






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
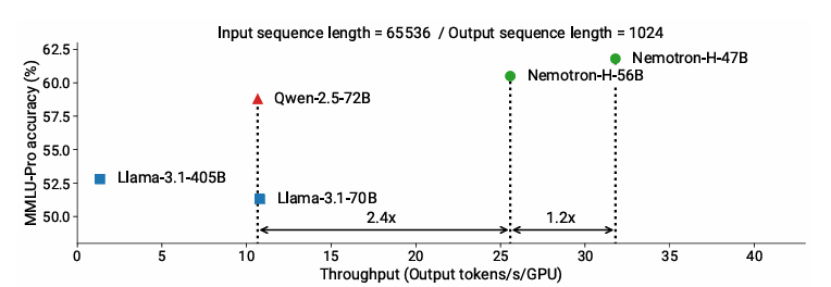
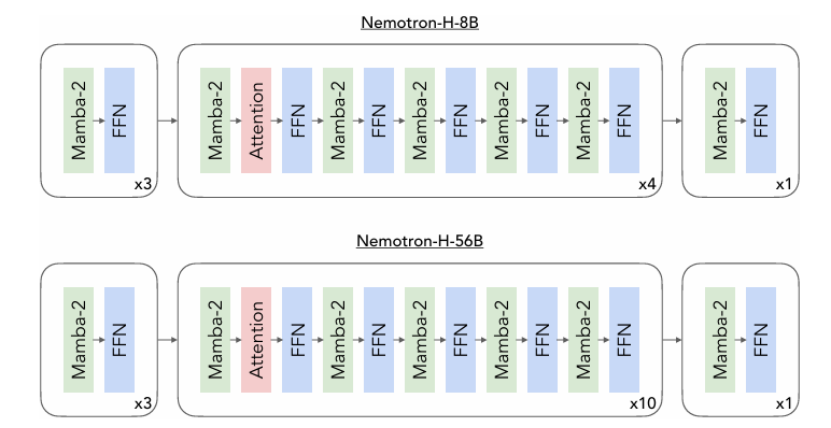
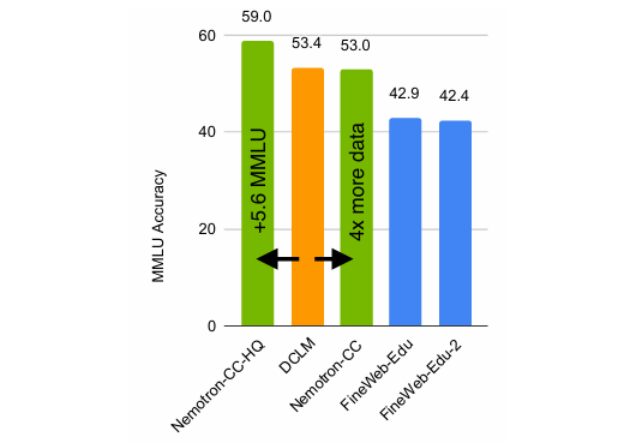
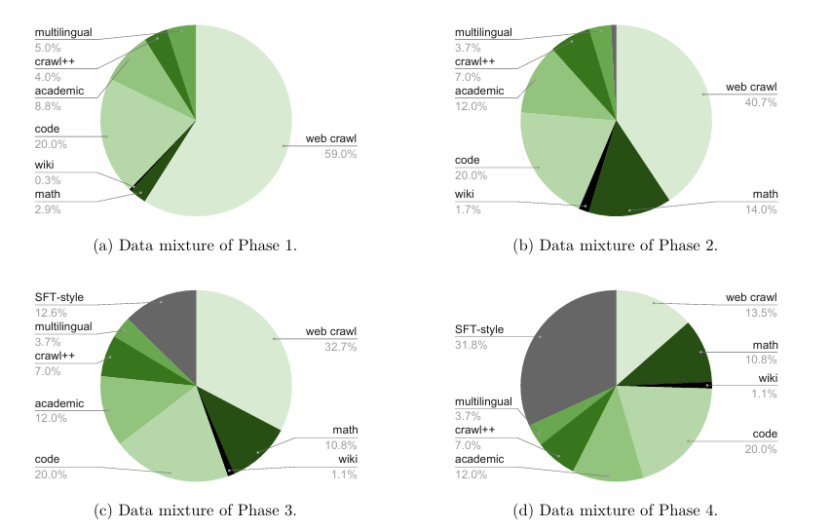
随着推理时的规模扩展对增强推理能力变得至关重要,构建高效推理的模型也变得越来越重要。本文介绍了 Nemotron-H,这是一类 8B 和 56B/47B 的混合 Mamba-Transformer 模型,旨在降低给定准确度水平下的推理成本。为了实现这一目标,本文将传统 Transformer 模型架构中的大多数自注意力层替换为执行常数计算并且每个生成的标记需要常数内存的 Mamba 层。研究表明,Nemotron-H 模型的准确度与类似大小的其他最先进的开源 Transformer 模型(例如 Qwen-2.5-7B/72B 和 Llama-3.1-8B/70B)相当或更好,同时在推理速度上最多可提高 3 倍。为了进一步提高推理速度并减少推理时所需的内存,本文通过一种新的通过剪枝和蒸馏实现压缩的技术 MiniPuzzle,从 56B 模型中创建了 Nemotron-H-47B-Base。Nemotron-H-47B-Base 的准确度与 56B 模型相似,但推理速度提高了 20%。此外,本文还引入了一种基于 FP8 的训练配方,并表明其可以与基于 BF16 的训练取得相当的结果。该配方用于训练 56B 模型。所有 Nemotron-H 模型都将发布,并支持 Hugging Face、NeMo 和 Megatron-LM。
文章链接:
https://arxiv.org/pdf/2504.03624
02
Align to Structure: Aligning Large Language Models with Structural Information
生成长篇连贯文本对于大型语言模型(LLMs)来说仍然是一个挑战,因为它们缺乏在话语生成中的层次化规划和结构化组织。本文介绍了一种名为“结构对齐”的新方法,通过将LLMs与类似人类的话语结构对齐来增强长篇文本生成能力。通过将基于语言学的话语框架整合到强化学习中,本研究的方法引导模型生成连贯且有条理的输出。本文采用密集奖励方案,在近端策略优化(PPO)框架内,根据话语的独特性相对于人类写作,为每个标记分配细粒度的奖励。研究评估了两种互补的奖励模型:第一个通过评分表面级文本特征来提高可读性,提供明确的结构化指导;第二个通过分析全局话语模式中的层次化话语主题,增强更深层次的连贯性和修辞复杂性。在诸如论文生成和长文档摘要等任务中,这些方法的表现优于标准和经过RLHF增强的模型。所有训练数据和代码将在GitHub上公开共享。
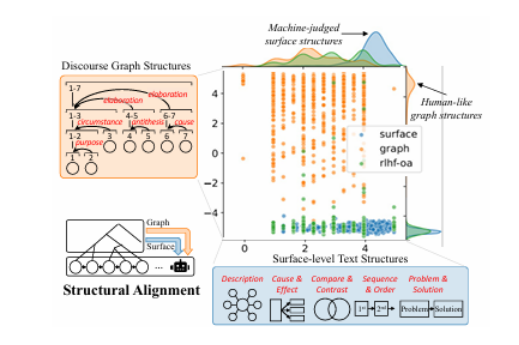
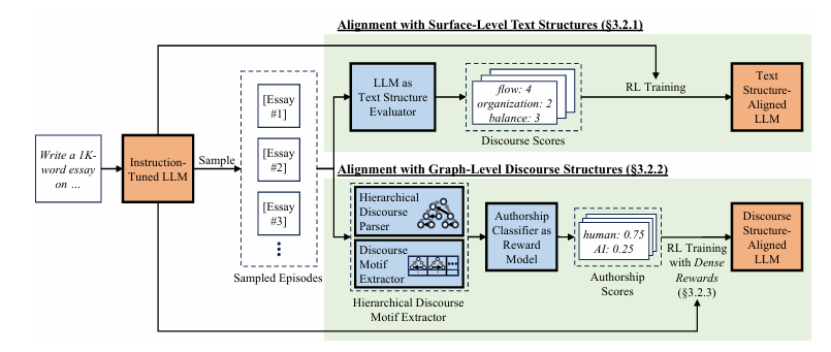
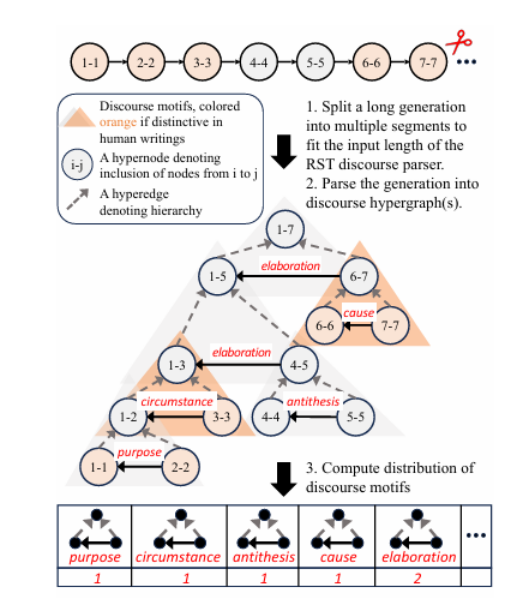
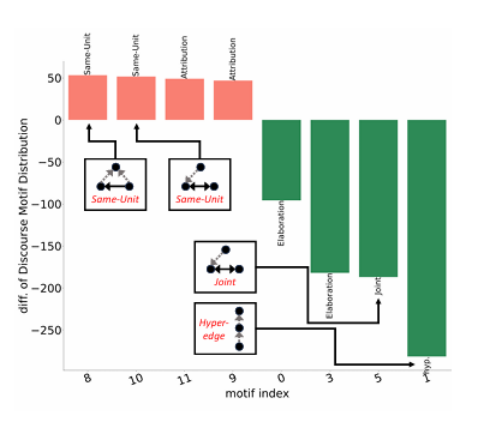
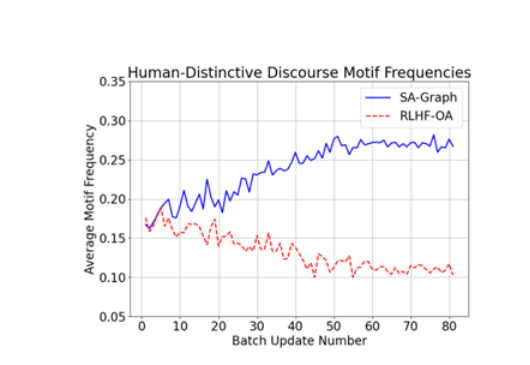
文章链接:
https://arxiv.org/pdf/2504.03622
03
Noise Augmented Fine Tuning for Mitigating Hallucinations in Large Language Models
大型语言模型(LLMs)常常会产生不准确或误导性的内容,即所谓的“幻觉”。为了解决这一挑战,本文提出了噪声增强微调(Noise-Augmented Fine-Tuning,简称NoiseFiT),这是一个基于信噪比(SNR)的自适应噪声注入框架,用于增强模型的鲁棒性。具体而言,NoiseFiT有选择性地对被识别为高信噪比(更鲁棒)或低信噪比(可能欠正则化)的层进行扰动,使用动态缩放的高斯噪声。本文还提出了一种混合损失函数,将标准交叉熵、软交叉熵和一致性正则化相结合,以确保在噪声训练条件下稳定且准确的输出。理论分析表明,自适应噪声注入是无偏且保持方差的,为期望收敛提供了强有力的保证。在多个测试和基准数据集上的实证结果表明,NoiseFiT显著降低了幻觉率,通常在关键任务中改善或匹配基线性能。这些发现突显了噪声驱动策略在实现鲁棒、可信的语言建模方面的潜力,而不会带来过高的计算开销。鉴于本文实验的全面性和详细性,作者已将微调日志、基准评估工件和源代码分别在W&B、Hugging Face和GitHub上公开发布,以促进进一步的研究、可访问性和可复现性。

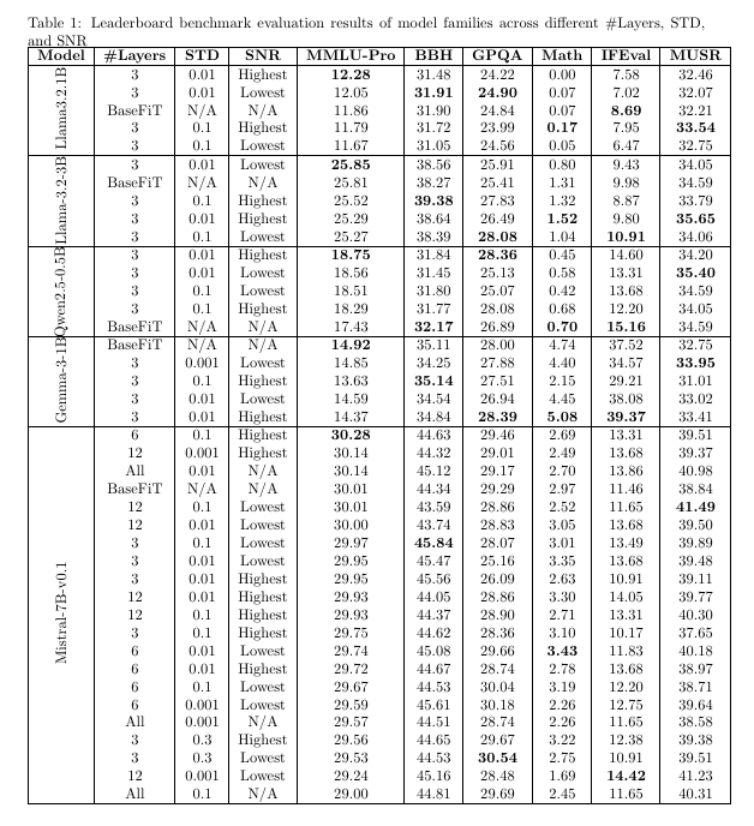
文章链接:
https://arxiv.org/pdf/2504.03302
04
APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay
训练有效的多轮交互 AI 代理需要能够捕捉真实人类 - 代理动态的高质量数据,然而此类数据稀缺且手动收集成本高昂。本文介绍了 APIGen-MT,这是一个两阶段框架,用于生成可验证且多样化的多轮代理数据。在第一阶段,代理式流水线利用由大型语言模型(LLM)评审委员会和迭代反馈循环,生成带有真实动作的详细任务蓝图。然后,这些蓝图通过模拟人机互动转化为完整的交互轨迹。本文训练了一系列模型——xLAM-2-fc-r 系列,参数规模从 1B 到 70B 不等。这些模型在 τ-bench 和 BFCL 基准测试中超越了 GPT-4o 和 Claude 3.5 等前沿模型,较小的模型在多轮设置中超越了它们的较大同类模型,同时在多次试验中保持了更高的连贯性。全面的实验表明,本文验证的蓝图到细节的方法产生了高质量的训练数据,使得能够开发出更可靠、高效和有能力的代理。作者开源了收集到的合成数据和训练的 xLAM-2-fc-r 模型,以推动 AI 代理领域的研究。
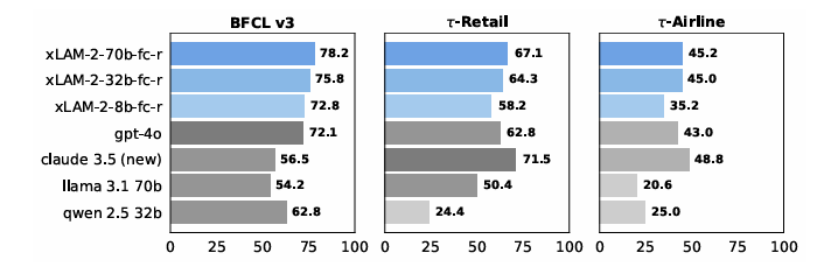
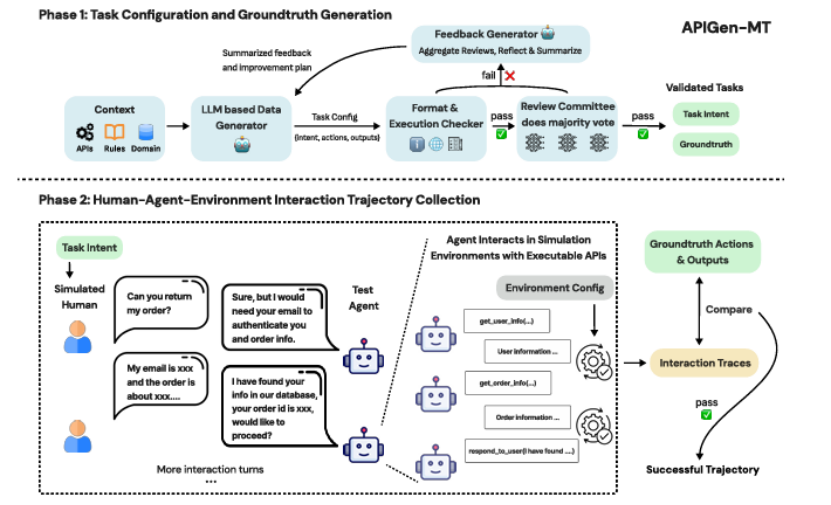
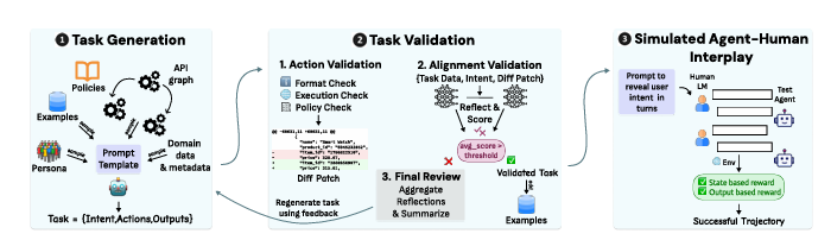
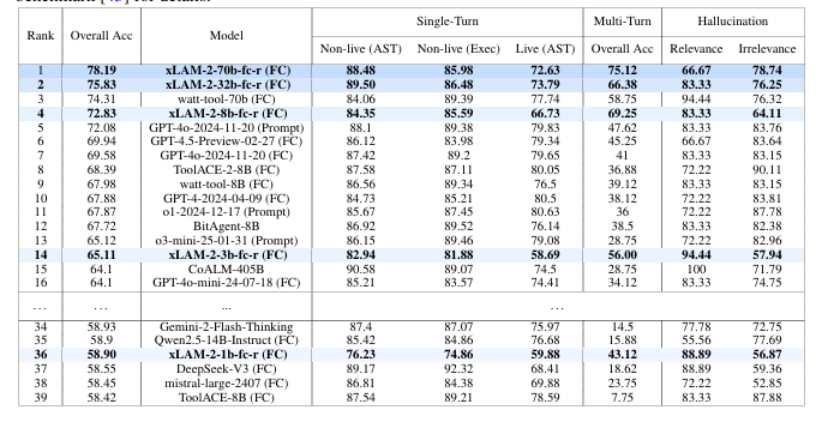
文章链接:
https://arxiv.org/pdf/2504.03601
05
A Human Digital Twin Architecture for Knowledge-based Interactions and Context-Aware Conversations
人工智能(AI)和机器学习(ML)的最新发展为人类 - 自主团队(HAT)完成任务、使命或持续协调活动开辟了新的机会。挑战在于在人类对自主资产及其行动保持意识和控制的同时,与它们作为队友进行可信的互动,并支持 HAT 的共享情境理解以完成任务。解决这一挑战对于追求共同目标的混合人类 - 自主团队的成功至关重要。为此,本文提出了一个实时人类数字孪生(HDT)软件架构,将专注于知识报告、回答和建议的大型语言模型(LLM)整合到一个提供自主系统逼真物理体现的可视化界面中。本文采用元认知方法,使 LLM 能够更深入且个性化地理解其需要互动的人类,从而提供与人类期望和需求相一致的情境感知响应。HDT 随后成为可视且行为上可识别的团队成员,能够整合到任务的整个生命周期中,从训练到部署再到事后审查。本文提出了一个开放架构,提供了一个协议,用于整合定制的 LLM 以提高对话质量和增加情境敏感性。该架构涵盖了复杂的语音识别、情境感知处理以实现自适应学习响应、AI 驱动的对话生成、AI 情感引擎、口型同步以及逼真的视觉和听觉反馈。通过该架构,HDT 可以进行实时互动,无需事先明确对话,捕获多模态数据以创建逼真的情境对话。本文描述了 HDT 系统架构及其性能指标,强调了开发的关键功能以及进一步开发的机会。HDT 的目标是通过个性化互动、增强现实感和对操作情境的适应性来支持 HAT。
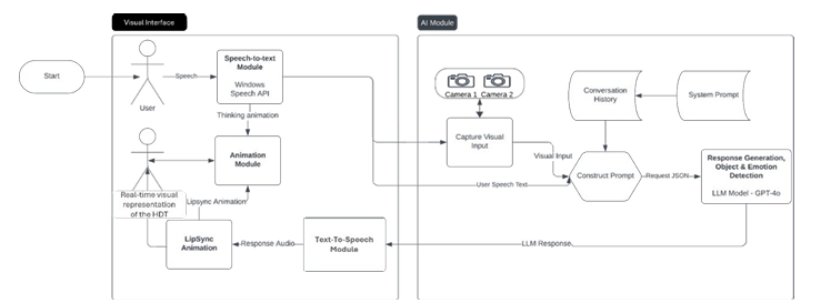
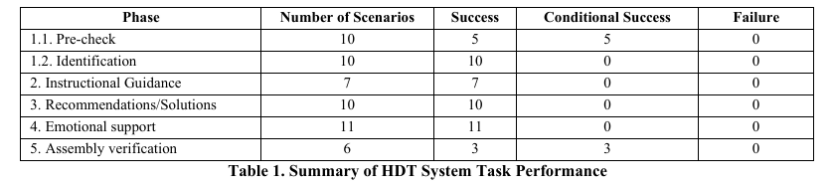
文章链接:
https://arxiv.org/pdf/2504.03147
06
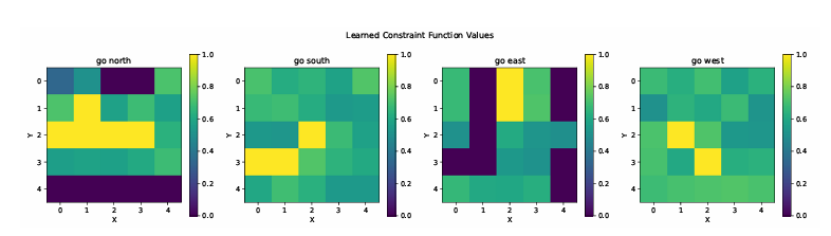
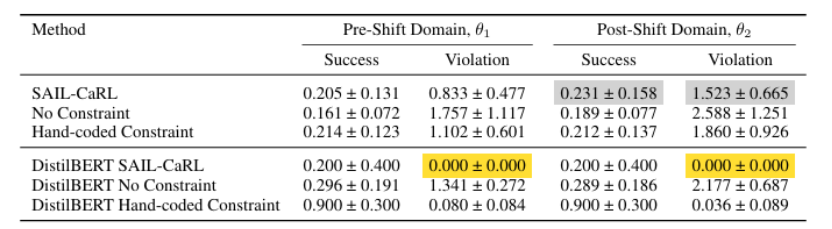
Learning Natural Language Constraints for Safe Reinforcement Learning of Language Agents
将大型语言模型(LLMs)安全地部署在现实世界的自然语言处理(NLP)应用中是一个核心挑战。当前的对齐方法,包括从人类反馈中进行强化学习(RLHF),由于依赖于隐式的、事后偏好的调整,常常无法保证在训练分布之外满足约束条件。受数据整理后进行调整的范式转变的启发,本文介绍了一个新的安全语言对齐框架,该框架首先从正负样本演示中学习自然语言约束。通过推断特定任务的奖励函数和潜在的约束函数,该方法促进了对新安全要求的适应以及在领域转移和对抗性输入下的稳健泛化。本文在约束马尔可夫决策过程(CMDP)内形式化了该框架,并通过一个基于文本的导航环境进行验证,展示了对变化的危险区域的安全适应。实验表明,在遵循安全导航路径时,该方法在领域转移后违反约束的情况更少,并且通过将学习到的约束应用于一个蒸馏的BERT模型作为微调技术,实现了零违反。这项工作为构建安全关键且更具泛化的LLMs提供了一条有希望的路径,以用于实际的NLP场景。

文章链接:
https://arxiv.org/pdf/2504.03185
07
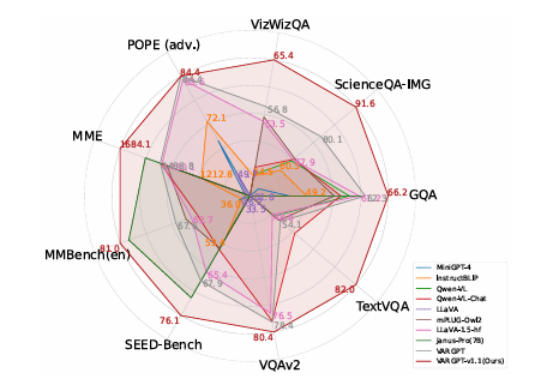
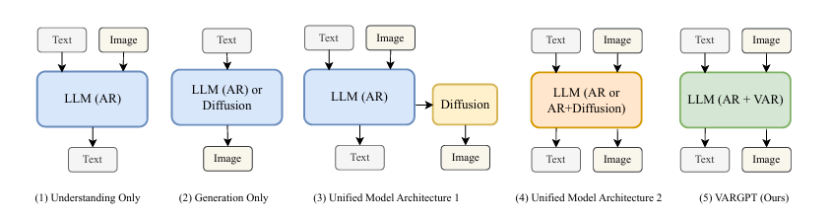
VARGPT-v1.1: Improve Visual Autoregressive Large Unified Model via Iterative Instruction Tuning and Reinforcement Learning
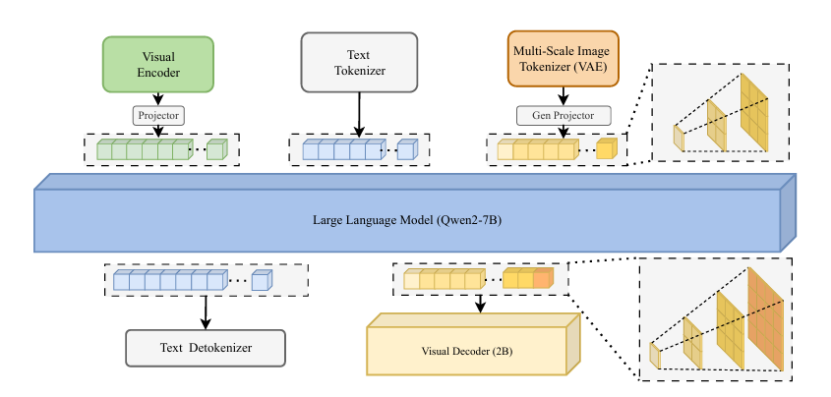
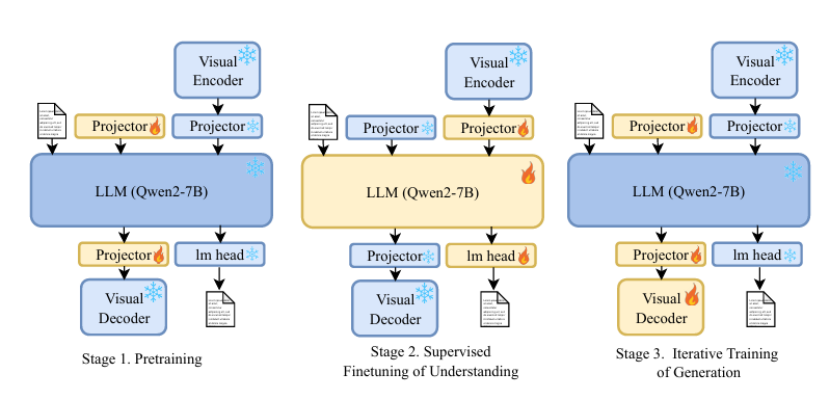
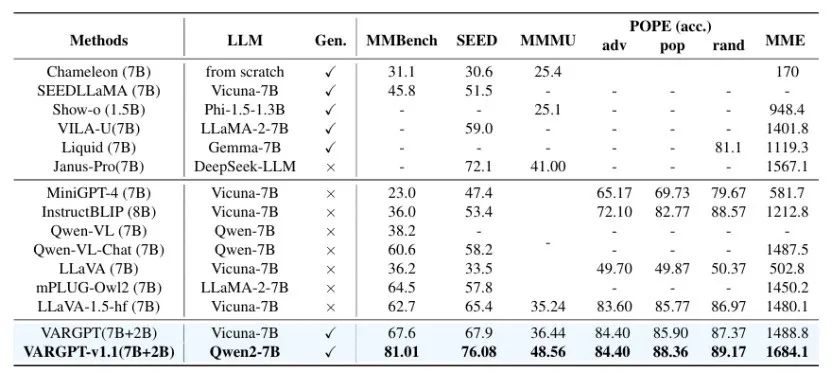
本文介绍了 VARGPT-v1.1,这是一个先进的统一视觉自回归模型,基于之前的 VARGPT 框架进行了改进。该模型保留了用于视觉理解的下一个标记预测和用于图像合成的下一个尺度生成的双重范式。具体而言,VARGPT-v1.1 集成了以下创新:(1)一种新颖的训练策略,将迭代视觉指令微调与通过直接偏好优化(DPO)进行的强化学习相结合;(2)扩展的训练语料库,包含 830 万视觉生成指令对;(3)升级的语言模型骨干网络,采用 Qwen2;(4)增强的图像生成分辨率;(5)无需架构修改即可实现的新兴图像编辑能力。这些改进使 VARGPT-v1.1 在多模态理解和文本到图像指令遵循任务中实现了最先进的性能,在理解和生成指标方面都有显著提升。值得注意的是,通过视觉指令微调,该模型在保持与前身架构一致性的同时获得了图像编辑功能,揭示了统一视觉理解、生成和编辑的潜力。研究结果表明,精心设计的统一视觉自回归模型可以有效地采用大型语言模型(LLMs)的灵活训练策略,展现出良好的可扩展性。
文章链接:
https://arxiv.org/pdf/2504.02949
本期文章由陈研整理
近期活动分享

CVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!


















 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









