









flume的一些核心概念:
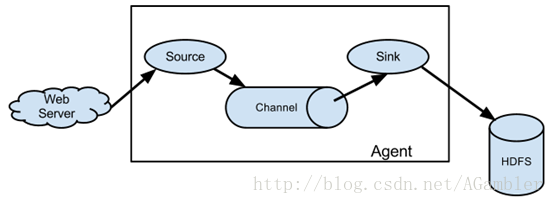
Agent: 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
Client: 生产数据,运行在一个独立的线程。
Source: 从Client收集数据,传递给Channel。
Sink: 从Channel收集数据,运行在一个独立线程。
Channel: 连接 sources 和 sinks ,这个有点像一个队列。
Events: 可以是日志记录、 avro 对象等。
flume的安装:
1)将下载的flume包,解压到指定目录中,你就已经完成了50%;
2)修改 flume-env.sh 配置文件,主要是JAVA_HOME变量设置;
JAVA_HOME=/usr/local/jdk1.8.0_91/
flume的案例:
1)案例1:监听指定日志文件,并发送到指定地址
配置文件:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/logs/test/test.log
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.keep-alive = 10
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.1.11
a1.sinks.k1.port = 41420
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c12)案例2:监听指定日志文件夹,传输新增文件
配置文件:
# Name the components on this agent
a1.sources = r1 r2
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /data/logs/backup_plat/adcallback
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = test
# Describe/configure the source
a1.sources.r2.type = spooldir
a1.sources.r2.channels = c2
a1.sources.r2.spoolDir = /data/logs/backup_plat/burypoint
a1.sources.r2.fileHeader = true
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = test
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.1.11
a1.sinks.k1.port = 41410
# Describe the sink
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.1.11
a1.sinks.k2.port = 41411
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Use a channel which buffers events in memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 100000
a1.channels.c2.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# Bind the source and sink to the channel
a1.sources.r2.channels = c2
a1.sinks.k2.channel = c2
3)案例3:接收日志,并传输到kafka
配置文件:
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
#hongyou/guessyoulike
a3.sources.r1.type = avro
a3.sources.r1.bind = 0.0.0.0
a3.sources.r1.port = 41420
## Source 拦截器
#hongyou/guessyoulike
a3.sources.r1.interceptors = i1
a3.sources.r1.interceptors.i1.type = static
a3.sources.r1.interceptors.i1.key = topic
a3.sources.r1.interceptors.i1.preserveExisting = false
a3.sources.r1.interceptors.i1.value = hongyou_guessyoulike_topic
#具体定义sink
#hongyou/guessyoulike
#a3.sinks.k1.type = org.apache.flume.plugins.KafkaSink
a3.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#a3.sinks.k1.metadata.broker.list=node1:9092,node2:9092,node3:9092
a3.sinks.k1.kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
a3.sinks.k1.sink.directory = /home/hadoop/app/apache-flume-1.7.0-bin/logs/
a3.sinks.k1.partitioner.class=org.apache.flume.plugins.SinglePartition
a3.sinks.k1.serializer.class=kafka.serializer.StringEncoder
a3.sinks.k1.request.required.acks=0
a3.sinks.k1.max.message.size=1000000
a3.sinks.k1.producer.type=async
a3.sinks.k1.encoding=UTF-8
#a3.sinks.k1.topic.name=hongyou_guessyoulike_topic
# Use a channel which buffers events in memory
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c14)案例4:接收日志,并传输到hdfs
配置文件:
a1.sources = r1 r2 r3 r4 r5
a1.sinks = k1 k2 k3 k4 k5
a1.channels = c1 c2 c3 c4 c5
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41410
a1.sources.r2.type = avro
a1.sources.r2.bind = 0.0.0.0
a1.sources.r2.port = 41411
# source r1定义拦截器,为消息添加时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ns1/logs/plat/adcallback
a1.sinks.k1.hdfs.filePrefix = adcallback_%Y%m%d
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollSize = 67108864
a1.sinks.k1.hdfs.rollInterval = 0
#具体定义sink
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://ns1/logs/plat/burypoint
a1.sinks.k2.hdfs.filePrefix = burypoint_%Y%m%d
a1.sinks.k2.hdfs.fileSuffix = .log
a1.sinks.k2.hdfs.fileType = DataStream
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollSize = 67108864
a1.sinks.k2.hdfs.rollInterval = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000000
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000000
a1.channels.c2.transactionCapacity = 100000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# Bind the source and sink to the channel
a1.sources.r2.channels = c2
a1.sinks.k2.channel = c2














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









