









恢复低分辨率文本图像具有挑战性,特别是对于在现实场景中具有复杂笔画和严重降质的中文文本图像。确保文本的准确性和样式的真实性对于高质量的文本图像超分辨率至关重要。最近,由于扩散模型强大的数据分布建模能力和数据生成能力,在自然图像合成和恢复方面取得了巨大成功。本文提出了一种图像扩散模型(IDM),用于以真实的风格恢复文本图像。对于扩散模型,它们不仅适用于建模真实图像分布,而且适用于学习文本分布。由于文本先验对于确保根据现有艺术作品正确恢复文本结构至关重要,作者还提出了一种文本扩散模型(TDM)用于文本识别,它可以指导IDM生成具有正确结构的文本图像。进一步提出了一个多模态混合模块(MoM),以使这两个扩散模型在所有扩散步骤中相互合作。在合成和真实数据集上进行的大量实验证明,本文基于扩散的模糊文本图像超分辨率(DiffTSR)可以同时恢复具有更准确文本结构和更真实外观的文本图像。
引言
模糊文本图像超分辨率(SR)专注于从由各种未知退化引起的低分辨率(LR)图像恢复高分辨率(HR)图像。与注重丰富和增强图像细节的自然图像超分辨率任务不同,还应确保在恢复的文本图像中保持文本的准确性和风格真实性。错误估计的文本结构,如扭曲、缺失、额外或重叠的笔画,将导致不准确的字符语义,在恢复的文本图像中是不可接受的。同样,不正确生成的文本风格,如字体、字形、颜色和姿态的变化,将使恢复的文本图像在视觉上令人不愉快和不真实。
为了以正确的结构重建文本图像,现有方法 [3, 25–27, 32, 42] 引入了利用低级和高级文本先验来通过考虑与文本结构相关的损失或整合额外的文本识别模块来引导恢复过程。尽管这些方法增强了重建图像中字符的视觉外观,但在遇到具有复杂笔画或严重劣化的文本图像时,它们很难恢复准确的文本结构。为了缓解上述问题,MARCONet 使用密码本存储每个字符的离散代码,这可以用于生成具有高文本准确性的高分辨率结构细节。此外,MARCONet 还利用 StyleGAN生成视觉上愉悦的文本风格。尽管 MARCONet 在一定程度上可以处理复杂的笔画和严重的劣化,但在训练期间预定义的字体样式限制了其处理现实世界中未见和多样化文本样式的能力,导致了一些恢复图像的不真实性和不准确性。
最近,由于其强大的数据分布建模和数据生成能力,扩散模型在自然图像合成和恢复方面取得了巨大成功。作者认为扩散模型也应该适用于建模各种文本风格,包括字体、字形、颜色和姿态,以恢复视觉上更愉悦和真实的文本图像。因此,提出了一种基于稳定扩散的图像扩散模型(IDM)来有效地建模文本样式。为了保持文本字符的准确性,IDM以输入的低分辨率图像和文本预测先验为条件。然而,从严重劣化的图像中准确识别文本是具有挑战性的,不准确的文本识别将导致恢复结果中的不正确文本结构。根据 [17] 的分析,扩散模型也适合建模离散变量分布,例如文本。基于此,本文引入使用文本扩散模型(TDM)来根据低分辨率输入正确识别文本,并提供文本先验,以帮助 IDM 以高准确性恢复文本图像。值得强调的是,TDM 可以使 IDM 受益,反之亦然。因此,进一步提出了一个多模态混合模块(MoM),以便这两个扩散模型在所有扩散步骤中相互合作。大量实验证明,基于扩散的模糊文本图像超分辨率(DiffTSR)能够同时从劣化的图像中恢复出具有令人满意的文本准确性和风格真实性的文本图像,特别是对于具有复杂笔画的中文文本图像。总的来说,工作具有以下主要贡献:
• 提出使用 IDM 和 TDM 来建模文本图像分布和文本分布,以便以高文本准确性和风格真实性恢复文本图像。
• 提出了一个 MoM 模块,使 IDM 和 TDM 在所有扩散步骤中密切合作。
• 大量实验证明,所提出的 DiffTSR 在合成和真实数据集上均优于现有方法。
相关工作
「模糊图像超分辨率」。模糊图像超分辨率(SR)旨在提高在现实世界场景中具有复杂未知劣化的图像的分辨率和质量。最近的工作从两个方面努力实现更有效的模糊SR:劣化模型估计和现实世界数据合成。前者以无监督的方式从低分辨率(LR)图像中学习劣化模型,然后应用非模糊SR方法。后者通过模拟现实世界劣化的复杂策略来合成 LR-HR 图像训练对。具体而言,BSRGAN使用随机洗牌策略实现更广义的劣化数据合成,而 Real-ESRGAN通过高阶劣化建模过程进一步增强了图像劣化的复杂性。尽管上述方法在自然图像的模糊 SR 方面取得了巨大成功,观察到,如果不考虑特定的字符结构和文本风格,有效提升文本图像的质量是不足够的。
「文本图像超分辨率」。文本图像超分辨率旨在增强图像的细节,同时提高文本的可读性,即文本识别的准确性。最近的研究主要集中在探索文本识别先验和字符结构先验的指导,以提高文本图像超分辨率的性能。具体而言,基于文本图像的特点,现有的工作主要从三个方面利用与文本相关的先验信息来约束文本图像的超分辨率:文本感知损失,文本识别先验和文本结构先验。先前的研究表明,文本先验在文本结构增强中起着重要作用。然而,它们大多数未充分利用文本先验信息,不能恢复具有多样化文本风格、严重劣化或复杂笔画的文本图像。
「扩散模型」。扩散模型由于在图像合成和可控图像生成中的卓越性能而引起了极大关注。受益于扩散模型强大的数据分布建模能力,最近的研究,通过利用扩散先验在图像超分辨率方面也取得了令人印象深刻的成果。此外,现有研究表明扩散模型还适用于建模离散数据,如文本、分割图等。本文旨在探索图像扩散模型和文本扩散模型之间的协同作用,并通过利用扩散先验实现具有高文本准确性和风格真实性的高质量文本图像超分辨率。
方法学
概述
本文提出使用扩散模型考虑文本先验来恢复降质的文本图像。首先,提出了一个基准模型,如下图2(a)所示。
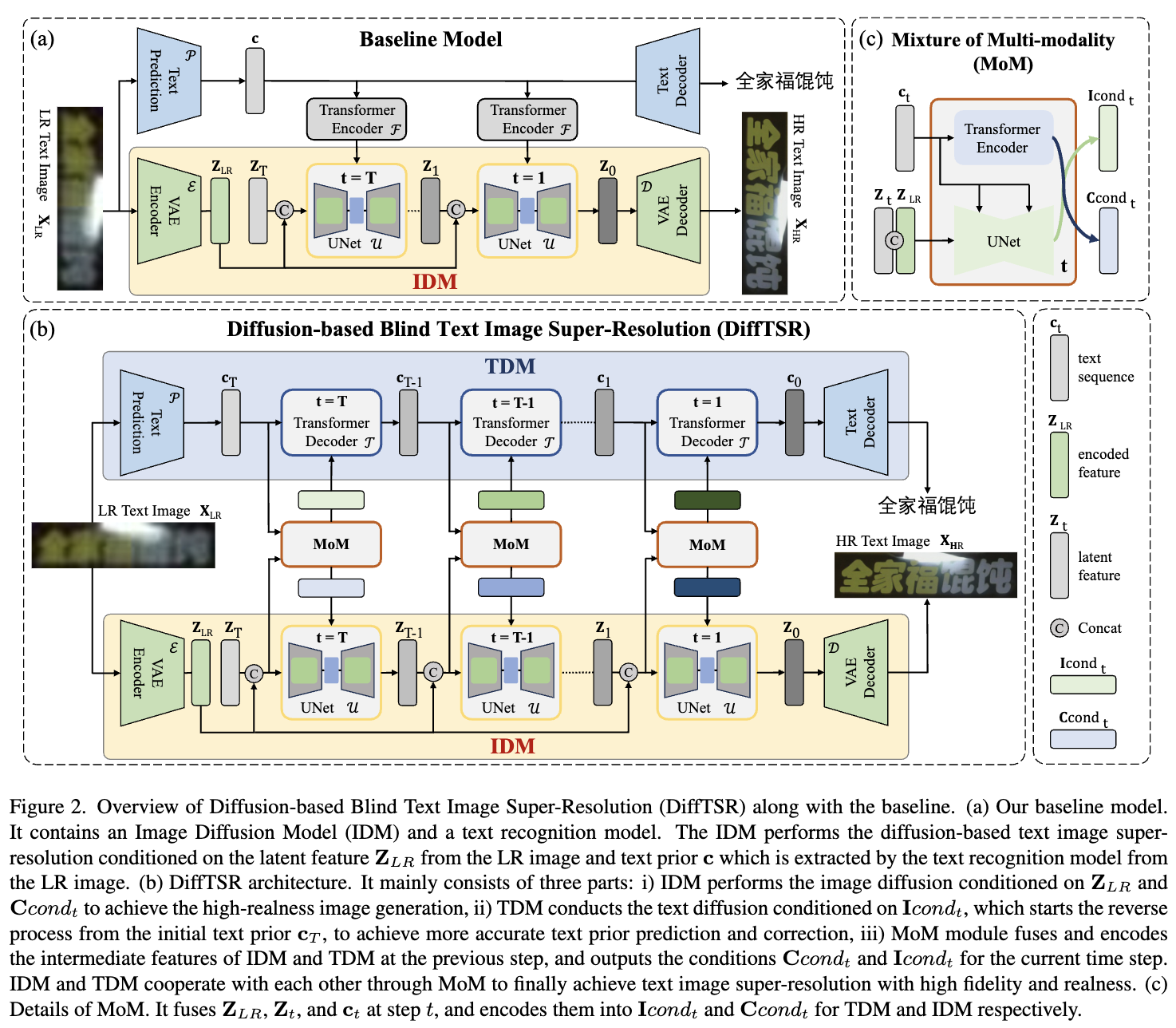
它使用文本识别模型提供文本先验。然后,采用所提出的图像扩散模型(IDM)来根据文本先验恢复文本图像。尽管上述基准模型可以相对可接受地恢复劣化的文本图像,但在遇到严重劣化时,可能会产生扭曲的文本结构。除了IDM外,所提出的基于扩散的模糊文本图像超分辨率(DiffTSR)还包括基于以下假设的文本扩散模型(TDM)和多模态混合模块(MoM):更准确的文本识别信息有助于IDM生成更真实的图像;同时,更高质量的文本图像有助于更好的识别。在DiffTSR中,TDM是一个扩散模型,逐渐识别具有给定图像信息的文本序列。至于MoM,它像是连接IDM和TDM的桥梁。它在扩散过程中为IDM提供更新的文本先验,并为TDM提供图像信息。通过这种方式,所提出的DiffTSR可以同时恢复具有高风格真实性和文本准确性的文本图像。DiffTSR的整体架构如上面图2(b)所示。
基准模型
基准模型如前面图2(a)所示。主要由两个部分组成,1)图像扩散模型(IDM),2)文本识别模型。文本识别模型从低分辨率文本图像中估计文本序列c,作为每个扩散步骤中的文本先验,并且IDM通过在条件为c和的情况下执行扩散逆过程来实现图像超分辨率。
为了建模现实世界文本图像的分布并实现逼真的图像生成,所提出的IDM基于稳定扩散。IDM通过VAE编码器E和解码器D在潜在空间中执行扩散正向和逆向过程。在通过ξ将HR图像X编码到潜在空间为Z = ξ(X)之后,IDM在时间步骤t中将噪声逐步添加到Z中,记为,并使用噪声预测网络Uθ逐渐去除逆过程中的噪声。为了使恢复结果与输入LR图像一致,通过与Zt串联的方式,编码的特征被视为中的一个条件。同时,文本先验也被视为中的另一个条件。具体而言,通过P中的文本识别模型估计的文本c,通过transformer编码器进行编码,并通过交叉注意力机制将编码的特征融入的中间层。
基准模型的采样过程的详细描述如下。首先,利用文本识别模型P从LR文本图像中预测文本序列c。然后,IDM启动逆过程,并在由VAE编码器E从LR图像XLR中提取的潜在特征ZLR和由transformer编码器从c中提取的文本先验的条件下重复噪声去除步骤,直到获得。然后,通过VAE解码器将恢复的文本图像重建为。基准模型可以恢复具有高真实性的文本图像,这得益于IDM生成逼真细节的能力。
基于扩散的模糊文本图像超分辨率
尽管上述基准模型可以有效地恢复低分辨率文本图像,但在遇到严重劣化时,仍会生成不令人愉悦的结果,如下图3(a)所示。

这是因为文本识别模型在高度扭曲的文本图像上表现不佳,而IDM在不准确的文本先验下无法恢复具有高文本准确性的文本图像。在本小节中,提出了基于扩散的模糊文本图像超分辨率(DiffTSR),通过在每个扩散步骤中共同优化图像恢复和文本识别,来恢复具有高文本准确性和风格真实性的文本图像。除了与基准模型相同的IDM外,DiffTSR还包含文本扩散模型(TDM)和多模态混合模块(MoM)。TDM、MoM和整个DiffTSR的详细描述如下。
现有研究表明,扩散模型不仅可以建模图像分布,还可以建模文本等离散数据。为了建模文本序列c的分布,TDM也遵循扩散过程的马尔可夫链,在正向过程中逐渐向文本序列添加随机噪声,然后学习逆过程以从嘈杂的数据中重构文本序列。与IDM不同,IDM是一个连续的扩散模型,添加的噪声符合高斯分布,而TDM是一个离散的扩散模型。类似于 [17, 48],TDM假设正向过程中的转移分布 遵循分类分布。在这个假设的基础上,TDM提出使用transformer解码器 来从 中去除噪声并生成 。为了使文本序列建模更符合输入图像的上下文,包含MoM估计的图像信息的 I 通过交叉注意力机制映射到 的中间层。TDM受益于文本建模能力以及图像条件指导,并生成与LR图像一致的更合理和准确的文本序列。
由于文本识别可以使文本图像超分辨率受益,反之亦然,我们提出了一个用于联合优化的多模态混合模块(MoM),如前面图2(c)所示。MoM由两个时态感知模块组成,一个UNet和一个transformer编码器。MoM的UNet在时间步骤 tfirst 从串联的 和 中提取图像信息。然后,通过交叉注意力机制, 被映射到 UNet 的中间层。UNet将多模态信息融合编码到 TDM 的每个时间步的图像条件中,从而自适应生成更适合TDM实现更高识别精度的图像条件。同时,MoM的transformer编码器接收来自TDM前一步的更正字符 ,并将其编码为IDM的字符嵌入空间中的文本条件: 。总的来说:
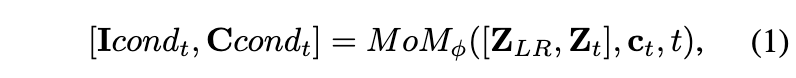
其中, 和 分别用作时间步骤 t 时 IDM 和 TDM 的条件。
介绍了IDM、TDM和MoM之后,DiffTSR的采样过程如下面Algorithm 1和上面图2(b)所示。

首先,通过VAE编码器E从LR图像中提取特征。与此同时,使用高斯分布随机采样,并从LR图像中获得初始估计的文本。请注意,TDM从初始估计的文本开始进行逆过程,而不是从随机采样的文本开始。在初始化过程之后,IDM使用UNet U从给定的、上一步的去噪特征以及MoM的文本先验Ccondt中去除潜在特征的噪声。同时,TDM使用transformer解码器T估计具有给定前一时间步的状态和MoM的图像条件的文本序列的潜在状态。通过T协同扩散步骤,可以估计得到,然后使用VAE解码器D重建具有高准确性和真实性的HR文本图像。由于通过MoM的联合优化策略,所提出的DiffTSR可以通过IDM逐步恢复HR文本图像,并在TDM中得到更准确的文本序列,如上面图3(b)所示。有关DiffTSR的采样和训练策略的更多详细信息,请参阅补充材料。
实验
实验设置
「训练数据集」。在这项工作中,主要关注现实世界中汉字的模糊文本图像超分辨率。为了获得大量带有文本标注的HR汉字文本图像,我们使用大规模的现实世界汉字文本图像数据集CTR。为了在训练过程中选择图像作为地面真实值,我们通过以下步骤对CTR训练集进行预处理:i)移除分辨率小于64像素的图像,ii)仅保留宽高比大于2的图像,iii)仅保留文本标注长度不大于24的图像,iv)将图像调整为128 × 512。然后,剩余63,644张HR文本图像,带有文本标注c,我们将这个数据集称为CTR-TSR-Train。采用BSRGAN和Real-ESRGAN中提出的劣化pipeline生成LR文本图像。
「测试数据集」。在合成和现实世界数据集上评估该方法,进行×2和×4的模糊超分辨率。对于合成测试集,作者使用与CTR-TSR-Train相同的预处理和劣化策略生成CTR-TSR-Test。这些图像来自CTR的测试集,总共有8,089个样本。对于现实世界数据集,使用RealCE的测试集,这是一个最近提出的现实世界中文-英文基准数据集。移除具有超过24个字符或LR-HR对齐严重的图像。最终,获得了1531个现实世界测试集的LR-HR对。
「比较方法和评估指标」。为了验证本文方法的有效性,分别将DiffTSR与自然图像超分辨率方法(即SRCNN、ESRGAN和NAFNet)以及文本图像超分辨率方法(即TSRN、TBSRN、TATT和MARCONet)进行比较。为了公平比较,修改它们的实现以处理×2和×4的图像上采样,并使用CTR-TSR-train数据集进行微调。此外,使用5个指标来评估上述方法在文本图像恢复上的性能。采用峰值信噪比(PSNR)和学习感知图像块相似度(LPIPS)来评估恢复图像与参考图像在图像空间和特征空间中的距离。为了进一步评估恢复图像的真实性,采用Frechet Inception Distance(FID。为了更好地评估恢复文本图像的文本准确性,采用单词准确性(ACC)和标准化编辑距离(NED)。采用预训练的TransOCR作为文本识别模型用于ACC和NED。
定量比较
在合成测试数据集CTR-TSR-Test和现实世界测试数据集RealCE上展示了定量比较。如下表1所示,DiffTSR在所有指标上均优于比较方法。
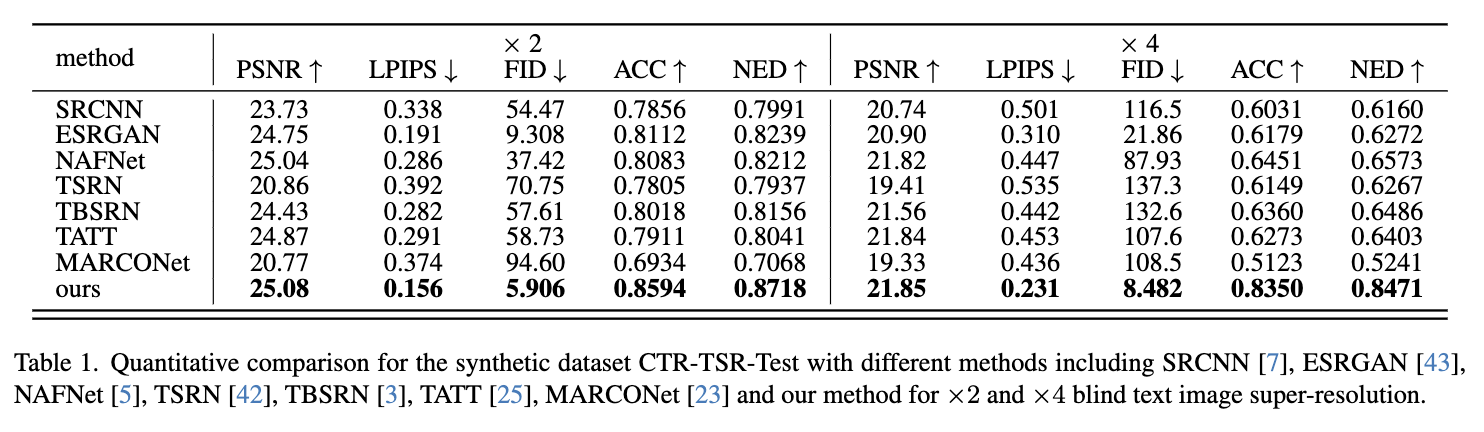
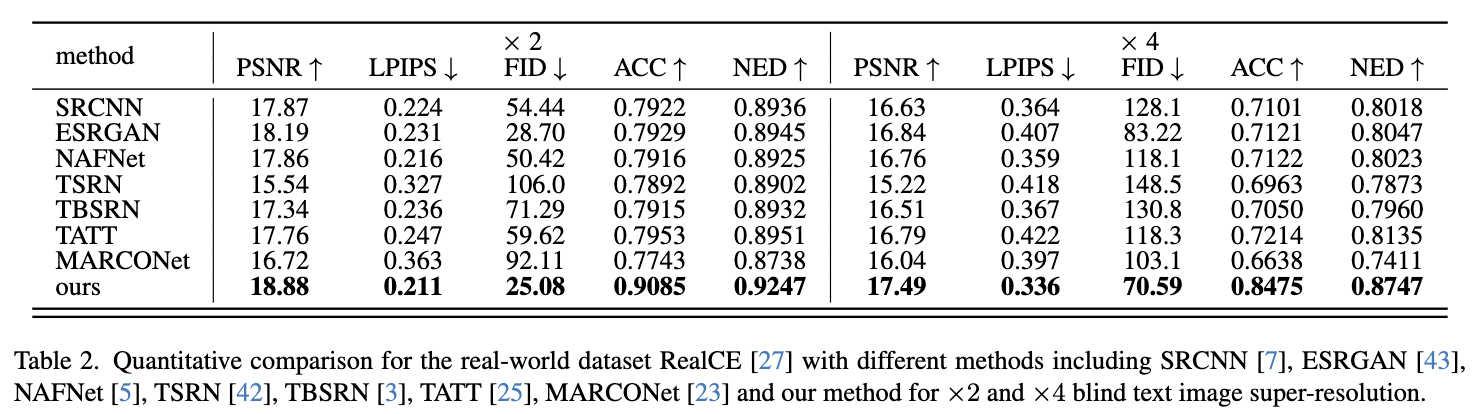
它取得了最佳的PSNR,表明它能够准确重建HR图像。由于具有强大的文本图像建模能力,我们的方法在LPIPS和FID方面表现更好,表明恢复图像的真实性更高。我们的方法在ACC和NED方面也表现更好,表明它能够通过TDM提供的文本先验有效地保持文本的准确性。同时,请注意我们的方法在RealCE上仍然展现出最佳性能,而没有在RealCE训练集上进行任何微调,如下表2所示,表明其在现实世界文本图像的强大泛化性能和建模能力。
定性比较
合成数据集CTR-TSR-Test的定性结果如下图4所示。

大多数超分辨率方法和文本超分辨率方法,如SRCNN、NAFNet、TSRN 、TBSRN和TATT,都比本文的方法恢复LR图像更差,这证明了所提出的IDM生成具有高真实性的文本图像的能力。由于具有强大的生成能力,ESRGAN 可以恢复更真实的图像(第一个结果)。然而,当劣化过于严重时,它也会生成伪影(第二和第三结果)。即使MARCONet具有通过密码本恢复更为愉悦的文本结构的能力,但在训练过程中未考虑文本样式时,它也会生成伪影(第一个结果)。此外,当劣化严重时(第二个例子)或遇到遮挡(第三个例子)时,MARCONet的文本先验是不准确的。这将导致MARCONet的恢复结果具有较低的文本保真度。在TDM对文本序列建模和MoM同时优化IDM和TDM的帮助下,我们的方法可以生成具有更高文本保真度的HR图像。
作者还基于实际数据集RealCE对不同的方法进行了比较。请注意,所有方法均未在RealCE的训练集上进行训练,以评估在遇到未知风格和劣化时的泛化能力。下图5中的结果表明,大多数方法,如SRCNN、ESRGAN、NAFNet、TSRN、TBSRN和TATT,几乎无法去除这个现实世界数据集中的劣化。

尽管MARCONet 在某种程度上可以恢复HR文本图像,但结果中仍会生成一些不准确和不愉快的笔画。借助IDM强大的分布建模能力,所提出的方法可以在现实世界场景中很好地泛化,并以高样式真实度和文本保真度恢复文本图像。
消融研究
本节验证了所提出方法中不同组件的有效性,并在下表3和图6中进行了比较。对于'exp1',它仅包含对LR图像进行条件化的IDM。
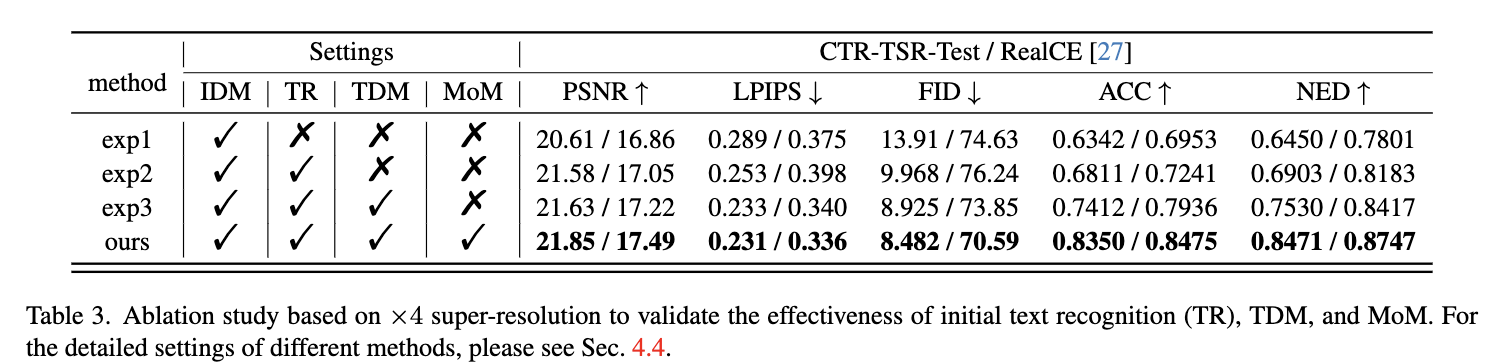

如图6的第二行所示,结果看起来像是中文字符。然而,生成的字符实际上在中文字母表中不存在,因为在扩散过程中未考虑文本先验。在前面的中的基线模型中,即'exp2'中,它使用文本识别(TR)方法预测文本序列并为IDM提供文本先验。因此,根据图6的第三行,'exp2'可以更好地保持文本保真度。然而,当劣化过于严重且文本字符识别不准确时,结果仍然不理想,如橙色边框中所示。'exp3'使用TDM,其初始状态由TR提供,来预测文本序列并为IDM提供文本先验。通过TDM通过扩散具有强大的文本序列分布建模能力,'exp3'可以比'exp2'更准确地识别文本,如图6的第四行所示。但是绿色边框中的文本字符仍然不正确。这是因为'exp3'中的TDM在扩散过程中未利用IDM提供的更高质量的图像信息来识别更准确的文本序列。我们的方法包含MoM模块,该模块可以在扩散步骤中为IDM提供更好的文本先验,并为TDM提供更好的图像先验。通过这种方式,本文方法中的TDM可以使用IDM提供的更高质量的图像信息纠正错误估计的文本序列。同时,IDM可以以更高的保真度恢复文本图像,如图6的第五行所示。同样,上面表3显示,考虑更多组件的所提出方法可以实现更一致的性能,证明了TR、TDM和MoM的有效性。
结论
本文提出了使用扩散模型来解决模糊文本图像超分辨率问题。由于扩散具有强大的分布建模和数据生成能力,所提出的IDM能够恢复逼真的HR文本图像。同时,还应用另一个扩散模型(TDM)来建模文本序列的分布并为IDM提供文本先验。通过这种方式,IDM还能够生成具有高文本保真度的文本图像。最后,提出了MoM,使这两个扩散模型在扩散过程中适当地相互合作。在合成和真实世界数据集上进行的大量实验证明,本文的方法在风格真实度和文本保真度方面均优于现有方法。
参考文献
[1] Diffusion-based Blind Text Image Super-Resolution
论文链接:https://arxiv.org/pdf/2312.08886
更多精彩内容,请关注公众号:AI生成未来


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









