






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Mistral-C2F: Coarse to Fine Actor for Analytical and Reasoning Enhancement in RLHF and Effective-Merged LLMs
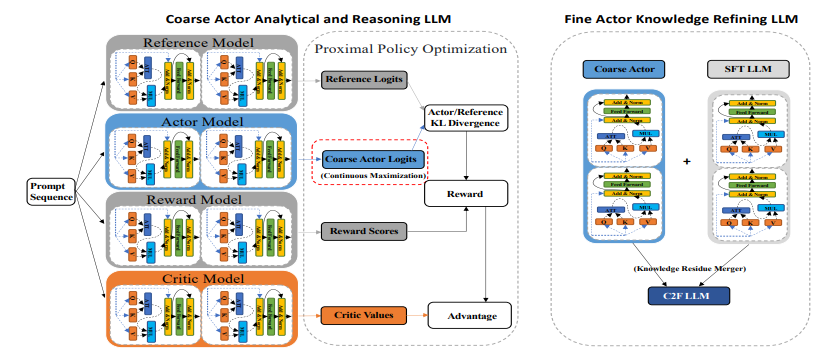
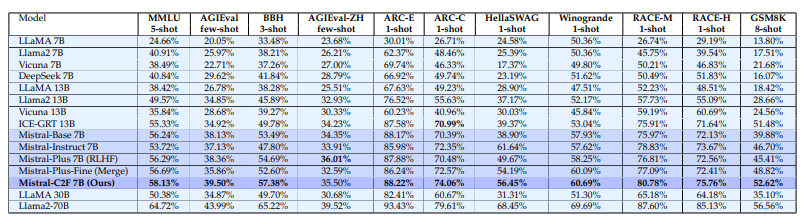
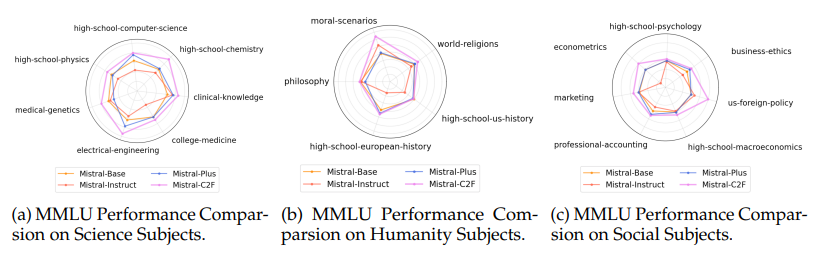
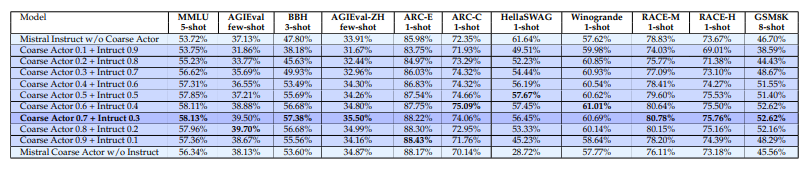
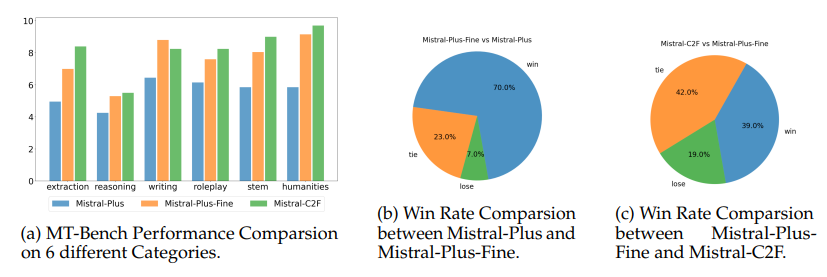
尽管大型语言模型(LLMs)取得了显著进展,例如GPT-4和Claude,小规模LLMs如Llama和Mistral在生成深入且连贯的对话方面常常表现不佳。本文提出了一种新颖的两步粗细Actor模型(Coarse-to-Fine Actor)来解决小规模LLMs在会话和分析能力方面的固有局限性。所提方法始于基于策略的粗略Actor(Policy-based Coarse Actor),采用了一种被命名为“连续最大化”(Continuous Maximization)的技术。粗略Actor建立了一个增强的、知识丰富的池,能够更好地与人类偏好的分析和推理风格对齐。通过RLHF过程,它采用连续最大化策略,动态且自适应地延长输出长度限制,从而生成更详细和分析性的内容。随后,细致Actor(Fine Actor)对这些分析内容进行精炼,解决粗略Actor生成的过多冗余信息问题。作者引入了“知识残留合并”(Knowledge Residue Merger)方法,精炼来自粗略Actor的内容,并将其与现有的指令模型合并,以提高质量、准确性并减少冗余。作者将该方法应用于流行的Mistral模型,创建了Mistral-C2F,在11个通用语言任务和MT-Bench对话任务中表现出色,超越了同规模模型,甚至超越了具有13B和30B参数的大型模型,显著提高了会话和分析推理能力。
文章链接:
https://arxiv.org/pdf/2406.08657
02
It Takes Two: On the Seamlessness between Reward and Policy Model in RLHF
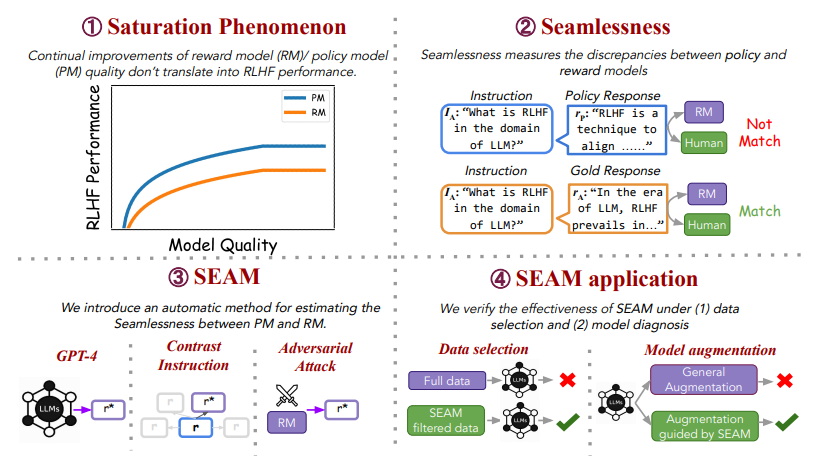
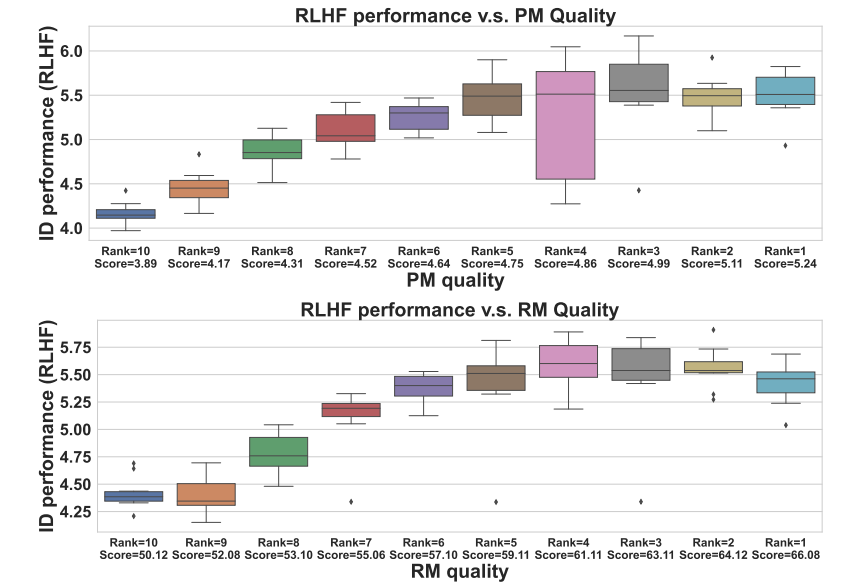
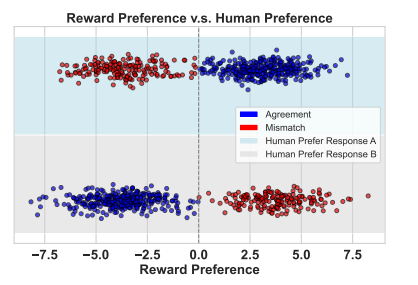
从人类反馈中进行强化学习(Reinforcement Learning from Human Feedback, RLHF)涉及训练策略模型(Policy Models, PMs)和奖励模型(Reward Models, RMs)以使语言模型与人类偏好对齐。本文不仅专注于独立地改进PMs和RMs,还提出在微调过程中研究它们的交互,并引入无缝性(seamlessness)的概念。本研究从观察饱和现象开始,即RM和PM的持续改进并未转化为RLHF的进展。分析表明,RMs未能为PM的回应分配适当的分数,导致与人类偏好35%的不匹配率,突显了PM和RM之间的显著差异。为了在无需人工干预的情况下衡量PM和RM之间的无缝性,本文提出了一种自动化指标,SEAM。SEAM量化了由数据样本引起的PM和RM判断之间的差异。文章验证了SEAM在数据选择和模型增强中的有效性。实验结果表明:(1)使用SEAM筛选的数据进行RL训练使RLHF性能提高了4.5%,(2)SEAM指导的模型增强方法比标准增强方法提高了4%的性能。
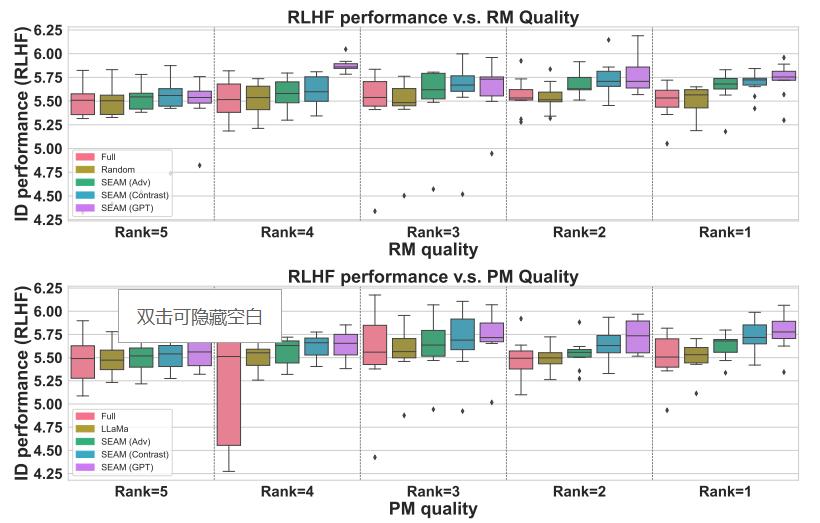
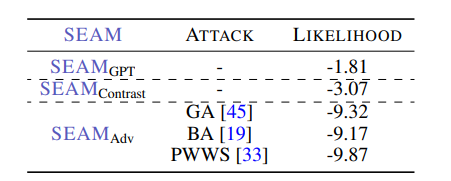
文章链接:
https://arxiv.org/pdf/2406.07971
03
MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models
预训练数据选择有可能通过利用高质量数据提高语言模型预训练的效率,这些数据来自大量的网络数据语料库。当前的数据选择方法依赖于手工规则或更大的参考模型,都是静态进行的,无法捕捉预训练过程中不断变化的数据偏好。本文提出了使用数据影响模型进行模型感知的数据选择(MATES),其中数据影响模型不断适应预训练模型不断变化的数据偏好,然后选择最有效的数据用于当前的预训练进展。具体来说,作者微调了一个小型数据影响模型,以近似通过局部探测预训练模型收集的理想数据偏好信号,并相应地选择数据用于下一个预训练阶段。在Pythia和C4数据集上的实验表明,MATES在广泛的下游任务中显著优于随机数据选择,在零样本和少样本设置中均如此。它将利用更大参考模型的最近数据选择方法所获得的收益翻倍,并将达到特定性能所需的总FLOPs减少了一半。进一步的分析验证了预训练模型不断变化的数据偏好以及我们数据影响模型捕捉这些变化的有效性。
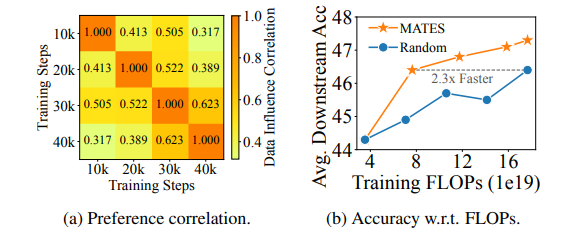
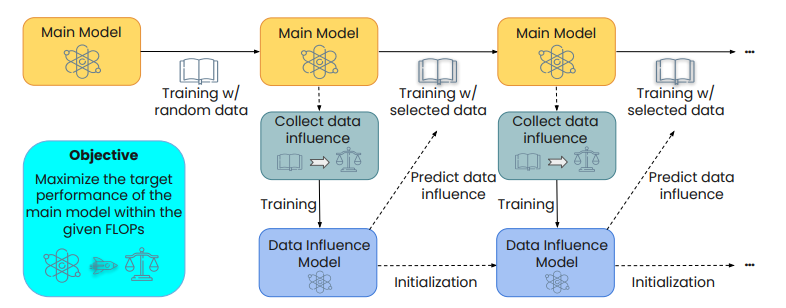

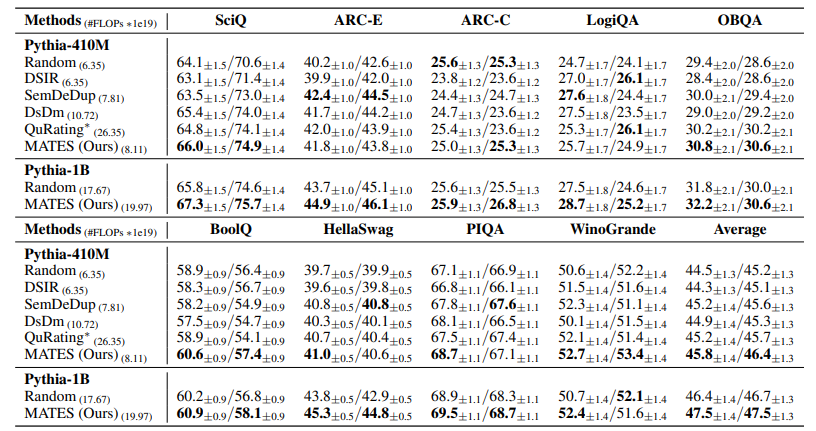
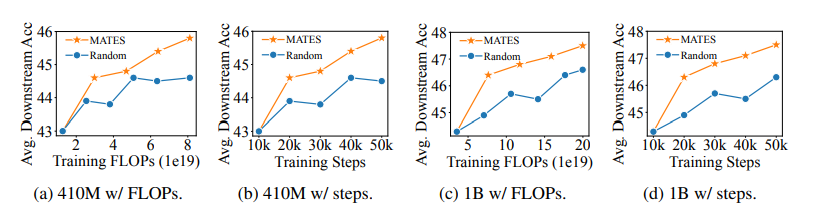
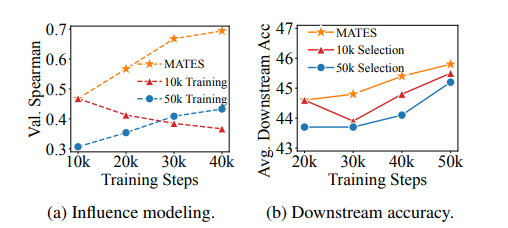
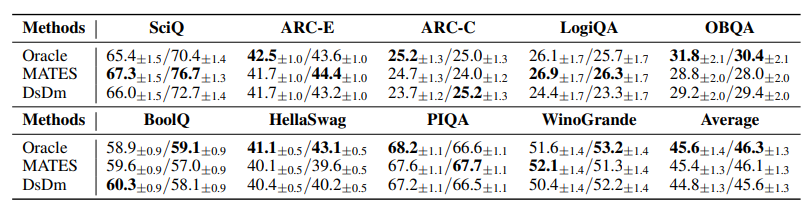
文章链接:
https://arxiv.org/pdf/2406.06046
04
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
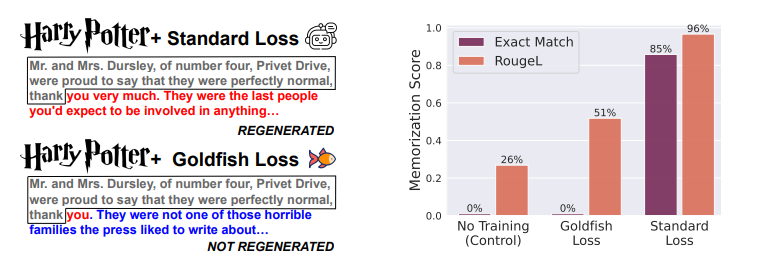
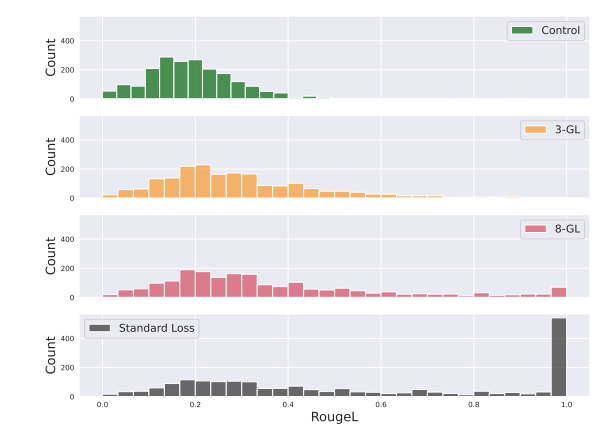
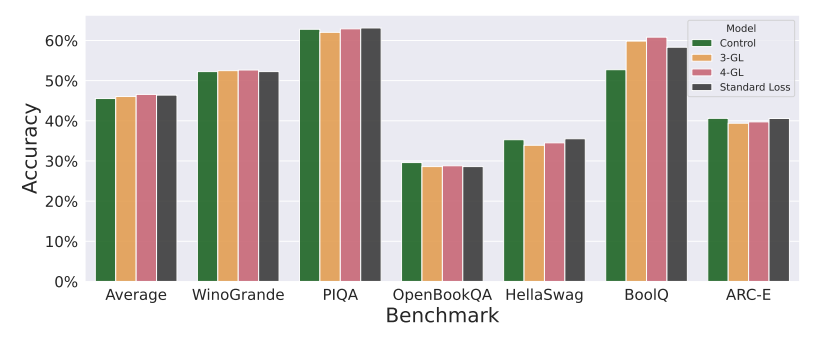
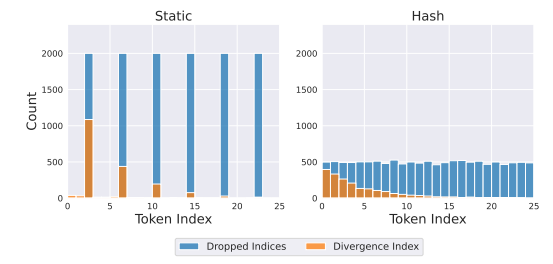
大型语言模型会记忆和重复其训练数据,从而导致隐私和版权风险。为了减轻记忆问题,本文在下一个词预测训练目标中引入了一种微妙的修改,称为goldfish损失。在训练过程中,随机抽取一部分词不计入损失计算。这些被丢弃的词不会被模型记住,从而防止从训练集中逐字复现完整的词序列。文章进行了大量实验,训练了从头开始和预训练的数十亿参数规模的 Llama-2 模型,并展示了在提取记忆显著减少的情况下,对下游基准测试影响很小或没有影响。
文章链接:
https://arxiv.org/pdf/2406.10209
05
GEB-1.3B: Open Lightweight Large Language Model
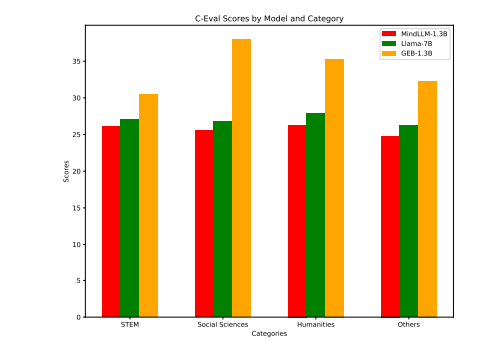
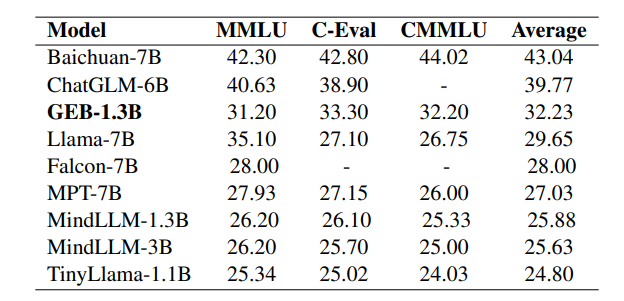
最近开发的大型语言模型(LLMs),如ChatGPT、Claude和Llama,展示了令人印象深刻的能力,甚至在某些任务上超越了人类水平。尽管这些模型取得了成功,但它们对资源的高要求——在训练和推理过程中需要大量计算能力——限制了它们仅能部署在高性能服务器上。此外,这些模型广泛的计算需求通常会导致响应时间延迟增加。随着对LLMs在CPU上高效运行的需求不断增加,关于优化轻量化模型用于CPU推理的研究应运而生。这项工作介绍了GEB-1.3B,一个在中英文两种语言上训练的轻量化LLM,使用了5500亿个词语进行训练。作者采用了创新的训练技术,包括ROPE、Group-QueryAttention和FlashAttention-2,在保持模型性能的同时加速了训练。此外,作者使用1000万条指令数据对模型进行了微调以增强对齐能力。GEB-1.3B在MMLU、C-Eval和CMMLU等一般性基准测试中表现优异,优于类似的模型如MindLLM-1.3B和TinyLLaMA-1.1B。值得注意的是,GEB-1.3B的FP32版本在CPU上的推理时间表现出色,目前正在通过先进的量化技术进一步提升速度。GEB-1.3B 作为开源模型的发布,是对轻量化LLM发展的重要贡献,有望促进该领域的进一步研究和创新。
文章链接:
https://arxiv.org/pdf/2406.09900
06
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
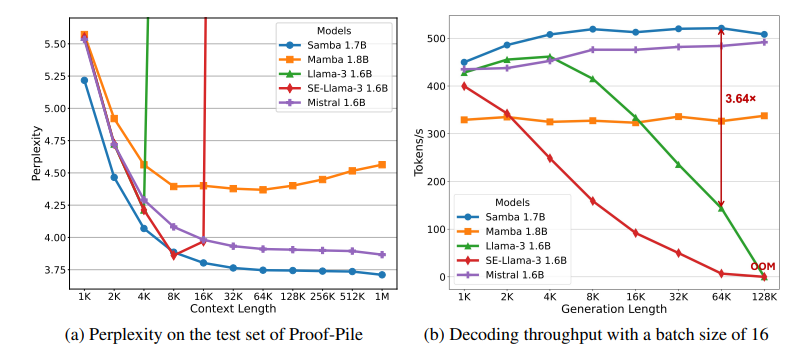
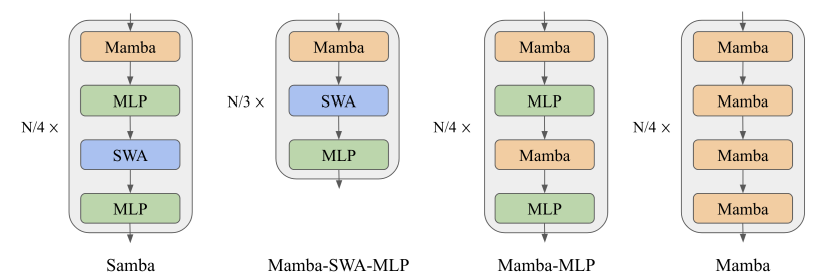
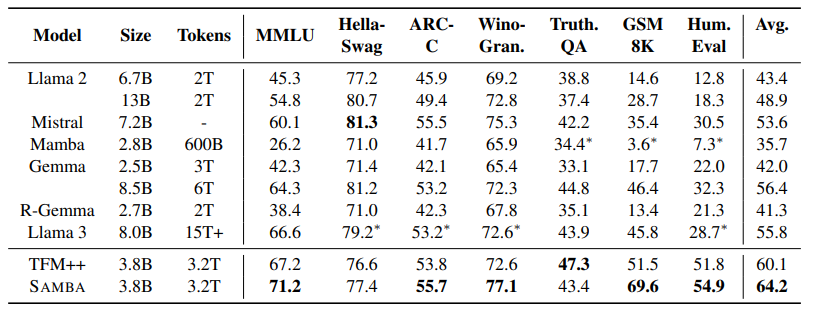
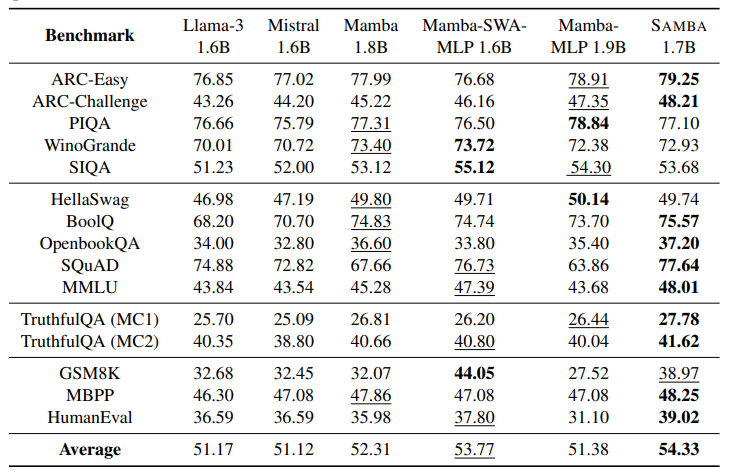
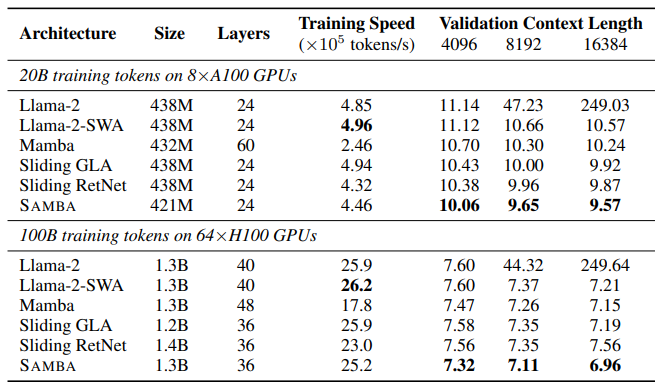
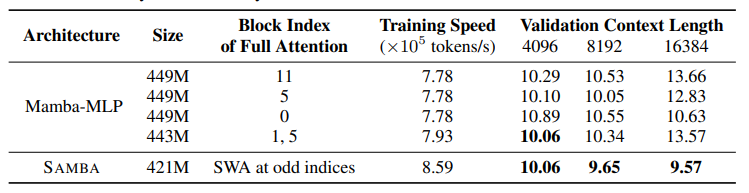
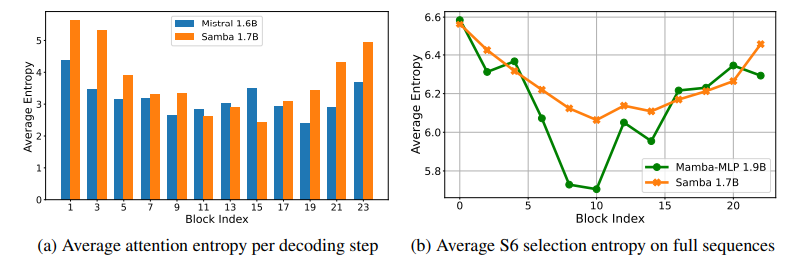
有效地对具有无限上下文长度的序列进行建模一直是一个长期存在的问题。过去的研究要么受到二次计算复杂度的影响,要么在长度泛化上的外推能力有限。这项工作提出了SAMBA,这是一种简单的混合架构,通过层次结构将Mamba(一种选择性状态空间模型,SSM)与滑动窗口注意力机制(SWA)结合起来。SAMBA选择性地将给定序列压缩到递归的隐藏状态中,同时仍然保持通过注意力机制精确回忆记忆的能力。本文将SAMBA扩展到38亿参数,并使用3.2万亿训练标记对其进行训练。结果显示,SAMBA在一系列基准测试中显著超越了基于纯注意力机制或状态空间模型的最先进模型。当在长度为4K的序列上训练时,SAMBA可以高效地扩展到256K上下文长度,同时完美地回忆记忆,并在最长100万上下文长度上表现出改进的标记预测能力。作为一种线性时间序列模型,SAMBA在处理长度为128K的用户提示时,与带有分组查询注意力的Transformers相比,吞吐量提高了3.73倍;在生成64K个标记时,实现了3.64倍的速度提升,并支持无限流式生成。
文章链接:
https://arxiv.org/pdf/2406.07522
07
GenAI Arena: An Open Evaluation Platform for Generative Models
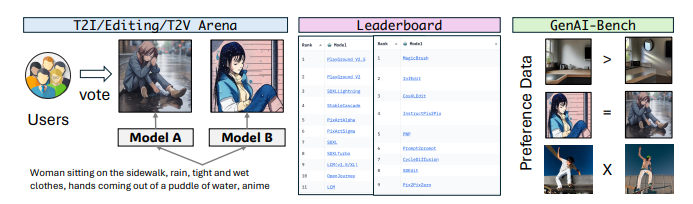
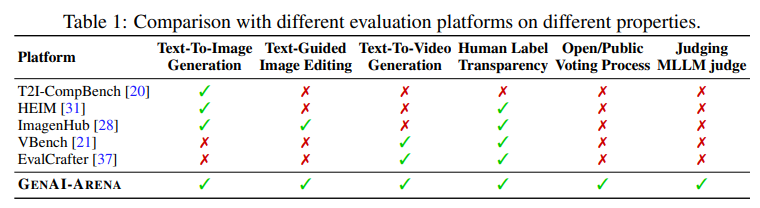
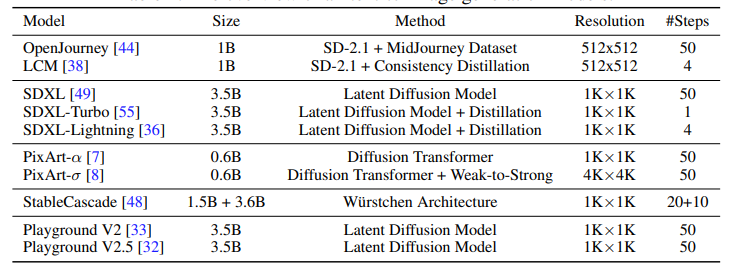
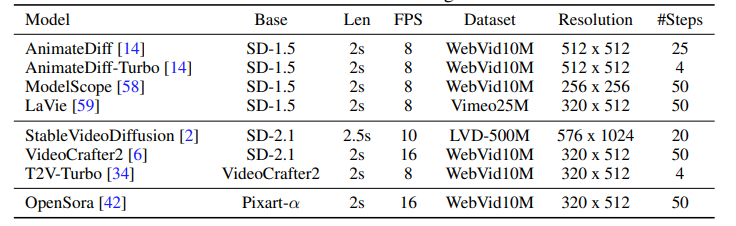
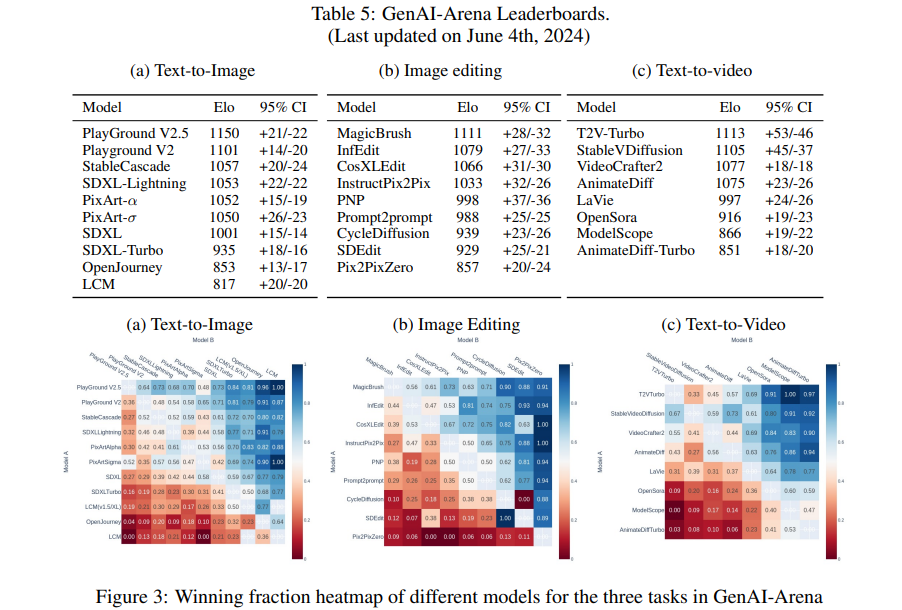
生成式人工智能(Generative AI)在图像和视频生成领域取得了显著进展。这些进步得益于创新的算法、架构和数据。然而,生成模型的快速普及揭示了一个关键问题:缺乏可信的评估指标。目前的自动评估方法,如 FID、CLIP、FVD 等,往往无法捕捉生成结果的细微质量和用户满意度。本论文提出了一个开放平台 GENAI-ARENA,用于评估不同的图像和视频生成模型,用户可以积极参与这些模型的评估。通过利用集体用户反馈和投票,GENAI-ARENA 旨在提供一种更加民主和准确的模型性能衡量方式。它涵盖了三个领域:文本生成图像、文本生成视频和图像编辑。目前,涵盖了总共27个开源生成模型。GENAI-ARENA已经运行了四个月,收集了来自社区的超过6000票。为了进一步推动基于模型的评估指标研究,作者发布了偏好数据的清理版本GenAI-Bench,用于这三个任务。该研究促使现有的多模态模型如Gemini、GPT-4o 模拟人类投票,计算了模型投票与人类投票的相关性,以理解它们的判断能力。结果表明,现有的多模态模型在评估生成的视觉内容方面仍然滞后,即使是最好的模型GPT-4o在质量子评分中的Pearson相关性也只有0.22,并且在其他方面表现得像随机猜测。

文章链接:
https://arxiv.org/pdf/2406.04485
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









