







什么是k近邻?
通俗来讲就是物以类聚,人以群分。具体来讲就是说,同一类别的东西其实是存在非常多的相同的特点,那么我们就可以通过某个某个样本的特点从而预测出它是什么类,或者我们可以通过看一个样本周围的样本都是什么类别,进而预测出它是什么类别,毕竟相同的东西扎堆存在。
所以说,既然是通过它周围的东西推导出它是什么类,那么“周围”到底怎么定义,所以就不得不引入一些距离衡量的东西,那么接下来看一些测量距离的名词。
欧氏距离:其实就是之前我有提到过的二范数,其实也可以理解为两点间的距离,公式如下:就是它们坐标相减的平当在相加,然后再开一个根号,具体写开就是【(x1-x2)^ +(y1-y2)^ +(z1-z2)^ +……+( - ) 】1/2 ,其实还是很好理解的。
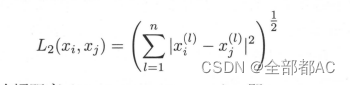
曼哈顿距离其实也就是一范数,具体就不展开说明了,公式如下
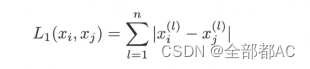
P范数根据如上的规律我们就可以定义出p范数的公式,如下,就不系展开讲了
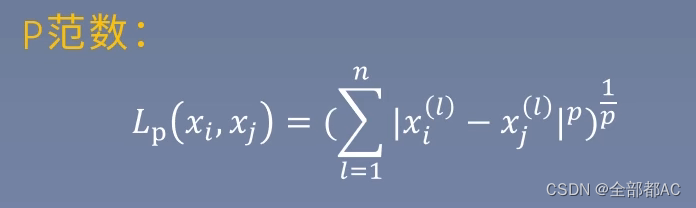
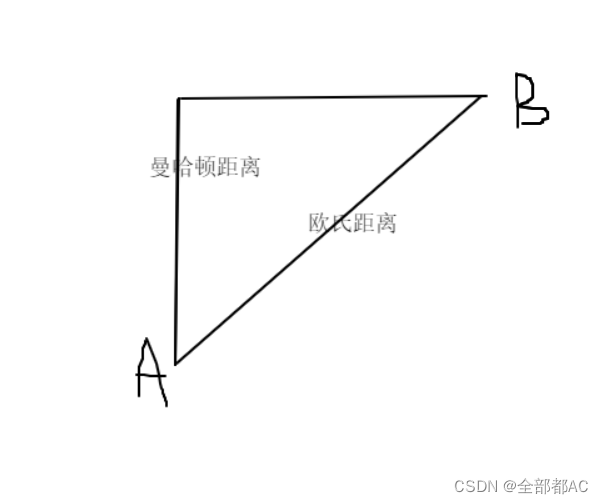
前面提到了不同的范数,我们按照他的几何意义来理解一下他们所代表的真是意义,如图所示AB间的直线距离就被称为欧氏距离,从A到B的距离被称为曼哈顿距离,又被称作是城市街区距离,这也很好理解的。
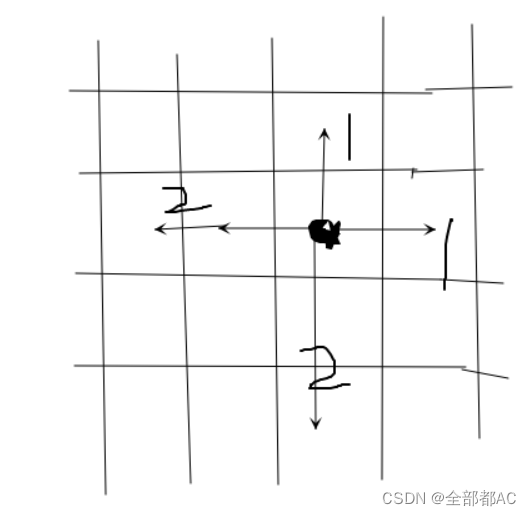
切比雪夫距离它指的是类似于棋盘上,棋子相邻之间的距离,所以也被称为棋盘距离,具体的几何意义如下图所示:
K怎么选?
1、K选小了会怎么样?
如果k的值过小他会使得预测的结果很敏感,特别依赖于它最邻近的很少的几个类别,假如说刚好最近的恰恰就几个就是噪声点,那么结果就会出现明显的偏差。
2、K选大了会怎么样?
如果k值过大,那么对于离它很远的一些样本也会对它的预测造成干扰,因为距离过大就很难保证他们还是一类的。
3、正确的选择方法
先用小一点的k,再通过交叉验证逐渐调大(就是在验证集上不断测验他的准确性),那么此时它周围的样本类别就可以代替它的类别了。
分类决策规则
k近邻法中的分类决策规则往往是多数表决,即由输入实例的 个邻近的训练实例中的多数类决定输入实例的类。















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









