







 Adaptive Softmax算法旨在解决自然语言处理中词汇量巨大导致的softmax计算效率低下问题。通过利用单词分布不均衡,将词汇表分成高频和低频两部分,优化计算过程,尤其适合GPU环境。通过调整不同类别的容量,进一步提高计算效率,降低时间复杂度。
Adaptive Softmax算法旨在解决自然语言处理中词汇量巨大导致的softmax计算效率低下问题。通过利用单词分布不均衡,将词汇表分成高频和低频两部分,优化计算过程,尤其适合GPU环境。通过调整不同类别的容量,进一步提高计算效率,降低时间复杂度。
参考链接
- 论文链接:https://arxiv.org/pdf/1609.04309v3.pdf
- 项目链接:https://github.com/facebookresearch/adaptive-softmax
Introduction:
- 本文提出是的方法是adaptive softmax, 该算法目的是为了提高softmax函数的运算效率,适用于一些具有非常大词汇量的神经网络。
- 在NLP的大部分任务中,都会用到softmax,但是对于词汇量非常大的任务,每次进行完全的softmax会有非常大的计算量,很耗时。所以paper中提出adaptive softmax来提升softmax的运算效率。
- adaptive softmax的特点
- 该算法的提出利用到了单词分布不均衡的特点(unbalanced word distribution)来形成将单词分成不同的类, 这样在计算softmax时可以避免对词汇量大小的线性依赖关系,降低时间复杂度;
- 另外通过结合现代架构和矩阵乘积操作的特点,通过使其更适合GPU单元的方式进一步加速计算。
Computation time model of matrix-multiplication:
- 大部分语言模型的瓶颈在于:隐藏状态的矩阵 H ∈ R B × d H∈R^{B×d} H∈RB×d(B=batch size,d为隐藏层状态维度)与词汇表矩阵 E ∈ R d × k E∈R^{d×k} E∈Rd×k(k=词汇表的大小)之间的矩阵相乘。
- 假设将 d d d和 B B B固定,下图为两个GPU模型K40和M40矩阵乘法时间随 k k k的变化图:
我们将上图的曲线记为函数 g ( k ) g(k) g(k),我们可以看到,大概在 k < k 0 ≈ 50 k<k_0≈50 k<k0≈50时,时间 g ( k ) g(k) g(k)是一个常量。直到 k > k 0 k>k_0 k>k0时, 时间 g ( k ) g(k) g(k)变成成了一个线性函数。
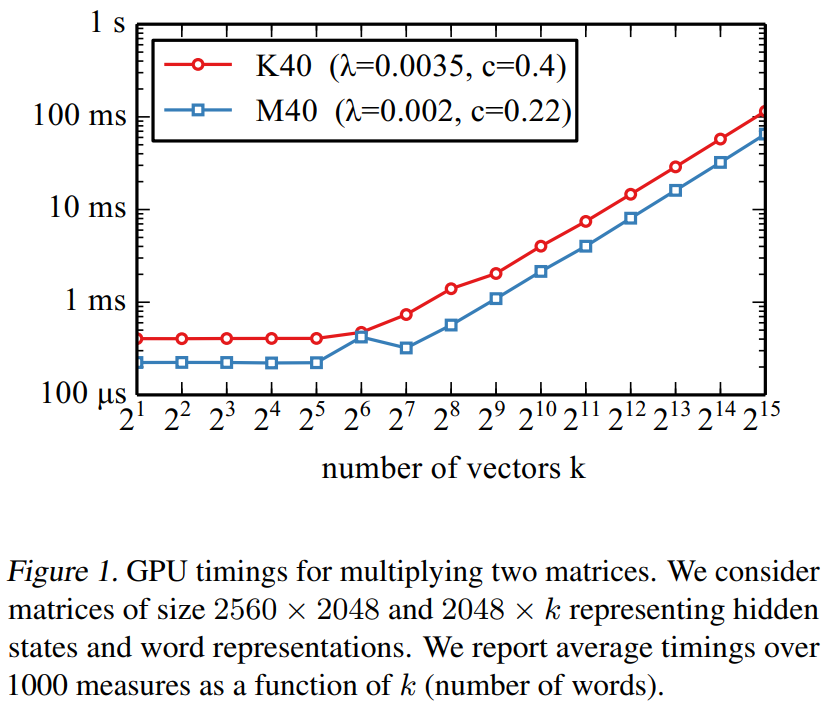
- 因此假设g(k)的表达式如下: g ( k ) = m a x { c + λ k 0 , c + λ k } = c m + m a x { 0 , λ ( k + k 0 ) } g(k)=max\{c+\lambda k_0,c+\lambda k\}=c_m+max\{0,\lambda (k+k_0)\} g(k)=max{ c+λk0,c+λk}=cm+max{ 0,λ(k+k0)}在K40上 c m = 0.4 c_m=0.4 cm=0.4,在M40上 c m = 0.22 c_m=0.22 cm=0.22.
- 同样的,假设将 d d d和 K K K固定,模型K40和M40矩阵乘法时间随 B B B的变化也呈现上面这样的关系。
- 这就表明矩阵相乘时,当其中一个维度很小时,矩阵乘法是低效的。也就是说计算大量小矩阵是不划算的,很容易理解,数据传输、函数调用开销等也需要消耗时间。也说明了,按层次来组织words时,如果中间节点有较少的子节点时 (比如huffman 编码的tree)是次优的。
- 所以paper中综合考虑了 k k k与 B B B,提出了下面的计算时间模型: g ( k ; B ) = m a x ( c + λ k 0 B 0 ; c + λ k B ) g(k; B) = max(c + λk_0 B_0; c + λkB) g(k;B)=max(c+λk0B0;c+λkB)
two-clusters case:
- 这部分讲解将词汇表分成两个类的Adaptive softmax模型。
- 在自然语言中,单词的分布遵循Zipf定律。大部分的概率被词典中一小部分词所覆盖,例如,在Penn TreeBank中87%的文档只被20%的词汇所覆盖。
- 首先将将词汇表 V V V分成两部分 V h V_h Vh和 V t V_t Vt, V h V_h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3627
3627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









