-starttime_tsne)
scaler = MinMaxScaler(feature_range=(0, 1))
X_tsne = scaler.fit_transform(dataset)
return X_tsne
博主这里定义了一个函数,因为后面还会用到所以定义了一个专门用tsne模型来降维的。首先time就不用多说了,小白入门时候讲的计时用的。这里作用就是看看模型所用时间多少,比较一下时间复杂度。MinMaxScaler就是数据归一化的实例了,其中feature_range
在博主关于lstm实战种也有讲过,就是表示标准化到0-1这个区间,也就是归一化了。当然如果不想要这个区间,比如说在某种特定情况下,你需要标准化到10-200,那么这个参数=(10-200)就可以解决了。最后fit一下就出结果。
同样的道理我们也定义一个专门用pca降维的函数,只要输入data,和n维就可以了。
def prepocessing_pca(data, n):
starttime_pca = time.time()
dataset = PCA(n_components=n).fit_transform(data)
endtime_pca = time.time()
print('cost time by pca:', endtime_pca-starttime_pca)
scaler = MinMaxScaler(feature_range=(0, 1))
X_pca = scaler.fit_transform(dataset)
return X_pca
这里我们加载数据,加载完调用函数,把我们的数据和维度输入进去就能得到降到2维下,并且归一化后的数据了。
iris = load_iris()
iris_data = iris.data
digits = load_digits()
digits_data = digits.data
digits_tsne = prepocessing_tsne(digits_data, 2)
digits_pca = prepocessing_pca(digits_data, 2)
iris_tsne = prepocessing_tsne(iris_data, 2)
iris_pca = prepocessing_pca(iris_data, 2)
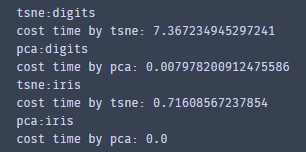
看看输出,我们发现用tsne降维的速度比pca慢了非常多!,几乎pca不用花多少时间,而tsne处理手写数字数据集时候花了7秒。看来时间是tsne一大诟病,不知性能如何,我们且往下看。
我们将降维后的数据可视化一下才能知道结果如何。这里就重点讲解第一个子图吧。先是设立seaborn的风格,个人喜欢,感觉好看。之后一些基本操作。因为我们传入降维函数是2维数据,所以这里scatter的x,y参数对应的就是digits_tsne[:, 0], digits_tsne[:, 1],cmap参数相当于是色盘,调颜色的,能让我们图更容易看出具体特征。这里的c是颜色,颜色对应色盘,而颜色的参数又是手写数字的标签。
举个例子假如这个点的坐标是0.1,0.4,且标签是0,那么这个点的颜色就对应色盘上的第一个颜色。
也就是下面colorbar颜色调的0号颜色。其实就是一一映射的关系了。
sns.set_style("darkgrid") #设立风格
plt.figure(figsize=(18, 8))
plt.subplot(1, 2, 1)
plt.scatter(digits_tsne[:, 0], digits_tsne[:, 1], c=digits.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 10))
plt.title("digits t-SNE", fontsize=18)
cbar = plt.colorbar(ticks=range(10))
cbar.set_label(label='digit value', fontsize=18)
plt.subplot(1, 2, 2)
plt.scatter(digits_pca[:, 0], digits_pca[:, 1], c=digits.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 10))
plt.title("digits PCA", fontsize=18)
cbar = plt.colorbar(ticks=range(10))
cbar.set_label(label='digit value', fontsize=18)
plt.tight_layout()
plt.savefig('D:/桌面/1.png', dpi=300)
最后我们看下效果。可以看到左图是tsne降维后的图,很明显的分块,大概能分成12块,那么有人疑惑了,明明标签0-9只有10个,怎么变成12个了,大家注意看颜色。以红色为例,大概有2块。这是由于本身数据的特征导致的。但是不得不说tsne的降维效果很好。而反观pca的,似乎是一盘散沙。大致分块能看得出来,但是彼此之间交错太多。效果不佳。
这是10维度的降维。tsne完胜。

相对于10维度,那么鸢尾花3个类别算是低的了。那我们来看看在鸢尾花数据集上的表现如何。下面代码功能和上面一样,只是输入改变。
plt.figure(figsize=(18, 8))
plt.subplot(1, 2, 1)
plt.scatter(iris_tsne[:, 0], iris_tsne[:, 1], c=iris.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 3))
plt.title("iris t-SNE", fontsize=18)
cbar = plt.colorbar(ticks=range(3))
cbar.set_label(label='digit value', fontsize=18)
plt.subplot(1, 2, 2)
plt.scatter(iris_pca[:, 0], iris_pca[:, 1], c=iris.target, alpha=0.6,
cmap=plt.cm.get_cmap('rainbow', 3))
plt.title("iris PCA", fontsize=18)
cbar = plt.colorbar(ticks=range(3))
cbar.set_label(label='digit value', fontsize=18)
plt.tight_layout()
plt.savefig('D:/桌面/2.png', dpi=300)
可以看到我们的pca也是很给力的,分为3个类别。但是集群的效果还是不如tsne,但是呢都能很好的看出来3个类别,这正好符合前文背景所说在高纬度上,tsne有着绝对的优势,但是低维度上,也毫不逊色pca。

其实到这里我们就很明白各自的优缺点了,但是博主还想做的更明显点,下面算是另一种体现吧。这个代码的功能是用字符来代替点,很明显的是用的是plt.text,意思是在某个点写某个字符。显然就是写对应的标签字符。也是一一映射的关系。
而plt.cm.Set3就是一个颜色,还有set1,set2,但是set3有11种颜色,我们的有10类别,所以只能用set3了。
plt.figure(figsize=(8, 8))
for i in range(len(digits_tsne)):
plt.text(digits_tsne[i, 0], digits_tsne[i, 1], str(digits.target[i]),
color=plt.cm.Set3(digits.target[i]/11.0), fontdict={'weight': 'bold', 'size': 13}, alpha=1)
plt.savefig('D:/桌面/3.png', dpi=300)
这是tsne降维后的结果,很直观的看到下图每个分类在各自的小地盘上。
pca也是同理,只是换下数据,博主就不再赘述,感兴趣的读者也可以当作是你们的小实战吧。

我们来看看在三维空间上的tsne效果如何。这段代码就是把之前降维到二维平面改成降维到三维平面。图的原理是一样的。是写而不是画。
X = prepocessing_tsne(digits_data, 3)
fig = plt.figure(figsize=(10, 10), dpi=100)
y = digits.target
ax = fig.add_subplot(1, 1, 1, projection='3d')
for i in range(X.shape[0]):
ax.text(X[i, 0], X[i, 1], X[i,2],str(digits.target[i]), color=plt.cm.Set3(y[i]/11.0), fontdict={'weight': 'bold', 'size': 13}, alpha=1)
plt.savefig('D:/桌面/4.png', dpi=300)
最后的结果。可以看到分块非常明显。而pca是做不到这一点的,感兴趣的小伙伴可以试着写写用pca在三维空间是什么样。

总结
总结一下,tsne在高维度数据有着绝对的优势,能够碾压其余降维模型,在低维度的数据也毫不逊色任何一种。但是缺点也很明显,性能的代价往往是时间,它的时间复杂度过高。















 3281
3281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









