







本文主要介绍我们在图表征领域被WWW 2021接收的工作,SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism。

Paper: https://arxiv.org/abs/2101.08170
Code: https://github.com/RingBDStack/SUGAR
Resource: https://github.com/SunQingYun1996/Graph-Reinforcement-Learning-Papers
目前,大部分图表征方法或采用全局池化方法生成一个全局表征向量,忽略了子结构的语义,或依赖专家知识抽取局部子结构,这导致图表征方法普遍具有可解释性差、泛化性差等缺点。
为有效解决这一问题,我们提出了子图神经网络SUGAR,通过自适应地提取显著子图作为原始图的代表性部分,在有效进行图分类的同时可挖掘子图层级的模式。为了在缺乏专家知识的情况下捕捉子结构的语义,我们首次引入强化学习来自适应地选择特征显著的子图结构,提高了模型的泛化能力;为获得更具判别性的子图表征,我们引入自监督的互信息机制,通过最大化局部与全局的互信息,使得子图表征中包含全图的特征。在六个公开数据集上的实验表明,我们的方法在取得最好结果的同时具有较强的可解释性。
研究背景
图是一种常用的用来建模复杂关系的结构,通过学习图嵌入,可以有效捕捉到结构数据的顺序、拓扑、几何等关系特征。除了节点层级(node-level)的嵌入方法外,图层级(graph-level)的嵌入方法在很多现实应用中有着很重要的作用,比如化学分子性质分析和药物发现、社交网络中的社团分析等等。
现有的图层级嵌入方法可以分为两大类:传统图核(graph kernel)方法和最近的基于图神经网络(Graph Neural Network, GNN)的方法。
图核方法使用核函数直接将原始的图结构分解为很多个子结构,通过比较子结构的相似度对图进行表示,在特定领域中取得了比较好的效果。但是图核方法需要人工设计核函数,这样设计出来的核函数只适用于特定领域,泛化性并不好;另一方面,随着子结构尺寸变大,嵌入的维度也会以指数级增大,这将使得图表征非常稀疏。
基于GNN的方法大多是先学习节点表征,再将节点表征融合为一个全局表征来表示整个图;然而,图具有广泛的属性结构,比如节点(node)、路径(path)、环(cycle)、图案(motif)、子图(subgraph)等,这些子结构往往包含着重要的语义信息,这在全局融合的过程中是很难捕捉到的。一些方法通过构造规则显示地提取motif等局部结构,但这也需要领域知识才能完成。
总的来说,现有的图嵌入方法有以下三点缺陷:
判别性(discrimination):融合所有的节点特征和关系来获得一个全局图表示通常会带来潜在的过度平滑问题,从而导致图的特征变得无法区分。
先验知识 (prior knowledge):以相似度或子结构提取的形式保存结构特征大多是启发式的,需要大量的先验知识,这是非常繁琐困难的。
可解释性 (interpretability):许多方法是通过逐步池化的方法来利用子结构,这丢失了许多精细的结构信息,导致下游任务结果缺乏足够的可解释性。
模型与方法
为解决上述判别性、先验知识和可解释性的问题,我们提出了一种子图神经网络,通过自适应地选择显著子图来代表图的判别性信息,从“节点-子图-图”三个层级保留结构信息,在具有强大表征能力的时候有很好的泛化性和可解释性。构建子图神经网络有三个步骤:
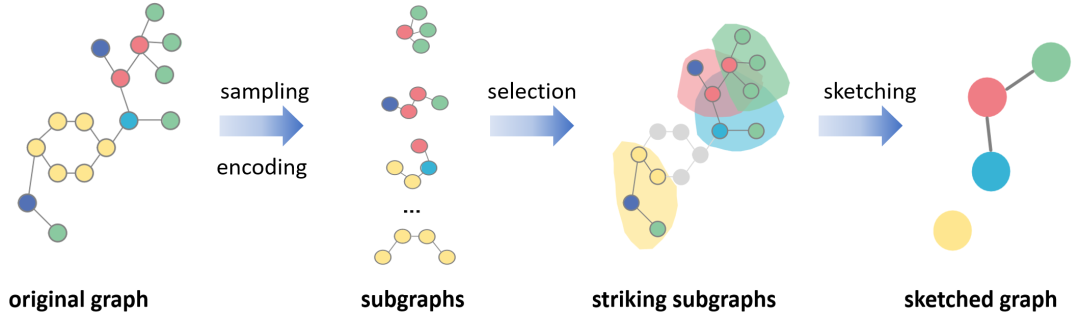
子图采样和编码:对每个图样本采样出固定数量的子图,通过子图内注意力(intra-subgraph attention)的方法对子图进行编码。
显著子图选择:通过强化学习机制选择top-k个子图作为显著子图。
构建骨架图(sketched graph):将选择出的显著子图作为节点进行图重构,获得一张骨架图,通过子图间的注意机制(inter-subgraph attention)和自监督互信息机制(Mutual Information)学习子图嵌入。
子图神经网络的构建过程中主要面临两大挑战:如何从不同类型的图数据中自适应地选出显著子图?如何在有效表征子图的同时保留整个图的结构特征?为解决这两大挑战,我们分别提出了强化学习驱动的子图选择机制和互信息驱动的子图表征方法:
强化学习驱动的子图选择机制
现有的top-k选择方法中,选择比例k常常作为一个超参数或者根据专家经验确定,泛化性差,我们提出了一种新的强化学习(RL)算法,通过更新选择比例k来实现对不同图数据集的自适应显著子图选择。k的更新过程可以定义为一个有限的马尔可夫过程(Finite Horizon Markov Decision Process,MDP),这个MDP的状态、动作、转移、奖励和终止定义如下:
状态(State):第e轮的状态可以表示为该轮选择的子图索引idx
动作(Action):RL算法根据奖励做出相应的动作,我们把动作定义为把选择比例k增加或减小一个离散值Δk。
转移(Transition):在每轮更新完k后,我们在下一轮中以新的比例k进行top-k选择。
奖励(Reward):由于GNN的状态难以度量,我们直接根据上一轮的分类精度确定相应的奖励值,
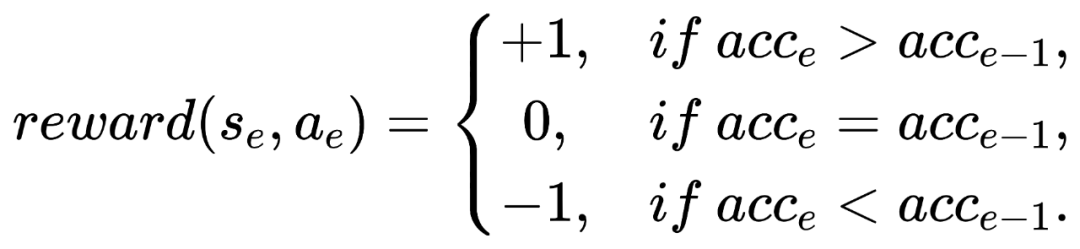
终止(Termination):如果连续十轮的k值没有变化,那么RL算法将终止更新。由于这个MDP是有限视野的离散优化问题,我们使用经典的Q-learning算法求解
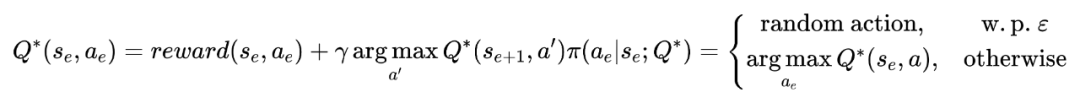
互信息增强的子图表征
由于我们的模型依赖于提取显著子图作为原始图的代表部分,为了使得获得的子图表征在具有判别性的同时能够包含图的全局特征,我们利用互信息(MI)来衡量子图嵌入的表征能力,在模型更新过程中最大化子图嵌入和全局嵌入的互信息。
首先,为了获得全局嵌入,我们使用一个READOUT函数来融合子图嵌入:
然后,我们使用常用的Jensen-Shannon (JS) MI estimator来最大化子图嵌入/全局嵌入的互信息。具体来说,使用一个判别器(Discriminator)来判别输入的子图嵌入/全局嵌入是否来自于同一个图:
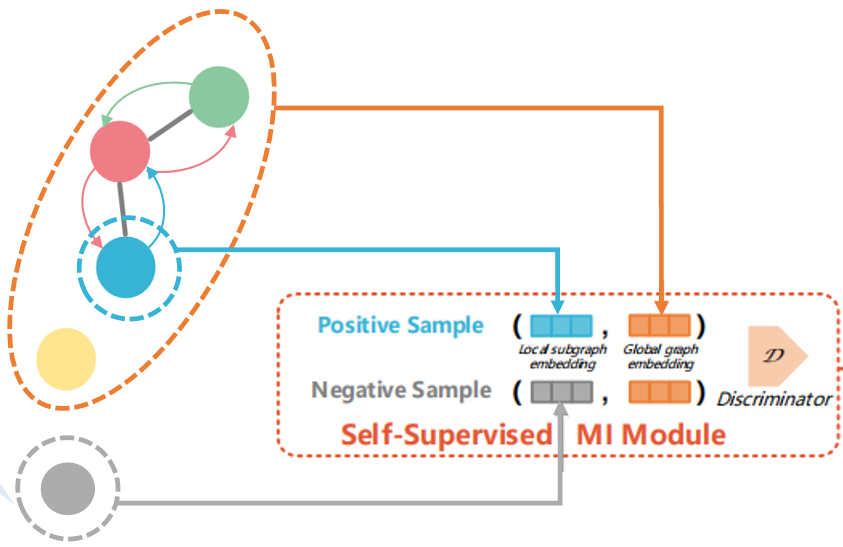
这种互信息最大化机制是以一种对比学习的方式进行的,除了将选择出的子图和原始图表征对作为正样本,我们还需要构建一些负样本(图中灰色部分)。这里我们提出了两种负采样方法:①将子图表征和另一个图的全局表征作为负样本;②将原始图的特征矩阵打乱,获得一个扰动的全局表征作为负样本。这两种负采样方法在实验部分进行了具体的分析,结论表明负采样方式①要优于②。
模型整体的损失函数是图分类损失函数与互信息最大化损失函数的结合:
模型整体框架和算法如下:
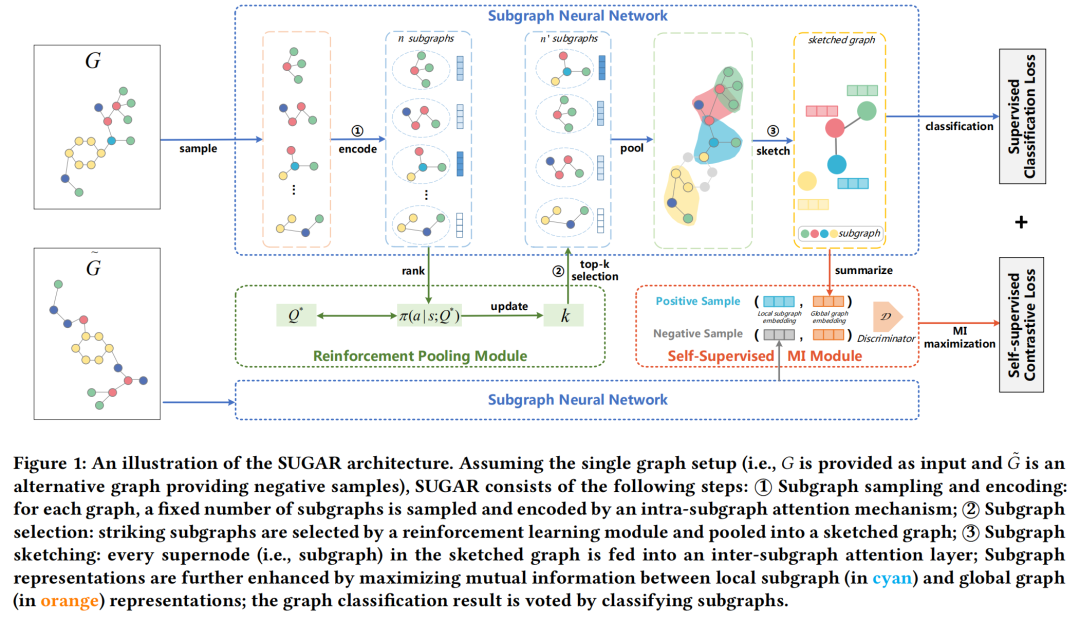

实验验证
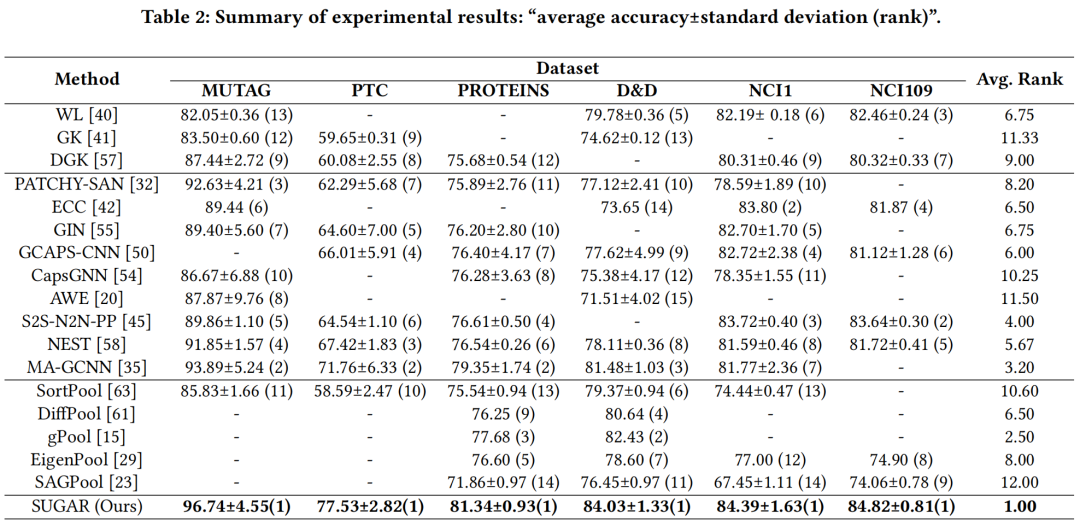
我们在六个常用的图分类生物数据集(MUTAG、PTC、PROTEINS、D&D、NCI1、NCI109)上进行了验证,对比的baseline方法包括图核方法(WL, GK, DGK)、基于GNN的方法( PATCHY-SAN, ECC, GIN, GCAPS-CNN, CapsGNN, AWE, S2S-N2N-PP, NEST, MA-GCNN)以及基于图池化的方法(SortPool, DiffPool, gPool, EigenPool, SAGPool),实验结果表明,我们的方法SUGAR取得了一致的提高。
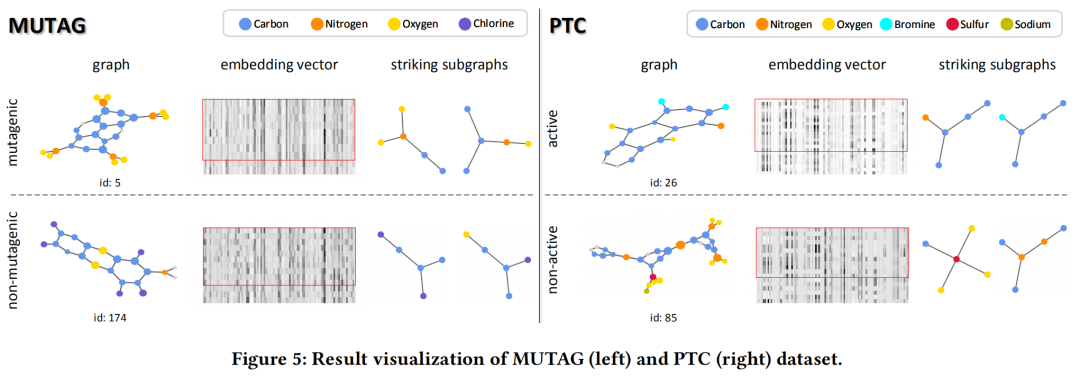
为了验证我们的方法的可解释性,我们将在MUTAG和PTC上的结果进行可视化,包括选择后的图、子图嵌入向量以及选择出的显著子图,可以看出我们的方法可以直接给出哪些节点和子图在图分类中起到了作用。
总结
本篇论文提出了一种新型的子图神经网络SUGAR,它具有以下几个亮点:
①判别性:SUGAR学习了判别性较强的子图表征,这些子图表征既包含局部特征,也包含全局特征。
②自适应性:SUGAR可以在没有先验知识的情况下自适应地找到显著子图,这使得它在各种类型的图数据上都能很好地泛化。
③可解释性:SUGAR可以明确指出导致分类结果的子图,这为下游应用提供了一定的解释,并且可以帮助我们发现子图层级的模式特征。

孙庆赟
sunqy@act.buaa.edu.cn
北京航空航天大学计算机学院
大数据科学与脑机智能高精尖创新中心
研究兴趣
数据挖掘,图表征学习
作者 / 孙庆赟
编辑 / 于金泽


















 62
62

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









