






如何批量下载上市公司财报和基础信息, 很多时候我们需要去公告中,提取自己想要的信息到excel中,那么如何做呢?
上市公司模块功能
- 1、上市公司信息批量下载
新开发的上市公司信息批量下载功能,可以一键导出基础数据、公司介绍、财务审计意见等信息到excel中,大大的简化了数据的整理,非常方便。
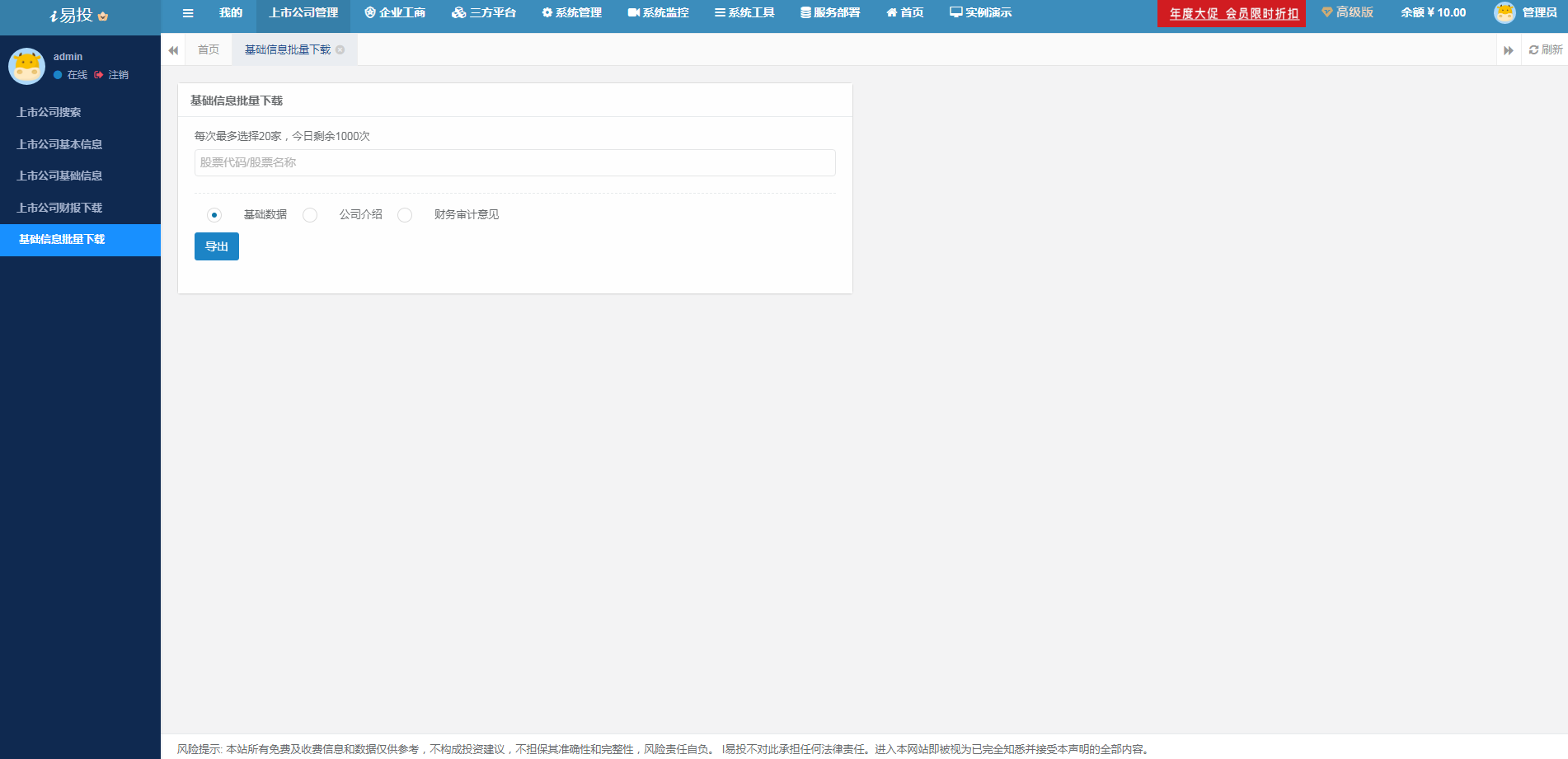
- 2、上市公司财报下载
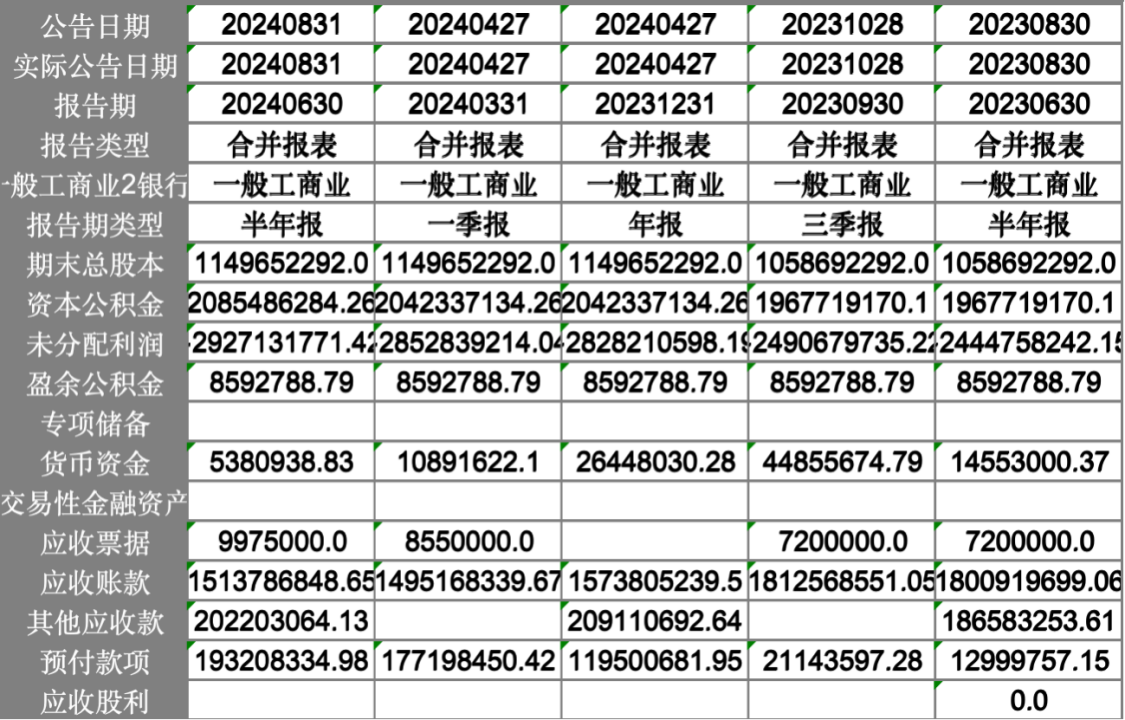
新开发的上市公司财报下载模块功能,数据更加全面,一键导出到excel中,涵盖了上市公司合并报表的历史财报数据,财报分为:利润表、资产负债表、现金流量表。大家可以直接一键导出到excel中,接着可以用excel中的行列置换来得到更加清晰的数据格式,非常方便。
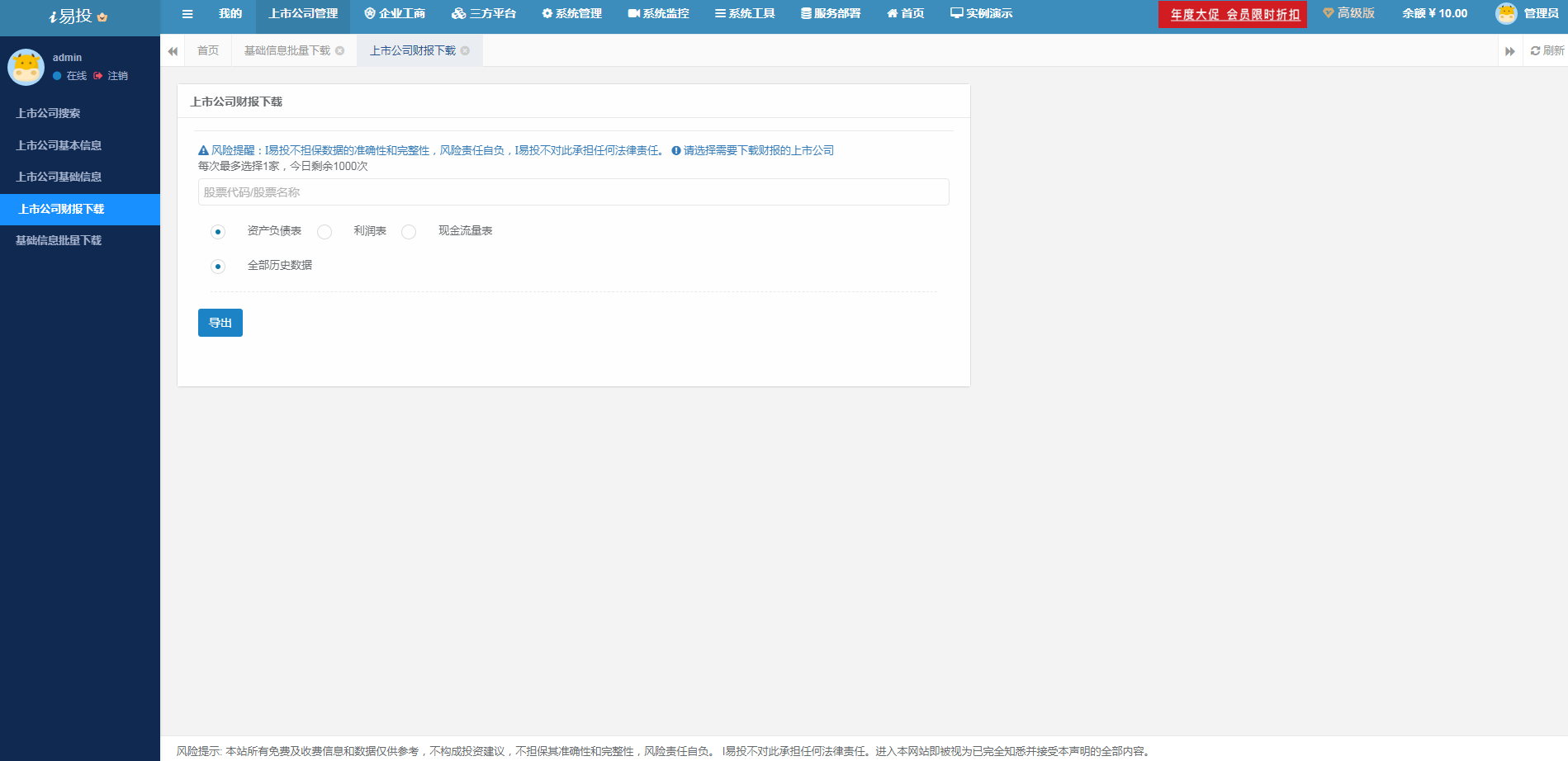
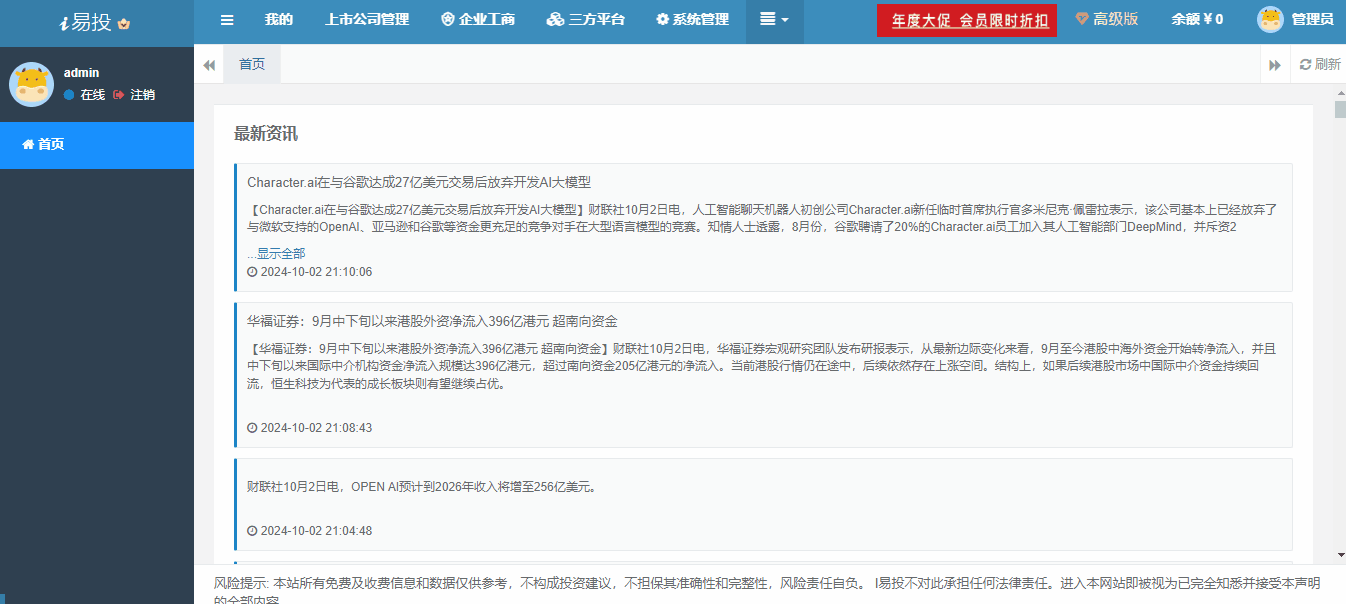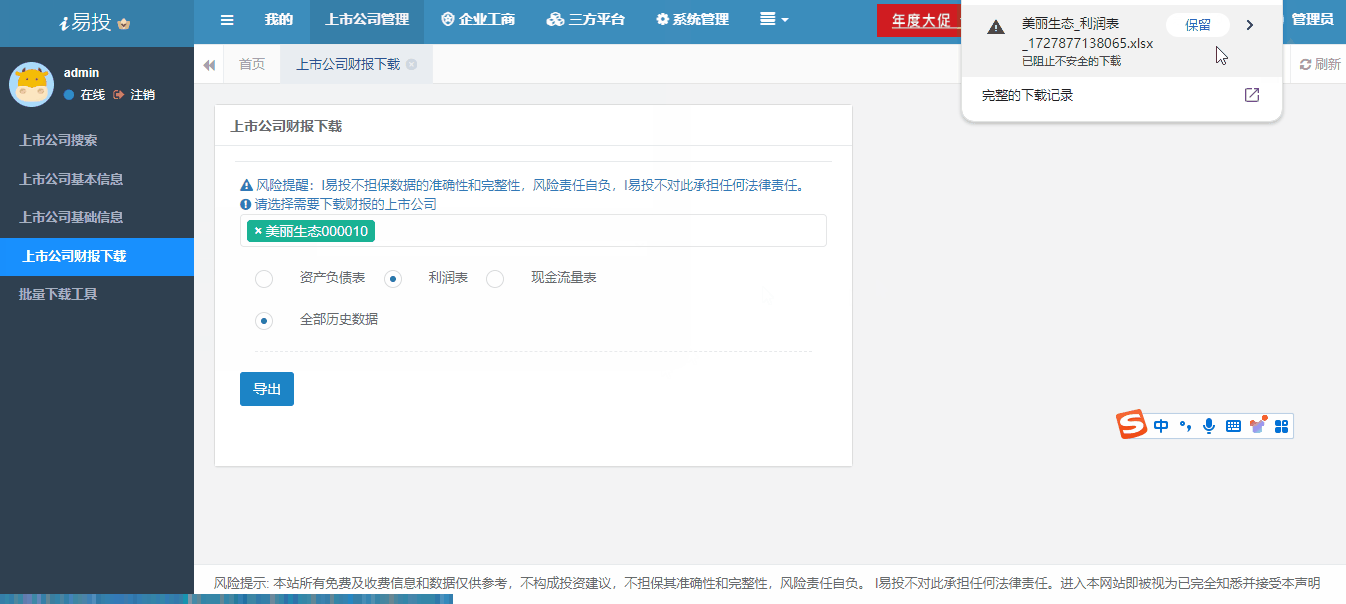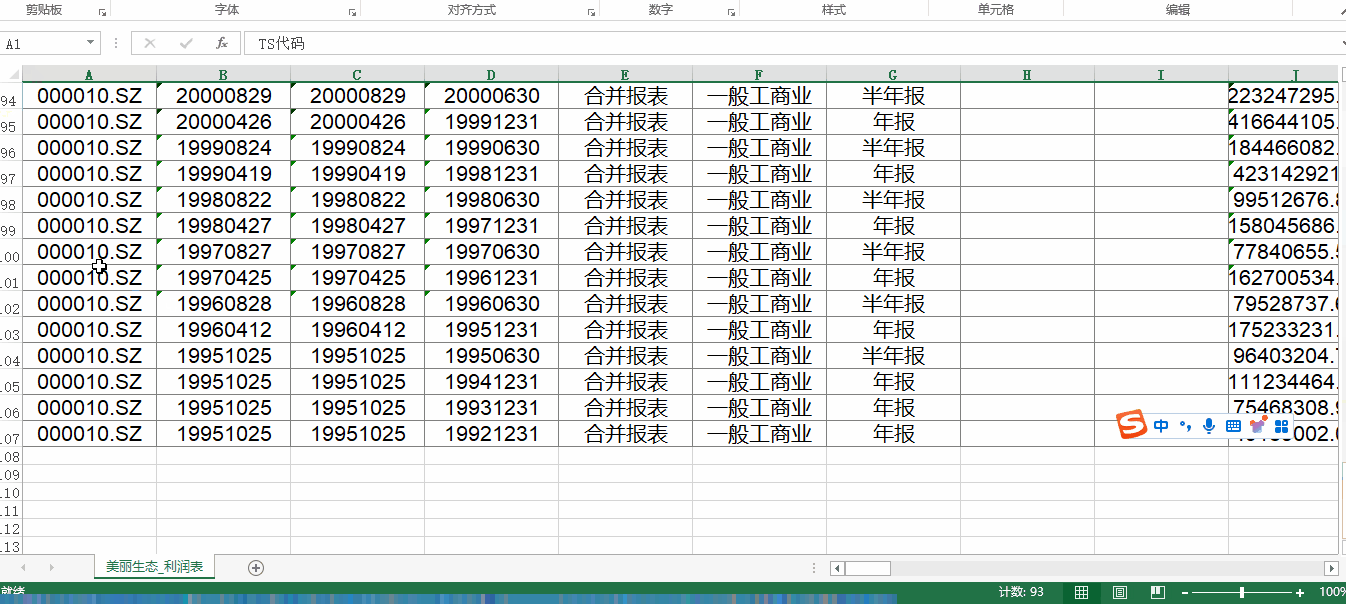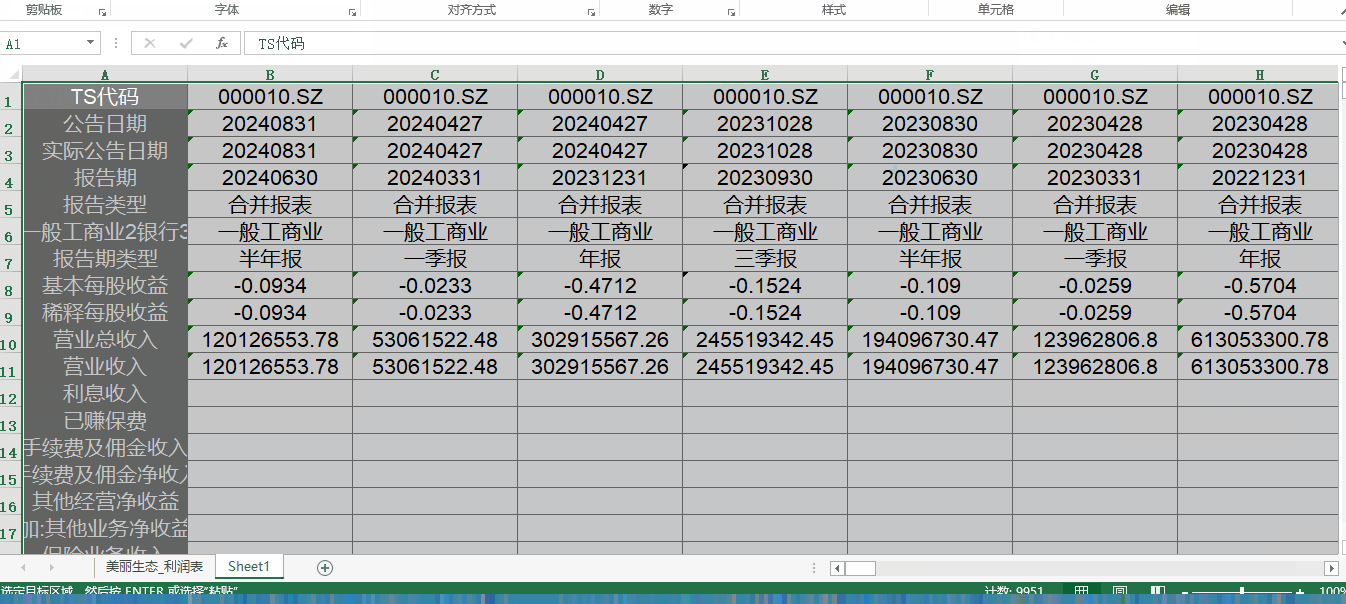
部分结果展示:
利润表:
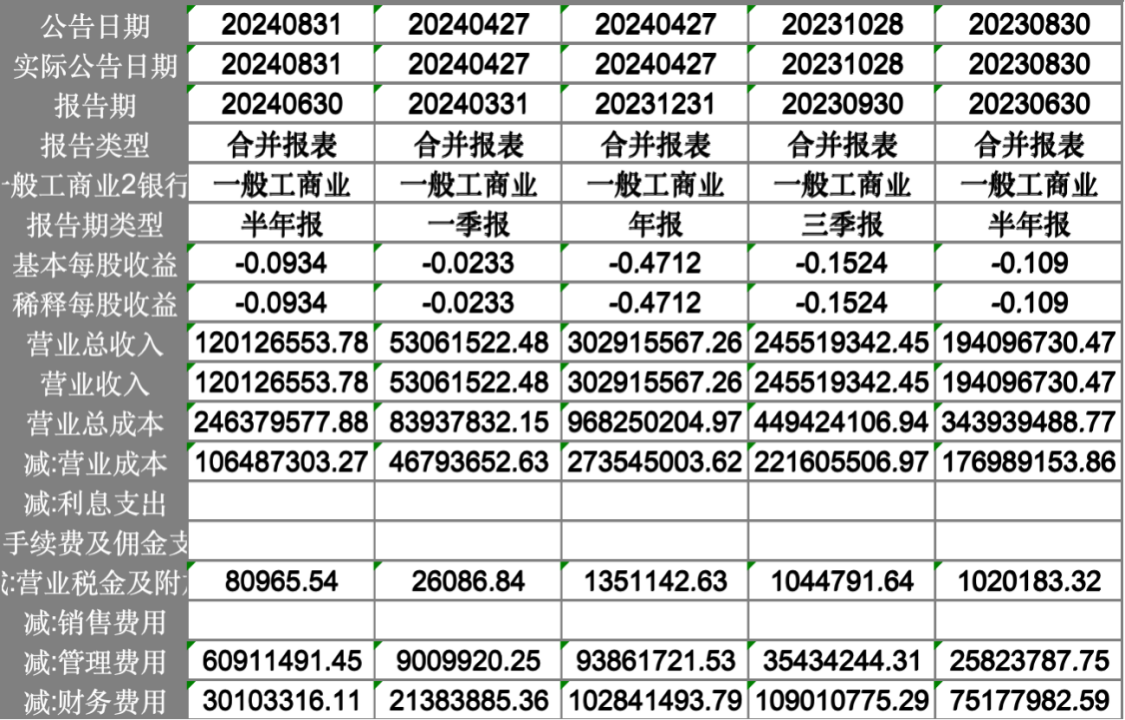
现金流量表:
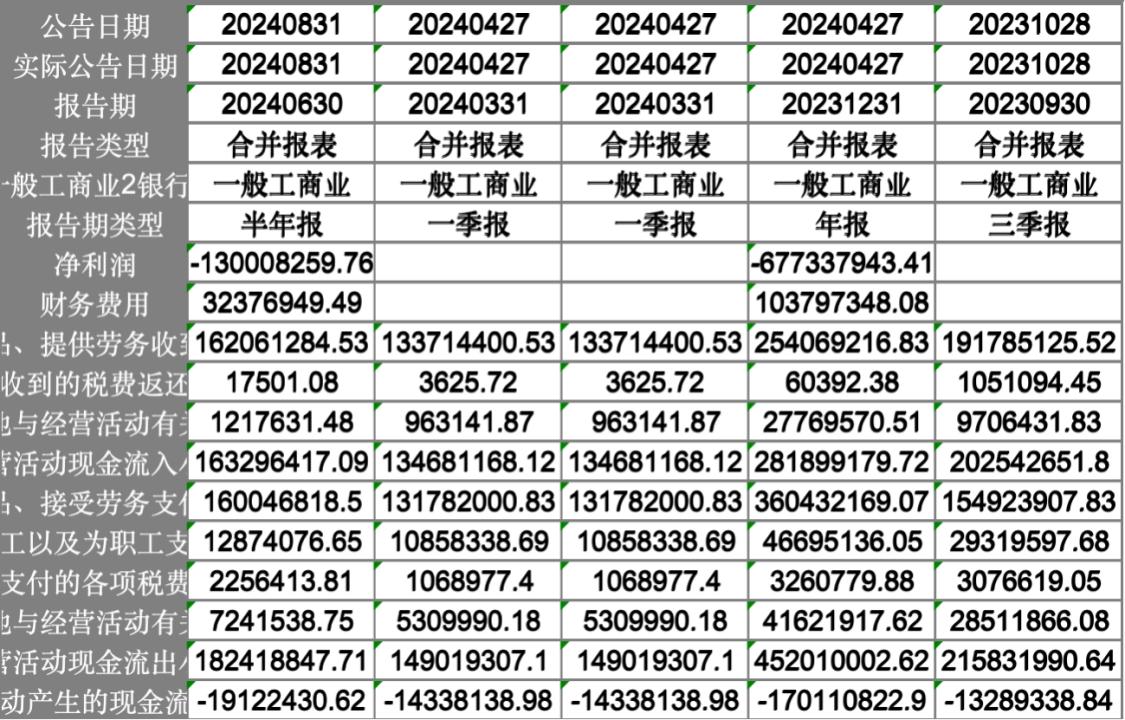
资产负债表:
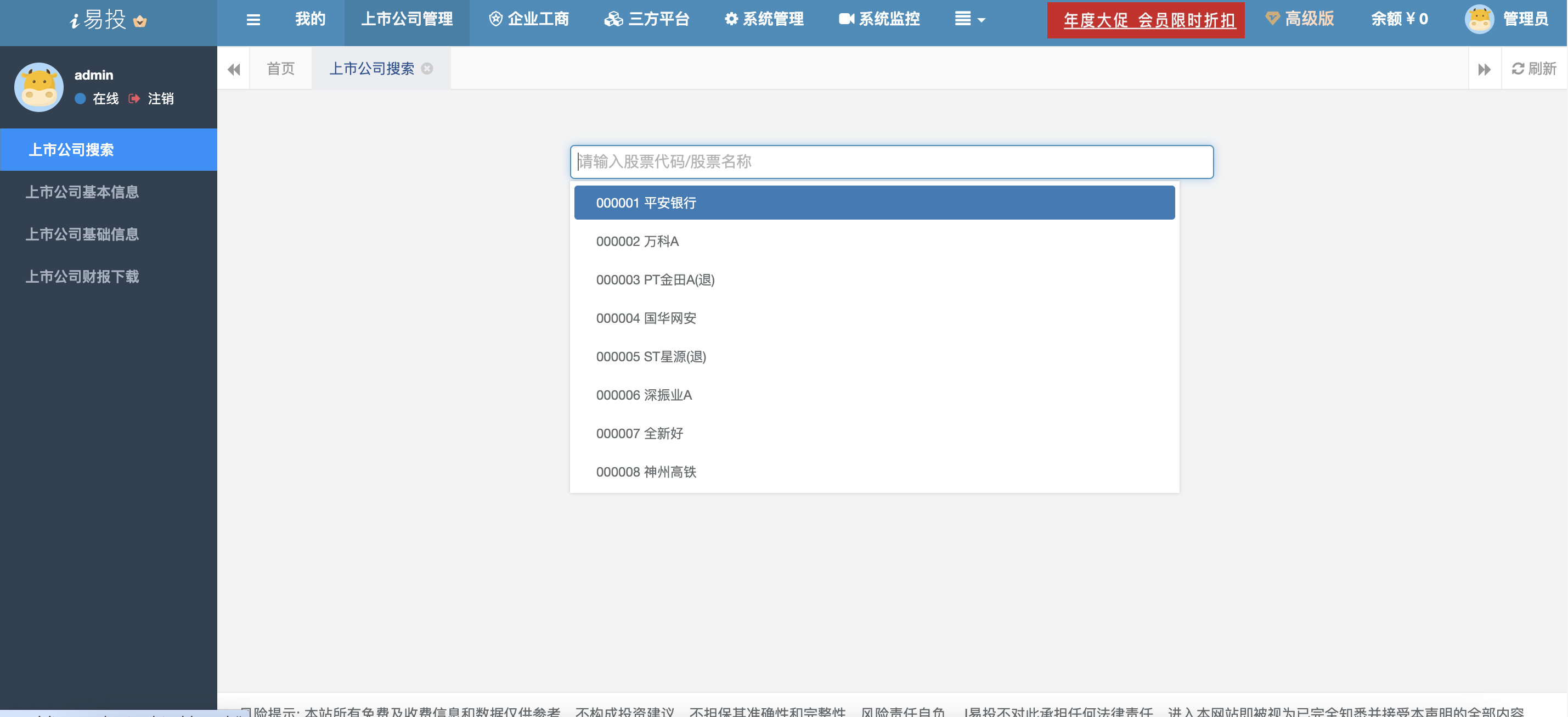
- 3、上市公司搜索
可以直接在搜索框中进行搜索,支持股票代码或者股票名称的输入,点击搜索结果完成查询。
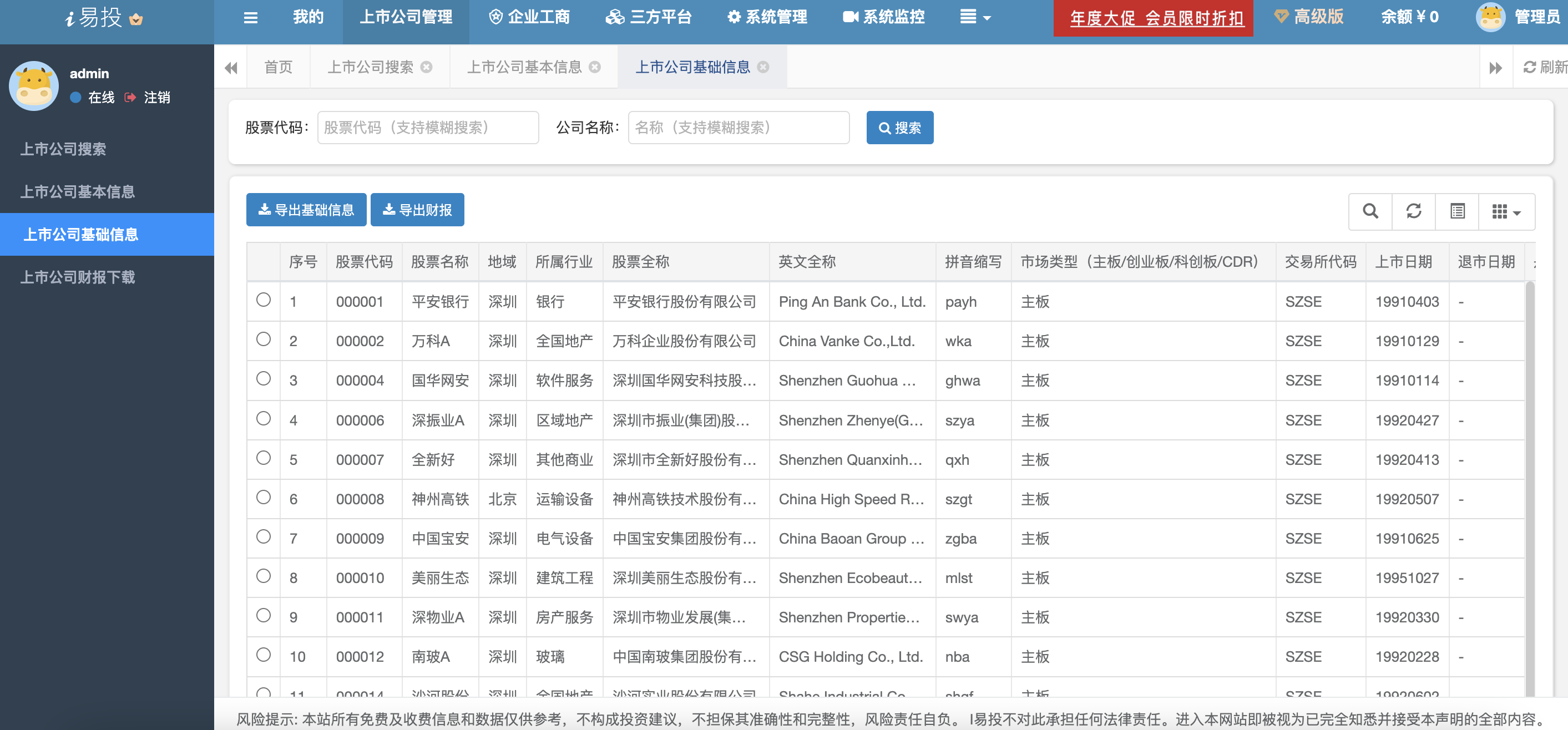
- 4、上市公司基础信息查询
获取基础信息数据,包括股票代码、名称、上市日期、退市日期等。支持导出。
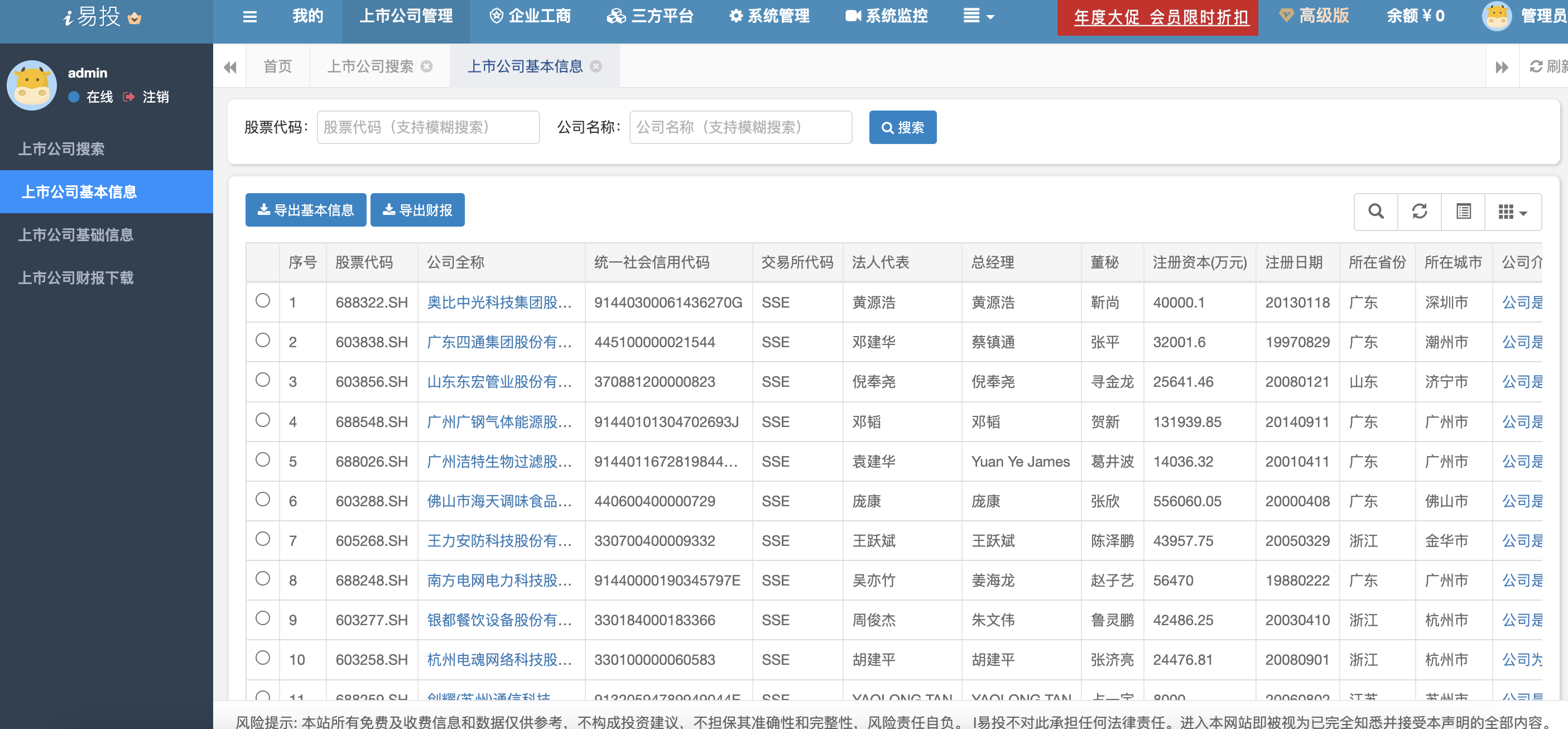
- 5、上市公司基本信息查询
上市公司的基本信息包括统一社会信用代码、法人代表、总经理、所在城市、公司介绍、经营范围等。支持导出。
i易投平台iyitou.com

















 6154
6154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









