






前言:抢先看!AGI-Eval 官方新鲜出炉的 DeepSeek能力评测报告首发!三大类型,多个新模型能力评测榜单直出。

目录
1. Deepseek新模型概览&整体结论
2. 通用评测结果
2.1 内部评测结果
2.2 公开评测结果
2.3 DeepSeek-V3-Base 基座模型评测结果
3. 推理专项评测结果
3.1 数学推理
3.2 代码推理
3.3 学科知识和推理
4. Janus Pro评测结果
4.1 理解能力
4.2 生成能力
最近 DeepSeek 的知名度突破圈层,大家都在进行操作尝试,不同媒介和平台都在关注,但是具体 DeepSeek 的模型能力的水位线在何处,与其他头部厂商以及 OpenAI 的能力差异如何,这个信息还没有公开权威的披露,此次 AGI-Eval 评测社区通过自建私有数据集及公开数据集做了多个维度的模型评测分析,输出一版全面、公正、权威 DeepSeek 最新模型的能力评测报告。
01 DeepSeek新模型概览&整体结论
先看 DeepSeek 新模型概况以及整体结论:

在通用模型和推理系模型的表现上 DeepSeek 都处于第一梯队,但在原生多模态模型上 DeepSeek 能力仍有空间,整体处于第三梯队,此次报告内容针对模型各能力项排名进行综合展示,后续将结合更多数据和 Case 做深度能力解析和拆分。
02 通用模型
【评测对象】:DeepSeek-V3-Chat 及 DeepSeek-V3-Base
【评测方式】:基于自建通用评测版本主客观评测相结合,全面衡量模型综合能力
【评测结论】:
-
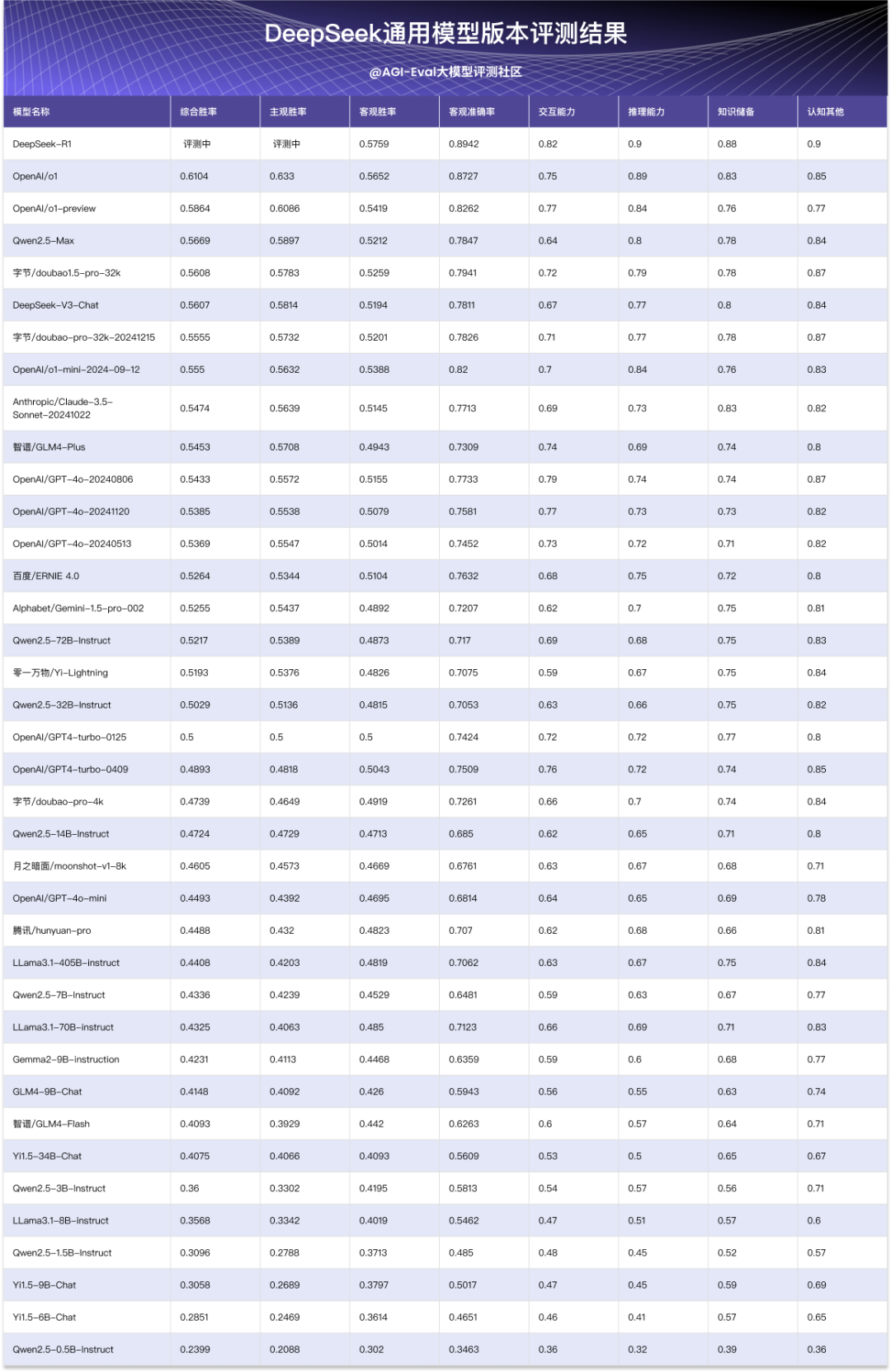
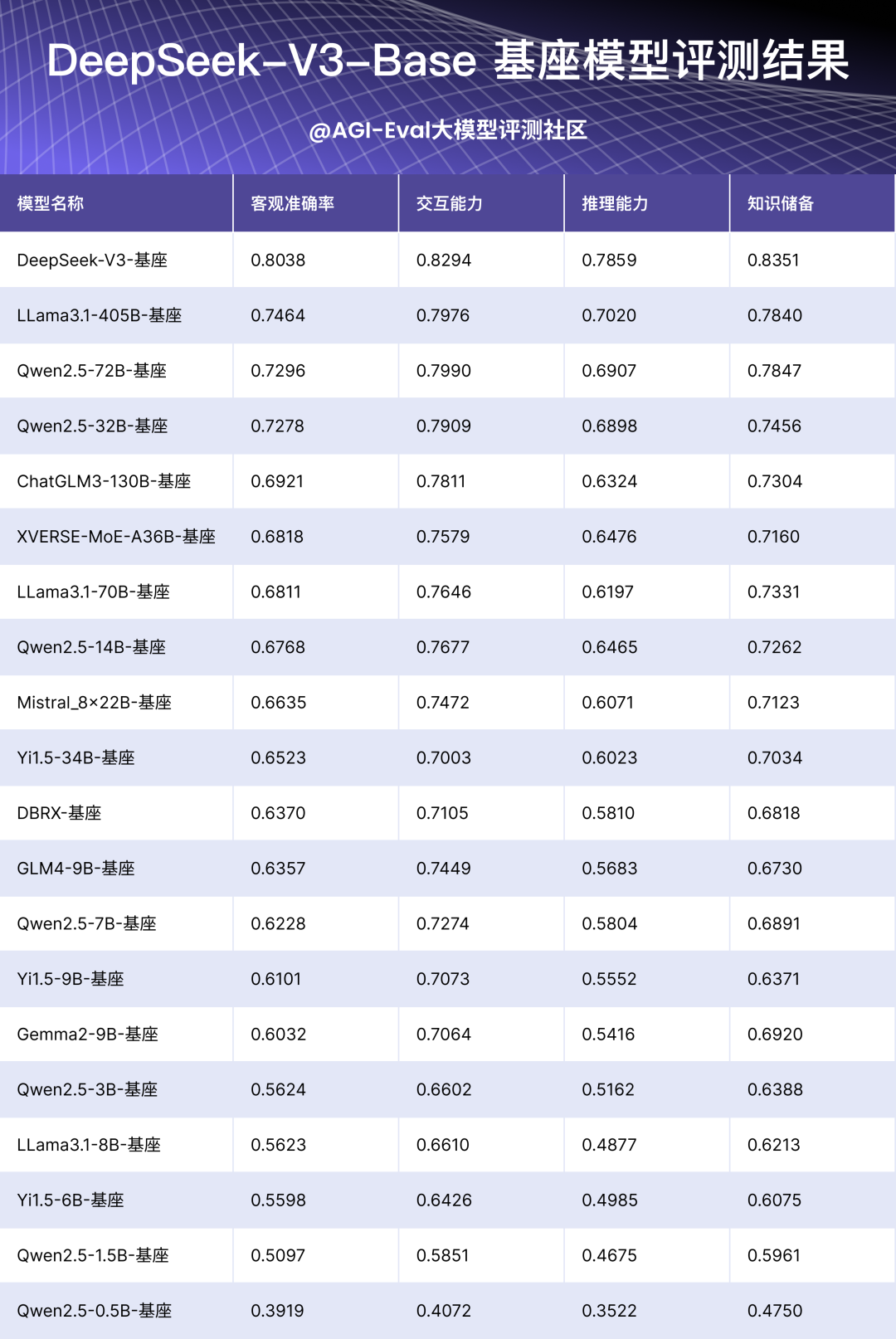
DeepSeek-V3-Chat 处于头部第一梯队,和 Claude3.5-Sonnet、Doubao1.5-Pro、Qwen2.5-Max 能力相当,相较 o1仍有差距;DeepSeek-V3-Base 模型处于开源基座 Top1;
-
通用能力方面,各维度表现较为均衡,无明显短板,代码能力突出;在数学和高难度学科上和头部模型还存在差距;
-
交互能力方面,英文及多轮交互相较头部模型仍有提升空间;
【特别注释】:
-
Doubao1.5-Pro:自建评测结果中能力和 DeepSeek-V3 能力相当,但在 Doubao1.5-Pro 发布提供评测结果中,微弱优于 DeepSeek-V3。
-
Qwen2.5-Max能力相当:自建评测结果中能力和 DeepSeek-V3 能力相当,但在 Qwen2.5-Max 发布提供评测结果中,Qwen2.5-Max 微弱优于 DeepSeek-V3。
2.1 内部评测结果
内部评测由综合客观评测及中文单轮主观评测构成,最终评测结果如下:
【指标注释说明】
-
客观评测准确率指标说明:模型回答正确数量/总评测数据总量;
-
主观评测胜率指标说明:(1*N_明显好+0.75*N_稍好+0.5*N_二者差不多+0.25*N_稍差+0*N_明显差)/总评测数据量
* 评测指标是被评测模型相对于标杆模型的五档加权胜率
*标杆模型为 GPT4-turbo-0125
2.2 公开评测结果
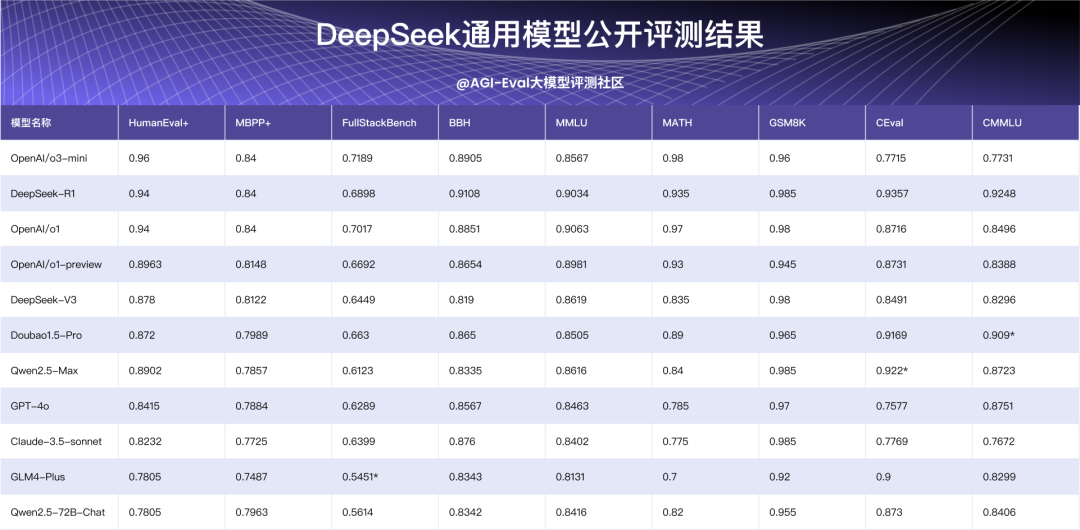
注:上标*的数据为直接采用的外部数据,其余为内部复现评测的结果。
2.3 DeepSeek-V3-Base 基座模型评测结果
当前稳定评测版本评测结果如下:
03 推理系模型
【评测对象】:DeepSeek-R1
【评测方式】:以推理专项评测为主(包含数学推理、代码推理、学科知识和推理),突出推理能力上的突破;辅以自建通用评测版本,体现综合能力。
【评测结论】:
-
推理方向整体:DeepSeek-R1 和 o1 处于第一梯队,能力水平相当。
-
数学推理方面:DeepSeek-R1 全面超越了 o1-mini,在初等数学领域的正确率接近 97%;在大学数学和竞赛数学方面更是超越了 o1。在应对更复杂的题目时,DeepSeek-R1 展现出更加显著的领先优势。
-
代码推理方面:DeepSeek-R1 与 o1 系列各有优势。R1 在竞赛级别算法题上表现更优、且和其他非推理模型拉开显著差距;o1 则在基础编程题目上表现更好。
-
学科知识及推理方面:DeepSeek-R1 全面超越 o1-mini;在竞赛学科方面超越 o3-mini、o1,在高中及大学学科方面与 o3-mini、o1 能力接近。
模型配置说明:R1、R1-Zero 模型在 Temperature 为 0 时思维链易崩坏,故按照官方推荐设置,Temperature 设置为 0.6 ,会带来一定的结果波动。其余模型 Temperature 均为 0
【特别注释】:
-
DeepSeek-R1-Zero:只经过强化学习(RL),不依赖人类专家标注的监督微调(SFT)
-
OpenAI/o1 pro mode:官方无API,需在网页端手动请求,故仅完成Math Pro Bench
3.1 数学推理
此次评测的数据推理测试集包括公开测试集及自建私有数据集
公开数据集
-
中英文均包括的数据集:OlympiadBench、MathBench
-
中文数据集:CMMLU-Math、CEval-Math、MathGLM、GaoKao
-
英文数据集:MMLU-Math、GSM8K、MATH
私有数据集
主要分为四个部分,其中 Math Pro Bench 可跳转 AGI-Eval 官方平台的评测集处查看https://agi-eval.cn/evaluation/home
-
OlympicArena-Math:上海交通大学刘鹏飞团队发布的数据集,未公开测试集答案,AGI-EVAL大模型评测社区通过合作获取到了全部测试集的答案,共 2,742 题
-
Math Pro Bench:2023 年考研数学填空题+2024 年高中数学竞赛一试,共 104 题
-
MO Bench:寻找外部供应商,自建高中数学竞赛题,共 38 题
-
CM Bench:寻找外部供应商,自建大学数学题,包含代数学、分析学、几何学、统计学、离散数学、计算数学、应用数学 7个部分,共 3,260 题
公开评测结果
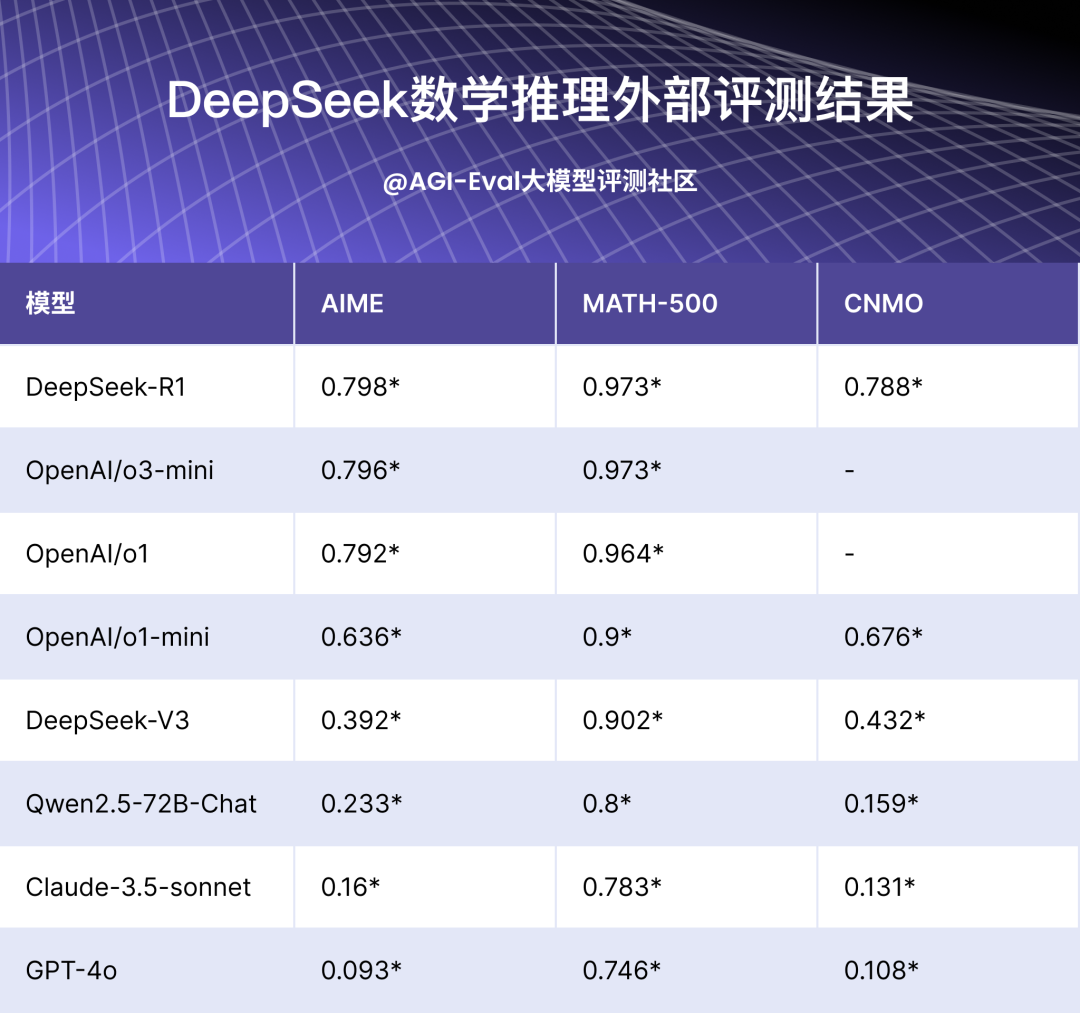
注:上标*的数据为直接采用的外部数据
内部评测结果
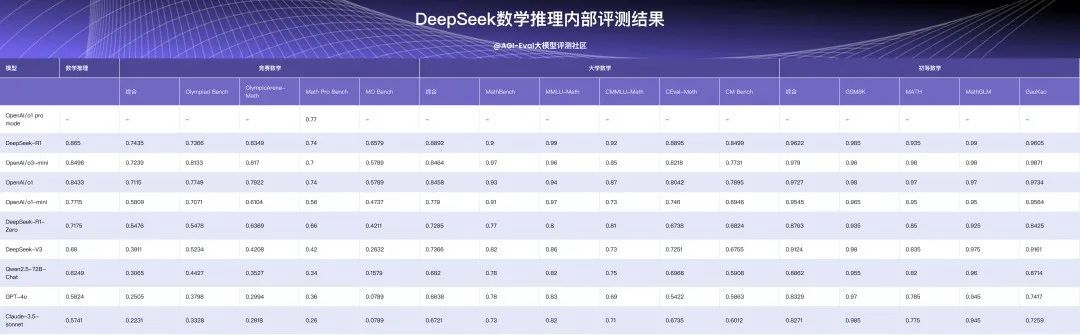
注:上标*的评测集为私有评测集,o1 pro mode 测试时无 API 接口,只测试了单一评测集。
3.2 代码推理
此次评测的数据推理测试集主要包括以下7个部分:
-
OI Bench:收集自高校教师私有的 ACM 竞赛难度选拔题,在题目中会提供伪代码题解,难度中等偏高。包括 Python、 C++、 Java、 JS 四种语言。
-
OI Bench hard:和 OI Bench 同源、收集自高校教师私有的 ACM 竞赛难度选拔题,去除了题目中的题解信息,难度高。包括 Python、 C++、 Java、 JS 四种语言。
-
LeetCode:收集自 LeetCode 周赛的算法题目,难度中等。包括 Python、 C++、 Java、 JS 四种语言。
-
HumanEval+:OpenAI 提出的一个基准数据集,关注使用函数实现基础算法和数据结构,难度较低,仅包括 Python。
-
MBPP+:Google 研究团队推出的一个数据集,关注使用代码实现一些常规的字符串操作、数据结构处理、数学计算等任务,难度中等偏低,仅包括 Python。
-
NL2CodeBench:由 AiXcoder 提出的一个方法级别的基准数据集,专注于评估模型基于自然语言作简单开发需求的能力、涉及 Java/Python 实际开发中的 API 调用、开发知识等考察,难度中等偏高,包括 Python、 Java 两种语言。
-
FullStackBench:是由字节跳动推出的多语言全栈编程评估基准,收集/改编于 StackOverflow 上的真实开发问题、包括服务端开发、网页开发、数据分析、机器学习等领域,难度中等。涉及 16 种编程语言,包括但不限于 Python、Java、C++ 等。
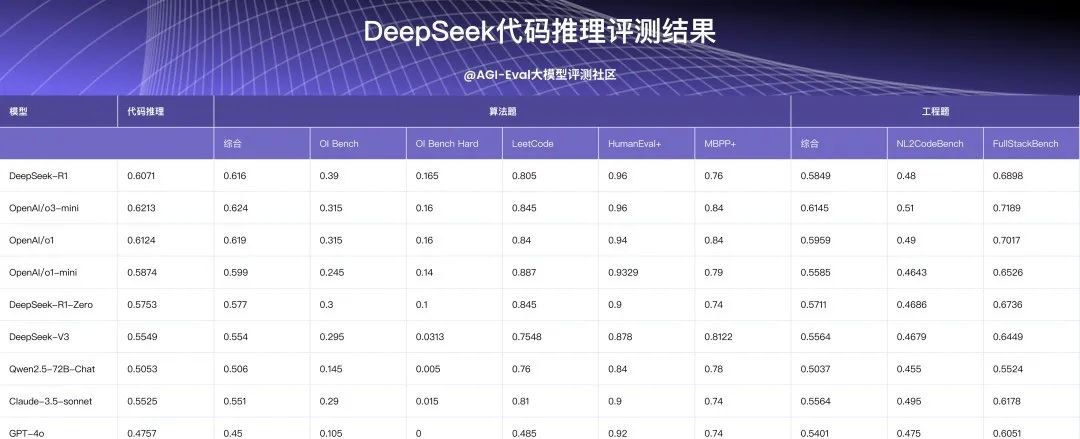
注:上标*的评测集为私有评测集
3.3 学科知识和推理
此次评测的数据推理测试集主要包括以下 4 个部分,其中 MDK Bench 可跳转 AGI-Eval 官方平台的评测集处查看 https://agi-eval.cn/evaluation/home
-
MDK Bench:AGI-Eval 大模型评测社区同华东师范大学合作建设私有学科黑盒评测集,包含9个学科,共4,377题
-
OlympicArena-Subject:上海交通大学刘鹏飞团队发布的竞赛学科评测集,物理、化学、生物、地理、天文5个学科。未公开测试集答案,AGI-EVAL大模型评测社区通过合作获取到了全部测试集的答案
-
MMLU:高中及大学学科公开评测集,包括人文社科、STEM等共57个学科
-
GPQA-Diamond:研究生学科公开评测集,包括物理、化学、生物3个学科
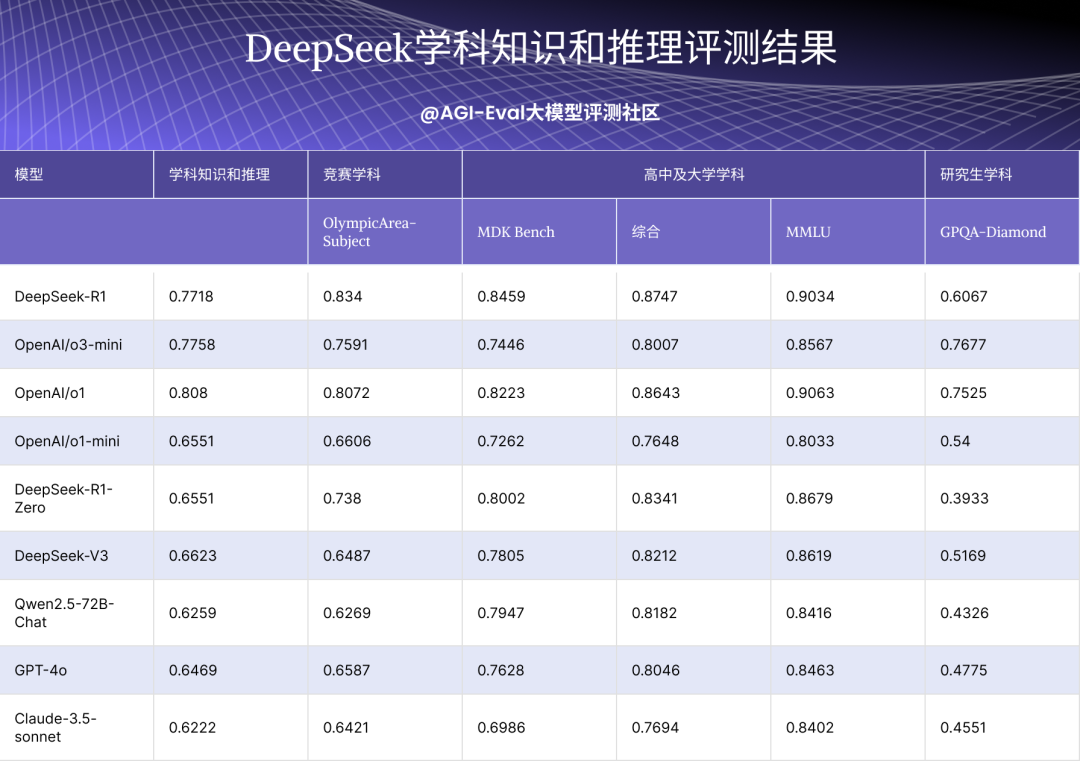
注:上标*的数据为直接采用的外部数据,其余为内部复现评测的结果;上标*的评测集为私有评测集
04 原生多模态模型
【评测对象】:Janus Pro
【评测方式】:基于自建通用评测版本,包含理解与生成两个方向的主客观评测
【评测结论】:
-
理解能力方面,Janus Pro-7B处在第三梯队,强于相近参数量的生成理解统一模型Emu3-8B,但与理解类模型Qwen2-VL-7B有明显差距
-
生成能力方面,图像文本一致性维度上 Janus Pro 处在第三梯队头部,强于 hunyuanDit 和 kwai-kolors 以及原生多模 Emu3,但弱于技术报告中宣称胜出的头中部模型 DALL-E3 与 SD3-Medium。图像生成质量维度上处在第三梯队末尾,弱于上一代开源专家模型和原生多模 Emu3。
4.1 理解能力
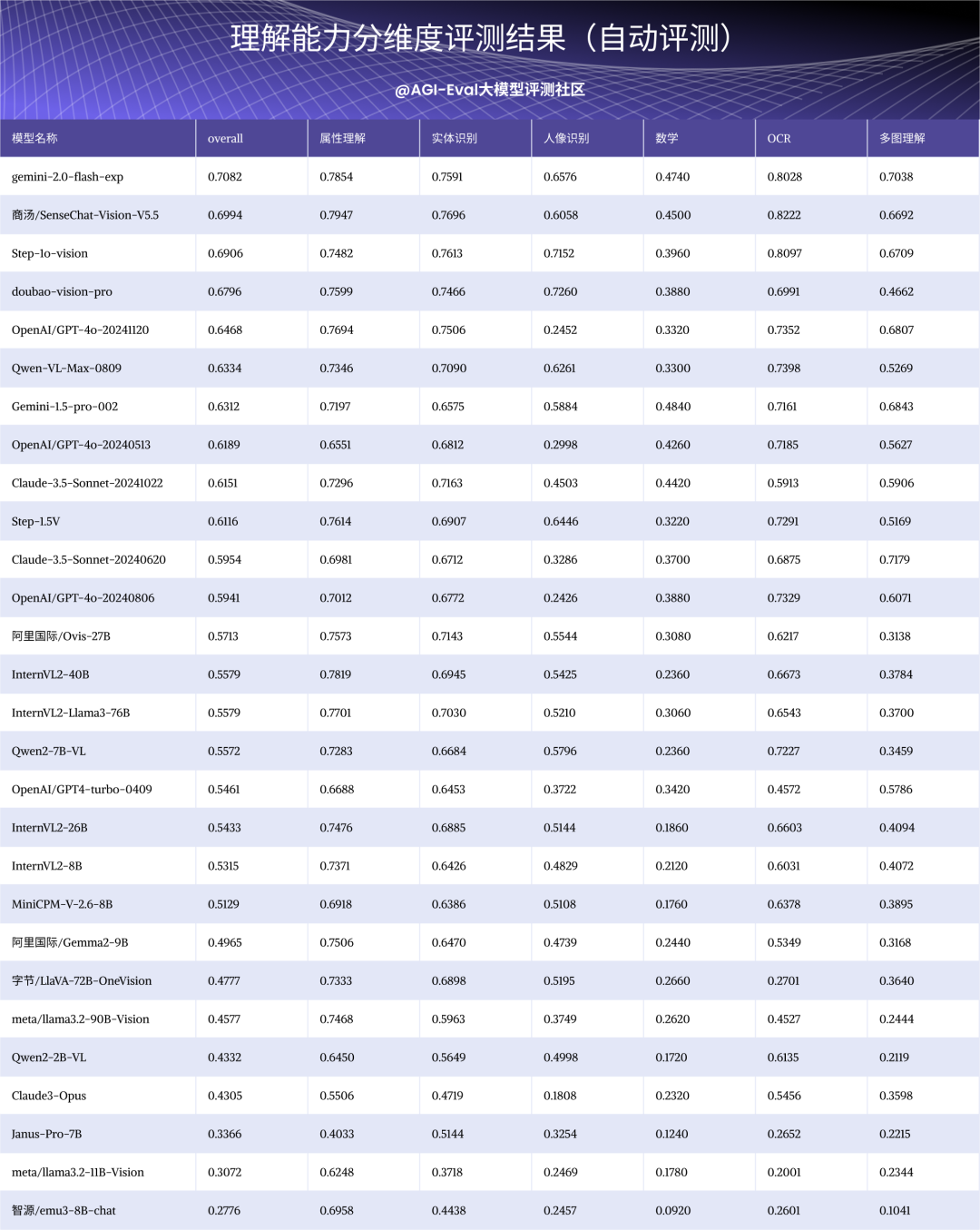
【理解能力整体结论】:
-
排在第三梯队,弱于业界第二梯队中具备相近参数量理解类模型,显著弱于Qwen2-VL-7B(技术报告宣称胜出的是23年8月发布的第一代版本而非最新版本)。
-
与生成理解统一模型进行比较,强于相近参数量的开源模型Emu3。
【具体说明】:
-
基础感知:不能准确理解场景、风格、颜色等;在涉及人像、空间位置、计数时相对较好。
-
数学:不具备基础几何和数学推理能力。
-
OCR:仅能识别简单数字和英文短语,完全不具备中文识别能力,图表理解能力也较弱。
-
多图理解:可对简单图片进行图文匹配,难以处理多个复杂图片。
【特别注释】:
-
理解类较好的模型:Qwen2-VL-7B,InternVL2-8B,MiniCPM-9B,Gemma2-9B,Qwen2-VL-2B
-
基础感知:包括属性感知、实体识别与人像识别
分维度
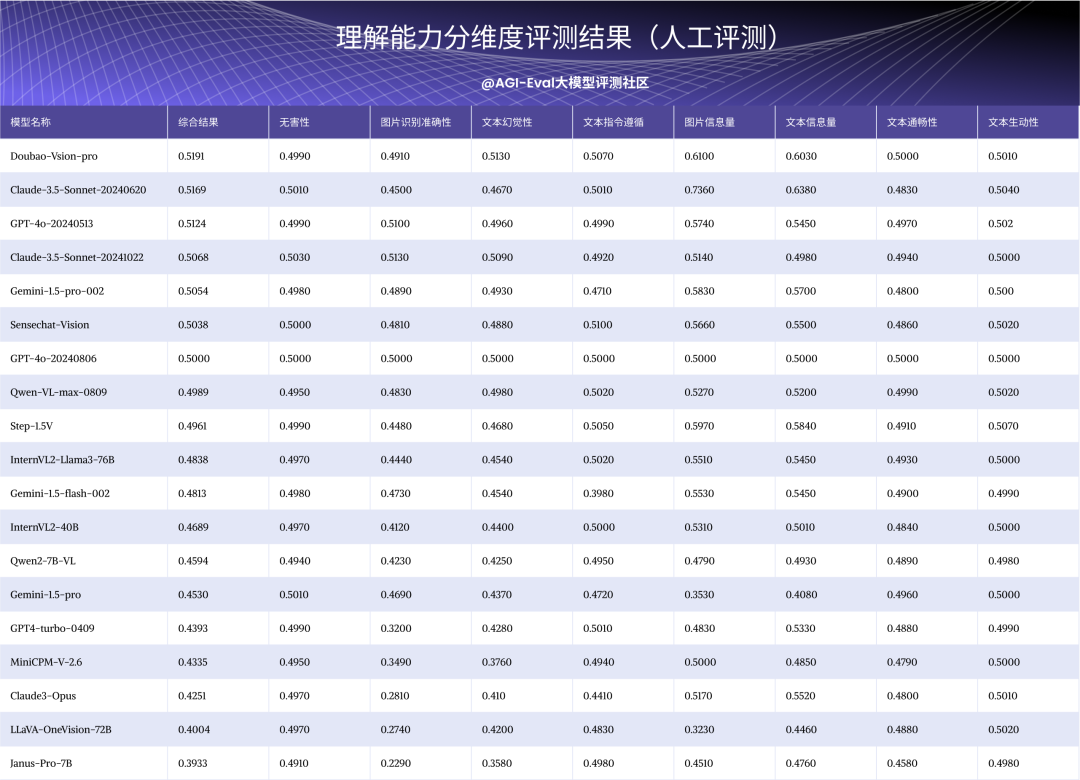
人工评测
4.2 生成能力
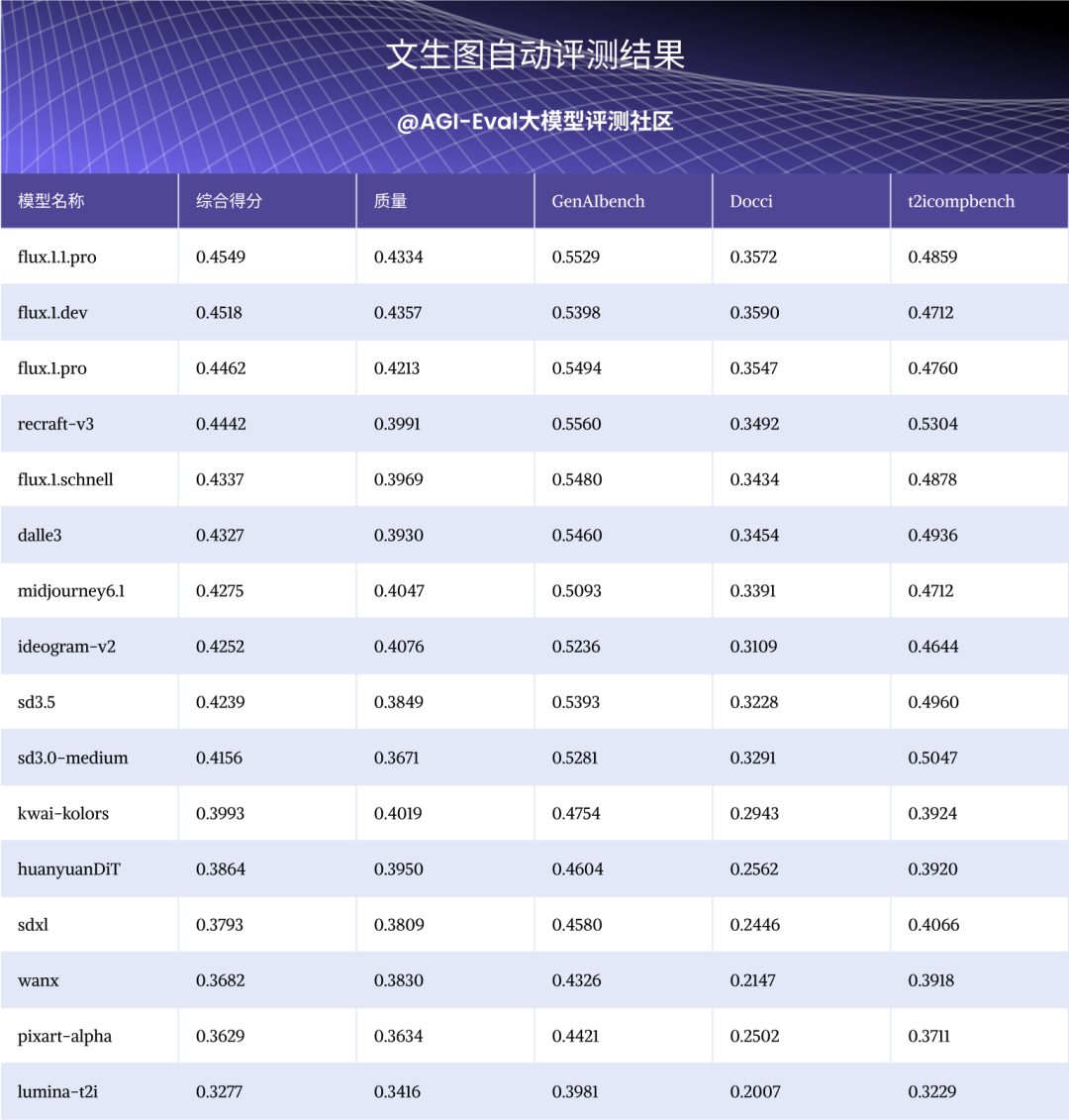
【整体结论】:Janus Pro的图像生成质量处于第三梯队尾部,弱于上一代开源的文生图专家模型,图像文本一致性维度上处于第三梯队头部.
-
图像文本一致性:Janus Pro击败了2B左右的hunyuanDit,快手的 kwai-kolors,但弱于论文中宣称胜出的 DALL-E3 与 SD3-Medium。
-
图像质量:其生成模型的分辨率仍较低,目前仅支持 384x384 分辨率,与主流的1024x1024 分辨率还有较大差距;对于较简单的主体生成,合理性明显弱于其他比较模型。
-
生成理解统一模型比较,Janus Pro 在图像文本一致性维度上强于 Emu3-Gen,在图像质量维度上弱于 Emu3-Gen。
【特别注意点】:
-
技术报告中 Janus Pro 在图文一致性维度击败 DALL-E3 与 SD3-Medium,自建评测的结论与其相悖,DALL-E3 > SD3-Medium >> Janus-Pro-7B > Emu3-Gen。
-
分析主要原因为 GenEval 和 DPG 数据集本身偏简单,主要考察简单属性,数量,位置生成能力,区分度有限。实际上 Janus Pro 在区分度较好的公开数据集Docci、GenAI以及自建数据集上都表现一般,明显弱于 DALL-E3 与 SD3-Medium。
【特别注释】:
-
文生图专家模型:sdxl(约3B base + 6B refiner, 23年7月开源),huanyuanDit(1.5B,24年5月开源),pixart-alpha(0.6B,23年12月开源),lumina-t2i(5B, 24年4月开源)
自动榜单
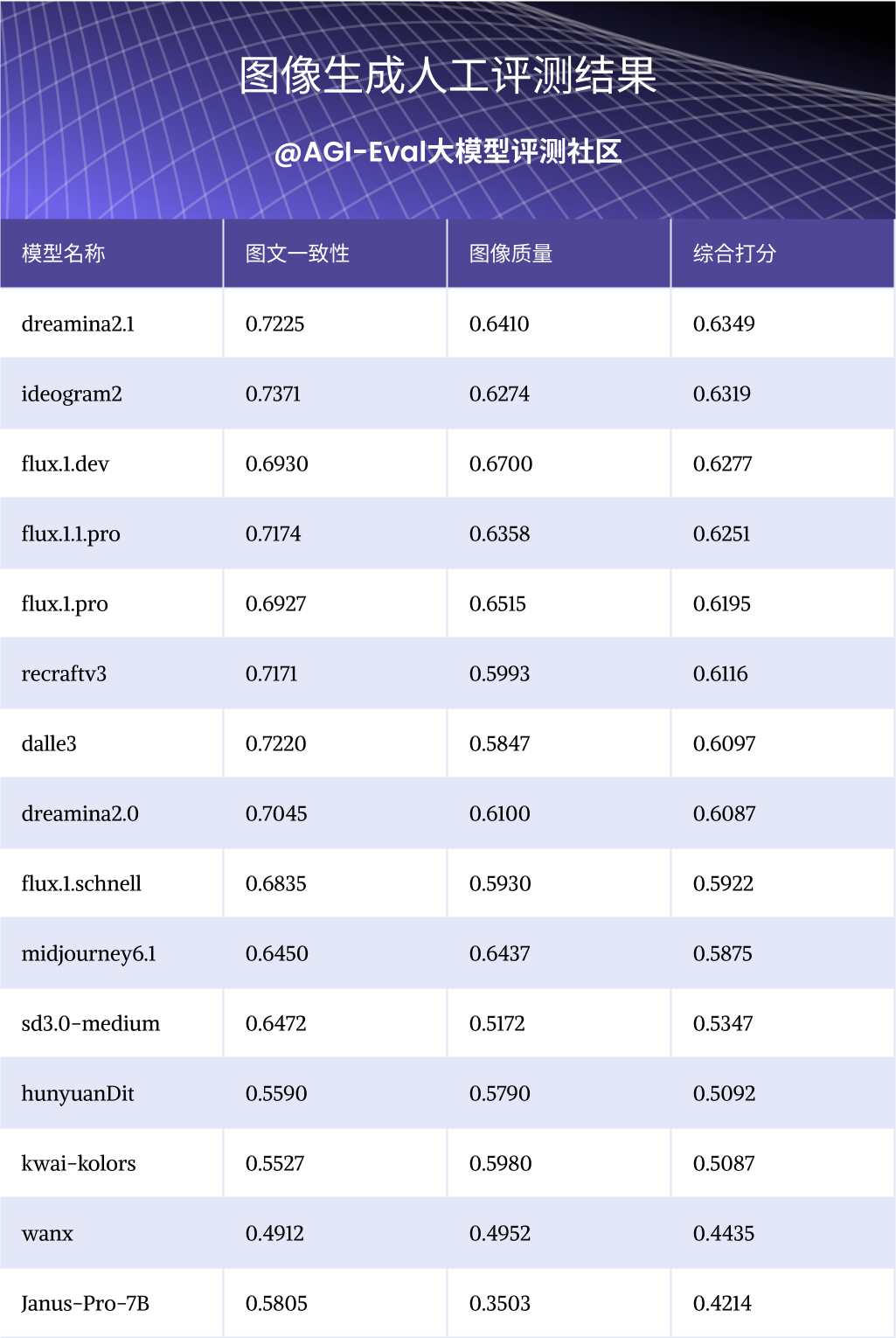
人工榜单
以上为 Deepseek 最新模型的全面评测及报告内容,后续会持续更新行业模型的能力测试及评测报告。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









