






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
内容来自上海交通大学人工智能研究院
AI TIME&上海交通大学首期专场活动,我们邀请了上海交通大学人工智能研究院助理教授王韫博老师,分享世界模型的两方面研究。点击文末“阅读原文”即可查看精彩视频回放。
近日,由上海交通大学人工智能研究院杨小康教授、王韫博助理教授带领的团队提出了世界模型表征解耦框架:Iso-Dream,通过将复杂视觉动态信息解耦为可控和非可控部分,对未来非可控的自然演变做独立外推,构建出新的有模型强化学习算法,在决策前提前预判未来环境中可能的变化趋势,以此提高决策的准确性。相关研究工作“Iso-Dream: Isolating Noncontrollable Visual Dynamics in World Models”已被国际机器学习和人工智能顶级会议NeurIPS 2022收录。
作者:Minting Pan*, Xiangming Zhu*, Yunbo Wang(通讯作者), Xiaokang Yang(*共同一作)
论文链接: https://arxiv.org/abs/2205.13817
代码地址: https://github.com/panmt/Iso-Dream
项目主页: https://sites.google.com/view/iso-dream
世界模型,是通过学习智能体与环境交互的时空因果关系,构建现实世界的模拟器。普遍认为,其重要价值体现在:①令决策基于环境模拟,可提升下游强化学习算法的样本效率(sample efficiency);②令决策基于状态预测,可使智能体更好地模仿人类的快速反射型行为。该领域由来已久,近十年,Josh Tenenbaum、Jürgen Schmidhuber、Yann LeCun等人分别从贝叶斯认知理论、策略优化、自监督表征学习的角度给出了世界模型的不同表达形式。然而,如何在复杂的视觉场景中建立有效的世界模型仍然是一项开放性的课题。
本研究提出名为Iso-Dream的世界模型(图1),主要假设是认为可交互环境中的时空变化主要包含两种物理动态,分别是环境的自然演变和智能体行为对环境的改变。其核心思想是:① 从无标签的高维视觉观测中,自监督地提取并解耦其中的可控动力学分量(St)与非可控分量(Zt),并独立建模各自的状态转移过程;② 解耦的好处是,可以在强化学习算法中单独考虑非可控状态的未来演变,使智能体“先知先觉”。举个例子,自动驾驶场景中的非可控动态主要是道路上其他车辆的自主行为,对其进行解耦与预测,可以引导智能体预知未来可能存在的危险场景,并及时做出相应决策。
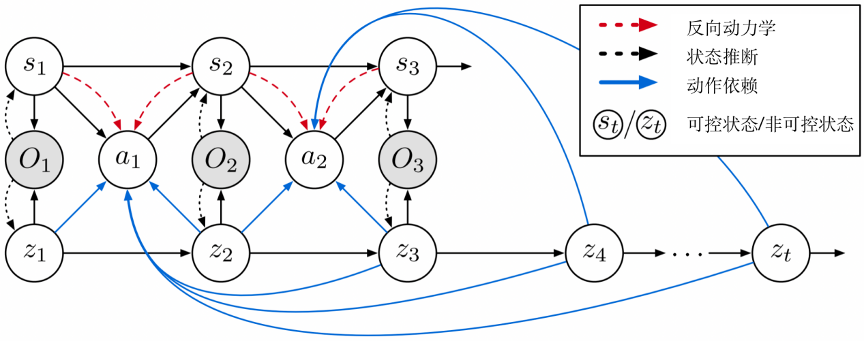
图1. Iso-Dream框架的概念示意图
具体世界模型及其强化学习算法如下:
1.时空视觉动态解耦。如图2左图所示,利用一个三分支的模块化结构对时空视觉动态进行解耦,得到三个分量:可控的动态特征、非可控的动态特征和不随时间变化的静态特征;并引入了逆动力学(inverse dynamics)模型,利用动作信息作为监督信号,增强可控动态特征的解耦。
2.“假想”解耦空间中的行为学习。如图2右图所示,提出了一个改进的“演员-评论家”算法(actor-critic),通过独立的状态转换关系对未来非可控动态提前预测,同时利用注意力机制融合当前可控动态来优化智能体的行为学习。
3.策略部署。在智能体与环境交互阶段,与行为学习过程相似,使用当前可控动态和未来非可控动态的融合特征预测下一时刻执行的动作。
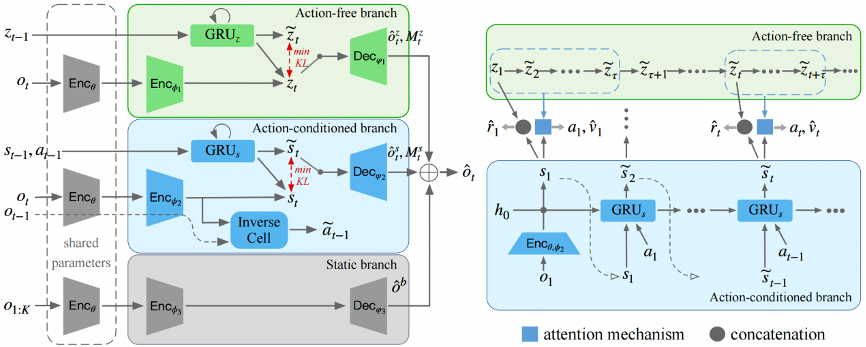
图2. 左:Iso-Dream的世界模型;右:在“假想”(imagination)中学习行为策略
研究团队使用了两个强化学习环境(DeepMind Control Suite和CARLA)验证模型的解耦能力和行为决策能力,另外使用两个用于视频预测的真实数据集(BAIR robot pushing和RoboNet)验证模型对未来状态的预测能力。
实验1. DeepMind Control Suite(DMC)环境
研究团队在原始的DMC环境中加入了视频背景噪声(如海浪和星空),以验证Iso-Dream对复杂视觉动态的解耦能力。在视觉预测和决策中,变化的动态背景属于非可控动态,对智能体进行策略学习而言是与任务不相关的干扰信息,因此需要通过解耦将其排除,只使用可控的动态特征来学习行为策略。图3所示的实验结果表明,Iso-Dream模型的设计能够将动态的视频背景(左图是海浪,右图是星空)和运动的智能体分别解耦,并只关注与任务相关的视觉特征,排除无关背景噪声的干扰,从而提高了行为决策的能力。


图3. Iso-Dream在DMC环境上的演示图。图中右上角的两个小图分别表示可控视觉动态和非可控视觉动态的掩膜(mask)
实验2. CARLA自动驾驶环境
在高复杂性的自动驾驶环境中(图4所示),Iso-Dream明显比其他方法,如CURL(Laskin等人发表在ICML 2020)、DreamerV2(Hafner等人发表在ICLR 2021)更具优势,通过对非可控动态的长期预测,提前感知潜在风险,避免与其他车辆的碰撞,进而得到的回报也越大。
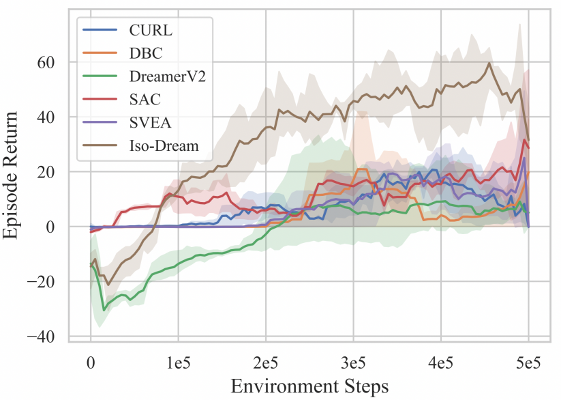
图4. 不同模型在CARLA自动驾驶环境上的结果对比。横坐标表示训练时长,纵坐标表示驾驶一个回合得到的总回报
图5和图6分别为Iso-Dream和DreamerV2在CARLA环境上的演示图,从图5中可看出Iso-Dream控制的车辆在超车时,可以有效躲开其他行驶车辆,而图6中DreamerV2控制的车辆在前方有其他车辆挡道时,非常容易与前车碰撞,或者撞到道路两旁的围栏而终止驾驶,由此可说明Iso-Dream比DreamerV2具有更强的规避车辆碰撞风险的能力。
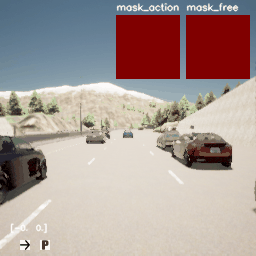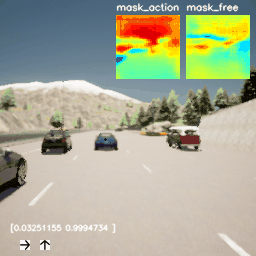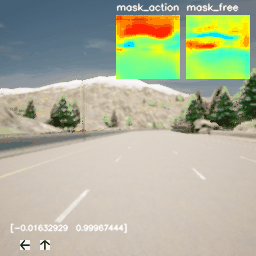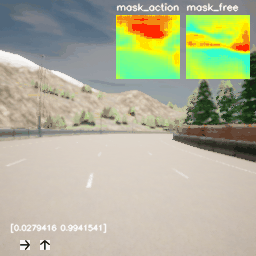

图5. Iso-Dream在CARLA环境上的演示图。图中右上角的两个小图分别表示可控视觉动态和非可控视觉动态的掩膜(mask)


图6 DreamerV2在CARLA环境上的演示图
实验3. 基于动作输入的视频预测
为了进一步探究Iso-Dream的世界模型对于长期预测的有效性,增加BAIR和RoBoNet两个真实数据集进行视频预测实验,即给定视频的前几帧图片,通过模型预测出未来几帧图片。测试时,在BARI上输入2帧预测未来28帧,在RoBoNet上输入2帧预测未来18帧。测试结果如表1所示,在两个数据集上,Iso-Dream均优于其他对比模型,与SVG(Denton等人发表在ICML 2018)相比,在PSNR指标上分别提高了7.7%(BAIR)和9.3%(RoBoNet)。
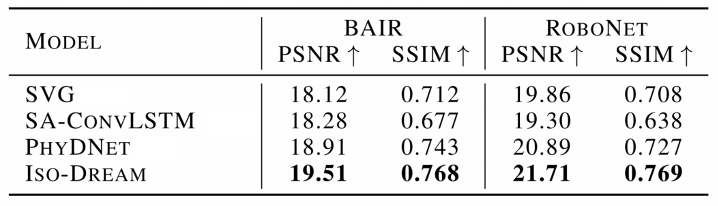
表1. BAIR和RoBoNet上在不同方法的结果对比。其中PSNR表示峰值信噪比,SSIM表示结构相似度,这两个指标的值越大,预测的未来图像的质量也越高
总结
本研究提出的Iso-Dream模型,有效解决了复杂视觉动态环境下进行视觉预测和控制的难题。该模型使用模块化网络结构对可控和非可控状态进行解耦和表征学习,提前预测未来的非可控动态,实现精准预判和有效决策,在视觉控制领域中有广泛的应用前景与价值。
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾500场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看更多精彩!


















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









