




北京时间 26 号晚,除了 GPT-4o 在图像生成方面放出大招,Google 也不甘示弱的发布了新模型 Gemini 2.5 pro,并且在各大榜单实现了“屠榜”,在多模态交互,数学科学,编程方面实现“遥遥领先”,跟 Openai 打了一次漂亮的“双响炮”。

目录:
1. Gemini 2.5 pro 实现屠榜?
2. Google 官方实测案例
3. 团队一手实测
3.1 多模态能力测试
3.1.1 微表情测试
3.1.2 三门问题测试
3.2 编程,科学与数学能力测试
3.2.1 编程能力测试
3.2.2 科学能力测试
3.2.3 数学能力测试
4. 总结和期待
01. Gemini 2.5 pro 实现屠榜?
Google 官方在北京时间 26 日晚在 X 上发布了 Gemini 2.5 Pro 发布的公告:
Google 官方发布的信息中,宣称这次 Gemini 2.5 pro 在各类榜单上实现了“屠榜”,Gemini 2.5 Pro 在对话能力榜单 Arena leaderboard 之中实现历史以来的得分最大飞跃,以超过 Grox-3 模型 40 分的成绩目前位居第一名。

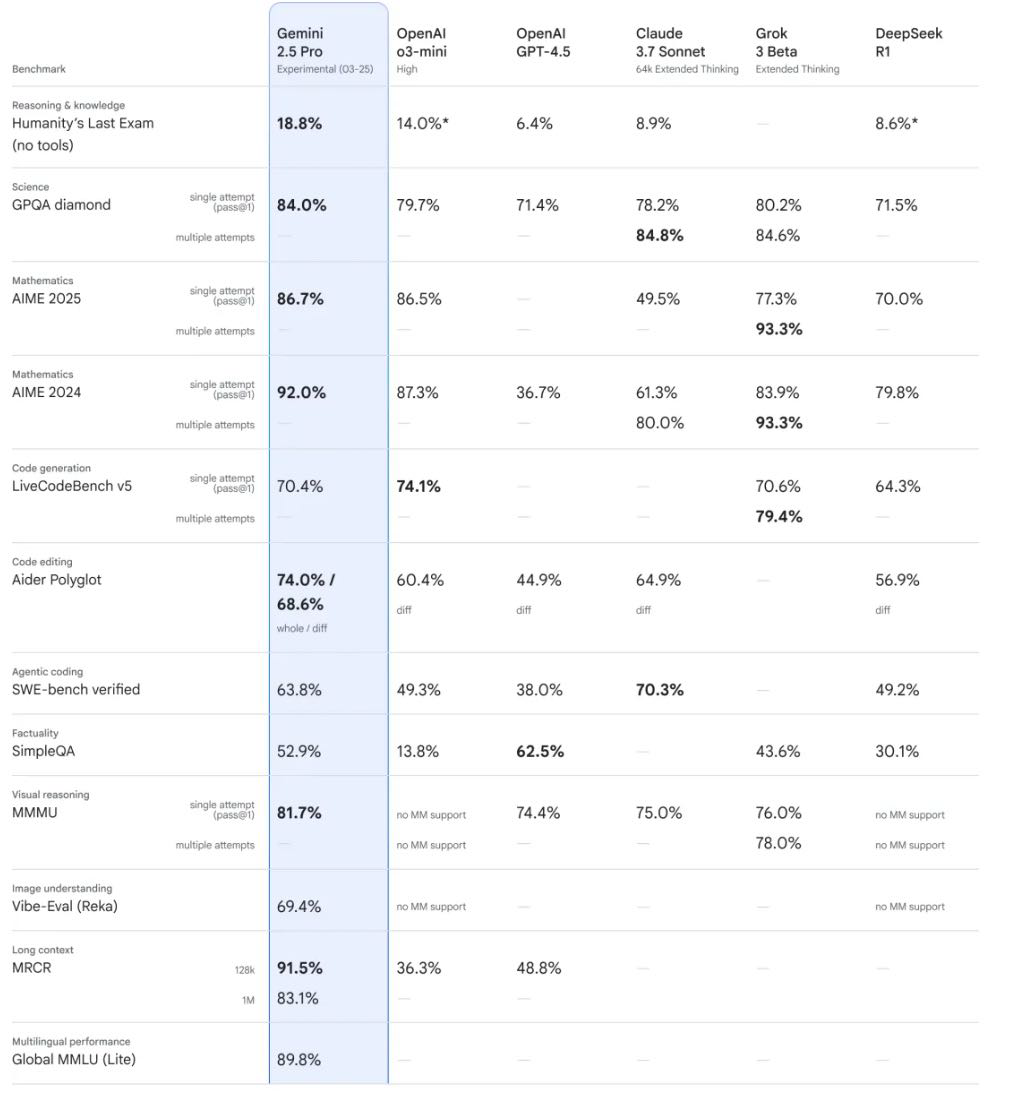
详细的对比数据可见上表
Gemini 2.5 Pro Experimental 在许多类别中都取得了排名第一的成绩,特别是在数学、科学、创意写作、指令遵循、较长查询表现突出。
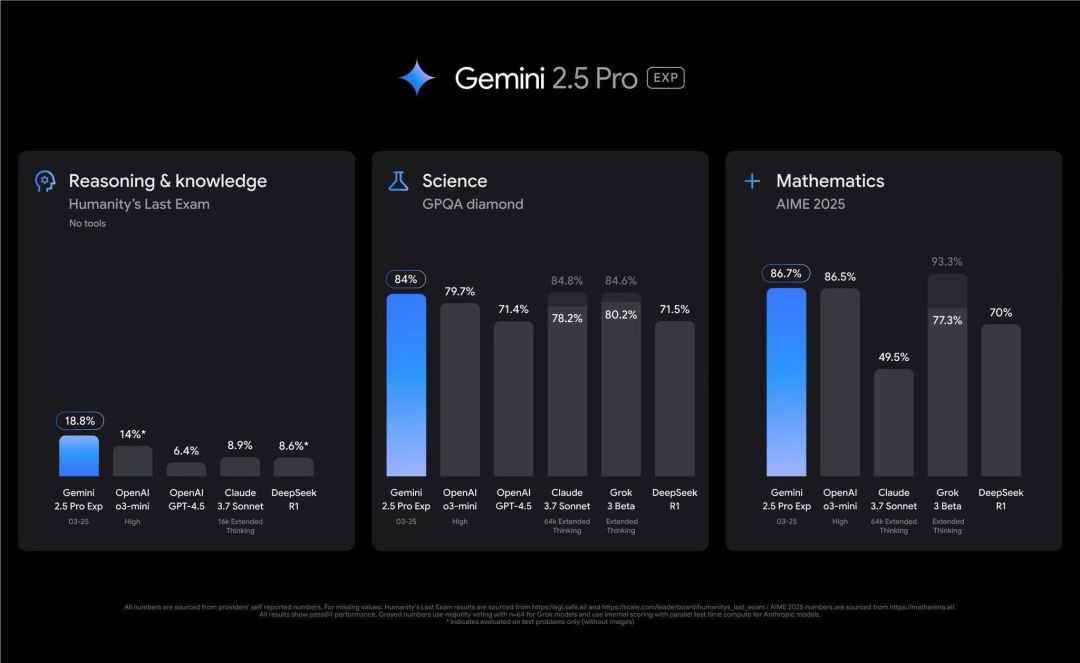
详细的对比数据可见上表
Gemini 2.5 Pro 在 Web 开发领域也表现不俗。在 WebDev Arena 上取得了第二的好成绩。它是第一款与 Claude 3.5 Sonne 相似,比上一代 Gemini 有了巨大的飞跃。
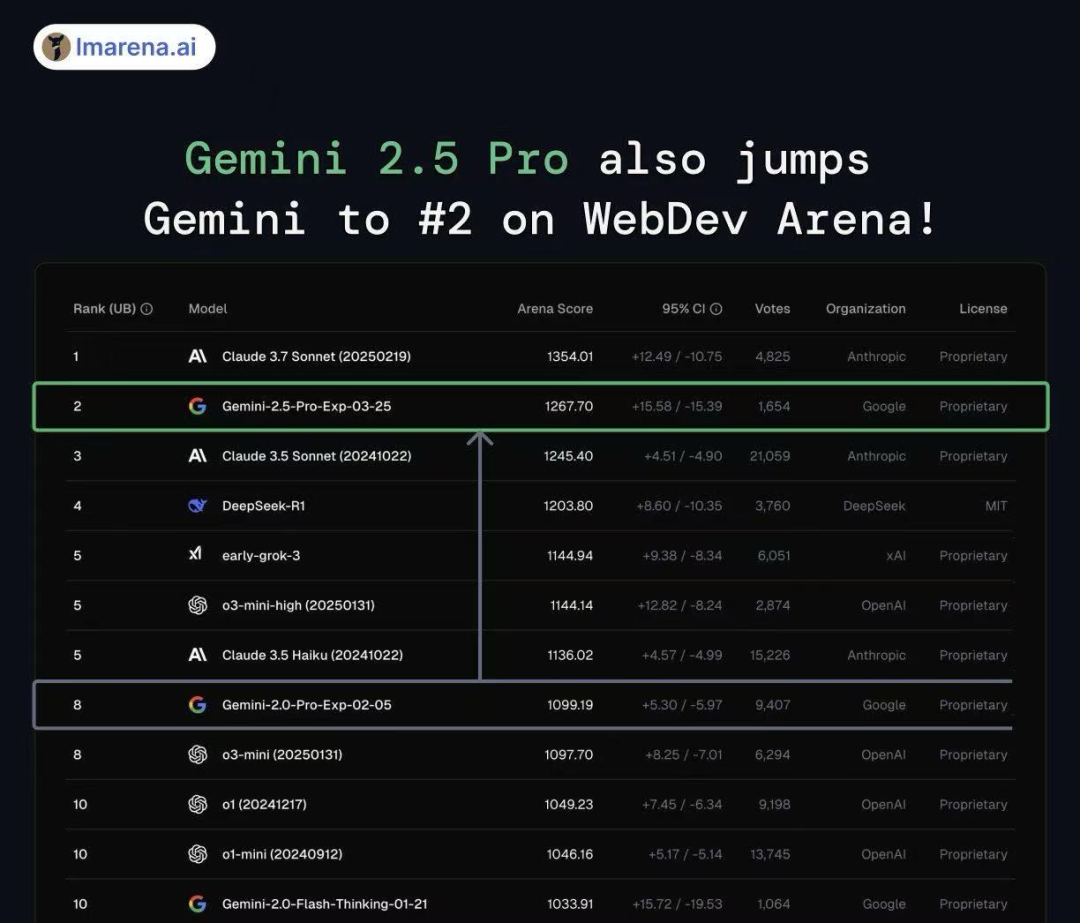
Gemini在WebDev Arena中的排名情况
那么,这次 Gemini 2.5 pro 在实践中表现如何呢?
关注我们,及时获取更多行业内容和资讯!

AGI-Eval大模型评测
AGI-Eval是上海交通大学、同济大学、华东师范大学、DataWhale等高校和机构合作发布的大模型评测社区,旨在打造公正、可信、科学、全面的评测生态以“评测助力,让AI成为人类更好的伙伴"为使命。
14篇原创内容
公众号
02. 官方实测
编程与视觉理解大师?
对此,Gemini 官方给出了几个实际的案例:
首先,看看 Gemini 对任务的理解
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









