







集合
一、集合概念
对象的容器,相当于存放对象的数组
区别:
(1)数组长度固定,集合不固定
(2)数组可以存储基本类型和引用类型, 集合只能存引用类型
二、Collection体系集合
1.Collection父接口
特点:代表一组任意类型的对象,无序、无下标、不能重复。
方法:
三、List体系集合
它继承了Collection
1.List子接口
特点:有序、有下标、元素可重复
方法: 实现类:(数据结构)
实现类:(数据结构)
【ArrayList】重点:
数组结构实现, 查询慢, 增删慢
运行效率快,线程不安全
【Vector】:用的比较少
数组结构实现,查询快,增删慢
运行效率慢,线程安全(因为加锁了)
【LinkedList】:
链表结构实现,增删快,查询慢
四、List 接口常见特点:有序且有下标, 可重复
五、List常见类
ArrayList:
源码分析:
DEFAULT_CAPACITY=10
// 集合添加元素后默认容量为10
// 没有添加,默认容量是0
elementData 存放元素的数组
size=0; 实际元素个数 注:size!=容量
add(S1);
每次扩容到原来的1.5倍
Vector:(源码分析忽略)
LinkedList:(源码分析略。就是数据结构内容)
ArrayList和LinkedList区别:(数据结构内容)
六、泛型
本质:参数化类型,把类型作为参数传递
常见形式:泛型类、泛型接口、泛型方法
语法:<T,…> T称为类型占位符,表示一种引用类型。
好处:提高代码重用性,防止类型转换异常,提高代码安全性
泛型集合
概念:参数化类型,类型安全的集合,强制集合元素的类型必须一直
特点:编译时即可检查,而非运行时就抛出异常;
访问时,不必类型转换
不同泛型之间引用不能相互赋值,泛型不存在多态
七、Set集合
没有顺序,没有下标,不能重复
继承自Collection
HashSet【重点】:
基于HashCode计算元素存放位置。
当存入元素的hash码相同时,会调用equals进行确认。
存储结构:哈希表(数组+链表+红黑树)
TreeSet:
基于排列顺序实现元素不重复
实现了SortedSet接口,对集合元素自动排序。
元素对象的类型必须实现Comparable接口,指定排序规则
通过CompareTo方法确定元素是否重复。
八、Map集合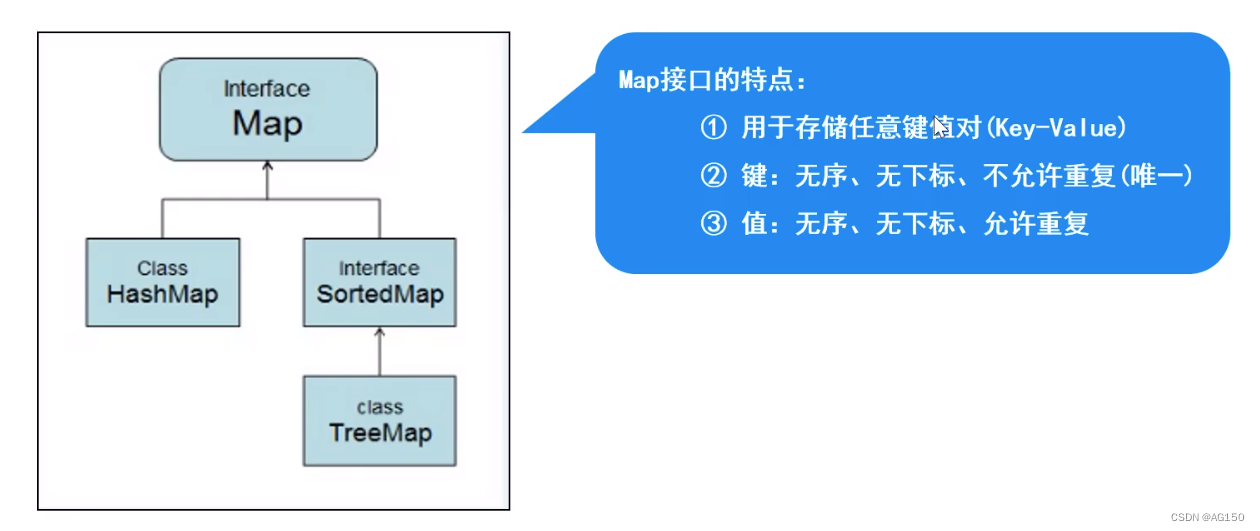
值可以对应多个键,但键只能对应一个值
方法:
HashMap【重点】
JDK1.2版本,线程不安全,运行效率快;允许使用nul作为key或者value
刚创建好HashMap没有添加元素, table=Null, size=0
数组等也是同理,没有必要一开始就占用空间
1)HashMap刚创定时,table是null,为了节省空间,添加第一个元素时,table容量调整为16
2)当元素个数>阈值(16*0.75=12)制,会进行扩容,扩容后大小为原来的2倍。目的是减少调整元素的个数。
3)jdk1.8 当每个链表长度>8,并且元素个数≥64时,会调整为红黑树,目的是提高执行效率
4)jdk1.8当链表长度<6时,调整成链表
5)jdk1.8以前,链表时头插入,jdk1,8以后是尾插入
Hashtable
JDK1.0版本,线程安全,运行效率慢;不允许null作为key或是value
Properties
Hashtable的子类,要求key和value都是string,通常用于配置文件的读取
TreeMap
实现类SortedMap接口(是Map的子接口),可以对Key自动排序
九、Collections集合工具类
概念:定义了除了存取以外的集合常用方法
方法:















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









