






消息协议



消息的可靠性






前言
IM系统的可靠性指的是端到端的可靠性,并不是tcp的可靠性,它是指客户端A,客户端B以及服务端三端通信之间的可靠性,并不是客户端A到服务端这么一个上行消息的可靠,这个tcp就可以保证了,当然说tcp只是保证在传输层到网络层的一个可靠,进入了webserver容器,也有可能丢失,业务如果没有处理清楚,panic了,消息也有可能丢失,所以本质上来说,tcp并不是端到端的可靠,这里强调的可靠是三端可靠,上行消息可靠,下行消息可靠。当然消息可靠有他自己的一个技术约束,不重、不漏、有序、及时,也就是客户端A到客户端B的消息不能重复、不能遗漏,客户端B感知消息的顺序应该和客户端A发送消息的顺序保持一致,然后发送的速度要及时。
技术约束
- 从服务端的视角来看,我们的系统,第一高可靠,至少要5个9以上的消息可靠,因为收发消息对于im来说是核心链路,所以可靠性要求非常高
- 其次就是及时性,因为用户对消息发出去的及时性非常的敏感,所以要求低延迟
- 然后就是高吞吐,对于极端的群聊场景,比如万人群聊这种,在特点活跃时间内,每发一条消息都是一次ddos攻击
技术方案
消息的可靠分为上行消息可靠和下行消息可靠,所以把这个问题缩小,先看客户端A到服务端的上行消息可靠
- 首先是消息不漏,消息在发送的时候可能会丢失,丢失的原因可能会有很多,客户端A发送消息时可能要经过层层的中间组件,其中某个组件panic了,然后就导致消息丢失没发出去,或者消息发出去了,到某个路由器,路由器挂掉了,导致消息丢失,到了服务之后,服务的网关层panic了,这样消息也丢失了,会有很多种可能性,导致消息没到达服务端。
传统的解决方案ack和消息重试,启动一个消息的定时器,在100ms之内还没有收到ack,就重发一条,一直重发一直重发,直到服务端回复个客户端A,就把这个定时器关闭掉,这样就可以做到消息的不漏,消息一定会到达服务端。但是这样的话就会引出一个问题,如果重复发送消息的话,由于网络之间的抖动,无法区分消息丢失和延迟之间的差别,也就是说,消息有可能是真的丢了,那这时候重发是没问题的,但是这个消息有可能是延迟的,定时器超时重传又发送一条,这样相同的消息就会有两个,延迟过去之后,两条消息都到达了服务端,那么就会出现重复的现象 - 解决重复,我们给每一个message分配一个ID,这个ID由客户端分配,从0开始一直不断自增,这样就有了一个顺序,根据这个id去判断消息是否已经存储了。
- 有序的话这个messageID是一个可排序的字段,从而保证消息的顺序
最大的问题在于消息的量级会很大,不满足我们的上面的约束高可用、高吞吐和低延迟和低成本,不能因为存储messageID来消耗过大的内存,影响可用性,服务崩溃重启可能需要很长的时间来恢复。
解决的办法呢首先就是tcp协议里面有个解决方案,在服务端和客户端都维护了一个list飞行消息的队列,这个消息发送出去,就存在飞行队列中,一旦ack才把这个飞行队列里的消息给删掉,服务端也是,但是对于百万长链接,可能就很耗内存。
所以退而求其次,就只保留一个消息ID就是clientID,clientID不需要全局有序,只需要客户端维护的每个会话是从零开始不断递增的,每一次发消息+1,然后每一次持久化,这样的话服务端每一次都维护一个maxID,当消息过来之后,它只会接受maxClientID+1,否则就会忽略,因为首先是在tcp上传输的,tcp已经保证了在传输层的有序性,所以在到达业务层的时候这个乱序的可能就很低了,所以这种其实不会造成大量的重试,当然也会有。所以这个TCP有序和业务上的有序其实是两个概念,要在业务层实现自己的消息有序性。
当消息存储到redis中,就会立刻push给客户端b,push的逻辑其实也需要有一个消息ID,但这个是服务端生成的,这就有讲究了,服务端是不能重启的,可能客户端只需要维护一个sessionID就可以了,服务端要维护上十亿个,所以对于服务端来说要维护的话就不能叫clientID了,应该叫messageID了,是会话维度的,不需要全局唯一,只需要sessionID+messageID能够具有唯一性就可以了,这样的话设计会简单一些,messageID假如是单调递增的,其实是有非常大的难度,客户端B只会接受max_id+1,否则忽略,接受了则回复ACK。
链接的可靠性
连接可靠性,让长链接持有的更久
系统现状
client和gateway建立连接之后,他们之间会收发消息,但这个通道和我们平常所说的tcp连接有些区别,平常我们都是在一个数据中心中的tcp,很容易建立连接,而且并不容易断开,因为经过的路由器会比较少,而且网络环境也比较稳定,但是对于im系统这种长链接服务来说,他是需要跨越公网的,这里面就会有非常多的路由节点,要跨公网建立长链接,每一个路由节点的每一个服务策略都是不同的,会造成非常多的不确定性,那我们的连接可靠性就是要消除这么一个不确定性,可靠性难做的一个原因就是数据规模大,在大数据的情况下,不可靠的事件都有可能发生。如果在持有百万连接的这种情况,那么可能会因为各种原因断开连接,造成这样连接的一个不可靠。
不可靠的原因,技术挑战
- 最常见的场景就是,公网环境下,肯定要经过运营商网络,运营商网络自己有一个为了减少服务路由的这么一个成本,因为要维护tcp路由表,表本身是占用一定的计算机资源的,即使字节数占用的很小,但也是占用一定的资源,为了减少机器的成本,就会周期性的扫描路由表,会把一段时间内没有收发消息的tcp连接清理掉,这个策略对运营商来说是非常好的,这样能有效的控制成本,不会导致黑客攻击导致占用大量的资源,整个网络陷入瘫痪,但是这样的话就会对im长链接服务造成一定的问题,运营商作为一个中间状态,在连接断开时都会发送一些final信号。所以在看客户端日志和服务端日志的,客户端会觉得是服务端断开了连接,服务端又会觉得是客户端断开了连接,感觉都是对端断开的,这种情况往往是由于服务的中间节点断开了连接,
- 其次还有数据中心都是有网关的,有l4或者l7网关,通常有两层,l4网关就是lvs,l7网关就是ngix,l就是层,l4就代表工作在四层osi的网络模型第四层的路由,不知道上游的应用层的信息,知道的是tcp、IP这些信息,根据这些信息去路由给下一层,通常会路由给l7层去代理,会做这么一个应用层的http转发,就是那url去做个转发,到真正的业务server,这种网关一般也会有一个tcp连接持有的最大时长,超过这个时长也会断开,所以要做长链接服务,要把这个也打通,
- 然后除了上面这种场景,还有一些场景比如移动互联网场景,客户端往往处于一种网络不确定性的一种状态,比如可能在可能在室内连wifi,移动到户外的时候就连接了手机的基站,这个时候长链接是必然会断开的,因为ip发生了切换。或者客户端可能会在一种高速移动的场景,在这种情况可能会出现移出漫游区域,从这个运营商基站,移动到另一个运营商基站,这种会导致ip地址的重新分配。当然有些运营商做了一些保证,虽然漫游区域发生了切换,但这个时候可能会让ip地址不发生切换,这样也就不会造成tcp长链接的断开,但如果运营商做这样的保证,连接就会断开。
- 除了这种强制的断开连接的场景,还有一些弱网的场景,就是网络状态不是很好,在地铁或者隧道当中,消息可能会传不过来,有丢包的现象,在这种弱网环境下,连接也有可能会断开,一旦连接断开,可能会非常影响用户体验,轻一点可能发消息就在那转圈,因为要重连连接,消息发不出去,重则由于连接断开,重连的时候可能会发生一些数据状态的改变,造成消息的错乱,vx好像也没完全解决这种问题,但是vx做的最好嘛,在隧道或者弱网环境体验会比较好些。
总结
- 中间代理资源的回收,这是导致连接断开的连断开
- 然后就是底层ip的切换
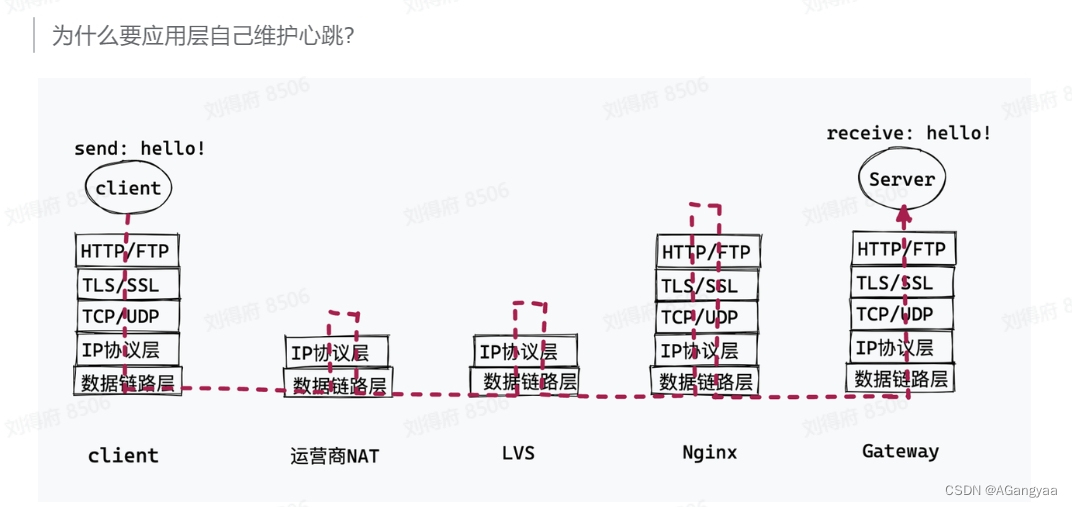
针对第一种原因,采用的方案也是im业务,无论是互联网的公司还是一些基础的开源的中间件,比如爱奇艺、喜马拉雅、知乎、vx或者像dubbo、zookeeper都会用的一种,就是心跳,心跳对于服务端来说是一种很常见的技术,也被用于很多场景,他的一个核心目标就是保活,就是告诉业务方,服务还一直存在着,因为网络是一种不受信的状态,除了通过这种心跳的方式,我们没有办法来获取一些信息知道服务还活着,只能通过心跳保活的这么一种方式。客户端会定时的给服务端发送消息,告诉服务端自己还活着,在这个过程中,就会刷新各个代理的一个超时时间,知道这个连接还是活着的,不能kill掉,会影响用户的一个体验,通常就是在链路上发送一个空的消息来防止资源的回收。但是有个前提就是,消息收发的周期要小于整个链路最小回收连接资源的周期。tcp连接作为一个传输层协议,就有一个长链接,可以开启一个长链接的选项,开启了底层就会发送一个心跳来保证长连接的状态,但是他的一个时间是两小时,但不同的运营商他的回收策略都是不一样的,中
国的话通常是5分钟,自己的网关可以自己设置,所以通常就是去服务商不可靠的这么一个最小值作为心跳的一次周期,
然后呢现在的问题就是由谁去发这个心跳,如果是服务端定期的遍历所有的socket去发,显然不可取,就比如有百万长连接,那每五分钟去遍历所有的socket,那就是一个巨大的带宽消耗,所以只能是由客户端来发消息,服务端创建一个定时器,客户端如果在规定的时间内没有发送,就把这个连接删除掉,回收资源,这就是心跳的一个设计
然后第二种原因,就是ip地址的更新,因为ip地址的切换会导致连接的断开,这种是没办法的,因为传输层技术上的一个约束。所以这个时候考虑的就不是长链接不断,因为做技术的设计,有时候要弱化嘛,退而求其次,做这种trade-off的折中设计,在这种情况下,去追求连接断开后,用户无感知的设计,那就是重试,不是说连接断开了,客户端就一定要告诉用户说连接断开了,因为用户有个反应时间,但计算机的反应时间很快,后台可以在一定时间内进行重试,直到把连接建立成功,这个时候用户在收发消息的时候,会觉得连接没有断开,但是底层已经把连接换了一个了,我们保证让这个连接断开之后,一段时间内能够快速的重连,来保证用户无感知,这是解决ip地址变更的一个办法。
然后呢,我们又根据技术上的一些约束条件以及一些资源情况做了一些优化,面试官我还要继续讲吗?
约束条件
- 资源成本,做这个连接的可靠性,要尽可能的减少服务器资源的消耗,这是接入层的一个重要目标,因为长链接要维护一个极速变化的一个服务,它不仅仅是一个有状态的server,同时对于长链接网络来说,它的变化是非常快的,基本上不可能持久化,对我们的可靠性造成一个工程性的挑战,所以为了解决这个问题,我们应该尽可能的节约一个资源成本,因为这些资源成本也就是状态,如果能维护的状态越少,就是越有利的
- 对于这个连接层最重要的就是可靠,任何各种极端情况下,都应该去快速恢复连接的一个,这是连接层非常重要的一点。
- 其次就是低延迟,不能因为维持可靠性就增加了延迟,因为毕竟是一个基础服务,基础服务延迟如果高的化,那业务就没法运作了
这是三个主要的技术约束
技术方案
- 编解码器,想要实现一个连接,就要在我们设置协议的基础上,设置一些信令,连接建立之后需要维护一些状态,比如我们就需要登录这样的一个状态,会传输一个数据包,这个数据包就告诉服务端它要登录了,这些数据包里会携带一些信息,最重要的就是设备ID,然后我们会根据这个设备id的处理逻辑生成接下来要进行消息收发访问的一些基本状态,这个就是登录的意思,当然登录指的不是账号的登录,而是连接的登录。登录好之后,然后这个心跳定时器启动,然后客户端在一定时间内频繁的发送心跳来保证连接的活跃,
- 时间轮,优化成本,成本的一个巨大开销就是定时器,因为定时器,是和长链接的是保持在一个水平扩展的状态,就是有多少长链接就要有多少心跳定时器,作为一个im,比如春节或者地铁上下班的时候,可能有个潮汐现象,大家都在这个时候登录,大量的建立连接,就会大量的创建定时器,会导致可能有很多定时器可能就在同一时刻开始定时,那这个时候,一旦定时器超时,就会产生绝大部分定时间超时,会出现调度潮汐,协程的调度可能就会出现问题,cpu的利用率会直接被拉满,同时定时器的存储也会占用极大的内存资源,那这个时候计算资源和内存资源都成为了瓶颈,golang本身想要提供一个高精度的定时器,他内部是四叉堆的实现,四叉堆的精度很好,但是会非常占用内存,同时插入和删除插入一个定时器的复杂度是logn,所以如果存在一些潮汐现象产生大量定时器都要插入这个四叉堆中,就会导致这个性能极度的损耗,为了解决这个问题,就要找到一个代替原生golang的定时器算法,因为其实并不需要高精度的定时器,这并不是一个强的技术约束,因为我们的心跳场景,迟一会或早一会都不会有什么影响,心跳的目的就是为了资源回收,不会对用户产生什么感知,所以这种场景比较适合用低精度的一个定时器,低精度的定时器可以有一个更好的时间复杂度,也就是时间轮,可以做到o1的时间复杂度,同时存储成本也会降低,优化了我们的一个性能,当然是以精度为代价的,kafka就实现了一个时间轮,很多好像和心跳相关的都基于时间轮
- 对于保证连接可靠性的时候,登录的时候要创建一个心跳定时器,然后从登录的信令中解析出一个设备ID,然后把channelID,channelID是等价于fd的,fd是存在一个bug的,fd是一个进程级别的,但是一旦跨进程传递给了stateserver,那么这个fd就不能唯一的表示这个链接了,我们是endpoint+fd,但是fd是会被复用,如果有延迟,可能会导致传到被复用的fd上,这样就把消息传递给了新的连接,可能会出现忽然有个莫名的人给你发了一条信息,造成这种消息的错乱,所以要有一个channelID的概念,这个通道表示就是一个链接,它是不可复用的,之前因为有复用的原因,所以会有消息错乱的问题,所以规定了channelID是一个int64的值是不断递增的,永远不会出现复用的问题,因为不需要维护全局的,维护一个进程级别的就可以,因为有endpoint做一个前缀,是个唯一的key,能够通过did找到endpoint和channelID找到这个链接在哪里,有这样一个路由信息
- 心跳的时候,当服务端接受到心跳消息的时候,会通过之前在登录的时候,映射的这个endpoint+channelID作为key,找到一个定时器对象,然后把这个定时器的任务重试一下,就是把这个定时器删除然后重新注册一个
- 重连的时候,我们面对的是一个ip的快速变更,所以也就是需要快速重连。也就是链接建立的状态,相对来说就是一个很重的操作,如果可以复用这个状态,那就可以做到一个快速重连的效果。比如说,这个长链接崩溃断开了,服务端感知到了,epoll中可以快速返回一个error事件,拿到这个事件后调用回调函数,直接通知给state server,让她把所有的状态、定时器、路由的key,等待一些状态全部清理掉,做链接的回收。但是我们的快速重连可以让链接断开之后,我们不会立刻回收所有的状态,而是进入一个延迟任务,这个延迟任务会执行一段时间,只要延迟任务到期之后,才会真正的把所有状态回收,也是启动一个定时器,交给时间轮,在一些极端的情况下,压力会非常大。在IP地址的变更场景,我这里是假设客户端断开连接之后是可重试的,相信这个客户端可以在10s之内快速的建立连接,然后再连接给这台机器,再连接给这台机器的时候,连接一旦创建成功,这个连接里就必须携带上次连接的channelID,所以channelID要随着ack或者心跳的方式把这个channelID返回给客户端,客户端在重连的时候告诉服务端老的channelID是什么,在重连信令中拿到老的channelID,就可以找到老的一些状态,就可以把这个channelID一替换,替换成新的channelID,相当于只换了一个底层的socket,而业务上的状态全都没有换,就实现了链接的复用,那也就不需要创建定时器,告知业务层感知,然后业务层做一些数据的处理、日志的打印或者什么一大堆的操作不需要做了,所以速度就会很快,这个就是快速重连,也就是就是资源的复用和链接的复用
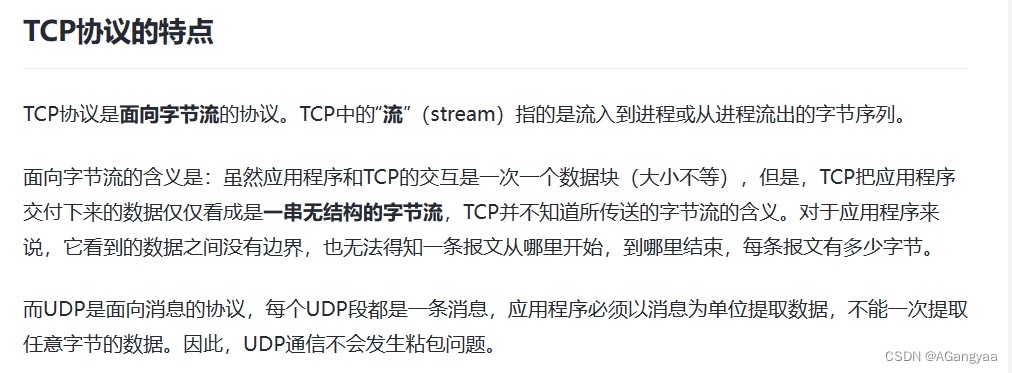
客户端如何选择网关IP地址ip config




如何设计并发通信模型来收发长链接消息
业务层怎么感知到连接在哪台机器上?并把消息分发出去呢?

为什么应用层自己维护心跳?


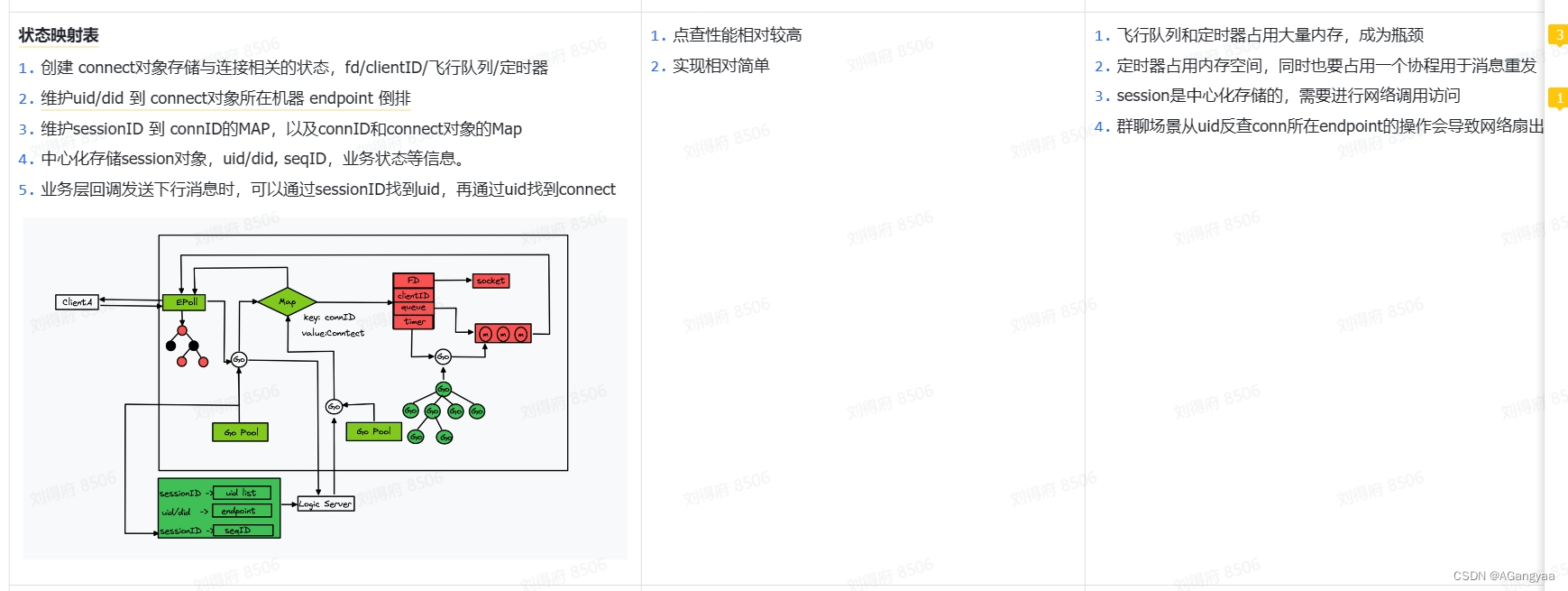
如何存储一个长链接的状态,才能既高效又节省内存?

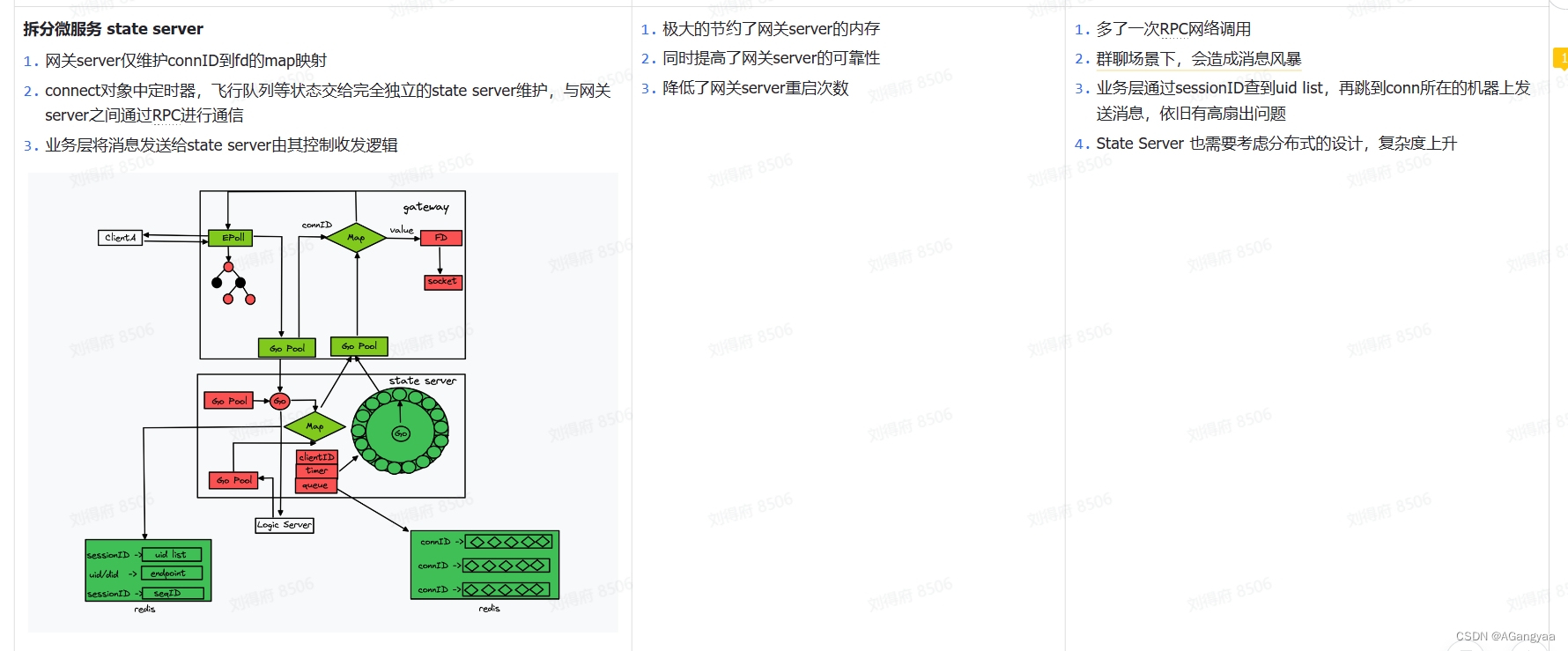

如何尽可能的减少长连接的崩溃/重启次数,做到永不死机?


Unix domain socket
虽然网络socket也可用于同一台主机的进程间通讯(通过localhost地址127.0.0.1),但是UNIX Domain Socket性能更高:不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程。
与TCP套接字相比较,在同一台主机的传输速度前者是后者的两倍。
这是因为,IPC机制本质上是可靠的通讯,而网络协议是为不可靠的通讯设计的。
UNIX Domain Socket也提供面向流和面向数据包两种API接口,类似于TCP和UDP,但是面向消息的UNIX Domain Socket也是可靠的,消息既不会丢失也不会顺序错乱。
一、使用方法
第一,在创建 socket 的时候,普通的 socket 第一个参数 family 为 AF_INET, 而 UDS 指定为 AF_UNIX 即可。
第二,Server 的标识不再是 ip 和 端口,而是一个路径,例如 /dev/shm/fpm-cgi.sock。
其实在平时我们使用 UDS 并不一定需要去写一段代码,很多应用程序都支持在本机网络 IO 的时候配置。例如在 Nginx 中,如果要访问的本机 fastcgi 服务是以 UDS 方式提供服务的话,只需要在配置文件中配置这么一行就搞定了。
二、连接过程
基于 UDS 的连接过程比 inet 的 socket 连接过程要简单多了。客户端先创建一个自己用的 socket,然后调用 connect 来和服务器建立连接。
在 connect 的时候,会申请一个新 socket 给 server 端将来使用,和自己的 socket 建立好连接关系以后,就放到服务器正在监听的 socket 的接收队列中。这个时候,服务器端通过 accept 就能获取到和客户端配好对的新 socket 了。
三、发送过程
这个收发过程一样也是非常的简单。发送方是直接将数据写到接收方的接收队列里的。
时间轮
时间轮的介绍
时间轮(TimeWheel)是一种实现延迟功能(定时器)的精妙的高级算法,其算法应用范围非常广泛,在Java开发过程中常用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等各种框架中,各种操作系统的定时任务crontab调度都有用到,甚至Linux内核中都有用到,不夸张的是几乎所有和时间任务调度都采用了时间轮的思想。
时间轮的作用
高效处理批量任务
时间轮可以高效的利用线程资源来进行批量化调度,把大批量的调度任务全部都绑定时间轮上,通过时间轮进行所有任务的管理,触发以及运行。
降低时间复杂度
时间轮算法可以将插入和删除操作的时间复杂度都降为O(1),在大规模问题下还能够达到非常好的运行效果。
高效管理延时队列
能够高效地管理各种延时任务,周期任务,通知任务等,相比于JDK自带的Timer、DelayQueue + ScheduledThreadPool来说,时间轮算法是一种非常高效的调度模型。
缺点:时间精确度的问题
时间轮调度器的时间的精度可能不是很高,对于精度要求特别高的调度任务可能不太适合。因为时间轮算法的精度取决于时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。
精度问题我们可以考虑后面提出的优化方案:多级时间轮。
整个过程总结




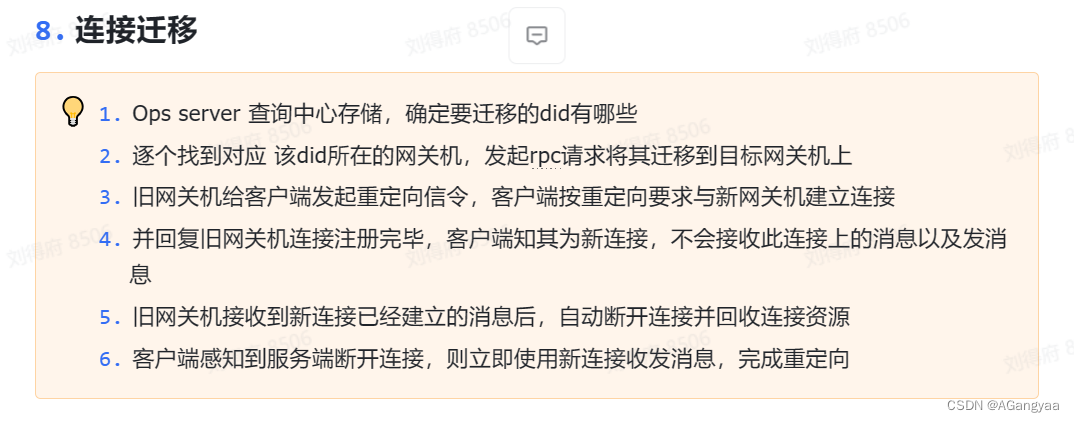
7、平滑重启



面试官你好,我叫闫港,我的本科院校是在山东济南的齐鲁工业大学,我今年大四。
然后我的实习经历是在我大二下学期也就是22年5月的时候收到了杭州网易的实习offer,实习了大概五个月左右的时间。我在网易主要做的一个业务是,为网易公司提供客服中台的这么一个业务,我们部门从技术架构主要分为四个方面,业务部分是分为智能客服,也就是用户在找客服的时候第一个面向的是机器人,然后用户转人工时会有一个人工客服,因此有一个支持人工客服工作的客服工作台,以及用户在提出转人工需求后,人工客服人手不够时用户会流转到留言平台去处理的一个留言工作台,然后会有一条微服务的通信链路也就是长链接网关的接入层,是基于webSocket和Stomp协议设计的,用来维护消息会话的存储,消息的状态,消息的推拉push,长链接状态的维持以及路由的切换,将业务部分串起来。我在网易公司的这段实习主要是就是去研发这条长链接网关,去用来维护消息会话的存储,消息的状态,消息的推拉push,长链接状态的维持,以及开发了一下智能客户的业务部分。
后来我又是在我大三也就是23年的年初,接到百度公司的offer,部门是在上海的服务体验发展中心部门。我在百度公司实习的时间更长一些,做的业务也和网易有些类似。我在网易的时候设计主要是相当于一个垂直领域的im业务,而我在百度呢,相当于是做了一个更通用型的im业务,我和我mt就是设计了一款更通用型的im接入层长链接网关。主要实现业务部分主要是:实现了一个ipconfig的服务,让我们长链接建连的时候调度更精准,相当于自定义的一套负载均衡。和长链接业务相当于一种系统资源,我们设计让单机持有的长链接数更多,大概单机能做10w-30w(一般15w)的长链接负载。然后就是im长链接业务里面比较重要的部分,一个就是作为长链接的业务,要去保证长链接的可靠性,让这个长链接持有的更长久,更可靠。还有,作为im业务,消息的收发可靠及时是im通讯的基础,所以要去保证消息收发的可靠、及时、有序到达。当然这里指的并不是传统的tcp协议的可靠,而是指客户端与服务端,服务端与客户端之间的三端通信的可靠性。 最后,因为本质上im业务里面有很多很多有状态的资源,如果机器重启或者业务功能导致的上线机器重启,有状态的资源就会丢失,会对服务有一定的影响,因此我们又对有状态的资源做了分布式的迁移,来去保证我们服务的整体可靠
我的个人技术栈是java,正常的java的开发技术栈像redis、mysql等都非常熟悉。
我秋招呢是也收到了一些offer,不过不是太满意,然后想来看一下春招的机会,这是我实习、技术以及目前的一些情况,我的自我介绍完毕,面试官
IM通信协议的设计
通信协议是整个IM工作中最核心的一个环节,因为所有的通信,都围绕着协议的设计所展开的,所以对于整体的架构来说是有一个演进上的决定性作用的
设计目标
IM的一个核心场景其实就是A客户发送消息给到服务端,服务端下发消息给到B客户端,这样的一个过程。对于早期的im来说其实是有两种架构,一是p2p这种对端架构,客户端A直接把消息发送给客户端B,无服务器的架构模式,这种会有很多问题,因为没有服务器就会没有监管,这样也没法去做离线会话,多端登录历史消息的拉取等场景都没法实现。
然后就是经过服务器的模式,A客户发送消息给到服务端,服务端下发消息给到B客户端,这也就是im通信的一个核心功能,消息的通信,A发送给服务端的消息叫做上行消息,服务端发送给客户端B接收者的时候叫下行消息。
对于消息来说,目标就是可达有序,不重不漏,
可达:A发送到消息必须发送到B客户端
有序:a b之间的收发消息要满足时序一致性,
不重不漏:也就是消息不能重复也不能漏发
本质上就是Qos2+时序性
评估标准
- 最重要的就是传输的【性能】,协议传输的效率,尽可能的降低端到端的延迟
- 【兼容】既要向前兼容,又要向后兼容,不同客户端的版本不会对通信造成影响
- 【存储】减少消息包的大小,降低空间占用率,对于im万亿级的来说,多出一个字节在一秒钟可能也会多出万亿字节,消息带宽是很高的,成本就是不可忽略的
- 【计算】减少编码时造成的cpu使用率的权衡,我们的协议在传输的时候要么是文本,要么是二进制,无论怎么传输,编解码的时候都要消耗cpu,所以在序列化和加解密的时候都要尽可能的降低cpu的利用率,接入层是很消耗cpu的,要加解密,序列化,可能会把cpu打到很高,如果设计中没有考虑到这一点,可能就会存在性能抖动,超过了cpu的利用率的上限可能就把进程kill掉了,一旦进程被kill掉,端上就会有感知,因为接入层是离APP最近的一层,要连接长链接,长链接一断开,用户就会有感知,如果在聊天的时候发现连接断开,消息丢掉,那这个消息的可用性就会很差,对于一个IM来说,用户的体验就会很差
- 【网络】尽可能的减少网络带宽消耗
- 【安全】协议安全性,防止协议被破解,协议一定要安全,不能被破解,同时在不能被破解的前提下,对于中国来说,要有监管的需要
- 【迭代】尽可能的灵活扩展,支持im复杂业务的演进。im业务是非常复杂的,要不断地更新和迭代,协议的设计要考虑到需求的一个不断迭代,灵活可扩展性,如果不兼容,app就不可用
- 【通用】可跨平台接入,H5,客户端,IoT设备。对于接入层来说,不应该假设对接的设备是什么,可能是pc也可能是移动端也可能是h5页面,也可能是个浏览器,也有可能是个IoT设备,作为一个通用性的接入层,应该要考虑到通用性,不能对可能的设备做假设
- 【可读】易于理解,方便调试。对于一个不断对互联网提供服务的系统来说,在出现问题的时候要方便排查
基本结构
对于一个协议设计来说,本质上是个网络协议,对于IM来说,其实只设计三个层次,数据链路层等更低的层次就不需要考虑了,真正需要考虑的是传输层、安全层和协议层,自顶向下的看问题,先说应用层协议其实有两种协议,就是文本协议和二进制协议,文本协议向redis就是用的文本协议通信,还要http这种,请求头、请求行、请求体这样的文本协议,文本协议指的是字符流,每一个字符都是可解释的,优势就是可读性好,在浏览器抓包明文就能看到,
但坏处也很明显,性能低,在计算机各种语音上实现的时候,字符串都要被当作不可变的类型,我们从字节数组转换成字符串的时候,可能需要一层复制copy或者是之类的一些处理,当网络传输的时候,底层传输的是字节流,到应用层需要把字节流通过一个编码方式翻译成字符流,这个翻译的过程就是损耗性能
所以在im的设计上或者工业上来说,几百人的im可能就用文本协议,因为实现简单,虽然未来会成为性能瓶颈,但现在实现起来简易。但在我的设计下,针对万亿级,肯定要选二级制协议,不要编解码的转换步骤,虽然不满足可读性的要求,但好处就是性能高,我看到业界都无可争议选择protobuf的序列化协议,body的消息体都采用protobuf取序列化和反序列化,连vx都是这样,只不过vx又做了一些优化,应用层实现一个自己的二级制协议,要有消息头和消息体。因为TCP是个线性的字节流,是没有边界的,所以头中要有一个固定长度的头,每次读取的时候要从固定长度消息头,在解析流的时候就先读出固定长度的消息头,读出消息长度去读取消息,然后再读取这些长度的消息
安全层,把安全层划分成三个类别,最简单的就是像https这种使用tls开源的算法库,去实现协议栈来加密,这样的话加密效果很好,坏处就是要管理证书,管理证书是相对困难的。或者自己在应用层做加解密,做固定加密,这样的话性能是最好的,但坏处就是客户端通过逆向工程拿到这个密钥,就相当于破解了所有用户的加解密。或者一人一密,但这样其实也没有解决黑客逆向拿到密钥,破解你的消息。或者一次一密,只有在建立连接的时候商量用什么加密,本质上就是ssl/tls的一次握手。加解密是个很消耗cpu资源,是一个计算密集型的问题,所以在考虑安全问题的时候,也要考虑服务端收发消息的性能这两点之间的取舍。业界的话其实就是使用Tls加密终止的方式,客户端发送一个加密的数据,到lvs,然后到l7层也就是ngix负载均衡会把tls解析出来,然后下发给长链接网关明文的消息,这样的话就把计算密集型的任务,拆解到ngix,在ngix利用Intel的智能网卡或者GPU加速去进行计算密集行的任务计算,提高它的性能
传输层是比较独特的,有两个协议是tcp和udp,tcp是稳定传输,但tcp只能保障消息到达机器而且,并不能保障消息到达机器以后是可靠的,tcp只能保障到内核的时候是可靠的,当数据复制的时候出现bug,或者到应用层的时候出现问题,都会导致消息变得不可靠,这也是协议设计的考量。而且tcp在网络不稳定的时候会发送频繁的断线重连,长链接就会断开,频繁的断线重连就会把长链接网关压挂,这也是TCP协议的弊端。UDP的好处呢就是我状态的,面向消息设计的,所以弱网环境是更优的,没有建立连接的过程。但现在大部分的设计都是基于TCP做的,只是会针对弱网环境做一些升级,感知变成了一个弱网环境,发送一个数据包比较慢,自动的切换成quick协议或者UDP协议,所以真正工业级较好的im是针对网络环境做协议整合的,我这里就单独默认以tcp实现了
开源协议
实现IPConfig
设计目标
用于im gateway服务去调度IP地址,所以本质上是一个http server的服务,提供一个能够查询endpoint信息列表的请求,提供一个get请求,这个请求查询的是endpoint的信息,endpoint是端点,是ip地址+端口号一个组合的字符串,当然也可以包含其他信息,比如说分值,距离包括一些元数据的一些信息,如果有需要的话可以往上加,所以它是个结构化的数据,考虑了可扩展性。所以对外只暴露一个list接口。之所以是list接口,是为了减少请求的次数,一次返回给批量个有序的,如果第一个连接的时候被拒绝了,可以拿第二个重试。ipconfig通过一套流程,一套算法去收集到了机器的数据,并对做一些指标上的计算, 能够感知到他的一些状态。也就是说这里面是存在一些延迟的,所以可能机器发生了一些变化,可能网关机已经满了,或者负载已经很高了,就启动了过载保护,就可能把这个连接拒绝掉。如果重试的话,发生了过载保护只会加剧过载,所以这个时候就可以使用第二个地址。这样就不用总是去请求ipconfig server,这也就是为什么要返回一个list。当然还有其他原因
在线查询,近线实时计算。也就是说,ipconfig统计机器指标这条线是一个近线实时计算,可能是flink mq,然后get请求是在线查询,具有在线请求的特征,对延迟的敏感度比较高,对稳定性要求要高。对近线计算的准确性和稳定性都有要求,因此通过这些描述我们可以拆分出它的约束条件
约束条件
- 负载均衡:我们要实习这个ipconfig server,最重要的一个特性就是负载均衡,它存在的意义就是如此。难点是我们要找出一个计算公式,一个数学模型能够,合理的描述我们这个网关机的一个负载状态,然后把这个ip,这个连接建立时候的调度,能够实现负载均衡的效果。比如我们有五个网关机,每一个网关机资源消耗的水平应该是大致均衡的,这才是我们ipconfig需要达到的一个效果
- 查询延迟:查询延迟要求要很低,因为所有建立连接的过程中,都需要先访问这个ipconfig server,拿到这个ip地址,如果延迟过高的话就会影响这个链接建立的速度,如此的话就会导致在启动的时候会转圈,会显示正在连接,因为这是一个串行的,所以这个ipconfig请求是一个强依赖,所以速度一定要足够快
- 查询吞吐:某一个Gateway建立连接,可能有非常多的client跟这个server建立连接,但这个时候server挂了,一旦挂掉,这些连接就断开了,这些链接一旦断开,就重新get请求获取一次最新的ip地址,因为这个时候会有时效性,如果再拿过去,可能在短时间内机器就发生了很多事情,如果再拿缓存的数据,还需要请求ipconfig,拿到最新的一个状态,这是防止延迟这个问题。所以这个时候就会大量的请求ipconfig server,吞吐就会一下子拉高,qps一下子拉高,如果ipconfigserver 扛不住这么多的并发请求的话,就会崩溃,一旦这个ipconfig server崩溃了,就致使整个app就不可用了,所以通过可靠性的角度来讲就要支持高吞吐,就是瞬间的并发峰值拉高
- 稳定性:因为ipconfig server是所有建立链接都要请求的服务,是一个核心依赖,如果它挂掉了,那它的整个服务就没法建立链接,也没法通信,什么都没法做。当然这个也要看后端兜底,这个时候http直接请求查询也是可以的,这是一个兜底策略。但无论如何,它的一个稳定性必须要保证,这个接口本身是一个P0级别的接口
- 安全性:既然是一个暴露给客户端使用的接口,所以一定要有一个安全认证机制,不能够无限的伪造客户端进行连接
架构设计
- 如何计算的更准确,才能保证长链接点负载均衡?
长链接和短链接有很大的不同,所以ngix那种短链接的负载均衡策略,就不太适合长链接。短链接的负载均衡策略:随机,轮训,加权平均。但是对于长链接的话,有一些不同的地方。如果一个客户端建立连接,长链接是一种持续的连接,这个连接一旦建立就会一直存在,所以会一直消耗服务端端一个资源。
然后第二个特点就是如果这个长链接他不访问的话是没有任何问题的,不收发消息,消耗的只是内存资源。但链接是分活跃和不活跃的,但是有一些客户端,是活跃的,会相互的收发消息的,对于活跃的链接消耗的资源会更大。也就是链接会有活跃和不活跃的区别,所以要负载均衡的话我们要预估这个链接是否是活跃的。如果我们给某个服务端分配了五个链接,但是这个五个链接有3个是极度活跃的链接,给另一个服务端也分配了五个链接,但是这五个链接都是不活跃,那这样的话负载一定是不均衡的,所以怎么去识别活跃的链接,这也是一个问题
然后还有计算状态的时效性,im聊天,这个状态其实是很难捕捉的,比如链接数量,消息重发数,网络带宽、qps等等,变化是非常快的,那也就是说要有一个ipconfig要实时的计算,那么这个多少秒的窗口是合适的呢,这是一个问题。比如计算好了每5s中计算一次,但是现在这个5s,使用的数据是5s之前的,这5s之前的数据并不能代表第5s的负载情况,可能中间已经发生了很多事情,可能他的负载均衡已经发生变化了,所以调度准确性就有问题
总结起来:长链接的调度就会存在三个点就是:持续负载/资源不均衡分配(就是活跃资源和静态资源没法预告,一个长链接,在不说话时持有的资源是它的定时器,socket等等这些基本的内存消耗是可以计算出了,但是一旦活跃,活跃的程度是没法计算出来的,而且变化会非常快,其次就是很难预估谁和谁要不要说话/计算的时效性也是一个问题
基于这3个约束我们可以去思考一下,基于约束二,我们要统计这个资源状态我们就必须统计这个机器本身的负载情况,我们想统计业务上的负载情况的话较难一些,但我们去统计机器本身的一个情况,比如说ip的物理地址,连接数,这个机器网卡消耗的网络带宽,内存的使用,cpu使用率,cpu load,im gateway server里的协程数,这些指标是有的,把这些指标做个加权平均,我们就能算一个融合分,这个时候我们要考虑怎么把融合分算的更准,不考虑其他情况,只考虑约束二。可以采用对上述进行加权平均这个基本思想,每个数都乘以一个系数,算融合分,那就可以了。每秒采样一次,然后拿到数据算一次然后排序就可以了,这是最简单的一个方法,这个方法也能很好的工作,没什么问题,但是我们要使他算的更准,就要考虑约束三,计算的时效性
对于计算的时效性,我们可以采用一个窗口平均值的一个思想,窗口平均值指的是,定义一个5s的窗口,这个窗口是一个数据结构,每一秒的数据放在对应的这个窗口里,一旦一个新的一秒的数据到来的时候,就把最老的顶掉,做一个先入先出的队列,那么我们每次采样的时候,其实就是对5s的每一秒的数据做一个均值采样,这是最简单的一个均值采样,这样我们就平滑了一个曲线,就使我们的计算更准确一些,因为状态是变化的,我们就取一个平均值,算出一个稳定值,我们通过这个值预测未来的一段时间内也是保持这个平均的量。或者我们给每一秒的采样值做一个置信度,比如第五秒的置信度较低,乘以系数0.1,第二秒的系数高一点乘以0.2这样以此类推,最近的数据可能乘以0.5或者更多,代表置信度更高,线性回归的模型,这种方式的话算的更准一些,加了一个置信度的权重,可以用一些数学公式,本质上是让他算的更准
融合分会带来一些问题,就是可解释性就会比较差,就是一旦出现问题,就很难排查,约束一就可以不用考虑了,因为这是无法避免的,长链接一定是会占有资源的,是无法避免的,这里只考虑二和三。就是一旦负载不均衡了,要去排查问题的时候,要看每一个ip打分,每个ip的分值是多少,但是分析分值的时候会发现,这个分值把它解释成公式比困难,加权平均相对来说还是比较好解释一下的,但是你很难去形容这个负载和网络带宽消耗、内存占用 cpu使用率之间的一个直接关系,很难说明,这样出错的时候就很难知道是哪里出了问题,很难去调整,这是融合分的一个问题。
所以其实我们想要找到一个比融合分也就是线性回归模型更好的一些解释,其实主要是我们选的这些参数和我们的负载均衡之间虽然是强相关的,但并不是百分百的,所以我们想选择一些百分百的、直观的一些指标,能够衡量我们说的负载均衡的情况。怎么做呢,其实就是根据我们上面说的三个特性,不统计机器上的一些数据,我们统计这个进程里的一些关键性的数据,也就是我们把这个level提高一下,以前的话我们可能只是统计一个os层面的数据,现在我们统计的是一个业务层的数据,就是这个进程级别的数据,好处就是说更准了,我们的信息量更大了,一旦遇到问题,我们就知道是负载出了问题,按照我们上面的说法,约束二,我们的链接存在活跃和非活跃两种状态,对于活跃的状态,机器存在大量的活跃的链接的通信,那这个时候其实我们要,我们在分析负载均衡的时候,会分析这台网关机的哪些资源会最先成为瓶颈,如果最先成为瓶颈的那个资源,我们把他的分值打压放后,这样来做排序。也就是如果这个机器上存在很多活跃状态链接的通信,那么瓶颈一定是网络带宽,所以我们在业务层统计的是进程im gateway server的进程收发消息的数据包的总字节数,这个比较好计算,因为我们在收发消息的时候会写一些网络层的代码,就能计算出这个data的size是多少,然后原子性的加在一起,每一秒统计一次,就可以知道每一秒这个网关机收发消息的总字节数是多少,我们用他来代替网络带宽这个指标,更加置信,更好统计,这是活跃状态。但是对于静态状态,就是说这个机器上大多数的链接都处于静止状态的,就是没有活跃性了,这个时候网关机的瓶颈就在链接持续负载时的内存上,我们要创建定时器,创建一些队列,socket,都消耗内存资源,包括协程,协程没有逻辑没有消息收发 没有逻辑在执行,也就没有协程栈了,但他本质上会有一小截协程栈存在,也会浪费内存资源,当静止状态时,网关机的计算瓶颈在内存上,对于静止状态和活跃状态,计算机的网关机的计算瓶颈是不同的,所以我们需要去识别出来,大多数情况下,很多机器有一部分链接是活跃的,有一部分是非活跃的,正常的情况下,做个二分法,是处于一个中间状态的,所以我们就需要一个阈值,在这个阈值之上的话我们就认为他是个活跃的,阈值之下就认为他是静态的,这个阈值可能就是一个超参数,需要不断的调整,可以理解为就是一个激活函数。所以关键的一点是怎么去识别活跃,静态的去用连接数去衡量,活跃的就以字节数去衡量,阈值的话可以对这个先用字节数做排序,如果活跃的字节数相等,我们在用连接数做排序,也就是我们用两个字段去排序就行了,这是最简单的一个思想,融合排序,字节数我们可以用一个规约,就是我们对它求一个近似(如果这个收发字节数是1kb,1kb和100kb对这个资源消耗都不是很大,因为整体的网络带宽可能是两个g,1kb和100kb虽然差100倍,但也不是它的瓶颈,这个时候用字节数去衡量带宽由于它变化的比较快,所以很难衡量出来,字节数的变化是相对快的,因为是活跃的,所以这个时候用这个衡量并不是很准,所以这个时候用静态分衡量。我们吧字节数做一个规约,转化一下单位,所有单位都按GB计算,保留两位小数,如果是这样的话,1kb和100kb这个时候,1kb是0GB,100kkb是0Gb,这样的话就可以退化使用静态的连接数对它做一个排序。我们这个网关机刚开始启动的时候,活跃链接比较少,不按字节数来做负载均衡的判断标准,我们就用连接数来做负载均衡的判断标准。达到一定条件之后,活跃链接数比例已经多了,那这个时候我们按照活跃链接的字节数来做负载均衡,效果会更好一点。
但是这样的话还是会有一些问题吧,这并不难说明这是一个最好的状态,很难区分这个静态和动态。这里提出一个假设就是,无论怎么调,有阈值就会有割裂的情况,那么这个时候应该怎么去权衡呢,这个时候也可以用线性回归模型把这两个参数做个加权平均,就是说当这个活跃链接比较,当这个一台网关机动态分为1GB的时候,其他网关机只有0.8GB,我们会优先把调度到0.8GB的机器上,但是这个1GB的链接可能只有两个链接,这两个链接可能疯狂的发消息,变得很活跃,但是这上面可能只有两个链接数,所以可以看到在链接数上是完全不平衡的,一旦这两人不说话,这个网关机一下子就只有两个链接数,其他的网关机可能有上千个链接,会存在这样的一个的不均衡的问题。所以这个时候我们可以提出用线性回归模型,对二者进行加权平均,两害取其轻。大概是这个思想。
还有就是我们这个模型中没有去考虑ip地址,但是大部分的模型中,尤其是像我们这样的im,除非你像陌陌、探探这种同城聊天的话,你对IP地址的考量是比较重要的,像我们做vx这种通用型im的话很难去考虑IP地址的一个链接情况,不过这个也是可以的,我们可以考虑同一个省的都连在一起
- 如何降低延迟
维护长链接socket
系统现状
垂直扩展和水平扩展,这里其实有一个这样的逻辑就是,如果你这个业务比较少,用户比较少可能只有五十万万或者百万用户的时候,开发一个网关机,这个网关机每一台能存2w,可能只需要25台长链接网关机,就能把这50万长链接全部cover住,这个时候就是追求的水平扩展,那25台机器的集群没什么问题。但如果是上千万或者上亿级别的长链接,如果每一台存两w长链接,那集群的规模就要很大,节点之间的运维成本就会非常的高,很难去运维。一旦运维出问题,就有可能造成灾难性的后果。所以这个时候需要去追求垂直扩展,让单机存储的连接比较多
维护长连接socket的状态
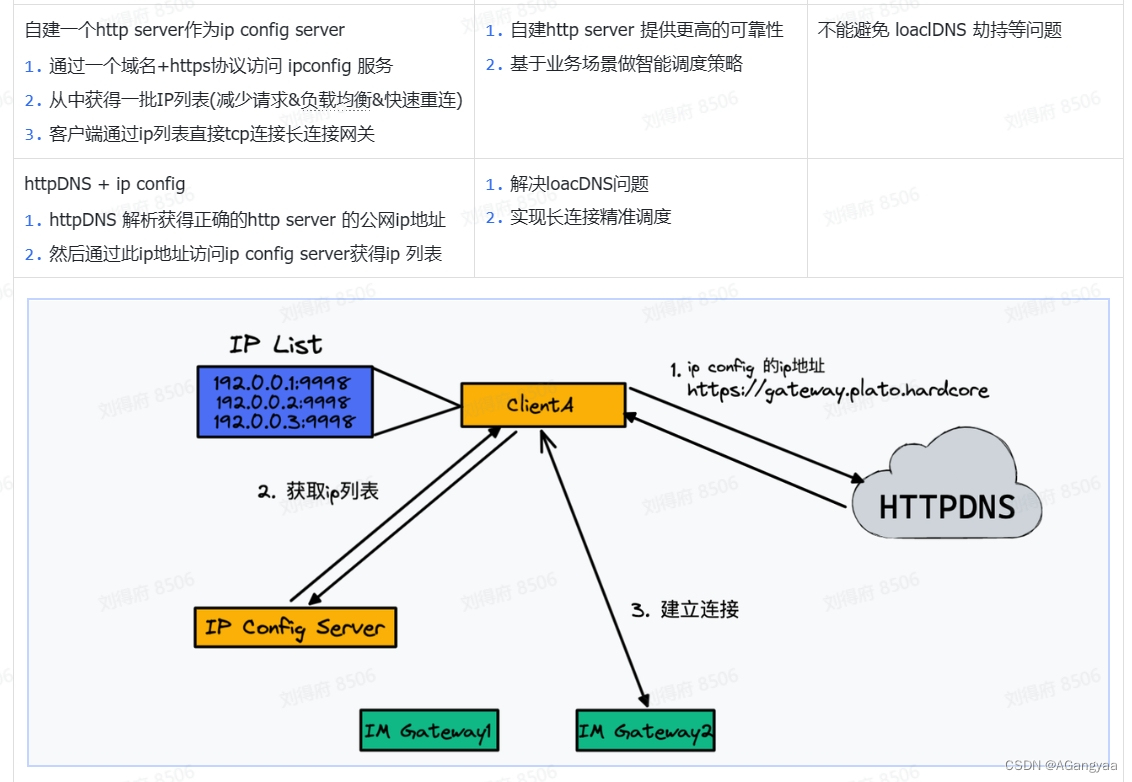
第一个要解决的就是怎么样在静态状态时,当这个连接跟服务器建立了tcp连接,没有收发消息的时候我们就称为静态状态,如何减少一个资源的内存消耗。本身接入层是工作在tcp这个层次上的,所以服务端是要维护一个状态的。最简单的一个方式就是一个accept去监听服务端的socket建立,会返回一个conn对象,拿到这个对象之后,要交给一个协程,然后协程有两个协程做收和发全双工,然后要有一个读read的这个socket的协程,一旦这个socket的队列中接收消息的时候,它就立刻从阻塞中的协程切换到非阻塞的状态,然后这个协程就开始工作,如果我们没有消息的时候,就陷入一个阻塞状态。同时写协程也是一样的,它监听一个写队列。
虽然这样很简单实现就能去工作了,但是这种并不满足内存要尽可能的小,这样,线程的时间复杂度开销就为0n,
因为一个协程也要有开销,一般静态的时候有2-4kb的量级,所以对于一个64gb的机器来说,最多可以存储八百万的链接,但是一般要留出一半的内存资源应对突发状况的热备,甚至要更低一些。也就是你只能存储400w长连接,在这个时候比如runtime有其他的内存使用,包括其他什么维护其他状态的内存信息,这种长连接网关很难达到30w甚至是10w长连接,如果是一个百万用户的,每台机器连两万,有50台机器就够100w长连接了那其实已经足够了,这样设计的话应对百万长连接的场景是没问题的。
这本身就是由于golang本身协程的资源消耗就很少,如果像Java的线程的话会占用更多资源,这个时候这样去设计就是不够看的,当前这种内存模型是不适用的,所以golang也是非常适合长连接网络的处理。所以我们这个时候就可以用一种方式就是epoll,它是linux提供的一个多路复用的一个技术,通常我们知道golang本身它底层的net网路就实现了这种epoll的技术,也就是它本身就是这种异步回调的方式,这种异步非阻塞的方式。这里是在应用层再实现一次,因为在golang的原生包它底层在处理消息的时候是异步的,但是它在应用层时就变成同步了,这就相当于处理底层类库的时候做到了非阻塞,一旦把这个消息传输给应用层的时候,就变成同步了,那这个性能就会下降。
这个资源占用也是一样的,每一个链接在静态的时候就算socket没有收发消息的时候,也有两个协程阻塞住这个socket,那两个协程就会占有一定的协程栈就会有内存资源,但是我们在应用层实现epoll的方法,如果socket没有读没有写事件的时候,就是在epoll的红黑树os层面去存储,我们的应用层不需要阻塞两个协程,只需要一个大的协程池就可以了。只有在accept事件发生,或者这个socket,reactor反应堆模式,这个时候它才会从工作池中拿出这个协程,当有读事件和写事件发生时,才会唤起一个协程去做处理,那这个时候就做到了多路复用,不需要阻塞协程。那这样的话就把两个协程都省略了,这样整体的一个内存使用情况就得到了一个进一步的提升。
然后就是要维护一个注册表,连接在创建的时候就要解析出did,因为业务层只知道一个did设备id,did和fd绑定一个大map。push的时候从uid拿到fd,再拿到连接。刚才说过,gateway的实现只是去持有长连接,但是长连接有两种接受消息和转发消息个state server做逻辑控制,状态server还需要告诉gatewayserver我要去给哪一个链接发送消息,是回复一个消息的ack,还是这个链接已经断开了要closed掉,还是说我真的要push一条消息,虽然这样设计是会增加通信成本,但是我们可以用一台大的物理机把这个控制层状态层和这个资源层部署到同一台机器上,这样虽然会占用同一台物理机的内存资源,但是这样的话把rpc的网络通信变成了进程间的通信,就用domain socket通信,那么它的整个网络通信的消耗就可以忽略不计。在维护注册表的时候,链接在创建的时候,我就需要把这个链接解析出did,因为业务层不知道fd的信息,只知道did设备id的信息,所以每个连接都是跟设备的id一一对应的,所以需要知道设备id是哪个,让设备id和链接对象绑定成一个大map,push的时候通过did查到fd,从fd中就可以拿到这个链接,就ok了,所以只需要维护一个大map
除此之外用到的协程池,想golang这种协程是一种资源,如果滥用协程,同样资源也是会耗尽的,所以我们需要去提高这个gateway server的一个可靠性,我们需要用一个协程池这样一个概念,把这个资源对象池化,资源对象池化之后呢做到资源的复用,不需要频繁的把这个协程创建和销毁,这样的话性能就会最高,同时也会做到资源上限的一个控制,资源池耗尽之后就拒绝服务,做了一个稳定性的控制,这也是池化的一个好处。
总结,主要就是长链接在静态时怎么样使资源消耗更少。有三大策略:有反应堆、异步回调的方式节省了两个协程,其次就是工作外包的一个思想,多进程拆分,把资源和逻辑隔离开,不然的话gateway server除了要频繁变更之外,还需要维护定时器、rpc调用关系等等业务上的一些逻辑,那这些都需要创建一个数据结构去维护这些状态,需要维护一个大map,这个did和链接是怎么映射的,而且定时器就是一个非常大的内存消耗,链接首先有个心跳定时器,所以这个心跳的定时器是和连接数相关的,比如100w长链接,就需要100w定时器,而且收发消息的时候也需要有一个定时器,因为消息在网络中发送出去的时候如果一段时间内没有发送出去要进行重发,确保消息的可靠性,所以这个定时器的成本就非常高,所以资源是收不住的,要做拆分。其次就是资源池化,对象复用,对象复用的好处就是对资源有个限度的管理,同时避免了不断庞大、比较消耗比较重的一些资源初始化和销毁的这样一个性能问题,都可以通过资源池化来解决,所以这三个策略就实现了最初的一个gateway的框架
实现的细节:有一个accept TCP会有多个协程accept listen住这个tcp,因为编写的不是http server,直接在tcp传输层做端口号的一个监听,listen多个多个协程不会有惊群的问题,多进程是有惊群问题的,但是在golang底层就处理好了,这样监听多个accept的好处是,以前普通的reactor模式只有一个协程、线程去监听accept,这样就是netty的模型,netty也可以设置,设置多个accept。这样的话,比如说有一个监听accept的协程 panic了,这样的时候多个监听accept的协程就互为back up,同时也会增加吞吐量,然后最终交给一个channel去处理,当然这个channel也可以搞多个,这样也会提高并发度,但是没有必要,因为已经达到单机的极限了,一个channel就足够了,这个channel就是accept好了之后就返回一个conn,这里面就有个fd,把这个fd发送给这个channel,那这个channel就会有多个epoller去监听,epoller就是封装的一个轮询器,轮询器里面也是有两个协程,epoll是服务初始化指定好的,比如我们指定cpu物理机的核数相对应,就是有16核就有16组轮询器,所以它是个常量,并不是跟你的连接数对等的,所以我们这个时候可以说协程数的复杂度是大o1,虽然连接数很多,但从算法复杂度的角度来看,它是一个常量,是有个上限的,所以它是大o1的。连接数本身是一个n,是线性的增长的,以前是2n,现在是o1,这也就是用epoll的好处,epoller两个协程,一个协程监听sub accept,其实就是说监听这个channel,监听这个channel里的fd,有多个核数就有16个协程,监听这个channel的fd作为消费者,消费到一个fd之后这个协程就会注册到自己所关联的epoll对象中,也就是每个accept有init初始化,初始化时就会调用这个创建epoll对象,这个epoll是os的系统调用,创建好之后epoll会返回一个fd,这个fd是关于epoll fd,fd是进程资源描述符嘛,可以是连接,也可以是epoll,有了这个之后可以存储起来,之后对epoll这个红黑树的操作都要通过这个fd完成,然后就是add,把这个代表连接的fd注册进来,注册进来之后这个fd在内核中会翻译成socket,epoll的底层是一个红黑树,然后红黑树里面呢每一个节点又会穿成一个链表list,这个链表就是当前可读或可写处于就绪状态下的socket组成的一个链表,所以这事内核中的一个复用模式,
这样的话另一个协程主要的作用就是wait,监听这个epoll的一个变化,一旦就绪队列里有socket就绪,那么它就会从阻塞队列中恢复,恢复之后,会拿到一批socket,比如有5个,就是当前时刻,有读事件或写事件,注册了什么事件,监听了什么事件,它就会产生一个事件的list,交给应用层,应用层就会把他分发给协程池做处理,然后这个协程池会解析做一个最外层的长度和data数据的一个解析,解析好这个data数据是二进制的数据调用rpc,把它交由控制层去做处理,交给它的时候要把endpoint就是它自己的端口号和fd交给他,这样的话就有了这个信息知道我这个网关机的ip和端口号和处于这个当前进程的fd是什么,就能够定位这个conn,然后这个rpc交给了状态server,因为这个状态server是一个无状态的是分布式的内存存储,会把这个存到一个map里,把它和did关联到一起,当业务层通过did找连接的时候会先找到endpoint和fd,找到这个之后会把这个消息发送给这个网关机,这个网关机拿到之后,会通过fd把消息发送到长链接。所以当accept拿到这个这个连接也就是注册的时候,会把这个fd mapping映射fd和conn,就是说这个fd的这个信息,会有rpc server传递进来,所以这个conn 都没有存did,直接存的fd和conn,did的信息是在状态server维护的,这样也节省了一个map的实现,要不然还要维护一个did到fd,fd到did的双层map,把这个endpoint和fd组成一个key,交给状态server去处理的话,它可以用这个分布式缓存数据,自己就不需要去做其他逻辑,这样的话就进一步节省了内存,性能也是无损的。rpc在push消息的时候,这个push消息就可以启动一个协程,这个协程会携带fd把这个消息发送到哪个连接上,所以这个网管及的实现是很纯粹的,没有什么其他的逻辑,这样的好处就是方便未来的灵活扩展
在持有socket的基础上,去控制socket收发消息
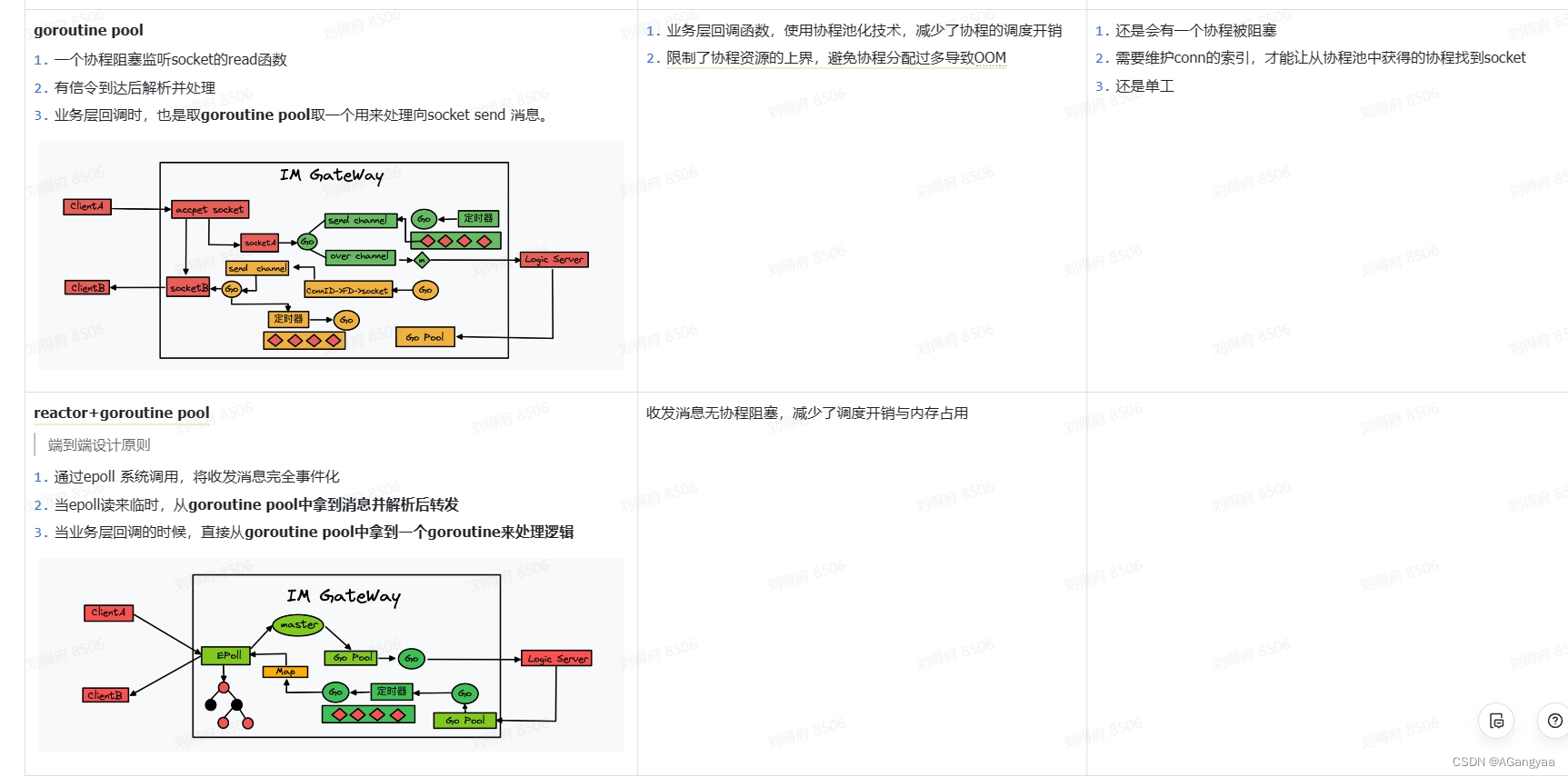
整个接入层,他的一个设计思想就是资源和控制的一个分离思想,也就是接入层的两个核心就是gatewayserver和state server,这两个server gateway server主要是持有长链接socket资源服务,state server就是一个控制服务,做逻辑控制,这两个server在一起组合接入层的一个核心逻辑。gateway server和state server基于rpc通信。
workpool协程池拿出一个协程,也就是gateway server调用rpc server的时候有两个操作,无论是发送消息还是什么,都不需要在意消息的内容是什么,只需要在意消息的结构就可以,对于它来说,消息的数据结构就是一个字节数组,直接把消息发送出去就可以,有一个send的rpc,还有一个取消操作,就是客户端主动断开连接或者是因为其他什么原因导致连接断开,这个时候,如果连接断开,gateway就需要一个手段,感知到连接的断开,主动的通知state server将状态清理,而不是等待state server主动的push一条消息的时候失败再去清理,如果一直不发消息的话,那状态就会占用内存,带来内存多余的消耗,所以要有取消连接的操作。那么state server作为一个rpc server要实现send 和cancel操作,然后接收到之后要有一个channel,把这个消息发送出去,告诉rpc server,然后他会作为一个client调用rpc server,然后 rpcserver 端要实现两个删除和连接(这个删除指的是服务端主动断开连接,作为gateway server来说,他没有权力断开连接,所有的控制逻辑都在state server里,所以他会主动的去断开连接,这样的话有一个断开连接的操作还有一个push消息下发的操作
技术约束
- 转发过程尽可能低延迟,这个是非常重要的,因为后端可能有很多业务逻辑,有很多微服务,如果由于实现资源和控制的分离,提高可靠性这方面的诉求,使延迟变得很高,这是不可接受的,因为这是一个基础服务,基础服务要做到尽量的对延迟无入侵的话是最好的,
- 所以说第二点要尽可能减少解析性的操作,因为解析性的操作会消耗内存也会消耗cpu,所以这块也是性能消耗,对于一些基础服务最看重的就是他的性能,也就是资源的一个使用情况,要尽可能的低
- 第三点就是处理rpc的异常,就是资源的调用过程中,网络错误或者超时了,要能做一些重试确保稳定性,比如超时,过载保护之类的
技术方案
首先最难的就是优化 gateway和stateserver的通信延迟,如果两个rpc通信,无论怎么样都是网络间的,网络之间的通信都在10ms以上的,当然有可能在一个机房,只有123毫秒,但是处理逻辑是复杂的,如何保证在push消息的时候延迟能够低于毫秒级的,做法很简单,就是使用多进程架构,把state server和gateway server部署到同一个docker里或者同一个物理机里,他们被绑定在一起,这个state server只操作他本机的gateway server,就和服务网格的遍车模式差不多,gateway和state 通过unix domain socket通信,这也是本地之间用于模拟socket通信的一种进程通信模式,服务网格就大量的使用这种手段,也就是在应用层是模拟socket进行通信的,是全双工的,但是他在底层并没有经过tcp/ip互联网的协议栈,而是在本地启动了一个文件系统,可能是个内存文件,然后这个内存文件是双工的,然后客户端发送消息写到内存文件,然后进程b读取这个内存把消息拿走,所以只需要经过本地的一个内存系统,所以性能相当的快,一定是低于毫秒级的,性能很好,解决了延迟的问题,然后设计这个state server的时候要考虑到这一点,这个state server只操作在同一台设备上的 gateway server,也就是不会出现这种扇出请求,这样的网络复杂度就会降低到最小,但是这个代码的复杂度就隐藏在了业务层和state server之间的通信
原理就是就近原则,本质上是没有走互联网的tcp/ip协议栈,整个处理过程就避免了网络中的拷贝,数据在多个协议层之间拷贝的情况,只是由一个进程拷贝到一个文件系统上,被另一个进程读取了,所以速度会非常快,这是对网络通信的优化
然后就是rpc需要哪些接口,当然这些接口要设计成什么模式的,可不可以做成两个接口,一个上行消息接口和一个下行消息接口,所有的命令通过一个接口也就是cmd信令的方式,这样的话一个接口就完事,然后所有的逻辑都在这个cmd里面,然后接收到这个rpc之后对cmd做一个switch,根据中断号去做不同的操作。当然除了这样设计的话还可以根据每一个cmd命令去设计一个rpc接口,这样也是可以的。另外对于每一个接口也可以是设计成一个批处理的形式,因为接入层的消息收发应该是很快的,消息收发会非常快的,延迟会非常低,qps会非常高,因为是底层操作,qps很高,那这个时候网络通信会非常的频繁,所以网络通信的次数是消耗比较大的地方,所以可以把接口做成批处理的形式,也就是这个接口是list,接受一连串的命令,一次性给用户返回,也就是在他的客户端我们要创建一个buffer,也就是把上游的命令不会第一时间发送出去,而是做一个缓存,缓存到多少条之后打包一起发送一条rpc,同时也需要在时间上做个限制,这样也就减少了通信的次数。但是其实gateway和state server已经使用了本地通信,既然都是本地的通信,那这个batch的操作就是可有可无的,不会快上很多。还有一种流的方式,grpc流模式的时候在发送一条消息的时候,上传下载的时候,传统的接口,必须全部上传成功之后才能进行下载,两步是同步的,流的话就是把这个粒度切细了,就是一个g的文件可以切成一小段一小段,每10m一个小文件上传之后都可以把这个小文件给下载下来,这样就变成流式的模式了,但对于im来说,每条消息都很短,基本上发过去之后很快就能解析完,基本上不需要有这种流处理,流处理基本上在大数据提高吞吐的场景下才会出现。对于im来说,实现的就是每个命令创建一个rpc,在服务端维护一个channel,异步的接受每一个cmd命令,在内部通过channel的方式来处理,这样的话就可以根据cmd拆分成多个channel队列,可以根据不同的命令做优先级的区别,比如说上行消息中,发送一条消息这个是用户直接感知的体验,所以他的优先级应该更高一点,但是对于像我们这个有个连接怪掉了,那这个时候gateway要通知state server要把这个连接断开,这个操作本质上是一个资源回收的操作,应该是一个后台任务,并不是一个用户真实感知的,其实优先级应该放低一些,所以这个时候比说出现交换机异常或者大规模的连接断开,那可能就产生大规模的资源回收任务,把真正的消息收发的任务给挤占了,那这个时候队列里全都是这种资源回收的任务,就会导致客户有明显体验的消息收发延迟感明显增加,用户的体验感就会下降,所以要区分不同的命令,分配不同的优先级,比如有一些撤回消息的命令,认为撤回命令应该要比发送命令的优先级更高,因为都删除了肯定是不想让别人看到的消息,所以删除消息的优先级要高于push其他消息的优先级,基于这个假设所以要做不同信令的区分
最终的实现方式:gateway调用rpc直接返回ok,会打包成一个cmd发送给channel去处理,当然是个生产者消费组的模式,拿到数据之后解析命令,可能是不同命令,然后把消息发送出去gatewayserver,然后gatewayserver 拿到这个命令之后然后再做处理
接口的定义就是grpc,所以有个pb的定义,
State server生命周期管理
连接可靠性,让长链接持有的更久
系统现状
client和gateway建立连接之后,他们之间会收发消息,但这个通道和我们平常所说的tcp连接有些区别,平常我们都是在一个数据中心中的tcp,很容易建立连接,而且并不容易断开,因为经过的路由器会比较少,而且网络环境也比较稳定,但是对于im系统这种长链接服务来说,他是需要跨越公网的,这里面就会有非常多的路由节点,要跨公网建立长链接,每一个路由节点的每一个服务策略都是不同的,会造成非常多的不确定性,那我们的连接可靠性就是要消除这么一个不确定性,可靠性难做的一个原因就是数据规模大,根据这个墨菲定律,在大数据的情况下,不可靠的事件都有可能发生。如果在持有百万连接的这种情况,那么可能会因为各种原因断开连接,造成这样连接的一个不可靠。
不可靠的原因,技术挑战
- 最常见的场景就是,公网环境下,肯定要经过运营商网络,运营商网络自己有一个为了减少服务路由的这么一个成本,因为要维护tcp路由表,表本身是占用一定的计算机资源的,即使字节数占用的很小,但也是占用一定的资源,为了减少机器的成本,就会周期性的扫描路由表,会把一段时间内没有收发消息的tcp连接清理掉,这个策略对运营商来说是非常好的,这样能有效的控制成本,不会导致黑客攻击导致占用大量的资源,整个网络陷入瘫痪,但是这样的话就会对im长链接服务造成一定的问题,运营商作为一个中间状态,在连接断开时都会发送一些final信号。所以在看客户端日志和服务端日志的,客户端会觉得是服务端断开了连接,服务端又会觉得是客户端断开了连接,感觉都是对端断开的,这种情况往往是由于服务的中间节点断开了连接,
- 其次还有数据中心都是有网关的,有l4或者l7网关,通常有两层,l4网关就是lvs,l7网关就是ngix,l就是层,l4就代表工作在四层osi的网络模型第四层的路由,不知道上游的应用层的信息,知道的是tcp、IP这些信息,根据这些信息去路由给下一层,通常会路由给l7层去代理,会做这么一个应用层的http转发,就是那url去做个转发,到真正的业务server,这种网关一般也会有一个tcp连接持有的最大时长,超过这个时长也会断开,所以要做长链接服务,要把这个也打通,
- 然后除了上面这种场景,还有一些场景比如移动互联网场景,客户端往往处于一种网络不确定性的一种状态,比如可能在可能在室内连wifi,移动到户外的时候就连接了手机的基站,这个时候长链接是必然会断开的,因为ip发生了切换。或者客户端可能会在一种高速移动的场景,在这种情况可能会出现移出漫游区域,从这个运营商基站,移动到另一个运营商基站,这种会导致ip地址的重新分配。当然有些运营商做了一些保证,虽然漫游区域发生了切换,但这个时候可能会让ip地址不发生切换,这样也就不会造成tcp长链接的断开,但如果运营商做这样的保证,连接就会断开。
- 除了这种强制的断开连接的场景,还有一些弱网的场景,就是网络状态不是很好,在地铁或者隧道当中,消息可能会传不过来,有丢包的现象,在这种弱网环境下,连接也有可能会断开,一旦连接断开,可能会非常影响用户体验,轻一点可能发消息就在那转圈,因为要重连连接,消息发不出去,重则由于连接断开,重连的时候可能会发生一些数据状态的改变,造成消息的错乱,vx好像也没完全解决这种问题,但是vx做的最好嘛,在隧道或者弱网环境体验会比较好些。
总结
- 中间代理资源的回收,这是导致连接断开的连断开
- 然后就是底层ip的切换
针对第一种原因,采用的方案也是im业务,无论是互联网的公司还是一些基础的开源的中间件,比如爱奇艺、喜马拉雅、知乎、vx或者像dubbo、zookeeper都会用的一种,就是心跳,心跳对于服务端来说是一种很常见的技术,也被用于很多场景,他的一个核心目标就是保活,就是告诉业务方,服务还一直存在着,因为网络是一种不受信的状态,除了通过这种心跳的方式,我们没有办法来获取一些信息知道服务还活着,只能通过心跳保活的这么一种方式。客户端会定时的给服务端发送消息,告诉服务端自己还活着,在这个过程中,就会刷新各个代理的一个超时时间,知道这个连接还是活着的,不能kill掉,会影响用户的一个体验,通常就是在链路上发送一个空的消息来防止资源的回收。但是有个前提就是,消息收发的周期要小于整个链路最小回收连接资源的周期。tcp连接作为一个传输层协议,就有一个长链接,可以开启一个长链接的选项,开启了底层就会发送一个心跳来保证长连接的状态,但是他的一个时间是两小时,但不同的运营商他的回收策略都是不一样的,中
国的话通常是5分钟,自己的网关可以自己设置,所以通常就是去服务商不可靠的这么一个最小值作为心跳的一次周期,
然后呢现在的问题就是由谁去发这个心跳,如果是服务端定期的遍历所有的socket去发,显然不可取,就比如有百万长连接,那每五分钟去遍历所有的socket,那就是一个巨大的带宽消耗,所以只能是由客户端来发消息,服务端创建一个定时器,客户端如果在规定的时间内没有发送,就把这个连接删除掉,回收资源,这就是心跳的一个设计
然后第二种原因,就是ip地址的更新,因为ip地址的切换会导致连接的断开,这种是没办法的,因为传输层技术上的一个约束。所以这个时候考虑的就不是长链接不断,因为做技术的设计,有时候要弱化嘛,退而求其次,做这种trade-off的折中设计,在这种情况下,去追求连接断开后,用户无感知的设计,那就是重试,不是说连接断开了,客户端就一定要告诉用户说连接断开了,因为用户有个反应时间,但计算机的反应时间很快,后台可以在一定时间内进行重试,直到把连接建立成功,这个时候用户在收发消息的时候,会觉得连接没有断开,但是底层已经把连接换了一个了,我们保证让这个连接断开之后,一段时间内能够快速的重连,来保证用户无感知,这是解决ip地址变更的一个办法。
然后呢,我们又根据技术上的一些约束条件以及一些资源情况做了一些优化,面试官我还要继续讲吗?
约束条件
- 资源成本,做这个连接的可靠性,要尽可能的减少服务器资源的消耗,这是接入层的一个重要目标,因为长链接要维护一个极速变化的一个服务,它不仅仅是一个有状态的server,同时对于长链接网络来说,它的变化是非常快的,基本上不可能持久化,对我们的可靠性造成一个工程性的挑战,所以为了解决这个问题,我们应该尽可能的节约一个资源成本,因为这些资源成本也就是状态,如果能维护的状态越少,就是越有利的
- 对于这个连接层最重要的就是可靠,任何各种极端情况下,都应该去快速恢复连接的一个,这是连接层非常重要的一点。
- 其次就是低延迟,不能因为维持可靠性就增加了延迟,因为毕竟是一个基础服务,基础服务延迟如果高的化,那业务就没法运作了
这是三个主要的技术约束
技术方案
- 编解码器,想要实现一个连接,就要在我们设置协议的基础上,设置一些信令,连接建立之后需要维护一些状态,比如我们就需要登录这样的一个状态,会传输一个数据包,这个数据包就告诉服务端它要登录了,这些数据包里会携带一些信息,最重要的就是设备ID,然后我们会根据这个设备id的处理逻辑生成接下来要进行消息收发访问的一些基本状态,这个就是登录的意思,当然登录指的不是账号的登录,而是连接的登录。登录好之后,然后这个心跳定时器启动,然后客户端在一定时间内频繁的发送心跳来保证连接的活跃,
- 时间轮,优化成本,成本的一个巨大开销就是定时器,因为定时器,是和长链接的是保持在一个水平扩展的状态,就是有多少长链接就要有多少心跳定时器,作为一个im,比如春节或者地铁上下班的时候,可能有个潮汐现象,大家都在这个时候登录,大量的建立连接,就会大量的创建定时器,会导致可能有很多定时器可能就在同一时刻开始定时,那这个时候,一旦定时器超时,就会产生绝大部分定时间超时,会出现调度潮汐,协程的调度可能就会出现问题,cpu的利用率会直接被拉满,同时定时器的存储也会占用极大的内存资源,那这个时候计算资源和内存资源都成为了瓶颈,golang本身想要提供一个高精度的定时器,他内部是四叉堆的实现,四叉堆的精度很好,但是会非常占用内存,同时插入和删除插入一个定时器的复杂度是logn,所以如果存在一些潮汐现象产生大量定时器都要插入这个四叉堆中,就会导致这个性能极度的损耗,为了解决这个问题,就要找到一个代替原生golang的定时器算法,因为其实并不需要高精度的定时器,这并不是一个强的技术约束,因为我们的心跳场景,迟一会或早一会都不会有什么影响,心跳的目的就是为了资源回收,不会对用户产生什么感知,所以这种场景比较适合用低精度的一个定时器,低精度的定时器可以有一个更好的时间复杂度,也就是时间轮,可以做到o1的时间复杂度,同时存储成本也会降低,优化了我们的一个性能,当然是以精度为代价的,kafka就实现了一个时间轮,很多好像和心跳相关的都基于时间轮
- 对于保证连接可靠性的时候,登录的时候要创建一个心跳定时器,然后从登录的信令中解析出一个设备ID,然后把channelID,channelID是等价于fd的,fd是存在一个bug的,fd是一个进程级别的,但是一旦跨进程传递给了stateserver,那么这个fd就不能唯一的表示这个链接了,我们是endpoint+fd,但是fd是会被复用,如果有延迟,可能会导致传到被复用的fd上,这样就把消息传递给了新的连接,可能会出现忽然有个莫名的人给你发了一条信息,造成这种消息的错乱,所以要有一个channelID的概念,这个通道表示就是一个链接,它是不可复用的,之前因为有复用的原因,所以会有消息错乱的问题,所以规定了channelID是一个int64的值是不断递增的,永远不会出现复用的问题,因为不需要维护全局的,维护一个进程级别的就可以,因为有endpoint做一个前缀,是个唯一的key,能够通过did找到endpoint和channelID找到这个链接在哪里,有这样一个路由信息
- 心跳的时候,当服务端接受到心跳消息的时候,会通过之前在登录的时候,映射的这个endpoint+channelID作为key,找到一个定时器对象,然后把这个定时器的任务重试一下,就是把这个定时器删除然后重新注册一个
- 重连的时候,我们面对的是一个ip的快速变更,所以也就是需要快速重连。也就是链接建立的状态,相对来说就是一个很重的操作,如果可以复用这个状态,那就可以做到一个快速重连的效果。比如说,这个长链接崩溃断开了,服务端感知到了,epoll中可以快速返回一个error事件,拿到这个事件后调用回调函数,直接通知给state server,让她把所有的状态、定时器、路由的key,等待一些状态全部清理掉,做链接的回收。但是我们的快速重连可以让链接断开之后,我们不会立刻回收所有的状态,而是进入一个延迟任务,这个延迟任务会执行一段时间,只要延迟任务到期之后,才会真正的把所有状态回收,也是启动一个定时器,交给时间轮,在一些极端的情况下,压力会非常大。在IP地址的变更场景,我这里是假设客户端断开连接之后是可重试的,相信这个客户端可以在10s之内快速的建立连接,然后再连接给这台机器,再连接给这台机器的时候,连接一旦创建成功,这个连接里就必须携带上次连接的channelID,所以channelID要随着ack或者心跳的方式把这个channelID返回给客户端,客户端在重连的时候告诉服务端老的channelID是什么,在重连信令中拿到老的channelID,就可以找到老的一些状态,就可以把这个channelID一替换,替换成新的channelID,相当于只换了一个底层的socket,而业务上的状态全都没有换,就实现了链接的复用,那也就不需要创建定时器,告知业务层感知,然后业务层做一些数据的处理、日志的打印或者什么一大堆的操作不需要做了,所以速度就会很快,这个就是快速重连,也就是就是资源的复用和链接的复用
消息可靠性,端到端的可靠性
前言
这个可靠性和指的端到端的可靠性,不是tcp的可靠性,是指客户端A,客户端B以及服务端三端通信之间的可靠性,不是说客户端A到服务端这么一个上行消息的可靠,这个tcp就可以保证,但当然tcp本身也只是保证在传输层到网络层的一个可靠,进了你的webserver容器,也有可能丢失,业务如果没有处理清楚,panic了,消息也有可能丢失,所以本质上来说,tcp也不是端到端的可靠,这里强调的可靠是三端可靠,上行消息可靠,下行消息可靠。当然消息可靠有他自己的一个技术约束,不重、不漏、有序、及时,也就是客户端A到客户端B的消息不能重复、不能遗漏,客户端B感知消息的顺序应该和客户端A发送消息的顺序保持一致,然后发送的速度要及时,
技术约束
- 从服务端的视角来看,我们的系统,第一高可靠,至少要5个9以上的消息可靠,因为收发消息对于im来说是核心链路,所以可靠性要求非常高
- 其次就是及时性,因为用户对消息发出去的及时性非常的敏感,所以要求低延迟
- 然后就是高吞吐,对于极端的群聊场景,比如万人群聊这种,在特点活跃时间内,每发一条消息都是一次ddos攻击
技术方案
消息的可靠分为上行消息可靠和下行消息可靠,所以把这个问题缩小,先看客户端A到服务端的上行消息可靠
- 首先是消息不漏,消息在发送的时候可能会丢失,丢失的原因可能会有很多,客户端A在去发送消息时可能要经过层层的中间组件,其中某个组件panic了,然后就导致消息丢失没发出去,或者消息发出去了,到某个路由器,路由器挂掉了,导致消息丢失,到了服务之后,服务的网关层panic了,这样消息也丢失了,会有很多种可能性,导致消息没到达服务端。
传统的解决方案ack和消息重试,启动一个消息的定时器,在100ms之内还没有收到ack,就重发一条,一直重发一直重发,直到服务端回复个客户端A,就把这个定时器关闭掉,这样就可以做到消息的不漏,消息一定会到达服务端。但是这样的话就会引出一个问题,如果重复发送消息的话,由于网络之间的抖动,无法区分消息丢失和延迟之间的差别,也就是说,消息有可能是真的丢了,那这时候重发是没问题的,但是这个消息有可能是延迟的,定时器超时重传又发送一条,这样整个相同的消息就会有两个,这个延迟过去之后,两条消息都到达了服务端,那么就会出现重复的现象 - 解决重复,我们给每一个message分配一个ID,这个ID由客户端分配,从0开始一直不断自增,这样就有了一个顺序,根据这个id去判断消息是否已经存储了,
- 有序的话这个messageID是一个可排序的字段,从而保证消息的顺序
最大的问题在于消息的量级会很大,不满足我们的上面的约束高可用、高吞吐和低延迟和低成本,不能因为存储messageID来消耗过大的内存,影响可用性,服务崩溃重启可能需要很长的时间来恢复
解决的办法呢首先就是tcp协议里面有个解决方案,在服务端和客户端都维护了一个list飞行消息的队列,这个消息发送出去,就存在飞行队列中,一旦ack才把这个飞行队列里的消息给删掉,服务端也是,但是对于百万长链接,可能就很耗内存
所以退而求其次,就只保留一个消息ID就是clientID,clientID不需要全局有序,只需要客户端维护的每个会话是从零开始不断递增的,每一次发消息+1,然后每一次持久化,这样的话服务端每一次都维护一个maxID,当消息过来之后,它只会接受maxClientID+1,否则就会忽略,因为首先是在tcp上传输的,tcp已经保证了在传输层的有序性,所以在到达业务层的时候这个乱序的可能就很低了,所以这种其实不会造成大量的重试,当然也会有。所以这个TCP有序和业务上的有序其实是两个概念,要在业务层实现自己的消息有序性。
当消息存储到redis中,就会立刻push给客户端b,push的逻辑其实也需要有一个消息ID,但这个是服务端生成的,这就有讲究了,服务端是不能重启的,可能客户端只需要维护一个sessionID就可以了,服务端要维护上十亿个,所以对于服务端来说要维护的话就不能叫clientID了,应该叫messageID了,是会话维度的,不需要全局唯一,只需要sessionID+messageID能够具有唯一性就可以了,这样的话设计会简单一些,messageID假如是单调递增的,其实是有非常大的难度,客户端B只会接受max_id+1,否则忽略,接受了则回复ACK,
实现state server分布式化
背景介绍
State server是一个状态服务,这个server本身是一个进程,如果这个进程退出,状态就会完全丢失,因为它把所有的数据都存在内存之中,首先把连接的持有和状态的持有分成了两个server来维护,是为了state server频繁的重启,只有它能频繁的重启,才能保证迭代的效率和可靠性,所以要把state server中的状态迁移到分布式的存储中心上,就把内存中的状态分布式化,迁移到redis中,然后state server就可以无限的水平扩展,崩溃重启之后立马就可以恢复,客户端无感知。
然后做到的一个效果就是state server如果崩溃,但是它没有持有资源,客户对这个重启就是没有感知的,然后state server状态恢复,仍然可以进行通信,所有的消息也没有丢,所有的状态也都是一致的,然后就能做到整个接入层没有单点,任何一个挂了,服务重启,整个服务依然可以运行,做到高可用,然后每一个数据占用内存,都是可以水平扩展的,可以通过加机器的方式,然后扩展它能够承载的长链接的规模,
目标及约束
我们要把state server改造成一个无状态或者是半状态的服务,把所有重启之后,跨进程生命周期的状态存放在redis中,提升它的可伸缩性和可用性
目标也就是无状态或者是半状态,,服务可以随时重启,
低延迟,因为以这种分布式存储为中心,那么存取状态就要通过网络调用的方式,这也是中心存储的一个代价,
技术方案
connID是在本地生成的,是一个int64的值,从0开始累加,这就是clientID的一个生成,一旦分布式化面临的问题就是,connID要存储在redis中,那就要做一个全局唯一的key。哪想到的一种方式就是endpoint+coonnID,这样就不会重复了,但同一台设备崩溃重启之后,endpoint不变,connID继续累加,这样的话可能还是会出现重复的现象,导致两个连接拥有同一个标记。然后redis有个runningid的概念,这个是一个uuid表示一个进程的字符串,全局唯一,用runningID+endpoint+connID,这样的话就可以做到整个id全局唯一。但问题是,由于runID和endpoint都是字符串,如果在gateway和state server中用字符串通信,那网络带宽就会占用很多,虽然做业务研发传一个字符串可能不在消耗的计算范围呢,但接入层是一个基础服务,有一个性能尺度的问题,做一个业务系统的话,用户的感知保持在一次逻辑处理在五六百毫秒,用户可能就会觉得是很流畅的,但是作为长链接收发的基础服务,每秒钟可能会被触发百亿次,如果通过字符串传输,那么带宽的浪费就会触发百亿次。所以他们的性能尺度不一样,要把网关的响应要控制住几毫秒甚至更少,所以网络带宽的一个消耗对于io密集型系统来说是一个非常致命的点,因此不能使用这个字符串传递,而使用int64的值做编码,这个场景也可以抽象为在分布式场景下全局唯一的一个id值,其实就是雪花算法。然后再去想优化的话,其实connID并不需要一个全局唯一的id。
然后就是state server改造成无状态的服务,首先state server的结构体里有心跳定时器,重连定时器,消息定时器。connID和maxClientID,其实分布式化就是把这些放到redis中
首先是connID是如何存储在redis中,connID作为key能够代表是一个整个state状态的,存储的时候要考虑的几个点点要考虑:第一何时存储到redis里,第二,什么时候删除,第三如果state server进程崩溃,重启的时候我们要reload,也就是由三个操作,第一个是add,第二个是delete,第三个是reload,还有一个get什么时候查询。然后采用redis的set的数据结构去存,set其实就是一个数据集合,这个set在redis中实现就是一个map,map的key是有点,value是空值,在redis中,我们通常要分布式存储嘛,然后我们要hash分片,不能把所有的connID存到一台单机的redis中,要分布式存储,也就是要涉及到一个hash shard的过程,直接就用hash的方法去做分片,因为connID没有时间戳,假定的分片是1024,根据hash取模得到一个槽位,然后把所有的槽位的值都放到这个槽中,那这个槽就是set集合的key,这样就会有1024个槽,也就是1024个set集合,每一个set集合我们通常控制它在5000条数据,因为redis里有个大key的概念,如果key过大,单线程的就容易把io打满,
然后他的一个过程能就是,当连接登录的时候,gateway server发送一个rpc给state server,加入到redis的shard中,当连接挂点时,重连定时器就会把这个set通过connID把这个set集合中给delete掉。然后就是reload,当这个state server挂了,重启之后,第一步登录进来之后redis里面已经写了一个set的集合了,
在state server重启进行读取的时候 要去加载set中的数据,在其配置中划分其所要读取的slot的range信息即可初始化阶段遍历slot批量读取set集合中的connID,基于connID的信息恢复一些信息。
但是这里需要注意的是,如果state server 写入sl+
ot是hash的,也就是说他可以任意的写入不同的slot上,但是当state server宕机重启后,仅取加载其配置的sot上的conn信息,这就导致conn的状态发生了迁移,不再+++原来state server上,但是按照现在的架构必须保证gateway server请求唯一的state server,否则将找不到对应的状态。如此说来conn信息的迁移将导致conn状态的丢失,因此hash是可行的。
为此,我们只能是配置的slotstate server的connID只能写入到配置的slot上,并重启时加载配置slot中的connID即可,如此才能实现state server的重启。
注: 这样的设计将使得state server难以扩缩容,这就是有状态服务相对于web server的技术挑战所在,对于状态我们只是将其分布式存储而已。
然后读取到connID的时候,需要去检查在崩溃之前有没有push的消息,也就是说state server在崩溃的时候,有正在push的消息,那么分两种情况,已经push给了客户端,和没有push给客户端。如果没有没有push给客户端,这个时候崩溃了,应该给im客户端返回一个错误,也就是没有送达给客户端,imserver就已经收到rpc调用失败报错,这个时候imserver重试即可,然后第二点就是说im server这个消息已经push给客户端,但是没有收到客户端的回执,但这个时候impush给state server这个rpc已经结束了,那么这个时候消息就有可能会丢失,那么这个时候我们必须要把这个msg信息存储下来,然后还要想一个地方就是我们发送消息之后,收到ack和没收到ack两种情况,如果ack收到了,我们就要把msg删除掉,没有收到这个ack,我们当前这个msgTimer依旧在运行,如果在收到ack之后崩溃,或者在没有收到ack崩溃,这两种情况又有一些区别。如果收到ack,没有把redis中的msg删除,这种情况下,就相当于丢失ack,然后我们在重启的时候,需要知道这个msg是不是删除,我的做法就是无论msg有没有收到ack,都new出一个新的msgTimer,最坏的情况也就是new出了两个msgTimer的间隔才把这个消息真正的删除。那客户端就有两种情况,第一个就是之前就已经ack过了,或者是这个消息ack失败了,无论是哪种情况,msgTimer到期把他删除就可以了,这样也就实现了state server重启之后,飞行消息能够发送出去
然后就是这个msg的存储,其实只需要存储最后一次push的msg就可以了,因为可以采用推拉结合的这么一种方式,因为我们长链接的push推送,本质上是一种通知客户端有消息到达,这样客户端不需要去服务端轮询造成带宽的浪费以及时延的问题,无论时延选择多少窗口,都有延迟。就比如消息有1,2,3三条,redis里只存第三条消息就可以了,其中1,2,两条消息有可能在push中丢失了,网络有延迟或者网络不稳定,只有第三条消息会去重试,
重试发送给客户端,然后这个消息发送给客户端,然后客户端发现自己有最大的seqID是0,但接受的是3,客户端也就知道有消息漏洞的存在,客户端就会主动去请求,把1,2消息拉过来进行消息补洞,所以只需要存储lastmsg就可以。但是这里有个问题就是ack,如果我发送1,2,3三条消息,假设1消息已经接收到了,那么2丢失了,3发送出去了,这个时候redis存储的是第三条消息,然后1消息的ack已经收到了,这个时候服务器就可能把3消息给ack掉了,然后第三条消息没有发送成功,客户端就会永久的丢失第三条消息。如果存在这种情况,就存在了严重的消息丢失问题,所以这里需要加一把锁,拿msg拼个字符串做一把锁,锁住当前的msgtimer,也就是每次更新这个lastmsg的时候,就要把这个标记更新,就是说当前的msgTimer锁住的是哪条msgID,如果ack发过来的msgID不匹配,就不ack,也就相当于把之前的ack都忽略掉了,只保留最基础的那个ack消息就可以了,这样的话,就做到只有对的上的消息才会ack,不会错乱ack
然后需要考虑的就是,需要恢复连接的心跳功能,也就是心跳定时器。但是这里我没有存储一个当时的时间戳,因为存储那个时间戳,因为存储原来的时间戳会占用资源存储成本会比较高,而且可能存储的时间戳很容易就和当前时间差很多,而且再与redis进行交互又会增加带宽消耗,所以不如直接不存了,不与redis通信了。一旦重启,就直接重启一个timer,就按最大的限度去计时,因为不论是心跳还是消息的重发,都不需要那么精准,最大的量两倍的rtt也是可以接受的
还有就是保证max_clientID就是上行消息的恢复,如果这个id丢失了,就不能保证消息的连续性,就会发生消息发送不出去的问题,也就是需是需要把这个max_clientID存储到redis中,每次更新都需要存储到redis中,每一个session都有一个max_clientID
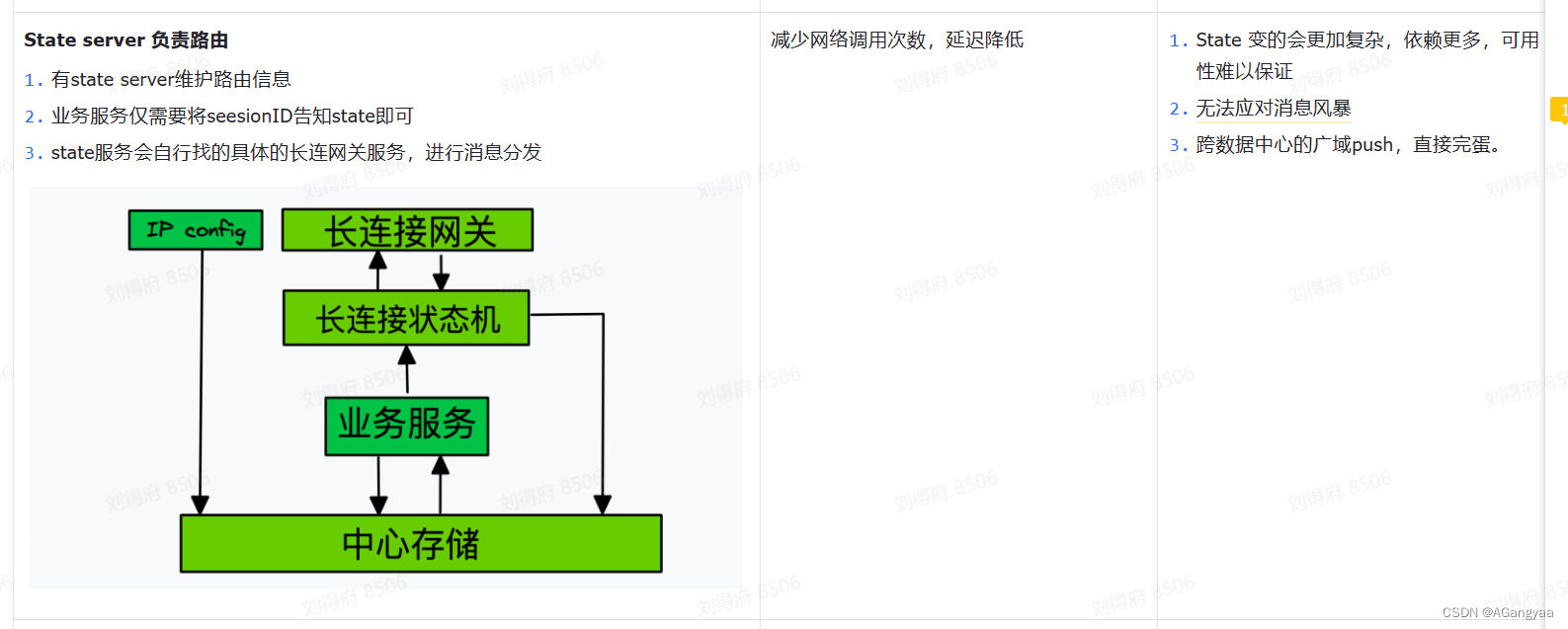
最后就是分布式场景下,gateway server和state server如何通信,上面只是把单机的状态放在了redis中,这是有状态服务的弊端,存算分离,业务代码是无状态的,存储部分是有状态的,存储的部分放在redis中。服务端尽量做成无状态的
如果我们长链接是服务发现的或者是负载均衡的,一个连接的请求被其他的state server做处理,其他的state server是没有这个状态的,因为连接是完全垂直切分的,那就会出错,这样的话gateway server和state server
出现了强绑定的关系,也就是gateway server node1节点只能跟 state server node1节点匹配,他俩之间做一对一通信,而不能负载均衡,而不能负载均衡,虽然这样会失去一定的可用性,但是对于一个有状态服务来说,好像只能这么设计,只能这样垂直扩展,提升他的一个重启之后的恢复速度,由于把这个状态都放到redis中,重启之后reload数据就可以,所以就必须保证 state server和gateway server是一对一通信的,也就是在配置文件中写上一些配置,也就是一个gateway server和一个state server做绑定,相互指定他的endpoint,然后state server也和redis的哈希槽也做了一个分片,一个state server只会操作划定的redis的分片,这样的话其实扩展gateway server和state server和redis的哈希分片其实也是可以无限扩展的。上行消息发送过来时,如果路由错了state server,就会导致状态长不到,其实做这样的绑定也可以节省一个路由的操作。这样的话其实设计的架构就是可以水平扩展的。如果是群聊消息的话可以使用mq的批量发送,如果是点对点的直接rpc发送即可
这种架构设计模式其实也可以做单元化部署,也就是当一个集群,有百万规模或者十几万的规模的时候机器的大集群,都会出现单元化部署的思想,这样gateway server和state server和redis组成一个单元进行无限的水平扩展,打但是这样的话就需要有一个路由,也就是需要下游的业务imserver是如何找到state server的,因为对于业务im server的话,作为外部服务看到的是一个did一个设备,而不是内部的clientID,所以需要一个设备到client的一个映射关系,不仅到client还需要知道这个clientID在哪台机器人,如果是点对点通信,通过rpc调用,就需要知道endpint的信息,这种映射关系就是路由,所以我设计了一个sdk,没有做成server服务,因为如果做成server服务的话又会增加新的网络调用,所以更好的一种方式就是做成了sdk,在做个不同的场景下复用。也就是对外提供的时候,比如imserver可能是一个业务方,而我们可能是一个消息中台,那么imserver就是一个业务方,给业务方提供一个调用中台的一个sdk,是一个很固定的一个操作,业务方通过这个sdk就可以使用中台的能力,去发送长链接消息
UNIX Domain Socket
socket API原本是为网络通讯设计的,但后来在socket的框架上发展出一种IPC机制,就是UNIX Domain Socket。
虽然网络socket也可用于同一台主机的进程间通讯(通过loopback地址127.0.0.1),
但是UNIX Domain Socket用于IPC更有效率:不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程。
UNIX域套接字与TCP套接字相比较,在同一台主机的传输速度前者是后者的两倍。
这是因为,IPC机制本质上是可靠的通讯,而网络协议是为不可靠的通讯设计的。
UNIX Domain Socket也提供面向流和面向数据包两种API接口,类似于TCP和UDP,但是面向消息的UNIX Domain Socket也是可靠的,消息既不会丢失也不会顺序错乱。
时间轮(Time Wheel)是一种数据结构,用于实现基于时间的事件调度系统。它被广泛应用于计算机网络、操作系统、分布式系统等领域中。
时间轮概念
时间轮的基本思想是将时间划分为固定大小的时间段,并将这些时间段组成一个环形结构。每个时间段对应一个槽(Slot),槽中保存了在该时间段内需要执行的事件列表。时间轮按照固定的时间间隔(通常为1秒)逐个推进,当时间轮的指针指向某个槽时,就执行该槽中所有事件。
优点
高效处理批量任务
时间轮可以高效的利用线程资源来进行批量化调度,把大批量的调度任务全部都绑定时间轮上,通过时间轮进行所有任务的管理,触发以及运行。
降低时间复杂度
时间轮算法可以将插入和删除操作的时间复杂度都降为O(1),相较于JDK 提供的 java.util.Timer 和 DelayedQueue 等工具类,其底层实现使用的是堆这种数据结构,存取操作的复杂度都是 O(nlog(n)),无法支持大量的定时任务。
缺点
时间精确度的问题
时间轮调度器的时间的精度可能不是很高,对于精度要求特别高的调度任务可能不太适合。因为时间轮算法的精度取决于时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度。
可以采用多级时间轮提高精度
宕机后无法恢复重新调度
时间轮任务队列存储在内存中,没有做宕机备份,无法在宕机恢复后重新调度。
支持宕机恢复需要做很多额外操作,可以参考携程QMQ实现
高可用:
如何保证整个服务的高可用性,要从两个角度上考虑。第一个角度就是,首先要对im的业务实现业务上的高可用性,也就是本身要去处理由于im系统自身原因导致的不稳定的一些因素。对于im业务来说,对于一个长连接的资源服务来说,要去保证其长连接的可靠性,也就是要去确保其在不同网络状态的情况下,其长连接的可靠性,保证其资源持有的更长久。然后就是,对于im业务,也就是我们使用的vx、qq、飞书这种的通信工具,去确保其消息的可靠性,保证其消息的有序、可达、及时、不重、不漏等消息通讯的特点。这个是业务层需要去保证的可靠性。保证了业务自身的高可靠性之后,就要去保证服务整体的可靠性。
整个接入层,他的一个设计思想就是资源和控制的一个分离思想,也就是接入层的两个核心就是gatewayserver和state server,这两个server gateway server主要是持有长链接socket资源服务,state server就是一个控制服务,做逻辑控制,这两个server在一起组合接入层的一个核心逻辑。保证其服务整体的可靠性,也就是要去确保其这两个服务的可靠性。
反问,面试官,你是想听我介绍哪一个呢?是介绍业务上的高可用性,还是服务整体上的可靠性呢?
服务整体的可靠性:刚刚也说了,接入层是一个资源和控制分离的一个sider-car思想,拆分了资源层gateway server和控制层state server层,服务整体上的可靠,就要保证这两个服务的可靠。也就是gateway崩溃或重启,对state server无影响,state server又因为是控制层,也就是会持有一些状态资源,state server崩溃或重启,首先不会对gate server服务有影响,然后其持有的状态资源,不会因为收到服务本身状态的波动而受到影响。
如果gateway server崩溃了,本身其是一个进程级别的服务,崩溃之后,迅速重启就可以。做了拆分之后,state server本身不会受到影响,作为一个控制服务,因为其没受到影响,这个时候只要控制其连接重连即可。
如果state server崩了,跳转state server分布式化, 这样其state server崩溃了,不会对其状态资源丢失,也不会对gateway server造成影响
如果是机器崩了,这个是机器的故障,这个时候客户端重新建立到新的机器中,建立新的资源即可。
高性能
epoll
第一个要解决的就是怎么样在静态状态时,当这个连接跟服务器建立了tcp连接,没有收发消息的时候我们就称为静态状态,如何减少一个资源的内存消耗。本身接入层是工作在tcp这个层次上的,所以服务端是要维护一个状态的。plato选择tcp长连接作为传输层通信协议,因此需要在服务端维护socket的状态,最简单的方法就是两个协程对应一个socket,一个处理此socket的读,另一个处理此scoket的写事件,并且需要有一个协程作为server socket监听服务端口,执行accept 逻辑,因此需要1+2N的协程数来监听维护socket的状态,其中N是gateway的持有连接句柄数量。虽然这样很简单实现就能去工作了,但是这种并不满足内存要尽可能的小,所以要进行优化
如果我们使用epoll的多路复用技术在业务层再次实现,那么即可通过reactor模式减少在连接静止状态下内存的消耗。
只有当有读事件或者写事件发生时才会从协程池中获得一个协程去读写socket,当有消息push的时候才会创建个协程,然后查询注册表信息找到socket进行读写,因此在连接静止状态下将没有协程的资源消耗,大部分的资源消耗会转化为os中epoll的红黑树的内存占用,而内核的性能将远高于业务进程,没有复杂的协程调度整体的GC和阻塞情况都将得到缓解,性能得到提升,完全可以做到单机突破百万长连接。
- Epoll reactor怎么用的
是什么:
epoll 和 Reactor 是两种在编写网络服务时常用的技术概念,广泛应用于处理 I/O 事件,特别是在高并发的服务器端编程中。
epoll
epoll 是 Linux 操作系统中的一种 I/O 事件通知机制,比传统的 select 和 poll 方式更加高效。epoll 能够在大量的文件描述符上高效地等待 I/O 事件,因为它不是每次调用都需要重新传递所有监听的文件描述符集合,而是可以在文件描述符上注册感兴趣的事件,当这些事件发生时,epoll 可以通过一种叫做 “就绪列表” 的方式通知应用程序,这样应用程序只会处理那些已经就绪的 I/O 事件。epoll 使用了以下三个主要的系统调用:
- epoll_create:创建一个 epoll 实例。
- epoll_ctl:向 epoll 实例中添加、修改或移除文件描述符。
- epoll_wait:等待注册的事件发生,返回就绪的文件描述符。
Reactor
Reactor 模式是一种事件处理模式,用于分离事件接收和事件处理的逻辑。在这种模式下,事件处理器负责监控一组事件源,并将活动事件通知给相应的事件处理函数或者对象。
在 Reactor 模式中,有以下几个重要的组件: - 事件循环 (Event Loop):循环等待事件的发生,并分发事件给对应的处理器。
- 事件处理器 (Event Handler):为特定事件类型定义的一个或多个回调函数。
- 资源 (Resource):文件描述符或网络连接等,事件循环会监听这些资源上的事件。
在服务器端网络编程中,Reactor 模式通常被用来监听和处理网络事件,例如请求到达或连接关闭等。在实际实现中,epoll 可以作为 Reactor 模式中事件循环的一种技术方式,用来监听文件描述符上的事件,它能够高效地管理和监听大量的网络连接。
他们常常一起使用:Reactor 模式定义了事件的管理和分发结构,而 epoll 提供了底层的系统调用支持。这种结合使用可以构建出同时高效和灵活的网络应用程序。
怎么用的
有一个accept TCP会有多个线程accept listen住这个tcp,因为编写的不是http server,直接在tcp传输层做端口号的一个监听,这样多个线程accept的好处是,以前普通的reactor模式只有一个线程、线程去监听accept这样的话,比如说有一个监听accept的线程 panic了,这个时候多个监听accept的线程就互为back up,同时也会增加吞吐量,。accept好了之后就返回一个conn,这里面就有个fd,把这个fd发送给其中一个epoller,有多个epoller监听,epoller就是封装的一个轮询器,轮询器里面也是有两个线程,epoll是服务初始化指定好的,和我们指定cpu物理机的核数相对应,就是有16核就有16组轮询器,所以它是个常量,并不是跟你的连接数对等的,所以我们这个时候可以说线程数的复杂度是大o1,虽然连接数很多,但从时间复杂度的角度来看,它是一个常量,是有个上限的。连接数本身是一个n,是线性的增长的,但时间复杂度却只有o1,这也就是用epoll的好处,epoller两个线程,一个线程监听sub accept,监听这个fd,有16个核数就有16个线程,监听到的这个fd就被作为消费者,消费到一个fd之后这个线程就会注册到自己所关联的epoll对象中,也就是每个accept有init初始化,初始化时就会调用这个创建epoll对象,这个epoll是os的系统调用,创建好之后epoll会返回一个fd,这个fd是关于epoll fd,fd是进程资源描述符嘛,有了这个之后可以存储起来,之后对epoll这个红黑树的操作都要通过这个fd完成,然后就是add,把这个代表连接的fd注册进来,注册进来之后这个fd在内核中会翻译成socket,epoll的底层是一个红黑树,然后红黑树里面呢每一个节点又会穿成一个链表list,这个链表就是当前可读或可写处于就绪状态下的socket组成的一个链表,所以这是内核中的一个复用模式,
这样的话另一个线程主要的作用就是wait,监听这个epoll的一个变化,一旦就绪队列里有socket就绪,那么它就会从阻塞队列中恢复,恢复之后,会拿到一批socket,比如有5个,就是当前时刻,有读事件或写事件,注册了什么事件,监听了什么事件,它就会产生一个事件的list,交给应用层,应用层就会把他分发给线程池做处理,然后这个线程池会解析做一个最外层的长度和data数据的一个解析,解析好这个data数据后,把它交由控制层去做处理
ipconfig 负载均衡
可伸缩性
介绍一下这个整个系统服务的特性,整个接入层,他的一个设计思想就是资源和控制的一个分离思想,也就是接入层的两个核心就是gateway server和state server,这两个server gateway server主要是持有长链接socket资源服务,state server就是一个控制服务,做逻辑控制,这两个server在一起组合接入层的一个核心逻辑。如果想要做到可伸缩性,由于我们这个接入层系统本身是一个有状态的服务,由于我们做了资源和控制的拆分,持有状态资源的服务在state server服务里。
State server是一个状态服务,这个server本身是一个进程,如果这个进程退出,状态就会完全丢失,因为它把所有的数据都存在内存之中,首先把连接的持有和状态的持有分成了两个server来维护,是为了state server频繁的重启,只有它能频繁的重启,才能保证迭代的效率和可靠性,所以要把state server中的状态迁移到分布式的存储中心上,就把内存中的状态分布式化,迁移到redis中,然后state server就可以无限的水平扩展,崩溃重启之后立马就可以恢复,客户端无感知。
然后做到的一个效果就是state server如果崩溃,但是它没有持有资源,客户对这个重启就是没有感知的,然后state server状态恢复,仍然可以进行通信,所有的消息也没有丢,所有的状态也都是一致的,然后就能做到整个接入层没有单点,任何一个挂了,服务重启,整个服务依然可以运行,做到高可用,然后每一个数据占用内存,都是可以水平扩展的,可以通过加机器的方式,然后扩展它能够承载的长链接的规模
然后做成这个效果之后,服务即可水平扩展。
对于上游服务感知,则是通过ipconfig服务,即我们有一个能够感采集知下游机器负载情况的服务,新扩容的机器肯定是负载最低的,所以上游在建立连接时会优先建立到新扩容的机器上去,,对于下游服务来说,我们有个router服务的路由表,根据这个router服务来去定位到下游
从而实现了整个服务的可伸缩性
redis里存了什么
本身state server持有的就是长连接的一个状态资源,他的状态资源可以从两个角度去考虑,一个就是长连接的标识,一个就是消息的标识,redis里存的呢,也就是这两个角度的状态的一些映射
首先是链接的标识,每一个链接会有一个connID,是一个long值,大部分的状态也是根据其connID去映射
映射会话的sessionID和did,能够通过sessionID去找到一个msgID,对于msgID其实只需要存储最后一次push的msg就可以了,具体的可以看消息可靠性去回答。
然后需要考虑的就是,需要恢复连接的心跳功能,也就是心跳定时器。但是这里我没有存储一个当时的时间戳,因为存储那个时间戳,因为存储原来的时间戳会占用资源存储成本会比较高,而且可能存储的时间戳很容易就和当前时间差很多,而且再与redis进行交互又会增加带宽消耗,所以不如直接不存了,不与redis通信了。一旦重启,就直接重启一个timer,就按最大的限度去计时,因为不论是心跳还是消息的重发,都不需要那么精准,最大的量两倍的rtt也是可以接受的
低成本:
- 同高性能epoll作用
- 我们这个服务本身的系统瓶颈主要在于负载,在于系统的内存,所以如何优化内存的消耗是一件非常重要的事情。所以为了进一步优化内存的消耗,我们的这个接入层部分,有为了确保长连接可靠性做心跳探活的一个心跳定时器,心跳定时器可能本身开销并不大,但是在大规模长连接负载状态下,就变得内存消耗极大。而且,也是同样的道理,我们有为了确保消息可靠性的一个定时器,在大大规模消息的情况下,消息的定时器也会变得消耗大量内存。因此为了优化这部分的内存消耗,我们引入了时间轮的概念,将定时任务存放到时间轮里,去优化定时器的消耗。
对于时间轮怎么用的:
就是将一个任务add到这个时间轮里。这个方法的目的是将一个计时器Timer对象插入到时间轮中。功能概述如下: - 方法首先读取当前时间轮的当前时间currentTime
- 接下来,方法检查要添加的计时器Timer的过期时间t.expiration是否已经过期。如果过期时间比当前时间加一个滴答时间(currentTime + tw.tick)还要早,意味着这个计时器已经到期,不能再添加进时间轮,方法返回false,时间刻度是1ms,大小大概有20个刻度。
- 如果计时器未过期,并且过期时间在当前时间加上整个时间轮跨度(currentTime + tw.interval)之内,它将被加入到其应处在的bucket中。每个bucket代表时间轮上的一个时间段,这里首先通过计算确定计时器应当放入哪一个bucket。
- 如果bucket的过期时间设置成功且是第一次设置(即bucket被重复利用),则将该bucket放入延迟队列tw.queue等待执行。如果设置的时间与当前bucket过期时间相同,则不会重复加入队列。
- 如果计时器的过期时间超出当前时间轮的跨度,那么它应该被加入到一个“溢出”时间轮中。如果当前还没有创建溢出的时间轮,代码会尝试去创建它(通过一个原子的“compare and swap”操作来确保只创建一次),然后再次尝试
lastMsg
websocket
TCP 协议本身是全双工的,但我们最常用的 HTTP/1.1,虽然是基于 TCP 的协议,但它是半双工的,对于大部分需要服务器主动推送数据到客户端的场景,都不太友好,因此我们需要使用支持全双工的 WebSocket 协议。
在 HTTP/1.1 里,只要客户端不问,服务端就不答。基于这样的特点,对于登录页面这样的简单场景,可以使用定时轮询或者长轮询的方式实现服务器推送(comet)的效果。
对于客户端和服务端之间需要频繁交互的复杂场景,比如网页游戏,都可以考虑使用 WebSocket 协议。
WebSocket 和 socket 几乎没有任何关系,只是叫法相似。
正因为各个浏览器都支持 HTTP协 议,所以 WebSocket 会先利用HTTP协议加上一些特殊的 header 头进行握手升级操作,升级成功后就跟 HTTP 没有任何关系了,之后就用 WebSocket 的数据格式进行收发数据。
一、WebSocket协议是什么
WebSocket是基于TCP的应用层协议,用于在C/S架构的应用中实现双向通信,它实现了浏览器与服务器全双工(full-duplex)通信,也就是允许服务器主动发送信息给客户端。
WebSocket 协议主要为了解决基于 HTTP/1.x 的 Web 应用无法实现服务端向客户端主动推送的问题, 为了兼容现有的设施, WebSocket 协议使用与 HTTP 协议相同的端口, 并使用 HTTP Upgrade 机制来进行 WebSocket 握手, 当握手完成之后, 通信双方便可以按照 WebSocket 协议的方式进行交互。
需要特别注意的是:虽然WebSocket协议在建立连接时会使用HTTP协议,但这并意味着WebSocket协议是基于HTTP协议实现的。
二、WebSocket与Http的区别
实际上,WebSocket协议与Http协议有着本质的区别:
1.通信方式不同
WebSocket是双向通信模式,客户端与服务器之间只有在握手阶段是使用HTTP协议的“请求-响应”模式交互,而一旦连接建立之后的通信则使用双向模式交互,不论是客户端还是服务端都可以随时将数据发送给对方;而HTTP协议则至始至终都采用“请求-响应”模式进行通信。也正因为如此,HTTP协议的通信效率没有WebSocket高。
。
stomp
WebSocket协议定义了两种类型的消息(文本和二进制),但其内容未作定义。该协议定义了一种机制,供客户端和服务器协商在WebSocket之上使用的子协议(即更高级别的消息传递协议),以定义各自可以发送何种消息、格式是什么、每个消息的内容等等。子协议的使用是可选的,但无论如何,客户端和服务器都需要就定义消息内容的一些协议达成一致。
一、概览
STOMP(Simple Text Oriented Messaging Protocol)最初是为脚本语言(如Ruby、Python和Perl)创建的,用于连接到企业 message broker。它被设计用来解决常用信息传递模式的一个最小子集。STOMP可以通过任何可靠的双向流媒体网络协议使用,如TCP和WebSocket。尽管STOMP是一个面向文本的协议,但消息的 payload 可以是文本或二进制。
STOMP是一个基于框架的协议,其框架是以HTTP为模型的。下面列出了STOMP框架的结构:
COMMAND
header1:value1
header2:value2
Body
客户端可以使用 SEND 或 SUBSCRIBE 命令来发送或订阅消息,以及描述消息内容和谁应该收到它的 destination header。这就实现了一个简单的发布-订阅机制,你可以用它来通过 broker 向其他连接的客户端发送消息,或者向服务器发送消息以请求执行某些工作。
当你使用Spring的STOMP支持时,Spring WebSocket 应用程序充当客户的STOMP broker。消息被路由到 @Controller 消息处理方法或简单的内存中 broker,该 broker 跟踪订阅并将消息广播给订阅用户。你也可以将Spring配置为与专门的STOMP broker(如RabbitMQ、ActiveMQ等)合作,进行消息的实际广播。在这种情况下,Spring维护与 broker 的TCP连接,向其转发消息,并将消息从它那里传递给连接的WebSocket客户端。因此,Spring web 应用可以依靠统一的基于HTTP的 security、通用验证和熟悉的编程模型来处理消息。
下面的例子显示了一个客户端订阅接收股票报价,服务器可能会定期发布这些报价(例如,通过一个预定任务,通过 SimpMessagingTemplate 向 broker 发送消息):
SUBSCRIBE
id:sub-1
destination:/topic/price.stock.*
下面的例子显示了一个客户端发送了一个交易请求,服务器可以通过 @MessageMapping 方法来处理:
SEND
destination:/queue/trade
content-type:application/json
content-length:44
{“action”:“BUY”,“ticker”:“MMM”,“shares”,44}
执行后,服务器可以向客户广播交易确认信息和细节。
在STOMP规范中,destination 的含义是故意不透明的。它可以是任何字符串,而且完全由STOMP服务器来定义它们所支持的 destination 的语义和语法。然而,destination 是非常常见的,它是类似路径的字符串,其中 /topic/… 意味着发布-订阅(一对多),/queue/ 意味着点对点(一对一)的消息交换。
STOMP服务器可以使用 MESSAGE 命令向所有订阅者广播信息。下面的例子显示了一个服务器向一个订阅的客户发送一个股票报价:
MESSAGE
message-id:nxahklf6-1
subscription:sub-1
destination:/topic/price.stock.MMM
{“ticker”:“MMM”,“price”:129.45}
一个服务器不能发送未经请求的消息。所有来自服务器的消息必须是对特定客户订阅的回应,而且服务器消息的 subscription header 必须与客户端 subscription 的 id header 相匹配。
前面的概述是为了提供对STOMP协议最基本的理解。我们建议阅读协议的全部 规范。
二、 好处
使用STOMP作为子协议可以让Spring框架和Spring Security提供更丰富的编程模型,而不是使用原始WebSockets。关于HTTP与原始TCP的对比,以及它如何让Spring MVC和其他Web框架提供丰富的功能,也可以提出同样的观点。以下是一个好处清单:
不需要发明一个自定义的消息传输协议和消息格式。
STOMP客户端,包括Spring框架中的一个 Java客户端,都是可用的。
你可以(选择性地)使用消息代理(如RabbitMQ、ActiveMQ和其他)来管理订阅和广播消息。
应用逻辑可以组织在任何数量的 @Controller 实例中,消息可以根据STOMP destination header 被路由到它们,而不是用一个给定连接的单一 WebSocketHandler 来处理原始WebSocket消息。
你可以使用 Spring Security 来保护基于 STOMP destination 和消息类型的消息。
1.1.红黑树的定义和性质
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
每个节点要么是黑色,要么是红色。
根节点是黑色。
每个叶子节点(NIL)是黑色。
每个红色结点的两个子结点一定都是黑色。
任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
1.2.红黑树的自平衡
红黑树能够实现自平衡,主要依靠以下三种操作:左旋、右旋、变色。
左旋: 以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。
右旋: 以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变。
左旋只影响旋转结点和其右子树的结构,把右子树的结点往左子树挪了。
右旋只影响旋转结点和其左子树的结构,把左子树的结点往右子树挪了。
变色: 结点的颜色由红变黑或由黑变红。
2.B树(多路平衡查找树)
B树是为磁盘等外存储设备设计的一种平衡查找树。系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
我们可以将磁盘中的数据记录表示为一个[key, val]形式的二元组,key为表中的主键值,data为主键对应的数据。对于不同的记录,key值互不相同。
在B树中,我们可以将每个磁盘块看成是B树的一个节点,在每个节点中,包含着升序排序的key主键,这些key主键中包含着对应data数据,并且将指向子节点的指针分割开来,在key左边的指针指向的key值比当前key值小,右边的指针指向的key值比当前大。
如下图所示,模拟查找key为29的数据:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
3.B+树
B+树是在B树的基础上做出的优化版本,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+树实现其索引结构。
在B树中每个节点中不仅包含数据的key值,还有data值。 而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B树深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
在B+树中:
- 非叶子节点只存储key键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据data记录都存放在叶子节点中。
通常在B+树上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+树进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
4.B树和B+树的总结
B树(B+树)都属于多路平衡查找树,在B树中,每个节点包含着多个key键值和data数据(按key值升序排列),key键值将指向子节点的指针分隔开,左边的指针指向比当前key值小的子节点,右边的指针指向比当前key值大的子节点。
B+树中将所有的data数据都放在了叶子节点,并且在叶子节点中形成了链式环结构。
演进
如果要让服务器服务多个客户端,那么最直接的方式就是为每一条连接创建线程。
其实创建进程也是可以的,原理是一样的,进程和线程的区别在于线程比较轻量级些,线程的创建和线程间切换的成本要小些,为了描述简述,后面都以线程为例。
处理完业务逻辑后,随着连接关闭后线程也同样要销毁了,但是这样不停地创建和销毁线程,不仅会带来性能开销,也会造成浪费资源,而且如果要连接几万条连接,创建几万个线程去应对也是不现实的。
要这么解决这个问题呢?我们可以使用「资源复用」的方式。
也就是不用再为每个连接创建线程,而是创建一个「线程池」,将连接分配给线程,然后一个线程可以处理多个连接的业务。
不过,这样又引来一个新的问题,线程怎样才能高效地处理多个连接的业务?
当一个连接对应一个线程时,线程一般采用「read -> 业务处理 -> send」的处理流程,如果当前连接没有数据可读,那么线程会阻塞在 read 操作上( socket 默认情况是阻塞 I/O),不过这种阻塞方式并不影响其他线程。
但是引入了线程池,那么一个线程要处理多个连接的业务,线程在处理某个连接的 read 操作时,如果遇到没有数据可读,就会发生阻塞,那么线程就没办法继续处理其他连接的业务。
要解决这一个问题,最简单的方式就是将 socket 改成非阻塞,然后线程不断地轮询调用 read 操作来判断是否有数据,这种方式虽然该能够解决阻塞的问题,但是解决的方式比较粗暴,因为轮询是要消耗 CPU 的,而且随着一个 线程处理的连接越多,轮询的效率就会越低。
上面的问题在于,线程并不知道当前连接是否有数据可读,从而需要每次通过 read 去试探。
那有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用。
I/O 多路复用技术会用一个系统调用函数来监听我们所有关心的连接,也就说可以在一个监控线程里面监控很多的连接。
我们熟悉的 select/poll/epoll 就是内核提供给用户态的多路复用系统调用,线程可以通过一个系统调用函数从内核中获取多个事件。
PS:如果想知道 select/poll/epoll 的区别,可以看看小林之前写的这篇文章:这次答应我,一举拿下 I/O 多路复用!(opens new window)
select/poll/epoll 是如何获取网络事件的呢?
在获取事件时,先把我们要关心的连接传给内核,再由内核检测:
如果没有事件发生,线程只需阻塞在这个系统调用,而无需像前面的线程池方案那样轮训调用 read 操作来判断是否有数据。
如果有事件发生,内核会返回产生了事件的连接,线程就会从阻塞状态返回,然后在用户态中再处理这些连接对应的业务即可。
当下开源软件能做到网络高性能的原因就是 I/O 多路复用吗?
是的,基本是基于 I/O 多路复用,用过 I/O 多路复用接口写网络程序的同学,肯定知道是面向过程的方式写代码的,这样的开发的效率不高。
于是,大佬们基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。
大佬们还为这种模式取了个让人第一时间难以理解的名字:Reactor 模式。
Reactor 翻译过来的意思是「反应堆」,可能大家会联想到物理学里的核反应堆,实际上并不是的这个意思。
这里的反应指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。
事实上,Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor 模式是灵活多变的,可以应对不同的业务场景,灵活在于:
Reactor 的数量可以只有一个,也可以有多个;
处理资源池可以是单个进程 / 线程,也可以是多个进程 /线程;
将上面的两个因素排列组设一下,理论上就可以有 4 种方案选择:
单 Reactor 单进程 / 线程;
单 Reactor 多进程 / 线程;
多 Reactor 单进程 / 线程;
多 Reactor 多进程 / 线程;
其中,「多 Reactor 单进程 / 线程」实现方案相比「单 Reactor 单进程 / 线程」方案,不仅复杂而且也没有性能优势,因此实际中并没有应用。
剩下的 3 个方案都是比较经典的,且都有应用在实际的项目中:
单 Reactor 单进程 / 线程;
单 Reactor 多线程 / 进程;
多 Reactor 多进程 / 线程;
方案具体使用进程还是线程,要看使用的编程语言以及平台有关:
Java 语言一般使用线程,比如 Netty;
C 语言使用进程和线程都可以,例如 Nginx 使用的是进程,Memcache 使用的是线程。
接下来,分别介绍这三个经典的 Reactor 方案。
#Reactor
#单 Reactor 单进程 / 线程
一般来说,C 语言实现的是「单 Reactor 单进程」的方案,因为 C 语编写完的程序,运行后就是一个独立的进程,不需要在进程中再创建线程。
而 Java 语言实现的是「单 Reactor 单线程」的方案,因为 Java 程序是跑在 Java 虚拟机这个进程上面的,虚拟机中有很多线程,我们写的 Java 程序只是其中的一个线程而已。
我们来看看「单 Reactor 单进程」的方案示意图:
可以看到进程里有 Reactor、Acceptor、Handler 这三个对象:
Reactor 对象的作用是监听和分发事件;
Acceptor 对象的作用是获取连接;
Handler 对象的作用是处理业务;
对象里的 select、accept、read、send 是系统调用函数,dispatch 和 「业务处理」是需要完成的操作,其中 dispatch 是分发事件操作。
接下来,介绍下「单 Reactor 单进程」这个方案:
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
单 Reactor 单进程的方案因为全部工作都在同一个进程内完成,所以实现起来比较简单,不需要考虑进程间通信,也不用担心多进程竞争。
但是,这种方案存在 2 个缺点:
第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
Redis 是由 C 语言实现的,在 Redis 6.0 版本之前采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
#单 Reactor 多线程 / 多进程
如果要克服「单 Reactor 单线程 / 进程」方案的缺点,那么就需要引入多线程 / 多进程,这样就产生了单 Reactor 多线程 / 多进程的方案。
闻其名不如看其图,先来看看「单 Reactor 多线程」方案的示意图如下:
详细说一下这个方案:
Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。
例如,子线程完成业务处理后,要把结果传递给主线程的 Handler 进行发送,这里涉及共享数据的竞争。
要避免多线程由于竞争共享资源而导致数据错乱的问题,就需要在操作共享资源前加上互斥锁,以保证任意时间里只有一个线程在操作共享资源,待该线程操作完释放互斥锁后,其他线程才有机会操作共享数据。
聊完单 Reactor 多线程的方案,接着来看看单 Reactor 多进程的方案。
事实上,单 Reactor 多进程相比单 Reactor 多线程实现起来很麻烦,主要因为要考虑子进程 <-> 父进程的双向通信,并且父进程还得知道子进程要将数据发送给哪个客户端。
而多线程间可以共享数据,虽然要额外考虑并发问题,但是这远比进程间通信的复杂度低得多,因此实际应用中也看不到单 Reactor 多进程的模式。
另外,「单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
多 Reactor 多进程 / 线程
要解决「单 Reactor」的问题,就是将「单 Reactor」实现成「多 Reactor」,这样就产生了第 多 Reactor 多进程 / 线程的方案。
老规矩,闻其名不如看其图。多 Reactor 多进程 / 线程方案的示意图如下(以线程为例):
方案详细说明如下:
主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
大名鼎鼎的两个开源软件 Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案。
采用了「多 Reactor 多进程」方案的开源软件是 Nginx,不过方案与标准的多 Reactor 多进程有些差异。
具体差异表现在主进程中仅仅用来初始化 socket,并没有创建 mainReactor 来 accept 连接,而是由子进程的 Reactor 来 accept 连接,通过锁来控制一次只有一个子进程进行 accept(防止出现惊群现象),子进程 accept 新连接后就放到自己的 Reactor 进行处理,不会再分配给其他子进程。
#Proactor
前面提到的 Reactor 是非阻塞同步网络模式,而 Proactor 是异步网络模式。
这里先给大家复习下阻塞、非阻塞、同步、异步 I/O 的概念。
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:
阻塞 I/O
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
非阻塞 I/O
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
举个例子,如果 socket 设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
因此,无论 read 和 send 是阻塞 I/O,还是非阻塞 I/O 都是同步调用。因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
异步 I/O
举个你去饭堂吃饭的例子,你好比应用程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
很明显,异步 I/O 比同步 I/O 性能更好,因为异步 I/O 在「内核数据准备好」和「数据从内核空间拷贝到用户空间」这两个过程都不用等待。
Proactor 正是采用了异步 I/O 技术,所以被称为异步网络模型。
现在我们再来理解 Reactor 和 Proactor 的区别,就比较清晰了。
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
举个实际生活中的例子,Reactor 模式就是快递员在楼下,给你打电话告诉你快递到你家小区了,你需要自己下楼来拿快递。而在 Proactor 模式下,快递员直接将快递送到你家门口,然后通知你。
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
接下来,一起看看 Proactor 模式的示意图:
介绍一下 Proactor 模式的工作流程:
Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 Asynchronous Operation Processor 注册到内核;
Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
Handler 完成业务处理;
可惜的是,在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 IOCP,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。
#总结
常见的 Reactor 实现方案有三种。
第一种方案单 Reactor 单进程 / 线程,不用考虑进程间通信以及数据同步的问题,因此实现起来比较简单,这种方案的缺陷在于无法充分利用多核 CPU,而且处理业务逻辑的时间不能太长,否则会延迟响应,所以不适用于计算机密集型的场景,适用于业务处理快速的场景,比如 Redis(6.0之前 ) 采用的是单 Reactor 单进程的方案。
第二种方案单 Reactor 多线程,通过多线程的方式解决了方案一的缺陷,但它离高并发还差一点距离,差在只有一个 Reactor 对象来承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
第三种方案多 Reactor 多进程 / 线程,通过多个 Reactor 来解决了方案二的缺陷,主 Reactor 只负责监听事件,响应事件的工作交给了从 Reactor,Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案,Nginx 则采用了类似于 「多 Reactor 多进程」的方案。
Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。
因此,真正的大杀器还是 Proactor,它是采用异步 I/O 实现的异步网络模型,感知的是已完成的读写事件,而不需要像 Reactor 感知到事件后,还需要调用 read 来从内核中获取数据。
不过,无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
JAVA中如何使用NIO机制的
在处理大量(如百万级)长连接时,操作系统的IO模型成为性能和可扩展性的关键因素。epoll是Linux系统上的一种高效IO事件通知机制,相比于传统的select和poll,它可以更好地扩展到大量并发连接。
Java通过NIO(New Input/Output)库提供了与epoll相似的机制,这部分通常被称为“高级IO”(Java NIO)。在Java NIO中,可以利用其非阻塞IO和选择器(Selector)机制来高效地管理成千上万的连接。下面是Java NIO使用epoll模型处理大量长连接的一些基本策略和步骤:
-
使用非阻塞IO:在Java NIO中,可以通过将SocketChannel设置为非阻塞模式来确保在操作该通道时不会阻塞。
-
创建Selector:Selector是Java NIO中的一个组件,它可以检查一个或多个NIO通道,并确定哪个通道准备好了读写数据。创建Selector对象将开始监听事件。
-
注册Channel到Selector:使用非阻塞通道(如ServerSocketChannel和SocketChannel)时,可以将这些通道注册到Selector并指定不同的事件(如接收、读取、写入或连接),Selector会监视这些事件的发生。
-
使用selector轮询就绪事件:通常使用一个主循环来调用Selector的select()方法来检测就绪的事件,select()方法会阻塞直到至少有一个注册的事件发生。
-
处理就绪事件:当select()方法返回后,会得到一组SelectionKeys,每个都代表一个已就绪的事件。就绪事件可以是新的连接请求,也可以是数据到达等事件。程序需要迭代这些SelectionKeys,并根据每个键的事件类型进行相应的处理,例如新的连接建立、数据的读取或写入。
-
优化资源管理:为了高效地处理如此众多的连接,可以使用线程池来处理数据的读写操作,以及连接的建立和断开。这样能够使主循环快速返回,持续监听新的事件,而具体的业务逻辑处理则交由线程池中的线程异步处理。
由于epoll本身支持“one-shot”模型,意味着它不会不断地告诉应用程序某个文件描述符就绪,除非应用程序重新充它。Java内部封装了这样的细节,确保在大规模连接场景下效率和性能。
要注意的是,尽管Java NIO可以通过Selector提供类似epoll的轮询机制,但是它是基于Java NIO的抽象,具体是否使用epoll则取决于JVM和底层操作系统。在Linux系统上运行的Java程序通常会利用epoll模型,如果在其他系统上(如Windows)则可能使用其他模型(比如IOCP)。需要查阅特定JVM实现的文档以了解其对epoll的具体使用情况。
javanio是异步io
Java中的NIO(New Input/Output)不是传统意义上的异步IO,它主要提供了非阻塞的IO操作。虽然NIO允许使用单一线程来管理多个IO通道,这看起来有点像异步IO,但是NIO依然属于同步非阻塞IO。
同步IO和异步IO的主要区别在于系统处理IO请求的方式。在同步IO模型中,应用程序发出IO请求后,必须等待IO操作完成然后才能继续执行其他任务。而异步IO模型中,应用程序发出IO请求后,可以立即执行其他任务,当IO请求完成时,系统会通知应用程序或回调指定的处理函数。
在Java NIO中,当你注册一个Channel到Selector,并对某些事件(如读取、写入)感兴趣时,你的线程可以继续做其它事情,并且会在事件准备就绪时得到通知,然后线程可以处理这些事件。这个过程需要线程主动去检查IO事件(通过调用select()方法),因此被称为同步非阻塞。
Java中真正的异步IO是由NIO.2中的异步通道(AsynchronousSocketChannel, AsynchronousServerSocketChannel 等)提供,它们在Java 7中引入作为一部分的Java NIO的扩展,称为 AIO(Asynchronous Input/Output)。AIO提供了真正的异步IO操作,当IO操作完成时,它可以自动地通知应用程序,或者调用一个事先指定的回调处理函数,无需线程持续检查或等待IO事件的发生。这样,应用程序可以在没有任何线程阻塞的情况下继续处理其他任务。
如何使用Java的nio处理百万长连接
处理百万级别的长连接,Java的NIO库提供了必需的机制。关键是非阻塞模式、选择器(Selectors)和可扩展的IO,这些特性使得单个线程能够高效处理大量的连接。为了使用Java NIO处理百万长连接,您可以按照以下的指导原则进行:
-
非阻塞模式:为了使用NIO,首先需要将SocketChannel设置为非阻塞模式。这允许您在不被IO操作锁住的情况下,检查多个通道(Channel)的IO状态。
-
使用Selector:Selector允许一个单独的线程来监控多个输入通道,可以检测一个或多个通道是否有事件就绪。例如,是否有新的连接请求可接受、是否可以读取或写入数据等。
-
注册通道到Selector:创建ServerSocketChannel,并与本地端口绑定后,将它注册到Selector。同样,对于客户端连接产生的SocketChannel,也应将其注册到Selector,并订阅感兴趣的事件,如读、写操作。
-
选择键集合:调用Selector的select()方法,它会阻塞到至少有一个注册的事件发生。当一个或多个通道准备好进行IO操作时,select()方法将返回准备就绪的通道的数量。通过selectedKeys()方法获取这些通道对应的SelectionKey集合。
-
处理就绪事件:接着对于每个就绪的SelectionKey,确定具体是哪种类型的事件准备就绪,然后进行相应的操作。如果是可接受的事件,可以接受客户端的连接。如果是可读或可写事件,可以进行数据传输。
-
线程池:由于主循环会处理所有IO事件,若在主循环中直接处理业务逻辑,会导致主循环无法及时地返回监听更多的IO事件。因此,应当使用线程池来处理业务逻辑。将数据读取、业务逻辑处理、数据写入等任务提交到线程池中,这样可以避免在事件处理过程中发生阻塞。
-
内存管理:管理这么多的连接同时也要考虑到内存的分配和压力。使用直接缓冲区(direct buffers)来减少在JVM堆和操作系统之间复制数据的开销。务必根据应用程序的需求合理分配和回收直接缓冲区。
-
心跳和超时处理:维护长连接意味着必须处理心跳保活(keep-alive)和连接超时机制,以识别和断开失效的连接。
-
调优:为了处理海量连接,需要对JVM和应用程序进行调优,例如优化堆大小、垃圾收集策略等。
这种模式的编程复杂性较高,但是对于高并发场景,这是一个可行的高性能方案。记住,所涉及的各个方面,包括网络带宽、硬件资源、操作系统的配置等都可能成为处理如此众多连接的瓶颈。所以还需要考虑到这些外部因素。
Javanio的核心组件,详细介绍,怎么使用
Java NIO的核心组件主要包括通道(Channels)、缓冲区(Buffers)、选择器(Selectors)和字节集(Charsets)。下面我会详细介绍这些组件以及如何使用它们:
1. 通道(Channels)
通道是Java NIO中的一个基本概念,它是对传统流的抽象,并可以提供一个连接到I/O源如文件、套接字等的通道。它主要分为两大类:选择器支持的(SelectionKey支持的操作类型)和不支持的。常用的通道有:
- FileChannel:用于文件的数据读写。
- DatagramChannel:通过UDP读写网络中的数据。
- SocketChannel:用于TCP网络数据的读写。
- ServerSocketChannel:可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel。
使用示例:
// 打开一个通道
FileChannel fileChannel = new FileInputStream("data.txt").getChannel();
// 使用文件通道读写数据
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = fileChannel.read(buffer);
// 关闭通道
fileChannel.close();
2. 缓冲区(Buffers)
缓冲区是一个容器对象,NIO系统通过Buffer对象处理数据。每一种基本的Java数据类型都有对应的Buffer类,如ByteBuffer、CharBuffer、IntBuffer等等。
使用示例:
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(48);
// 写入数据到Buffer
int bytesWritten = channel.write(buffer);
// 读取数据从Buffer
int bytesRead = channel.read(buffer);
// buffer.flip()方法,将Buffer从写模式切换到读模式
buffer.flip();
// get()方法从Buffer中读取数据
byte aByte = buffer.get();
3. 选择器(Selectors)
选择器是Java NIO中的多路复用器,它可以检测一个或多个NIO通道,并能知道哪个通道可以进行数据的读写。这样一个单独的线程可以管理多个channel,适用于建立连接数目较多但负载较低的场合。
使用示例:
// 创建一个Selector
Selector selector = Selector.open();
channel.configureBlocking(false);
// 将通道注册到选择器上
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
// select方法返回值表示有多少通道已经就绪
while(selector.select() > 0) {
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey aKey = keyIterator.next();
if(aKey.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (aKey.isConnectable()) {
// a connection was established with a remote server.
} else if (aKey.isReadable()) {
// a channel is ready for reading
} else if (aKey.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
}
4. 字符集(Charsets)
Charsets用来编码和解码字符数据,它定义了字符如何在字节和字符之间转换。
使用示例:
// 编码和解码使用的Charset
Charset utf8 = Charset.forName("UTF-8");
// 编码成ByteBuffer
ByteBuffer byteBuffer = utf8.encode(CharBuffer.wrap("Hello World"));
// 解码返回CharBuffer
CharBuffer charBuffer = utf8.decode(byteBuffer);
以上是Java NIO核心组件的介绍和基本用法。Java NIO的API相对Java IO更复杂,但它提供了更高的控制和可伸缩性,尤其是需要处理数千个连接的高并发应用程序时。学习如何正确使用这些API对于编写高效的网络和文件I/O代码是非常重要的。
一个channel对应多少个socket
在Java NIO中,Channel与Socket之间的关系取决于具体类型的通道。以下是一些常见类型的通道以及它们与Socket之间的对应关系:
-
SocketChannel - 每个
SocketChannel对应一个Socket。SocketChannel是连接到TCP网络套接字的通道,可以进行读写操作。每当你创建一个新的SocketChannel,实际上底层会创建一个新的Socket。 -
ServerSocketChannel -
ServerSocketChannel本身对应一个ServerSocket。ServerSocketChannel用于监听新进来的TCP连接,每当accept()方法返回时,它会创建一个包含具体新连接的SocketChannel,该SocketChannel对应一个单独的Socket。 -
DatagramChannel - 一个
DatagramChannel对应一个DatagramSocket,用于UDP通信,其中数据通过数据报(datagrams)方式发送和接收。
因此,有关一个Channel对应多少个Socket的问题,答案是:SocketChannel和DatagramChannel均一对一对应,即一个Channel对应一个Socket;而ServerSocketChannel用于接收新的连接,与之对应的ServerSocket可以创建多个SocketChannel,每个SocketChannel对应一个客户端的Socket连接。
在NIO中,使用多路复用技术,一个线程可以管理多个通道(channels),但每个通道代表一个连接或者一个绑定的套接字,所以从多路复用的角度看,一个通道确实是与一个套接字绑定的。
JAVA中时间轮怎么使用
在 Java 中,时间轮算法通常用于实现高效的定时调度器,尤其是处理大量的定时任务时。时间轮算法通过将时间分割成多个“槽”(slot)来组织定时任务,每个槽代表一定的时间区间。任务被放入相应的槽中,当时间轮转动到某个槽时,该槽中的所有任务都会被执行。
Java中没有内置的时间轮算法实现,但是可以通过第三方库如Netty的HashedWheelTimer来使用,或者根据时间轮算法原理自己实现。以下是利用Netty的HashedWheelTimer的一个简单示例和自定义时间轮算法的概念介绍。
使用Netty的HashedWheelTimer
添加Netty依赖到你的项目中如果你使用的是Maven:
<dependencies>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>你的Netty版本号</version>
</dependency>
</dependencies>
然后你可以这样使用HashedWheelTimer:
import io.netty.util.HashedWheelTimer;
import io.netty.util.Timeout;
import io.netty.util.TimerTask;
import java.util.concurrent.TimeUnit;
public class HashedWheelTimerExample {
public static void main(String[] args) {
HashedWheelTimer timer = new HashedWheelTimer(100, TimeUnit.MILLISECONDS, 512);
TimerTask task = new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
System.out.println("任务执行:" + System.currentTimeMillis());
}
};
// 延迟3秒执行任务
timer.newTimeout(task, 3, TimeUnit.SECONDS);
// ...
// 程序处在某个长时间的执行状态
// ...
timer.stop(); // 当不再需要时停止定时器
}
}
在这个例子中,HashedWheelTimer使用100ms作为tick的间隔,并且有512个槽,意味着每个槽代表100ms,总共可以表示的时间为51.2秒。你可以创建TimerTask实例,然后通过调用newTimeout方法来安排任务。
手动实现一个简单的时间轮算法
如果你打算自己实现一个基础版本的时间轮算法,请考虑以下关键的组成部分:
- 轮槽(wheel slots):构成时间轮的槽数组,每个槽可持有和管理一份任务列表。
- 指针(ticker):指示当前时间槽的位置。
- 时间间隔(tick duration):每个槽所代表的时间长度。
- 定时器线程(timer thread):驱动整个时间轮运行,按给定的时间间隔推进指针,并执行到时的任务。
以下是手动实现的一个非常简化的时间轮算法的例子:
import java.util.List;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class SimpleTimingWheel {
private final int wheelSize;
private final long tickDuration;
private final TimeUnit timeUnit;
private final List<Map<Long, Runnable>> wheel;
private final ScheduledExecutorService executor;
private long currentTime;
public SimpleTimingWheel(long tickDuration, TimeUnit timeUnit, int wheelSize) {
this.tickDuration = tickDuration;
this.timeUnit = timeUnit;
this.wheelSize = wheelSize;
this.wheel = new ArrayList<>(wheelSize);
for (int i = 0; i < wheelSize; i++) {
wheel.add(new HashMap<>());
}
currentTime = System.currentTimeMillis();
executor = Executors.newSingleThreadScheduledExecutor();
}
public void start() {
executor.scheduleAtFixedRate(this::tick, tickDuration, tickDuration, timeUnit);
}
public synchronized void addTask(Runnable task, long delay) {
long executionTime = System.currentTimeMillis() + timeUnit.toMillis(delay);
if (delay < tickDuration) {
executor.submit(task);
} else {
long index = (executionTime / tickDuration) % wheelSize;
wheel.get((int) index).put(executionTime, task);
}
}
private synchronized void tick() {
currentTime += tickDuration;
int index = (int) ((currentTime / tickDuration) % wheelSize);
Map<Long, Runnable> tasks = wheel.get(index);
for (Map.Entry<Long, Runnable> taskEntry : tasks.entrySet()) {
if (taskEntry.getKey() <= currentTime) {
executor.submit(taskEntry.getValue());
tasks.remove(taskEntry.getKey());
}
}
}
public void stop() {
executor.shutdown();
}
}
请记得,这个简化版的时间轮算法实现没有处理很多实际情况,比如时间槽轮转、任务重试、任务取消等等。在实际开发中,如果业务场景复杂,推荐使用现成的成熟库以保证性能和可靠性。
绑定定时器到时间轮上通常涉及到计算任务预定执行的时间,然后将任务安排到时间轮上合适的槽位中。一个槽位代表时间轮上的一个时间段,任务会被放置到其应当执行时间所映射的槽位中。下面的步骤通常是创建一个基于时间轮算法的定时器的过程:
-
初始化时间轮:首先初始化时间轮,确定轮槽的数量和每一个轮槽代表的时间间隔。
-
创建任务:为需要执行的操作创建一个任务,该任务可以是实现了某个接口(如
Runnable或TimerTask)的类的实例。 -
计算槽位索引:根据任务的预定执行时间计算出它应该放置在哪个槽位上。通常通过以下方式计算:
预定执行时间 = 当前时间 + 延迟时间 索引 = (预定执行时间 / 时间间隔) % 轮槽数 -
安排任务到槽位:将任务添加到计算出的索引对应的槽位上,通常在槽位中保持一个任务列表来管理同一槽位的所有任务。
-
处理时间轮转动:实现一个定时器线程,定时轮询每个槽位。当时间指针到达某个槽位时,执行该槽位中所有的任务,并处理完成的任务。
以下是一个示例性质的简单代码片段,展示如何将任务绑定到时间轮的槽位上:
// 假设我们有以下时间轮结构:
public class TimeWheel {
private List<List<Runnable>> slots;
private int currentSlot = 0;
private int wheelSize;
private long tickDuration;
private TimeUnit timeUnit;
public TimeWheel(int wheelSize, long tickDuration, TimeUnit timeUnit) {
this.wheelSize = wheelSize;
this.tickDuration = tickDuration;
this.timeUnit = timeUnit;
this.slots = new ArrayList<>(wheelSize);
for (int i = 0; i < wheelSize; i++) {
slots.add(new LinkedList<>());
}
// 代码省略:启动定时任务以驱动时间轮运转
}
// 添加定时任务到时间轮
public void addTask(Runnable task, long delay) {
long delayTicks = timeUnit.toMillis(delay) / tickDuration;
int slotIndex = (int)((currentSlot + delayTicks) % wheelSize);
List<Runnable> slot = slots.get(slotIndex);
synchronized (slot) {
slot.add(task);
}
}
// 时间轮推进一个槽位,并执行任务
private void advanceWheel() {
currentSlot = (currentSlot + 1) % wheelSize;
List<Runnable> currentTasks = slots.get(currentSlot);
// 代码省略:执行currentTasks中的所有任务
}
// ... 其他方法
}
在实现自定义定时器时,请确保妥善处理多线程同步,避免潜在的并发问题。上述代码仅作为理解如何将任务绑定到时间轮的基础概念,实际应用中应使用更完善的实现,如Netty中的HashedWheelTimer。















 5817
5817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









