






 使用Python编程抓取巨潮资讯网上2023年1月4日至7月4日间,标题含2023年日常性关联交易的新三板公告。数据存储为Excel表格,然后生成PDF文件,过程中处理反爬策略,但部分下载失败,需增加下载间隔防止被封锁。
使用Python编程抓取巨潮资讯网上2023年1月4日至7月4日间,标题含2023年日常性关联交易的新三板公告。数据存储为Excel表格,然后生成PDF文件,过程中处理反爬策略,但部分下载失败,需增加下载间隔防止被封锁。
巨潮资讯网是股票公告的指定披露渠道之一,上面有非常详细的A股股票公告内容。
现在,我们要获取2023-01-04~2023-07-04期间所有新三板公司中标题包含“2023年日常性关联交易”的公告。
首先从network中获取到真实网址:http://www.cninfo.com.cn/new/hisAnnouncement/query
然后在查询里面输入时间和关键词,点击查询
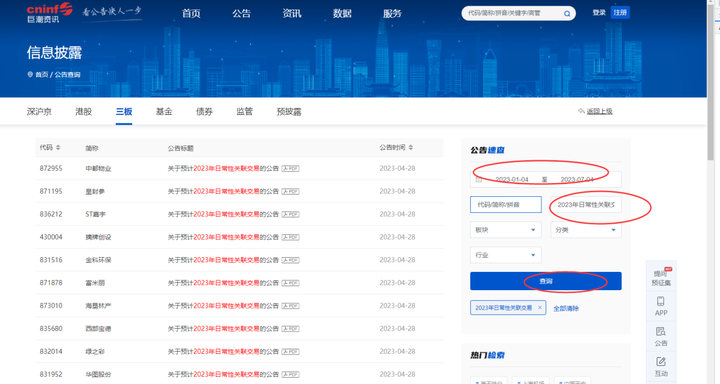
然后可以看到返回的是json数据:
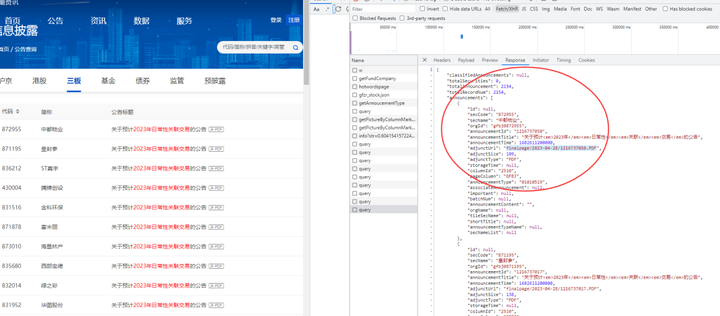
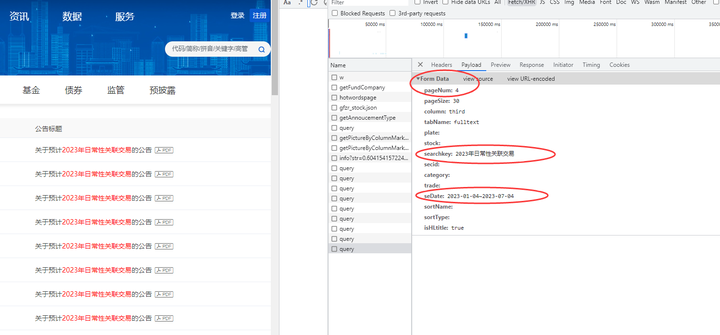
通过formdata传递参数:
所以可以在ChatGPT中这样输入提示词:
你是一个Python编程专家,要完成一个爬取网页数据的任务。具体步骤如下:
打开网页http://www.cninfo.com.cn/new/hisAnnouncement/query,
该动态网页的Request headers
Accept:
*/*
Accept-Encoding:
gzip, deflate
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Connection:
keep-alive
Content-Length:
240
Content-Type:
application/x-www-form-urlencoded; charset=UTF-8
Host:
Origin:
Referer:
http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&lastPage=index
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36
X-Requested-With:
XMLHttpRequest
该动态网页的Formdata
pageNum: 1
pageSize: 30
column: third
tabName: fulltext
plate:
stock:
searchkey: 2023年日常性关联交易
secid:
category:
trade:
seDate: 2023-01-04~2023-07-04
sortName:
sortType:
isHLtitle: true
其中,pageNum参数的值是从1到72;
获取每页的json数据;
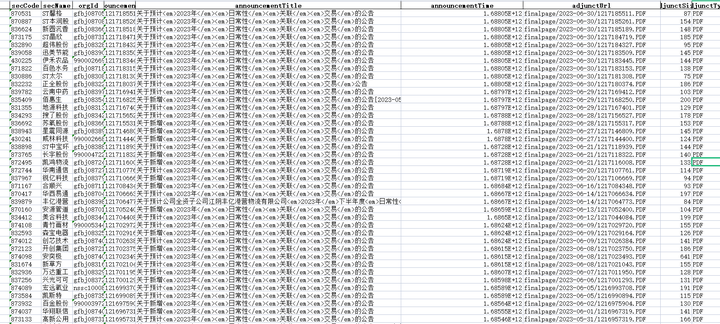
然后提取json数据中的 "announcements"数据,保存到F盘的excel表格“新三板 2023年日常性关联交易20230704.xlsx”;
读取F盘的excel表格“新三板 2023年日常性关联交易20230704.xlsx”,提取单元格secCode{no}、secName{no}、announcementTitle{no}的内容,连接在一起,作为PDF文件的标题;
提取单元格adjunctUrl{no}的内容,作为PDF文件的URL,前面加上http://static.cninfo.com.cn/,构成PDF文件的完整下载URL;
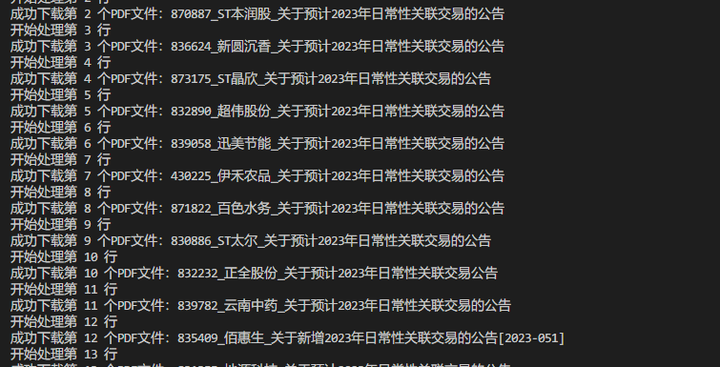
下载这个PDF文件,保存到F盘的文件夹:”新三板 2023年日常性关联交易20230704”
其中,no参数的值是从2到2125;
注意:
每一个步骤都要输出信息;
每爬取一页,暂停10秒;
每1个PDF文件下载完后,暂停5秒;
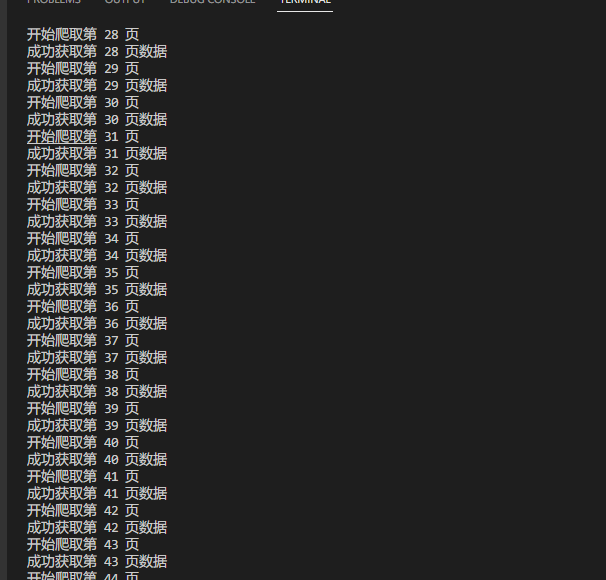
数据爬取正常,全部公告信息成功保存到表格:
全部公告成功下载到本地:

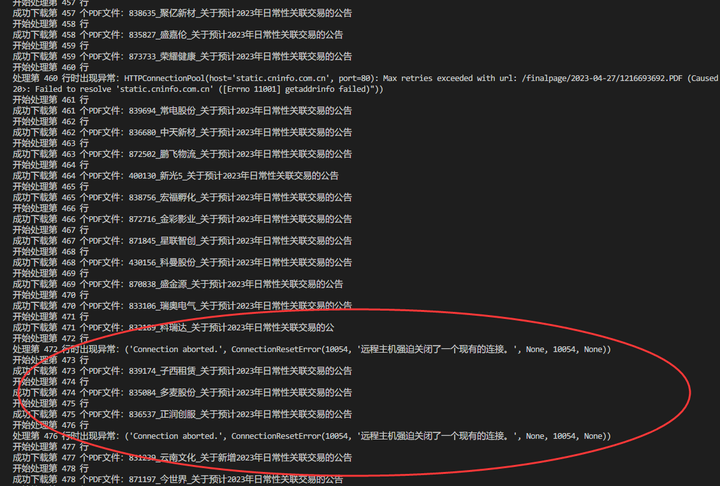
但是,也有一些没有成功下载,应该是频繁连接导致触发网站的反爬虫机制。所以,每下载一个公告后应该等待时间设置长一些,比如10秒或者15秒。

















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









