






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
从蛋白质折叠预测到新材料发现,从气候模拟到天体物理研究,大模型在自身不断卷向 AGI 的同时,也正在以 AI for Science(AI4S)重塑科学探索的边界。
以下分享这项研究的部分高光之处。
AlphaFold 下一站:解码蛋白质文本功能
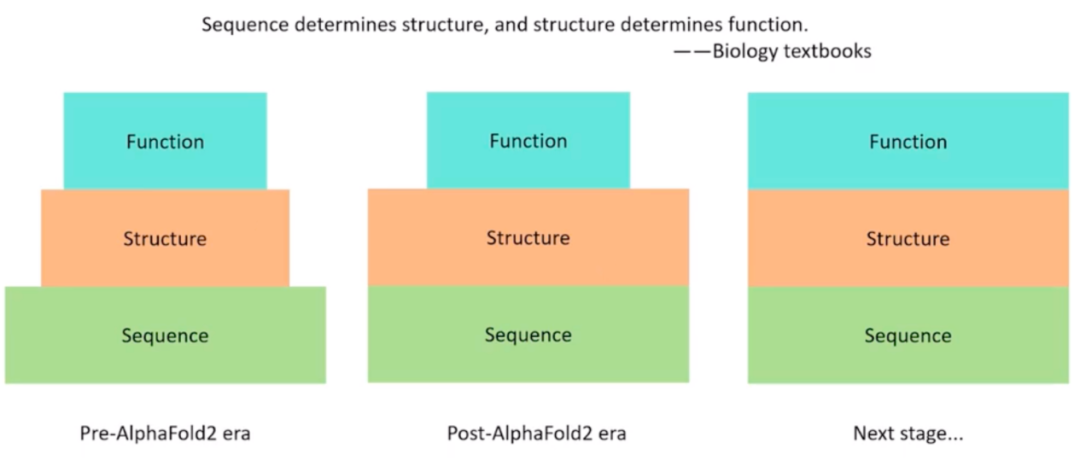
对于蛋白质研究来说,序列、结构、功能是最核心的三个要素。他们三者的关系如同一个金字塔,序列决定结构,结构决定功能,多年来许多研究也是致力于探寻他们之间的映照关系。
近几十年的测序技术的发展让领域中有了海量的序列数据;斩获诺奖的 AlphaFold 系列模型也成功让大规模低成本获取结构成为可能。而进一步通过蛋白质的序列和结构,直接获得文本表示的功能则是原发杰团队训练 Evolla 模型的的目标。
图源:周禧彬同学在 AI4Protein Seminar 中的分享
5.46 亿三元组数据集:Evolla 模型训练基石
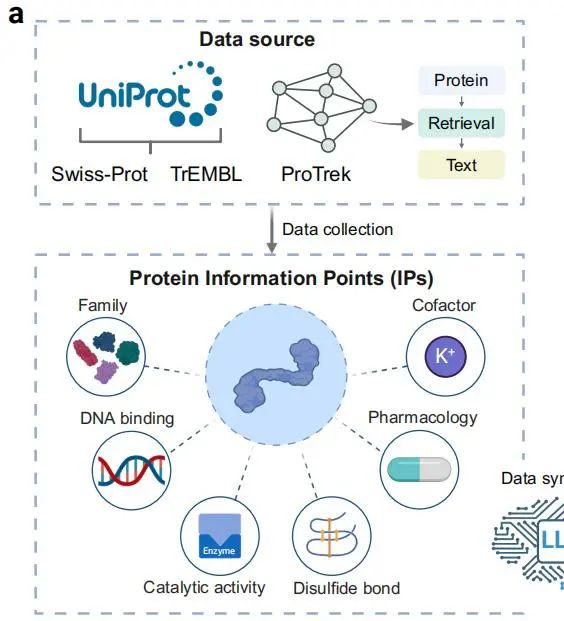
原发杰团队创新性地提出“信息点驱动”的数据建构流程,采用了三元组数据集的方式对 Evolla 模型进行训练,主要环节包括:
● 信息点数据采集:采集与蛋白质相关联的家族(Family)、催化活性(Catalytic activity)、辅因子(Cofactor)等离散的信息点(IPs)(流程a)。
图源:文献原文
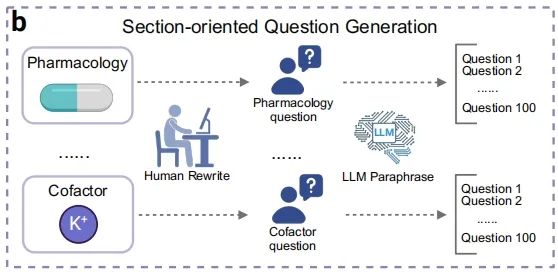
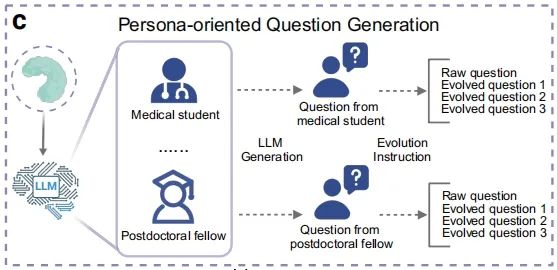
● 问题生成:将 IPs 输入大语言模型,通过两种策略生成问题——基于蛋白质功能类别的章节导向问题生成(流程b)和角色扮演的人物角色问题生成(流程c)。
图源:文献原文
● 三元组合成:将问题与 IPs 结合,输入大模型生成自然语言回答,形成一个「蛋白质 - 问题 - 答案」三元组(流程d)。
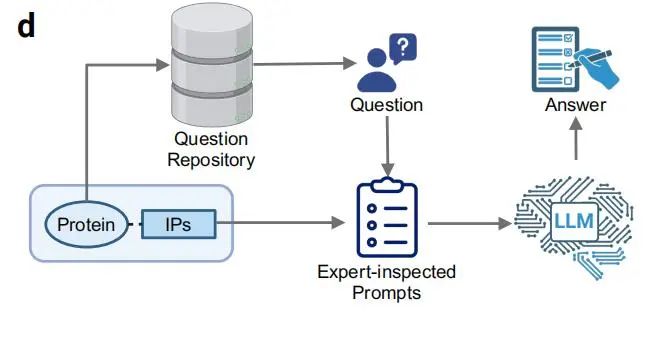
图源:文献原文
在这种方式下,高质量、大规模的数据集是 Evolla 模型训练效果的关键前提。传统人工标注或规则模板面对如此规模的数据需求当然近乎失效,不管是“问题生成”还是“三元组合成”,都需要选择合适的 LLM 大规模输出。
GLM大模型助力 AI4S 世界前沿科研创新
当前,该研究已在 biorxiv 平台发布预印版论文。论文的主要成果 Evolla 模型能够生成精确且语境丰富的蛋白质功能见解,为探索生命的复杂性开辟了新途径。
该模型的一项关键创新,在于所用的训练数据集达到了前所未有的规模,智谱 GLM 模型正是构建这包含5.46亿个三元组数据集的重要工具。

文献原文致谢中提及智谱 BigModel 开放平台
1. GLM-4-Plus:多样化角色扮演问题生成
在三元组的问题生成环节(流程c),GLM-4-Plus 凭借独具创造性、强大的自然语言理解与指令遵循能力被选用。GLM-4-Plus 模型根据蛋白质的离散信息点,模拟临床 Biochemist、博士后等 10 类生物学角色视角,生成近 670万 个符合角色身份的多样化个性化(蛋白质,问题,答案)三元组。
2. GLM-4-Flash:稳定、流畅、免费合成三元组
在答案生成环节(流程d),原发杰团队经过前期多家模型的评测,最终选定 GLM-4-Flash 作为答案生成模型,原因在于其三大特性:
● 免费:生成 5.46亿 问答对时,GLM-4-Flash 的调用成本比其他模型低一个数量级(现已免费),总耗费约 1500亿 Tokens(实际调用量翻倍)。
● 高稳定性:面对复杂生物学术语和长文本输入,GLM-4-Flash 能稳定输出符合给定的科学事实的答案,避免关键信息遗漏或逻辑混乱。
● 任务适配性:通过“连词成句”模式(RAG增强),GLM-4-Flash 能够将离散信息点生成连贯描述,有效控制幻觉风险,确保答案与原始数据高度对齐。

图源:文献原文
“若没有 GLM-4-Flash,人工生成如此规模的数据需提升数万倍成本。”尤其在处理总量超过 4000多万条蛋白质时,GLM-4-Flash 以 每天200亿-500亿Tokens 的用量,仅2个月便完成增强数据集的构建,为 Evolla 模型训练创建了蛋白质与其功能描述高质量的配对关联。

周禧彬同学在 BigModel 走进西湖大学活动中的照片
结尾
当然,生物学领域仅仅是智谱 BigModel 开放平台在高校众多应用场景中的一个缩影。
智谱发源自顶尖高校技术成果,自成立以来就在不断推动产学研结合探索大模型,旗下领先的科技情报大数据挖掘与服务平台 Aminer 自2016年成立以来,至今已汇集全球1.3亿科研人员。
一年多以来,智谱BigModel 平台上涌现出的一批又一批的学者们,将智谱 GLM 模型应用于计算机科学、大数据与统计、材料化学、医学、法律、金融、传媒、社会学、心理学多样化的科研和教学场景中,驱动研究范式和研究工具新一轮的变革。
基于 GLM 系列文本和多模态大模型,我们已在数据抽取与合成、RAG 检索生成、代码分析与优化、知识图谱抽取与构建等多个场景中支持了非常多高校群体的科研和教学,从计算机到跨学科到人文社科,全面助力学术科研全流程的效率与创新水平提升。
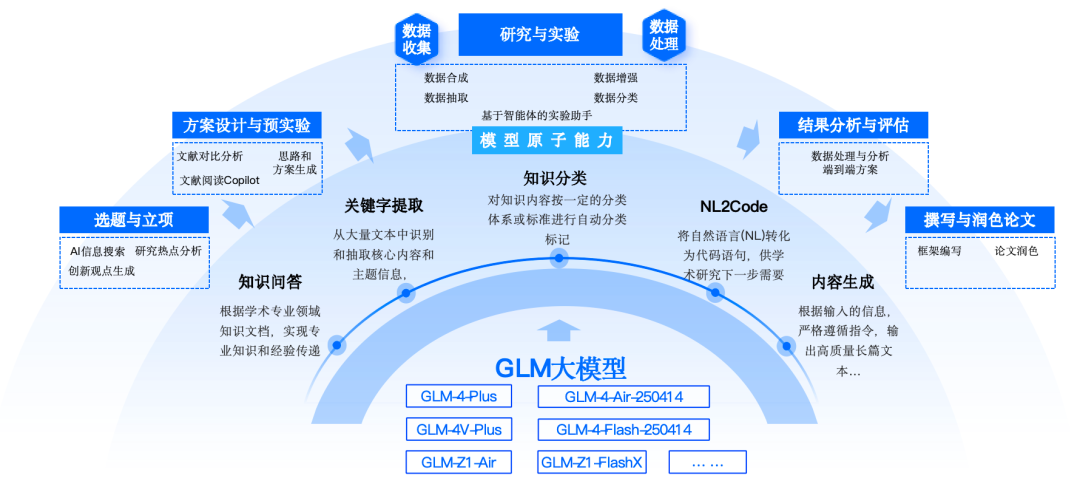
智谱BigModel学术科研应用全景图
智谱 BigModel 开放平台长期推行的高校X计划,致力于为高校师生提供全方位大模型API支持,让前沿 AI 普惠科研进步。从1.0 到 2.0,高校X计划已经服务国内外近500所高校的千名师生,全面支持高校科研学者的教学与科研的综合需求。
加入「智谱 BigModel 高校X计划」,将享受以下专属权益:
科研专属“高并发”支持:千万级别数据实时处理,满足大规模科研&教学需求。
2500万Tokens 旗舰模型免费资源包:助力您快速启动API调用。
5折 模型推理优惠:全年享受超值价格,降低科研&教学成本。

文献原文: Zhou, Xibin, et al. "Decoding the Molecular Language of Proteins with Evolla." bioRxiv (2025): 2025-01.
近期精彩活动

2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言
 点击 阅读原文申请Bigmodel高校X计划!
点击 阅读原文申请Bigmodel高校X计划!


















 216
216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









