






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
引言:探索知识检索与问题解答的新方法
在人工智能领域,尤其是在自然语言处理(NLP)中,知识检索和问题解答一直是研究的热点。随着大型语言模型(LLM)的发展,如GPT和BERT系列,这些模型在多种任务上展示了卓越的性能。然而,这些模型在处理知识密集型问题时仍面临挑战,尤其是在需要实时更新和整合外部知识时。
传统的方法依赖于将大量知识编码进模型的参数中,但这种方法不仅更新成本高,而且难以适应知识的快速变化。为了解决这些问题,研究者们提出了检索增强生成(Retrieval-Augmented Generation, RAG)方法,通过外部知识的动态检索来增强模型的应答能力。然而,这些方法在实际应用中仍然存在检索不相关信息导致性能下降的风险。
为了进一步提升模型的问题解决能力,并减少错误信息的干扰,本文提出了一种新的框架——检索增强迭代自反馈(Retrieval Augmented Iterative Self-Feedback, RA-ISF)。该框架通过迭代处理问题,并在三个子模块中优化信息的整合和处理,显著提高了模型在复杂问题解答中的表现。
论文标题:RA-ISF: Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
机构:
Zhejiang University
Southeast University
Massachusetts Institute of Technology
论文链接:https://arxiv.org/pdf/2403.06840.pdf
通过这种创新的方法,RA-ISF不仅提高了问题解答的准确性,还通过减少幻觉现象(即模型生成与现实不符的答案)来提高了答案的质量。这一研究不仅推动了知识检索和问题解答技术的发展,也为未来相关技术的研究提供了新的方向和思路。
RA-ISF框架概述
Retrieval Augmented Iterative Self-Feedback (RA-ISF) 是一种新型的检索增强框架,旨在通过迭代自反馈机制解决大型语言模型(LLM)在处理复杂问题时遇到的挑战。该框架结合了自我知识判断、文本相关性评估和问题分解三个子模块,以提高问题解决能力和减少错误信息的生成。
1. 自我知识模块(Self-Knowledge Module):此模块首先判断问题是否可以仅凭模型已有的知识解决。如果可以,模型将直接给出答案,否则进入下一阶段。
2. 文本相关性模块(Passage Relevance Module):在需要外部信息时,此模块负责评估检索到的文本段落与问题的相关性。只有当文本与问题高度相关时,才会将其用于生成答案。
3. 问题分解模块(Question Decomposition Module):当问题复杂或需要更多信息时,此模块将问题分解为更小、更易管理的子问题,并对每个子问题重复前两个模块的过程。
RA-ISF框架的设计允许模型在面对不同类型的问题时,能够灵活调整处理策略,从而提高答案的准确性和相关性。通过这种迭代和分层的处理方式,RA-ISF能够有效地整合内部和外部知识,优化问题解决路径,减少无关信息的干扰。
深入解析RA-ISF的工作机制
RA-ISF框架通过其三个子模块的协同工作,实现了对复杂问题的高效处理。以下是这一过程的详细解析:
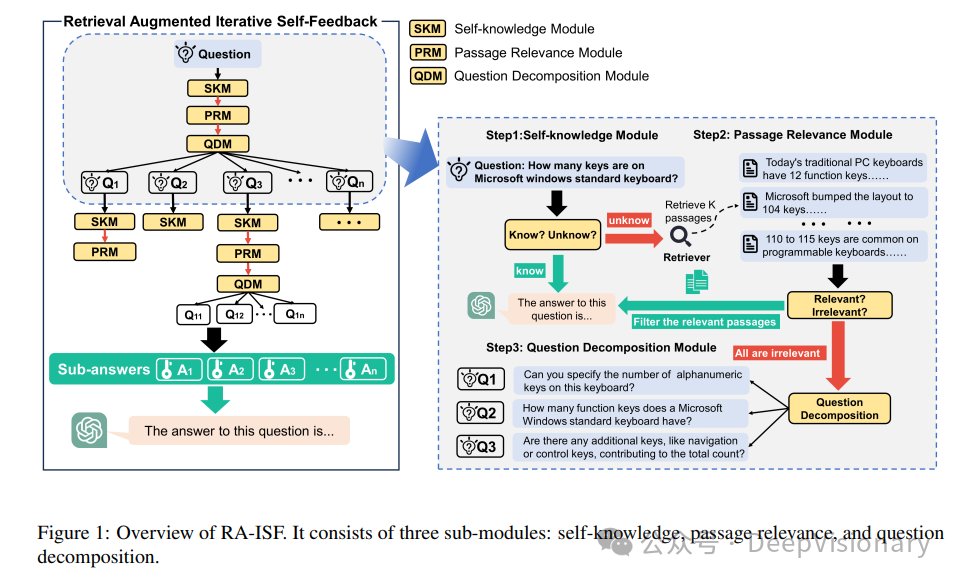
1. 自我知识判断:当输入一个新问题时,RA-ISF首先通过自我知识模块判断该问题是否可以依靠模型现有的知识库解决。这一步骤是快速且成本低,能有效减少不必要的外部检索,提高处理速度。
2. 外部文本检索与评估:如果问题不能仅凭内部知识解决,RA-ISF将使用检索器查找相关的外部文本。文本相关性模块随后评估这些文本与问题的相关性。只有评估为高度相关的文本才会被用来辅助生成答案,这一机制显著减少了不相关信息的干扰。
3. 问题分解与迭代处理:对于更复杂或需多步推理的问题,问题分解模块将问题拆分为若干子问题,每个子问题都将重新经过自我知识判断和外部文本检索评估。这一迭代过程不仅增强了模型处理复杂问题的能力,也使得答案更加精确和全面。
4. 综合答案生成:在处理完所有子问题后,RA-ISF将各子问题的答案综合起来,形成对原始问题的完整回答。这一过程确保了问题的每个方面都得到了充分考虑和解答。
通过这种迭代自反馈的工作机制,RA-ISF能够有效地提升大型语言模型在开放域问题解答中的表现,特别是在处理需要深层次推理和多步骤解答的复杂问题时。此外,RA-ISF还通过减少错误信息的生成,显著提高了信息的准确性和可靠性。
实验设计与数据集介绍
1. 数据集介绍
为了全面评估不同特征的数据集的性能,我们使用以下五个代表性数据集进行评估:Natural Question (NQ)、TriviaQA、StrategyQA、HotpotQA 和 2WikiMQA。这些数据集涵盖了从单一事实问题到需要多步推理和多源信息整合的复杂问题。
Natural Question (NQ): 包含大量的实际用户查询和对应的维基百科页面,用于评估开放域问答系统的性能。
TriviaQA: 包含大量的问题和答案对,这些问题是从网络和维基百科文档中收集的,适用于测试信息检索和问答系统。
StrategyQA: 需要从问题中推断出解决策略,涉及隐式推理步骤的问答基准。
HotpotQA: 设计用于测试多跳问答能力,需要结合多个维基百科文章的信息来回答问题。
2WikiMQA: 结合了结构化和非结构化数据,用于评估模型在处理多跳问题时的推理能力和解释性。
2. 实验设计
实验中,我们采用了Retrieval Augmented Iterative Self-Feedback (RA-ISF) 框架,该框架通过三个子模块迭代处理问题:自我知识模块、段落相关性模块和问题分解模块。这种设计旨在通过迭代反馈机制提高模型处理复杂问题的能力。
自我知识模块:首先判断问题是否可以仅凭模型已有的知识解决。
段落相关性模块:对检索到的文本段落进行相关性评估,筛选与问题相关的文本。
问题分解模块:对于无法直接回答的问题,将其分解为子问题,并对每个子问题重复上述步骤。
通过这种方法,RA-ISF能够有效地整合外部知识和模型固有的知识,同时减少由于检索到不相关文本而导致的错误信息干扰。
主要实验结果与分析
1. 实验结果
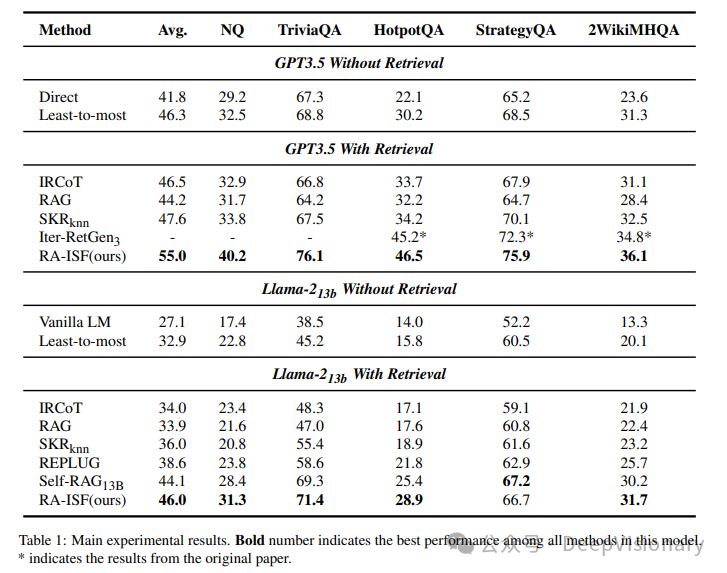
在使用GPT3.5和Llama2模型进行的实验中,RA-ISF在所有五个数据集上均表现优异,特别是在处理需要复杂推理的StrategyQA和TriviaQA数据集时,相比于传统的RAG方法和其他基线方法,RA-ISF显示出显著的性能提升。
在StrategyQA数据集上,与直接使用RAG相比,RA-ISF的性能提高了11.2个百分点。
在TriviaQA数据集上,RA-ISF也显示出了较大的性能提升,这表明RA-ISF在减少幻觉问题(即模型生成与问题不相关的答案)方面具有明显优势。
2. 性能分析
RA-ISF框架通过迭代地解决子问题并整合相关文本,有效地提高了问题解决的准确性和效率。此外,三个子模块的协同工作显著提高了模型对复杂问题的处理能力,尤其是在外部知识的检索和整合方面。
自我知识模块允许模型首先尝试使用已有知识解决问题,减少不必要的外部检索,提高处理速度。
段落相关性模块确保只有与问题高度相关的文本被用于生成答案,减少了错误信息的干扰。
问题分解模块通过将复杂问题分解为更易管理的子问题,使模型能够更有效地处理信息,提高了答案的准确性和相关性。
综上所述,RA-ISF通过其创新的迭代自反馈机制,在多个开放域问答任务中均实现了优于现有技术的性能,特别是在处理复杂、知识密集型问题时的表现尤为突出。
消融研究
在RA-ISF框架中,我们通过消融研究来评估三个子模块——自知识模块、段落相关性模块和问题分解模块——对整体性能的贡献。这些研究帮助我们理解每个组件的重要性以及它们如何共同作用以提高问题解决的效率。
1. 自知识模块的消融
在没有自知识模块的情况下,RA-ISF直接使用段落相关性模块处理问题,不进行自我知识判断。这种情况下,模型可能会忽略内部已知的信息,导致不必要的外部信息检索,增加处理时间和降低效率。
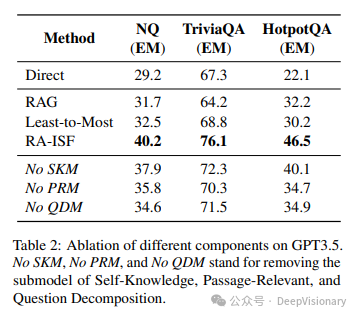
2. 段落相关性模块的消融
去除段落相关性模块后,如果自知识模块判断问题不能仅凭内部知识解决,系统将直接进入问题分解阶段,而不评估检索到的文本段落的相关性。这可能导致使用不相关的信息来尝试解答问题,增加误解和错误答案的风险。
3. 问题分解模块的消融
在没有问题分解模块的情况下,如果段落相关性模块未找到相关文本,问题将被标记为“未知”,而不会尝试进一步分解问题。这限制了模型处理复杂或多步骤问题的能力,可能导致在需要深入分析和理解的情况下无法给出答案。
通过对比完整的RA-ISF框架与各种消融版本,我们发现去除任何一个模块都会导致性能下降,这验证了每个组件在提高问题解决能力中的重要性。特别是在处理需要广泛外部知识和深层次理解的复杂问题时,三个模块的协同工作显得尤为关键。
讨论与未来研究方向
RA-ISF框架通过其创新的迭代自反馈机制,在多个基准测试中显示出优越的性能。然而,我们也认识到该框架存在一些限制和潜在的改进空间。
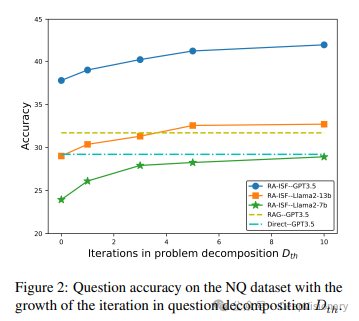
1. 迭代问题解决的效率问题
虽然迭代方法可以提高问题解决的深度和准确性,但它也可能导致处理时间增长,特别是在问题连续无法解决时。未来的研究可以探索如何优化迭代过程,比如通过改进问题分解策略或更智能的停止条件,以提高效率。
2. 特定领域的适应性
当前的RA-ISF框架主要针对开放域的问题解答,其在特定领域(如医学、法律)的表现尚未得到验证。未来的工作可以探索如何将RA-ISF适应于这些领域的特定需求,可能包括定制知识库的构建和特定类型问题的处理策略。
3. 简化模型复杂性
RA-ISF框架依赖于多个子模块和复杂的迭代机制,这可能增加模型部署和维护的难度。研究简化模型结构的方法,同时保持或提升性能,将是未来工作的一个重要方向。
4. 减轻幻觉问题
尽管RA-ISF在减少幻觉问题方面取得了一定的进展,但如何进一步减轻大型语言模型在信息检索中可能出现的错误和偏差,仍然是一个重要的研究课题。这可能涉及改进文本相关性判断的算法或开发更精确的知识提取技术。
总之,RA-ISF展示了迭代自反馈机制在复杂问题解答中的潜力,为未来的研究提供了新的方向和挑战。通过不断优化和扩展这一框架,我们有望在自动问答和知识处理领域取得更大的进步。
总结
本文介绍了一种新颖的检索增强迭代自反馈(RA-ISF)框架,旨在解决大型语言模型(LLM)在开放域问答任务中的知识更新和利用问题。RA-ISF通过三个子模块:自知识模块、段落相关性模块和问题分解模块,迭代处理问题,有效地整合了内部知识和外部检索信息,提高了问题解决的准确性和效率。
主要贡献
RA-ISF框架通过自知识判断、相关段落检索和问题分解三个步骤,显著提高了模型对复杂问题的处理能力。实验结果显示,该方法在多个数据集上均优于现有的检索增强方法。
该框架还特别强调了迭代分解问题的重要性,能够在模型初步无法解答或检索到不相关文本时,通过分解问题为子问题并解决,从而有效提升了问题的解决率。
在处理知识密集型问题时,RA-ISF通过减少幻觉现象(即模型生成与事实不符的答案)和提升事实推理能力,表现出了较传统方法更优的性能。
实验与评估
在GPT3.5和Llama2等多种大型语言模型上的测试显示,RA-ISF在包括Natural Question和TriviaQA在内的多个标准数据集上都有出色的表现。
通过对比实验和消融研究,验证了自知识模块、段落相关性模块和问题分解模块的有效性和必要性。移除任何一个模块都会导致性能下降,证明了RA-ISF各部分的协同作用对于整体性能的重要贡献。
局限性与未来工作
尽管RA-ISF在开放域问答任务中表现优异,但其在特定领域如数学推理、法律或医学等专业领域的表现尚未验证。未来的研究可以探索将RA-ISF应用于这些领域的可能性。
迭代问题分解策略可能导致问题处理过程中的效率问题,特别是在连续探索无解或相关性低的子问题时。未来的工作可以在优化迭代策略和提高检索效率方面进行改进。
总之,RA-ISF框架通过创新的迭代自反馈机制,显著提升了大型语言模型在开放域问答任务中的性能,特别是在处理复杂和知识密集型问题方面显示了其独特的优势。未来的研究将进一步探索其在更广泛应用和不同领域中的潜力。

点击 阅读原文 观看讲者直播讲解回放!
往期精彩文章推荐

ACL 2024主会文章:实体关系分析助力大型语言模型攻克复杂推理挑战
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看讲者直播讲解回放!


















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









