









是一篇综述性文章。
作者为了得知当前最好的检测方法还有多大发展空间,采取的方法就是将当前较好的检测方法与人工检测做对比。

人工检测方法:从头顶到双脚之间画一道线,框出人所在的位置。
对比方式:自动检测方法画出的方框如果与人工检测的方框重合度达到50%以上,就认为检测到了此行人。
对比结果:最好的检测方法也比人工检测的效果差了10%。
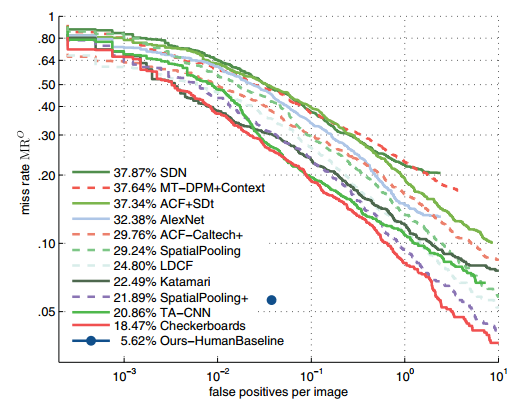
P.S.checkerboards最好,checkerboards其实是Integral Channel Feature的一种。
所以作者提出这篇文章要解决的问题:
如何缩小甚至消除机器检测准确率与人工检测准确率之间的差距?
首先分析为什么机器检测有时候会出错,然后再改进出错的地方,性能自然就提升了。
先分析检测方法的问题。
检测方法主要有三方面的问题:False Positive (误报)、False Negative(漏报)、Poor Alignment(校准错误)
先分析False Positive的种类,作者统计了一下,主要分三类:重复框出同一个人象、框出了完全没有行人的背景、忽略了一部分存在行人的区域(数据集中的标签错误)
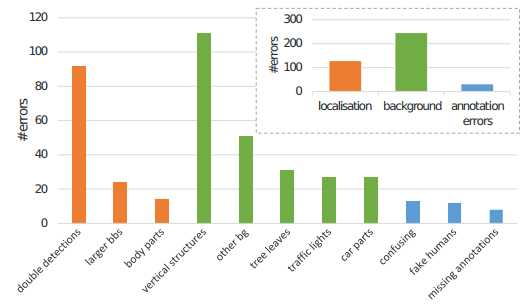
举例:


再分析False Negative的种类,作者统计了一下,主要分三类:没有检测到乘坐交通工具的人、没有检测到只漏出侧面的人、没有检测出过小的和重叠的人
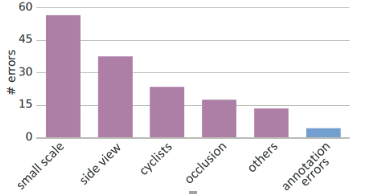
最后举例Poor Alignments的情况:

提出对于这些错误的解决办法:
False Positive:
| 重复框选同一人问题 | 当选中人时,模仿手工框选的方法绘制从头到双脚间的标准线。 同时选中框要按照这个人最大可见区域绘制,来保证把行人最大范围地选中。 |
| 选中无行人区域问题 | 检测器需要结合垂直方向的图像上下文来探测物体,不能局限于图像的一个小部分,也可以事先对物体高度进行粗略地估计。 |
| 忽略部分区域 | 给训练集中数据打标注时,应该通过观看整个影像来确定行人是否存在, 要把一些容易被忽视的区域也标注出来,如:人群、海报和雕像中的人以及不确定是否包含行人的区域。 |
False Negative:
| 交通工具问题 | 在训练集中额外添加行人乘坐交通工具的图片 |
| 行人侧身问题 | 在训练集中额外添加行人侧身的图片 |
| 人象过小和重叠问题 | 对训练集和测试集图片进行重新标注 |
采取了新的数据集(新的数据集为对旧的数据集中的图片进行重新标注)
新的与旧的区别:
1.把以前被忽视的区域和人群都标注出来。
2.标注结果不是从单张图片得来的,是从整个视频影像得来的。
3.可以对同一张图片的标注进行多次校正。
进行了实验:用新的/旧的测试集在新的/旧的/INRIA上测试。
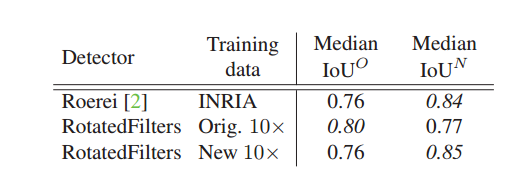
结果:
1.使用原始标注进行测试时只有原始数据集表现较好。
2.使用新型标注进行测试时,INRIA和使用了新型标注的数据集都表现得比1的结果好。
在前景背景识别方面又加上了卷积神经网络:VGG 和AlexNet
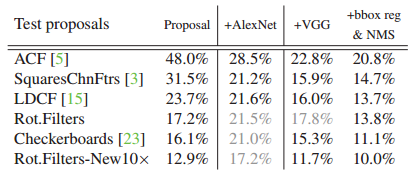
结论:
1.AlexNet不能一直保持优势。
2.VGG也类似,在与效果较差的检测器对比时,效果有提高,但当使用较好效果的检测器时,VGG就会出问题。
但VGG又比AlexNet强。
3.再加上边框回归+NMS效果较好。
因此:
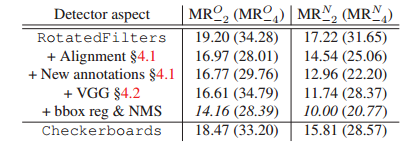
RotatedFilters+图像校准+新标注的数据集+VGG+边框回归NMS是较好的选择。
本文结论:
通过人工对图片进行行人检测,得出了对于自动探测器探测准确率的期待值。深入分析了为什么当前的优秀探测器没有达到这个标准。对于不同的检测错误提出了相应的解决方案,相信在未来机器与人在行人检测方面的差距将进一步缩小。















 4720
4720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









