








论文链接: https://arxiv.org/pdf/2405.18750
项目链接:https://t2v-turbo.github.io/
基于扩散的文本到视频(T2V)模型取得了显著的成功,但仍然受到迭代采样过程速度缓慢的影响。为了解决这一挑战,一些一致性模型被提出来促进快速推理,尽管以牺牲样本质量为代价。在这项工作中,旨在突破视频一致性模型(VCM)的质量瓶颈,实现快速且高质量的视频生成。本文引入了T2V-Turbo,将来自不同可微分奖励模型混合的反馈集成到预训练T2V模型的一致性蒸馏(CD)过程中。值得注意的是,本文直接优化与单步生成相关的奖励,这些奖励自然产生于计算CD损失,有效地绕过了通过迭代采样过程反向传播梯度所施加的内存限制。值得注意的是,本文的T2V-Turbo产生的4步生成在VBench上取得了最高的总分,甚至超过了Gen-2和Pika。本文进一步进行了人类评估来证实结果,验证了本文的T2V-Turbo产生的4步生成优于它们的教师模型产生的50步DDIM样本,这表示视频生成质量的提升了十倍以上,同时加速了视频生成的过程。
介绍
扩散模型(DM)已经成为神经图像和视频合成的强大框架,加速了文本到视频(T2V)模型的前沿发展,例如Sora,Gen-2和Pika。尽管这些基于扩散的模型的迭代采样过程确保了高质量的生成,但它显著减慢了推理速度,阻碍了它们的实时应用。另一方面,现有的开源T2V模型,包括VideoCrafter和ModelScopeT2V,是在网络规模的视频数据集上训练的,例如WebVid-10M,视频质量各不相同。因此,生成的视频通常在视觉上看起来不吸引人,并且无法准确与文本提示对齐,偏离了人类的偏好。
为了解决上述列出的问题,已经进行了一些努力。为了加速推理过程,Wang等人应用了一致性蒸馏(CD)理论,从教师T2V模型中蒸馏出一个视频一致性模型(VCM),使得在只需4-8个推理步骤中便能生成合理的视频。然而,VCM生成的质量受到教师模型性能的自然瓶颈限制,并且减少的推理步骤进一步降低了其生成质量。另一方面,为了使生成的视频与人类偏好保持一致,InstructVideo借鉴了图像生成技术,并提出通过迭代视频采样过程反向传播可微分奖励模型(RM)的梯度。然而,计算完整的奖励梯度成本过高,导致了巨大的内存成本。因此,InstructVideo通过将梯度计算限制为仅在最终DDIM步骤中截断采样链,从而损害了优化精度。此外,InstructVideo受限于其依赖于图像文本RM,无法充分捕捉视频的过渡动态。从经验上看,InstructVideo仅对有限的一组用户提示进行实验,其中大多数与动物相关。因此,它对更广泛范围提示的泛化性仍然是未知的。
本文旨在通过打破VCM的质量瓶颈,实现快速且高质量的视频生成。本文介绍了T2V-Turbo,它将来自多种RM混合的奖励反馈集成到从教师T2V模型中蒸馏VCM的过程中。除了利用图像文本RM来使单个视频帧与人类偏好对齐之外,本文进一步结合了来自视频文本RM的奖励反馈,全面评估生成视频中的时间动态和过渡。本文强调,本文的奖励优化避免了通过迭代采样过程反向传播梯度所涉及的高度消耗内存的问题。相反,本文直接优化由计算CD损失而产生的单步生成的奖励,有效地规避了传统方法面临的优化DM时的内存限制。
根据经验,本文展示了T2V-Turbo在4-8个推理步骤内生成高质量视频的优越性。为了说明本文方法的适用性,分别从VideoCrafter2和ModelScopeT2V中提取T2V-Turbo(VC2)和T2V-Turbo(MS)。值得注意的是,T2V-Turbo的两个变体在4个步骤生成的结果都优于视频评估基准VBench上的SOTA模型,甚至超过了使用大量资源训练的专有系统,如Gen-2和Pika。本文进一步通过使用EvalCrafter基准中的700个提示进行人类评估来证实这些结果,验证了T2V-Turbo的4步生成优于其教师T2V模型的50步DDIM样本,这代表了十倍以上的推理加速和增强的视频生成质量。
本文的贡献有三点:
- 从多种RM的反馈中学习T2V模型,包括视频文本模型。据作者所知,本文是第一个这样做的。
- 在仅4个推理步骤中在VBench上建立了一个新的SOTA,优于使用大量资源训练的专有模型。
- 根据人类评估,本文T2V-Turbo的4步生成优于其教师T2V模型的50步生成,代表了超过10倍的推理加速和质量改进。
使用混合奖励反馈训练T2V-Turbo
介绍下训练流程,推导出T2V-Turbo。为了促进快速高质量的视频生成,在从教师 T2V 模型中提取时,本文将来自多个 RM 的奖励反馈集成到 LCD 过程中。下图 2 概述了本文的框架。值得注意的是,本文直接利用单步生成 z ^ 0 = f θ ( z t n + k , ω , c , t n + k ) \hat{z}_0 = f_{\theta}(z_{t_{n+k}}, \omega, c, t_{n+k}) z^0=fθ(ztn+k,ω,c,tn+k) 由计算 CD 损失 L CD \mathcal{L}_{\text{CD}} LCD (6) 得出,并将从中解码的视频 x ^ 0 = D ( z ^ 0 ) \hat{x}_0 = D(\hat{z}_0) x^0=D(z^0) 优化为多个可微分的 RM。因此,本文避免了通过迭代采样过程反向传播梯度所面临的挑战,这是传统方法优化 DM 时经常面临的。
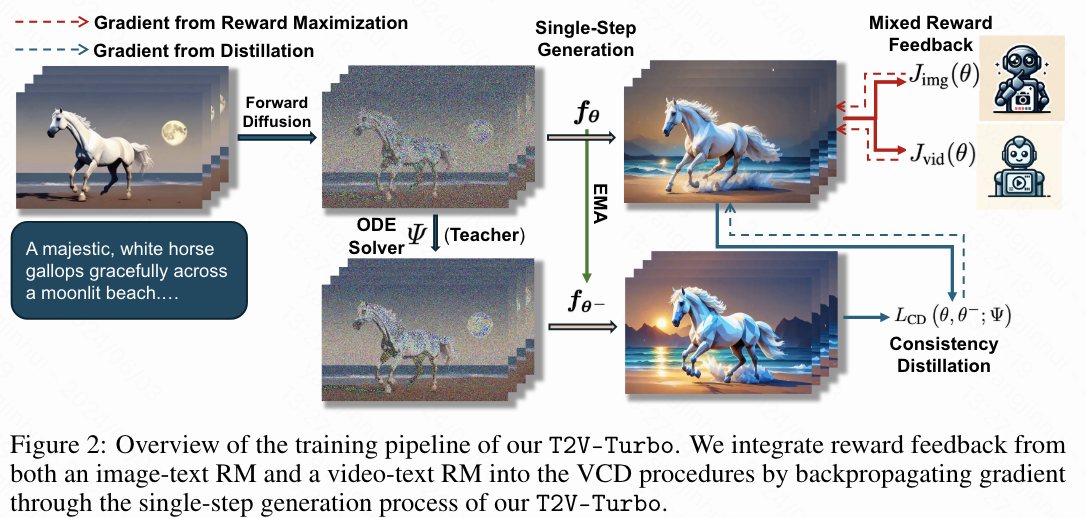
特别是,本文利用图像文本 RM 的奖励反馈来提高每个单独视频帧的人类偏好,并进一步利用视频文本 RM 的反馈来改善生成视频中的时间动态和过渡。
优化人类对个人视频片段的偏好
Chen等在训练 T2V 模型时,通过将高质量图像作为单帧视频来实现高质量的视频生成。受到他们成功的启发,本文通过优化可微分的图像文本 RM R img R_{\text{img}} Rimg 来将每个单独的视频帧与人类偏好对齐。具体来说,本文从解码视频 x ^ 0 \hat{x}_0 x^0 中随机采样一批 M M M 帧 { x ^ 1 0 , . . . , x ^ 0 M \hat{x}_1^0, ..., \hat{x}^M_0 x^10,...,x^0M},并最大化它们由 R img R_{\text{img}} Rimg 评估的分数。
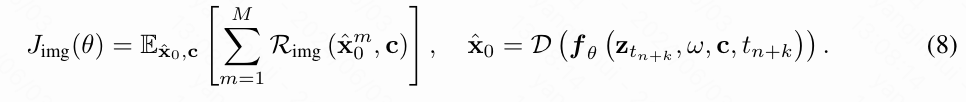
优化Video-Text反馈模型
已有的图像文本RM仅限于评估单个视频帧与文本提示之间的对齐,因此无法评估涉及帧间依赖性的时间维度,例如运动动态和转换。为了解决这些缺点,本文进一步利用视频文本RM
R
vid
R_{\text{vid}}
Rvid 来评估生成的视频。相应的目标函数
J
vid
J_{\text{vid}}
Jvid 如下给定:
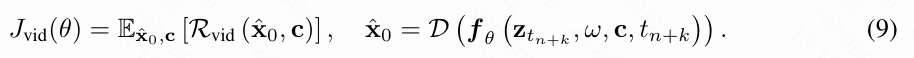
总结
为此,本文可以将本文训练流程的总学习损失 L L L 定义为 L C D L_{CD} LCD (式6)、 J img J_{\text{img}} Jimg (式8)和 J vid J_{\text{vid}} Jvid (式9)的线性组合,其中包含了权重参数 β img \beta_{\text{img}} βimg 和 β vid \beta_{\text{vid}} βvid。
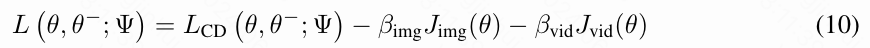
为了减少内存和计算成本,将本文的T2V-Turbo初始化为教师模型,并且仅优化LoRA权重,而不是执行完整的模型训练。在完成训练后,本文合并LoRA权重,使得本文的T2V-Turbo每步推理成本保持与教师模型相同。
实验结果
本文的实验旨在展示T2V-Turbo在4-8个推理步骤内生成高质量视频的能力。本文首先在标准基准测试集VBench上进行自动评估,以综合评估本文的方法在各个维度上的性能,并与广泛的基线方法进行比较。然后,本文使用来自EvalCrafter的700个提示进行人类评估,比较T2V-Turbo的4步和8步生成与教师T2V模型的50步生成以及基线VCM的4步生成。最后,对关键设计选择进行消融研究。
设置 本文通过从基于扩散的T2V模型VideoCrafter2和ModelScopeT2V中提取,分别训练T2V-Turbo(VC2)和T2V-Turbo(MS)。与两个教师模型类似,本文使用WebVid10M数据集进行训练。本文在8个NVIDIA A100 GPU上进行了10K个梯度步骤的模型训练,没有梯度累积。将每个GPU设备上的训练视频批次大小设置为1。本文采用HPSv2.1作为本文的图像文本RM R img R_{\text{img}} Rimg。当从VideoCrafter2进行提取时,本文将InternVideo2(InternVid2 S2)的第2阶段模型作为本文的视频文本RM R vid R_{\text{vid}} Rvid。当从ModelScopeT2V进行提取时,本文将 R vid R_{\text{vid}} Rvid 设置为ViCLIP。为了优化 J img J_{\text{img}} Jimg (8),本文通过设置 M = 6 M=6 M=6 从视频中随机采样6帧。对于超参数(HP),本文设置学习率为 1 e − 5 1e^{−5} 1e−5,指导尺度范围为 [ ω min , ω max ] = [ 5 , 15 ] [\omega_{\text{min}}, \omega_{\text{max}}] = [5, 15] [ωmin,ωmax]=[5,15]。本文使用DDIM作为本文的ODE求解器 Ψ Ψ Ψ,并设置跳跃步长 k = 20 k=20 k=20。对于T2V-Turbo(VC2),本文设置 β img = 1 β_{\text{img}}=1 βimg=1 和 β vid = 2 β_{\text{vid}}=2 βvid=2。对于T2V-Turbo(MS),本文设置 β img = 2 β_{\text{img}}=2 βimg=2 和 β vid = 3 β_{\text{vid}}=3 βvid=3。
VBench 自动求值
本文评估了本文的T2V-Turbo(VC2)和T2V-Turbo(MS),并将它们与广泛的基线方法进行比较,使用了标准视频评估基准VBench。VBench旨在从16个解耦维度全面评估T2V模型。VBench中的每个维度都根据特定的提示和评估方法进行了定制。
下表1比较了本文方法的4步生成与VBench排行榜上各种基线方法的比较,包括Gen-2、Pika、VideoCrafter1、VideoCrafter2、Show-1、LaVie和 ModelScopeT2V。原文附录中的表4进一步将本文的方法与VideoCrafter0.9、LaVie-Interpolation、Open-Sora和 CogVideo 进行了比较。每个基线方法的性能直接来自于VBench排行榜。为了获得本文方法的结果,本文严格遵循VBench的评估协议,为每个提示生成5个视频以计算指标。本文进一步从VideoCrafter2和ModelScopeT2V中提取VCM(VC2)和VCM(MS),并将它们的结果进行比较,而不包括奖励反馈。
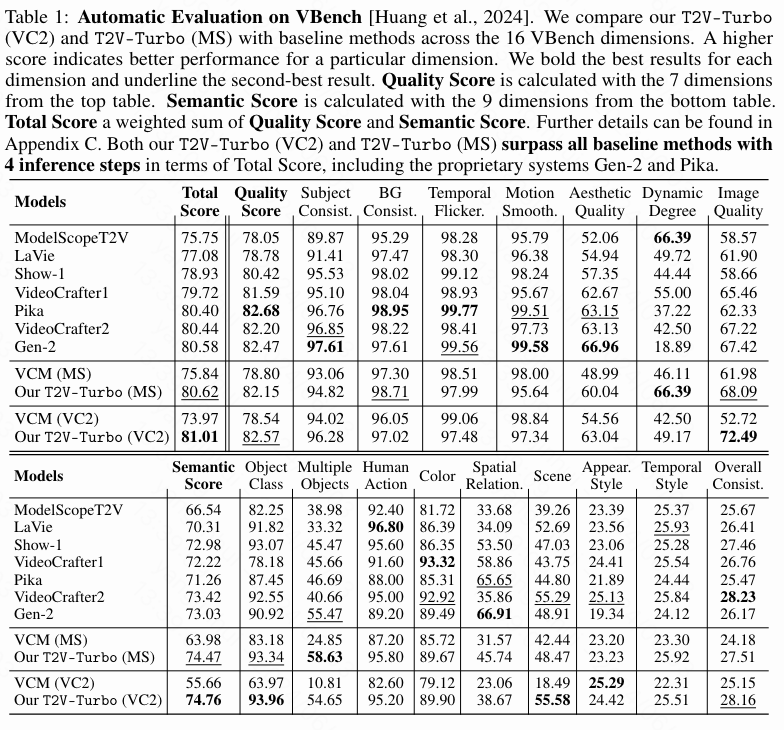
VBench已经制定了自己的规则来计算总得分、质量得分和语义得分。质量得分是使用顶部表格中的7个维度计算的。语义得分是使用底部表格中的9个维度计算的。而总得分是质量得分和语义得分的加权和。正如上表1所示,本文的T2V-Turbo(MS)和T2V-Turbo(VC2)的4步生成在总得分方面超过了VBench上的所有基线方法。这些结果尤其引人注目,因为本文甚至超过了使用大量资源训练的专有系统Gen-2和Pika。即使从一个较不先进的教师模型ModelScopeT2V进行提取,本文的T2V-Turbo(MS)也获得了第二高的总得分,仅次于本文的T2V-Turbo(VC2)。此外,本文的T2V-Turbo通过超越其教师T2V模型打破了VCM的质量瓶颈,明显优于基线VCM。
使用 700 个 EvalCrafter 提示进行人工评估
为了验证本文的T2V-Turbo的有效性,本文将T2V-Turbo的4步和8步生成与相应教师T2V模型的50步DDIM样本进行比较。本文进一步比较了从相同教师T2V模型提取时,本文的T2V-Turbo的4步生成与它们基线VCM的4步生成。
本文利用来自EvalCrafter视频评估基准的700个提示,这些提示是基于真实世界的用户数据构建的。本文从亚马逊的 Mechanical Turk 平台雇用人类标注员来比较使用相同提示生成的不同模型的视频。对于每次比较,标注员需要回答三个问题:
- Q1)哪个视频在视觉上更吸引人?
- Q2)哪个视频更符合文本描述?
- Q3)在给定的提示下,您更喜欢哪个视频?
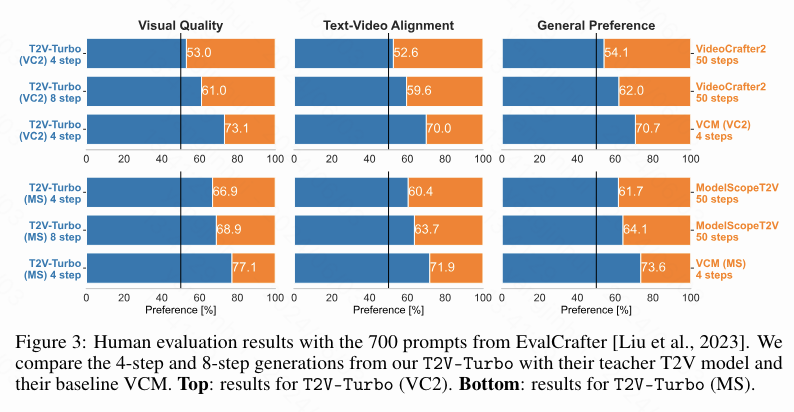
下图3提供了完整的人类评估结果。本文还在图4中对不同的方法进行了定性比较。附录F进一步包括了额外的定性比较结果。值得注意的是,与其教师T2V模型的50步生成相比,本文的T2V-Turbo的4步生成受到人类的青睐,表示推理加速了25倍并提升了性能。通过将推理步骤增加到8步,本文可以进一步改善从本文的T2V-Turbo生成的视频的视觉质量和文本-视频对齐,事实上,本文的8步生成在所有3个评估指标中都更受人类喜爱,相比本文的4步生成。此外,本文的T2V-Turbo显著优于其基线VCM,证明了将混合奖励反馈纳入模型训练的方法的有效性。
消融实验
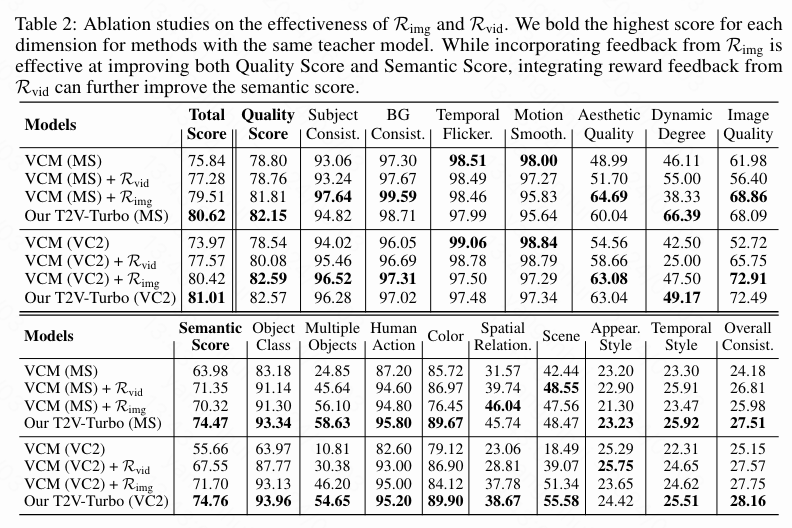
本文对每个RM的有效性感兴趣,特别是对视频文本RM R vid R_{\text{vid}} Rvid 的影响。因此,本文对 R img R_{\text{img}} Rimg 和 R vid R_{\text{vid}} Rvid 进行了消融实验,并尝试了不同选择的 R vid R_{\text{vid}} Rvid。
消融RM R img R_{\text{img}} Rimg 和 R vid R_{\text{vid}} Rvid 。回想一下,本文的T2V-Turbo的训练同时包含来自 R img R_{\text{img}} Rimg 和 R vid R_{\text{vid}} Rvid 的奖励反馈。为了展示每个单独的RM的有效性,本文通过训练VCM(VC2)+ R vid R_{\text{vid}} Rvid 和 VCM(VC2)+ R img R_{\text{img}} Rimg 进行消融研究,分别仅包含来自 R vid R_{\text{vid}} Rvid 和 R img R_{\text{img}} Rimg 的反馈。同样,本文评估了VBench上来自不同方法的4步生成。下表2中的结果显示,将来自 R img R_{\text{img}} Rimg 或 R vid R_{\text{vid}} Rvid 的反馈纳入其中都会导致性能提升超过基线VCM。值得注意的是,仅优化 R img R_{\text{img}} Rimg 就可以带来显著的性能提升,而将来自 R vid R_{\text{vid}} Rvid 的反馈纳入其中可以进一步提高VBench上的语义得分,从而实现更好的文本-视频对齐。
不同选择的 R vid R_{\text{vid}} Rvid的影响。本文通过将 R vid R_{\text{vid}} Rvid设置为ViCLIP和Intervideo2的第二阶段模型(InternVid2 S2)来调查不同选择的 R vid R_{\text{vid}} Rvid的影响,从而训练T2V-Turbo(VC2)和T2V-Turbo(MS)。在模型架构方面,ViCLIP采用了CLIP文本编码器,而InternVid2 S2则利用了BERT-large文本编码器。此外,InternVid2 S2在几个零-shot视频文本检索任务中表现优于ViCLIP。如下表3所示,当集成来自ViCLIP或InternVid2 S2的反馈时,T2V-Turbo(VC2)在VBench上可以实现相当不错的性能。相反,当使用ViCLIP时,T2V-Turbo(MS)表现更好。然而,即使使用InternVid2 S2,本文的T2V-Turbo(MS)仍然超过了VCM(MS)+ R img R_{\text{img}} Rimg。

结论 & 限制
在本文中,提出了T2V-Turbo,通过打破VCM的质量瓶颈,实现了快速和高质量的T2V生成。具体来说,本文将混合奖励反馈集成到教师T2V模型的VCD过程中。从经验上讲,本文通过从VideoCrafter2和ModelScopeT2V中提取T2V-Turbo(VC2)和T2V-Turbo(MS)来说明本文方法的适用性。值得注意的是,本文的两个T2V-Turbo的4步生成都优于VBench上的SOTA方法,甚至超过了它们的教师T2V模型和专有系统,包括Gen-2和Pika。人类评估进一步证实了这些结果,显示出本文的T2V-Turbo的4步生成受到人类的青睐,而不是它们的教师的50步DDIM样本,这代表了超过十倍的推理加速和质量改进。
虽然本文的T2V-Turbo标志着高效T2V合成的重要进步,但也需要认识到一些局限性。本文的方法利用了一种混合RM,包括视频文本RM R vid R_{\text{vid}} Rvid。由于缺乏一个针对视频文本配对反映人类偏好的开源视频文本RM,本文转而使用像ViCLIP和InternVid S2 这样的视频基础模型作为本文的 R vid R_{\text{vid}} Rvid。尽管从这些模型中获得的反馈提升了本文的T2V-Turbo的性能,但未来的研究应该探索使用更先进的 R vid R_{\text{vid}} Rvid来进行反馈训练,这可能会进一步提高性能。
参考文献
[1] T2V-Turbo: Breaking the Quality Bottleneck of Video
Consistency Model with Mixed Reward Feedback
更多精彩内容,请关注公众号:AI生成未来
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









