






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
探索 AGI 的道路上,需要更广的能力纬度,更深的能力探索,全方面评估模型的优劣势。前有 DeepMind AlphaGeometry 在数学几何证明上达到了 IMO 金牌选手的水平,后有 AI-MO 挑战赛,探索 AI 在 IMO 竞赛上的表现。两者都在呼唤更有难度的评测集,来向大模型发起挑战,甚至是不远处的 AGI。
然而传统的数学、物理评测集随着 LLMs 和 LMMs 的快速发展,逐渐缺少挑战性,不能满足于目前研究需求,无法准确的评估当下模型的推理性能瓶颈。近日,我组联合北航、曲一线智能出版中心联合发布了 OlympiadBench,一个 Olympiad-level 的双语、多模态的科学评测集。包含 8952 条数学和物理题,这些都来自于国际奥赛、中国奥赛、中国高考题和模拟题。根据评测,当下最好的多模态模型 GPT-4V 在 OlympiadBench 上仅达到了 17.23%。

论文信息
➤ 论文地址
🔗https://arxiv.org/abs/2402.14008
➤ GitHub链接
🔗 https://github.com/OpenBMB/OlympiadBench

OlympiadBench特色之处
Olympiad-难度之高:人类智慧的巅峰——奥林匹克竞赛;
Multimodal-不止文字:在传统评测集局限于文字的基础上,扩展更多的模态:图片、表格;
Science-科学推理:评估大模型在数学、物理上的推理能力;
Bilingual-双语研究:第一个分别在高难度数学、物理上提供双语研究的评测集。

一道IMO题目

OlympiadBench的绝对优势
下表是 OlympiadBench 和相关评测集的比较,从中可以看出,OlympiadBench 有绝对优势。
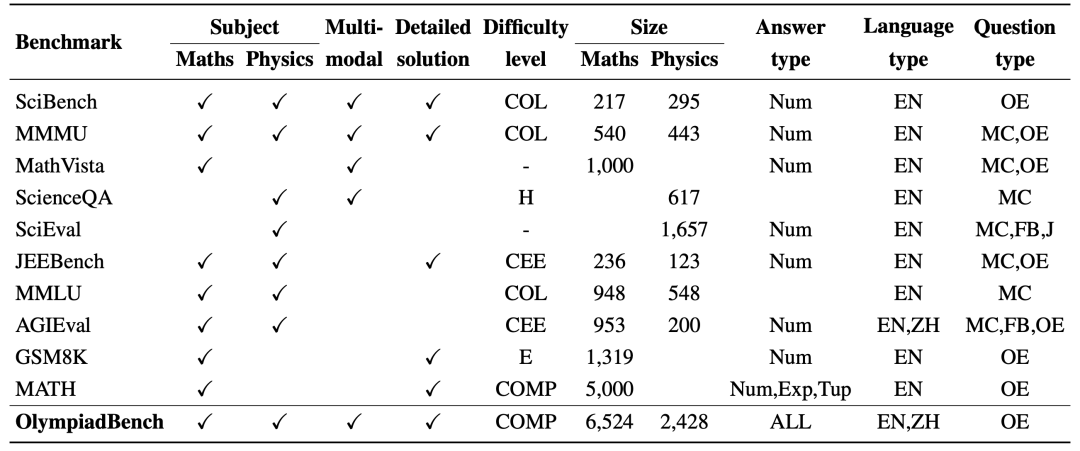
和相关评测集的全面比较
奥赛级别。我们挑选了国内外奥林匹克竞赛、国内高考题和模拟题的解答题和证明题。无论是难度还是题目形式,均和以往的评测集不同,都对模型进行高阶推理提出巨大的挑战性,
数学&物理。在科学问题中,OlympiadBench 选择了数学、物理,这两个对人类科学极其重要的学科,其中物理的难度不亚于数学,却经常被忽略。我们收集这两个学科来推动 AGI 在科学推理上的发展。
多模态。随着 LMMs 的快速发展,传统的评测集一般是 text-only,不满足研究需求。OlympiadBench 包含了多模态信息,同时为 LLMs 和LMMs提供挑战性的题目。
双语。目前比较常用的评测集主要是英文,而中文环境下缺少有难度的评测集。所以我们收集了中文环境下有难度的题目,为中文大模型、中文的研究提供资源。我们也是第一个提供双语、多模态的科学评测集。
详细的数据信息。每条数据都包含了专家级别标注的解答过程,以及人工标注的细分领域、题型等等。我们庞大的数据量也为科学推理研究提供宝贵的资源。

OlympiadBench的构建过程
OlympiadBench 的目标是建立一个代表人类智力成就顶峰的基准,从而鼓励研究人员推动大模型的数学和物理推理能力的边界。为了实现这一愿景,我们收集了国内外奥林匹克竞赛题目以及国内的高考题目。对于奥林匹克竞赛,我们从官方下载PDF,并使用 Mathpix 转化为 markdown。我们对处理的结果进行细致的校对、修复。然后进行统一去重。最后,我们为每一条数据详细地标注了答案类型和子字段等关键信息,从而获得干净、准确和详细的数据集。
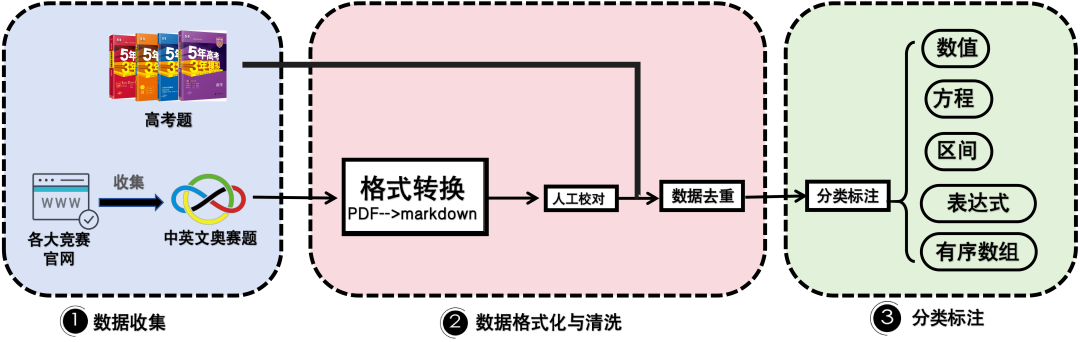
OlympiadBench构建流程
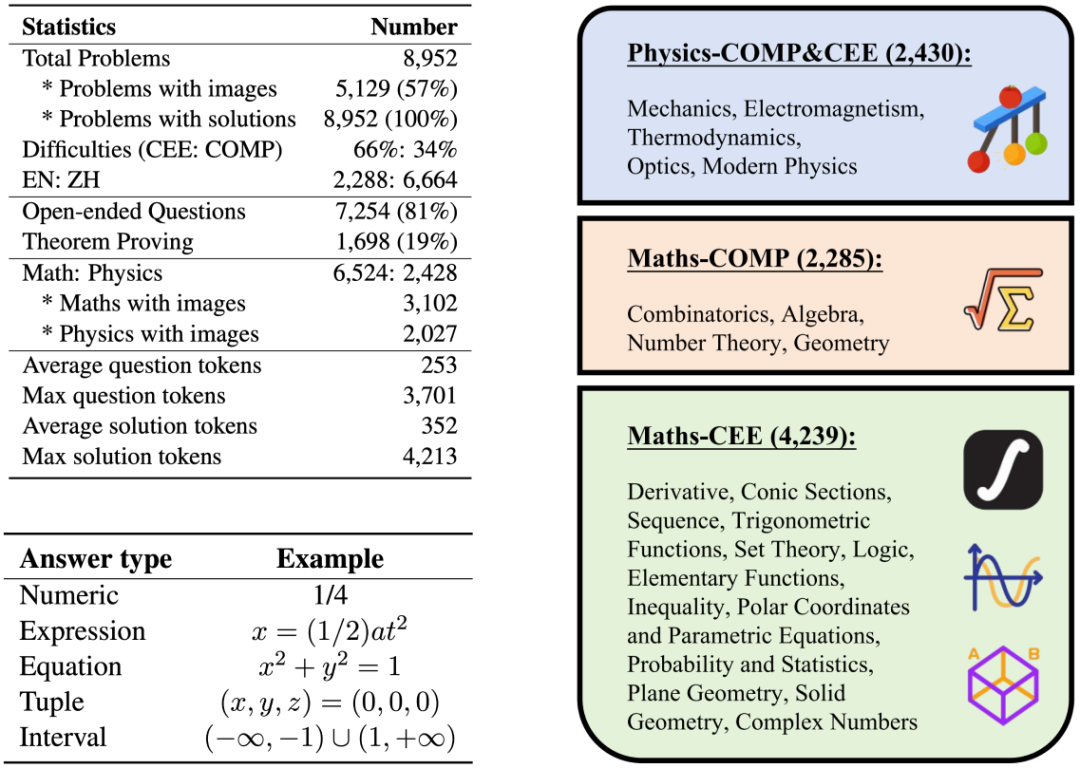
数据集的详细信息
为了更准确全面的评估,我们针对以上五种答案题型(数值、方程、区间、表达式和有序数组)的题目,构建了一个自动评分的 Pipeline。

自动评分 Pipeline
针对每一种不同的答案类型,我们都预先进行了特殊的预处理,随后再使用Python的Sympy库将其解析为符号表达式,并在此基础上进一步地判断数学意义上的等价性。其中区间和有序数组(比如坐标)都适用同一套预处理方法,当模型回答与正确答案在这两种类型上不等价时,再依次采用对数值、方程、表达式的预处理方案。基本上所有答案在预处理后,都直接通过相减后是否小于最低允许误差(默认为1e-8)的情况来进行判断等价性,除了对方程是采用移项后相除是否为整数的方法进行判断。

等价的复杂测试样例(源自物理奥赛)
相比现有评测集常用的的精准匹配(Exact match)方法,该评分 Pipeline 更好地考虑到了答案格式的多样性,通过使用 Sympy 库对于符号表达式的支持,可以基本覆盖大部分的复杂测试样例(如上图所示)。同时,我们还考虑到了实际考试中,对于许多数值计算类的题目,是允许参赛者给出的答案与正确答案存在一定的误差,因此除了物理答案中有明确指出的误差范围,我们也根据数值计算中可能的取近似值操作,人工给出了一个大致的允许误差范围,进一步提升了该自动评分 Pipeline 的有效性。

实验结果
我们收集的题目分为证明题和解答题(可以使用 Pipeline 自动评分)。对于证明题我们进行抽样检查,以下实验结果为使用自动评分 Pipeline 的解答题的结果,下图为本实验统一采用的 prompt 模板。

实验所用prompt模板
我们选了当下性能最好的几个多模态模型进行评测。如下表所示。
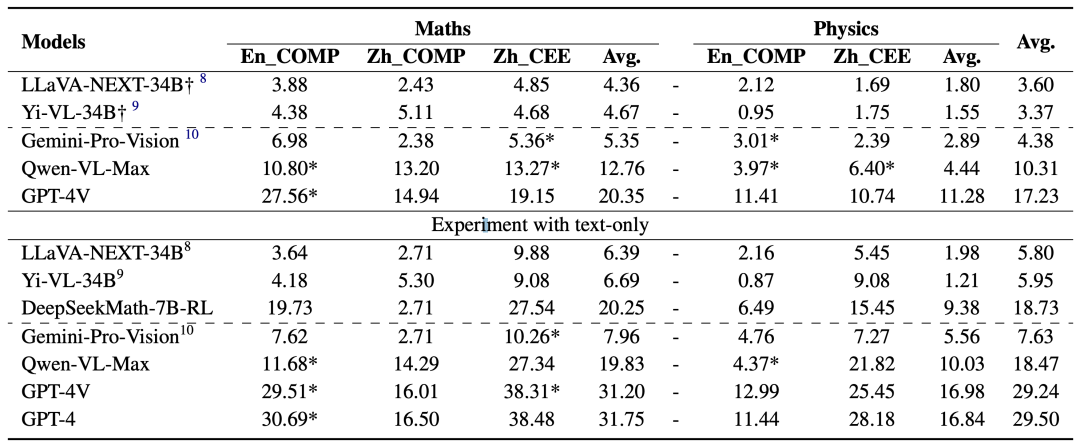
实验结果
➤ 实验结果
OlympiadBench 比现在评测集更具有挑战性,最先进的 GPT-4V 的平均准确率仅为17.23%。
最强大的闭源模型和开源模型之间仍然存在巨大差异。GPT-4V 的平均准确率是性能最好的开源模型 Yi-VL-34B 的 5 倍以上。
图像、物理和非英语文本提供了更高的难度挑战。
➤ 问题分析
GPT-4V的错误分析:我们手动抽样检查了 GPT-4V 回答错误的 97 道数学题(英文 55 道,中文 42 道)和 67 道物理题,并分析了错误类型,如下图所示。
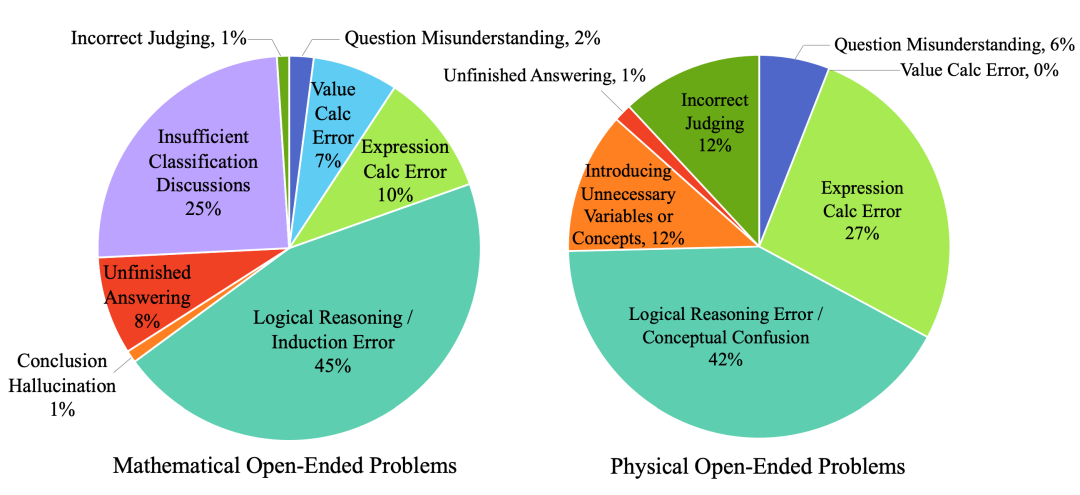
错误类型统计
在数学问题中,GPT-4V的典型错误包括:推理错误、在组合问题上的分类讨论不足;在需要大量计算的问题上(例如圆锥曲线问题)表现不佳,具体表现为计算过程缺乏逻辑,导致模型无法提供合理的答案。不过,我们也发现 GPT-4V 在解决一元二次方程和导数问题上有较强的能力。
在物理问题中,GPT-4V 在处理时往往会陷入概念混淆,或引入不必要的变量或概念,但其简化和转换代数表达式的能力却强于纯数学情境,几乎没有数值计算错误。
我们根据OlympiadBench的知识点标签,分析了GPT-4V在不同知识点上的表现(解答题的准确率),结果如下图。
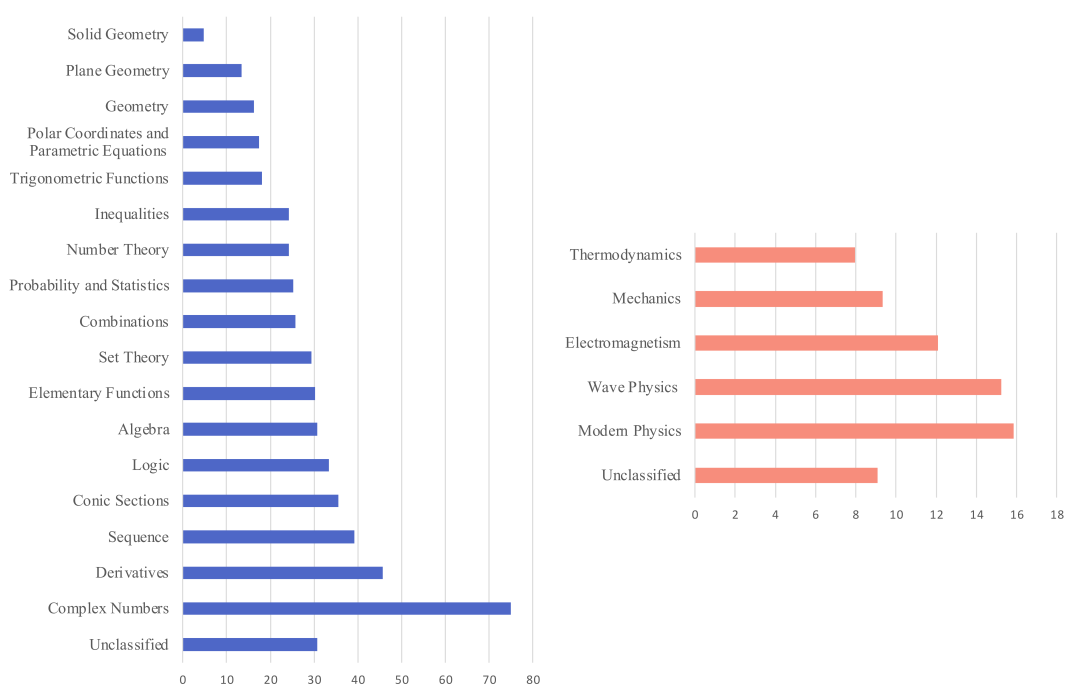
计GPT-4V 在不同知识点上的表现
在数学问题中,GPT-4V 在几何方面的表现较差,准确率最低的几乎都是与几何相关的。这表明需要提高模型对平面或三维情况的理解和想象能力。然而,GPT-4V 在与导数和复数相关的知识上表现较强。
至于物理问题,没有一个知识点的准确率超过 16%,其中 GPT-4V 在热力学和力学方面表现较差。

总结与展望
我们构建了一个 Olympiad-level的双语、多模态、科学评测集,在高难度的题目上探索模型在数学和物理推理上的智慧表现。通过一系列评测实验,表明OlympiadBench 具有很强的挑战性。希望 OlympiadBench 可以为推动AGI的发展提供帮助,另外科学的评测集也不仅限于数学、物理,未来我们将继续扩展我们的评测集,提供更全面的评估。

点击 阅读原文 观看讲者直播讲解回放!
往期精彩文章推荐
ACL 2024 | 智能体学习框架:经验式共同学习,增强多智能体协作式软件开发能力
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看讲者直播讲解回放!


















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









