






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
作者及关键词
作者:徐榕荟,成涵吟,郭晨娟,高洪帆,胡吉林,杨斌,杨彬
关键词:路径表征学习,多模态,自监督学习
摘要
在智能交通的各个领域中,开发有效的路径表征变得越来越重要。尽管预训练的路径表征学习模型表现出了不错的性能,但它们主要关注单模态数据的拓扑结构,如道路网络,而忽略了与路径图像(如遥感图像)相关的几何和上下文特征。整合来自多种模态的信息可以提供更全面的视角,提高表征精度和泛化能力。然而,信息粒度的差异阻碍了基于路网的路径(道路路径)和基于图像的路径(图像路径)的语义对齐,同时多模态数据的异构性也给有效融合和利用带来了巨大挑战。本文提出一种新的多模态、多粒度的路径表征学习框架(MM-Path),通过整合道路路径和图像路径这两种模态来学习通用的路径表征。为增强多模态数据的对齐,我们提出了一种多粒度对齐策略,系统地将节点、道路子路径和道路路径与其对应的图像块关联起来,确保详细的局部信息和更广泛的全局上下文的同步。为了有效解决多模态数据的异构性,我们提出了一种基于图的跨模态残差融合组件,旨在全面融合不同模态和粒度的信息。最后,在两个下游任务下的两个大规模真实数据集上进行了广泛的实验,验证了MM-Path的有效性。
论文链接:
https://arxiv.org/abs/2411.18428
代码链接:
https://github.com/decisionintelligence/MM-Path
动机
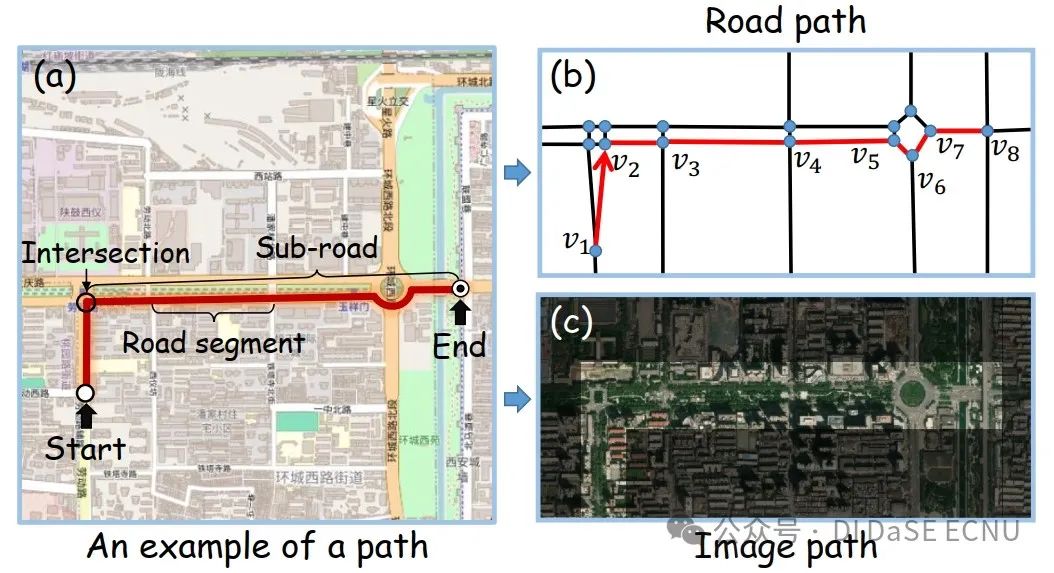
在智能导航、城市规划以及城市应急管理等领域,理解路径并开发有效的路径表示变得日益重要。路径表征可以广泛应用于路径旅行时间估计、路径推荐以及公共交通系统的布局分析与优化等方面。近年来,许多研究工作致力于构建预训练路径表征学习模型,这些模型展现了出色的泛化能力。在现实世界中,路径存在于多种模态中,它们提供了更为丰富和多样的信息。例如,从道路网络中提取的路径(简称“道路路径”)揭示了道路段之间的拓扑关系;而遥感图像中的路径(简称“图像路径”)则从几何特征及更广泛的环境上下文中提供了新的视角(如图1 所示)。通过整合这些不同的模态信息,我们能够从多角度丰富路径的表征,进而提升模型的准确性和泛化性。然而,目前的路径表征学习模型主要依赖于来自道路网络的单一模态数据,尚未充分捕获对于全面理解路径至关重要的深层次、全面的上下文信息。因此,开发一个能够整合多模态数据的预训练路径表征学习模型显得尤为必要。
挑战
构建这样一个预训练多模态路径表征学习模型时,主要面临了两个挑战:
(1)道路路径和图像路径之间的信息粒度差异严重阻碍了跨模态语义对齐。如图1所示,道路路径通常侧重于详细的拓扑结构并描绘道路连通性,而图像路径则提供了更广阔的全局环境上下文,反映了相应区域的功能属性。需要指出的是,图像中可能包含大量与道路路径相关性较低的区域,如图1(c) 中的深色区域。现有的的图像-文本多模态模型通常采用单图像与文本序列对齐的方式,这种单一的粗粒度对齐方法可能引入噪声,不足以满足路径表征的精细对齐需求。
(2)道路路径和图像路径固有的异质性对特征融合构成巨大挑战。道路路径和图像路径在学习方法上的差异巨大,导致它们被映射到不同的嵌入空间,使得具有相似语义的特征维度包含完全不同的信息。简单的融合策略可能会导致信息丢失或偏差增加,且难以捕捉道路路径和图像路径之间的微妙相关性。
方法
为应对这些挑战,我们提出一种多模态、多粒度的路径表征学习框架MM-Path,用于学习通用路径表征。图2 展示了MM-Path的总体框架。MM-Path包含了两个关键组件:多粒度对齐(Multi-granularity Alignment)组件和基于图的跨模态残差融合(Graph-based Cross-modal Residual Fusion)组件。
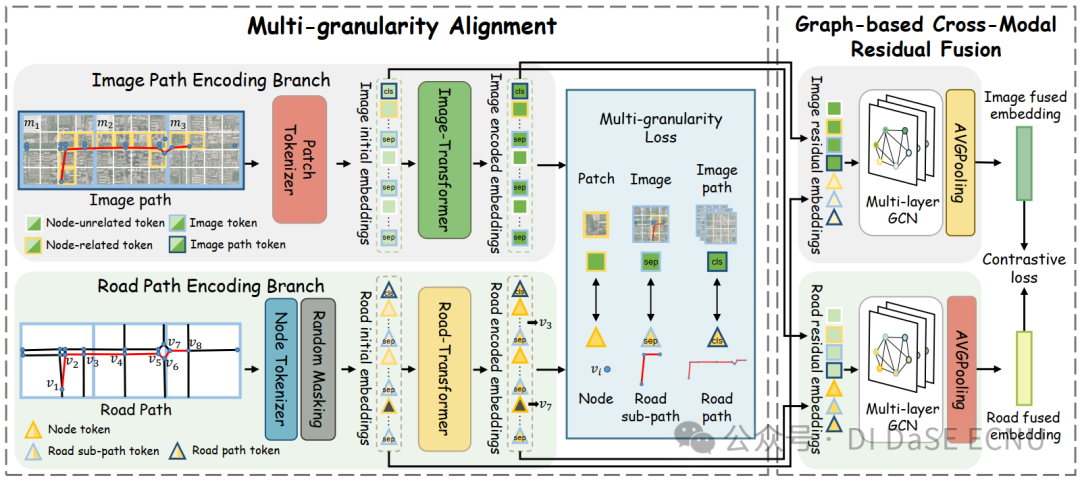
多粒度对齐组件系统地将路口、子路径和整个道路路径与其对应的图像信息关联起来,以更精细的粒度准确捕捉细节,并在更粗的粒度上保持全局对应。具体来说,我们将整个感兴趣区域的图像划分为固定尺寸的小图像,沿着每条路径收集固定尺寸的小图像,并将收集的图像排列在一个图像路径(即图像序列)中。然后,我们采用模态特定的tokenizers分别为道路路径和图像路径生成初始嵌入。随后,这些初始嵌入被输入到Transformer架构中,在三种粒度上学习每种模态的复杂编码嵌入。最后,采用多粒度对齐损失函数确保不同粒度下道路和图像编码的嵌入对齐。
基于图的跨模态残差融合组件旨在在融合空间上下文信息的同时有效融合跨模态特征。我们将每个模态的编码嵌入与另一个模态的初始嵌入拼接起来,分别创建道路和图像残差嵌入,以融合不同阶段的跨模态特征。然后,基于空间对应关系和上下文信息为每条路径构建跨模态邻接矩阵。该矩阵利用GCN迭代地分别融合两种残差嵌入,从而获得道路和图像融合嵌入。最后应用对比损失来确保两种模态融合嵌入的一致性。最后,我们将这两个融合的嵌入连接起来,得到一个通用的路径表征。由于最终表征有效地融合了两模态的跨阶段特征和空间上下文信息,因此该组件不仅实现了深度的多模态融合,而且增强了信息的综合利用。
实验结果
整体表现
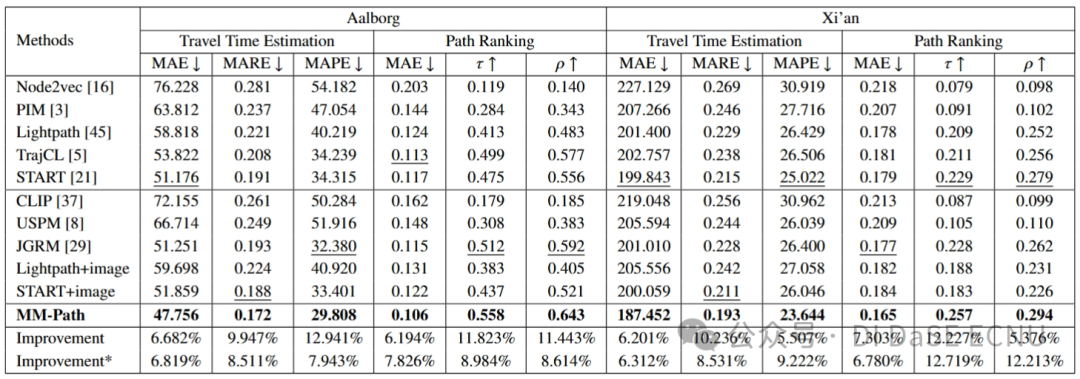
表 1 展示了两项任务——旅行时间估计和路径排序的整体性能表现。我们使用“”(越大越好)和“”(越小越好)来标记数值的优劣。在每项任务中,我们通过粗体和下划线来分别突出最佳和次佳的表现。此外,“Improvement”和“Improvement*”两行分别量化了MM-Path模型相较于最佳单模态和多模态基线模型的性能提升。MM-Path在两个数据集上的表现都优于所有基线,显示了它的优越性。
消融实验
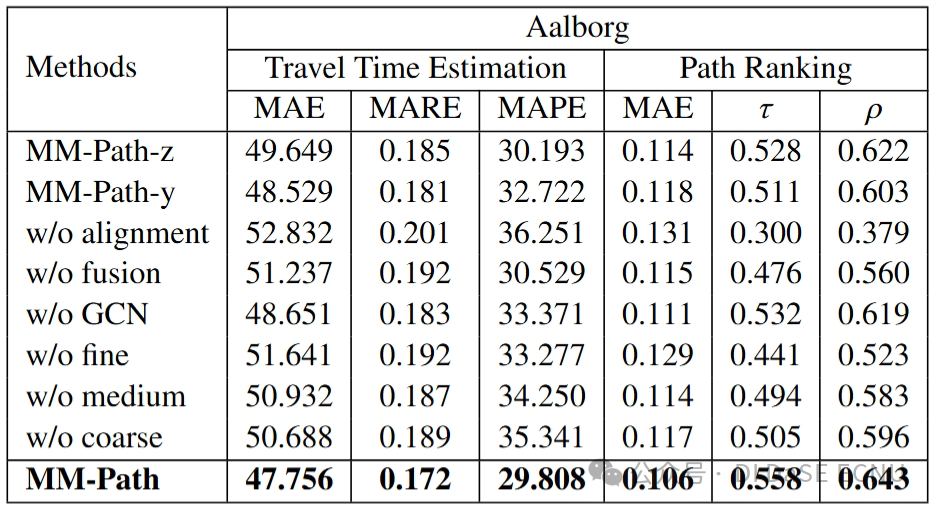
我们为了验证MM-Path模型各组成部分的重要性,设计了八种不同的变体模型:(1) MM-Path-z:这种变体利用道路融合嵌入作为路径的通用表征,专注于探究道路路径编码嵌入与图像路径初始嵌入融合的表征效果。(2) MM-Path-y:该变体使用图像融合嵌入作为路径的通用表征,探究图像路径编码嵌入与道路路径初始嵌入融合的表征效果。(3) w/o alignment:此版本不包含多粒度损失,以评估多粒度对齐策略的影响。(4) w/o fusion:这一变体采用来自两种模态的编码嵌入的平均池化代替了基于图的残差融合组件,以测试融合策略的有效性。(5) w/o GCN:在此变体中,交叉注意力机制取代了基于图的跨模态残差融合组件中的GCN,用以探究GCN的具体作用。(6) w/o fine, (7) w/o medium, and (8) w/o coarse:这些变体分别省略了细粒度、中粒度和粗粒度的loss,分别评估细、中、粗三种粒度信息在模型表现中的作用。
这些变体模型在两个真实数据集的下游任务中的表现被汇总在表 2 和表 3 中,通过这种方式,我们能够深入理解各个模型组件对总体性能的贡献和重要性。
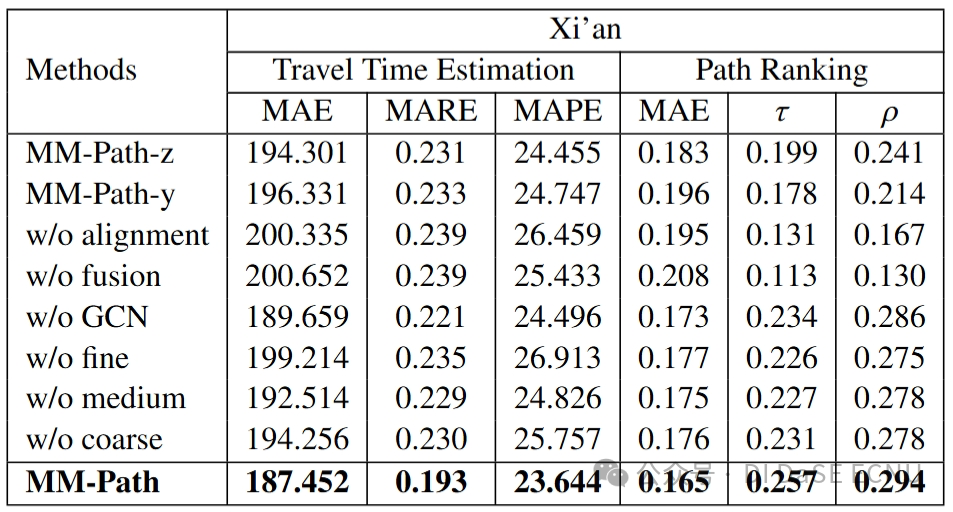
预训练效果
我们改变了用于微调的标记数据的大小,并比较了所提出的MM-Path(Pre-trained)与其缺乏预训练(No Pre-trained)的变体的性能。图 3 显示了旅行时间估计和路径排序任务上的性能。
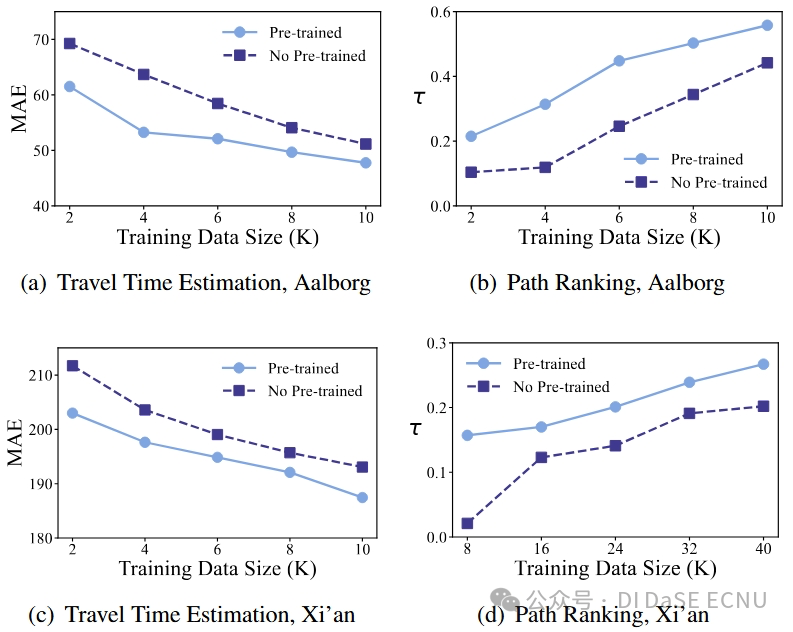
参数敏感性
我们探讨了图像粒度大小对模型性能的影响。为了均匀分割,每个500500像素的图像分别被分割为11、22、44、55和1010个patch。图 4 详细说明了每种粒度大小的模型表现和推理时间。
示例分析
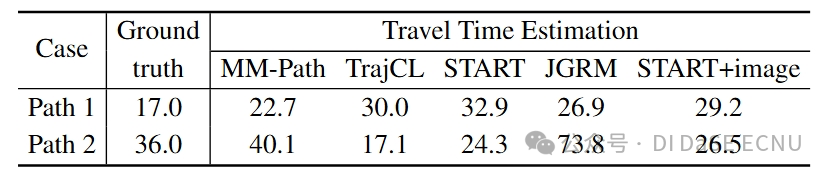
我们考察了奥尔堡的一对具有代表性的路径,以证明MM-Path的优越性。道路路径和图像路径如图 5 所示。
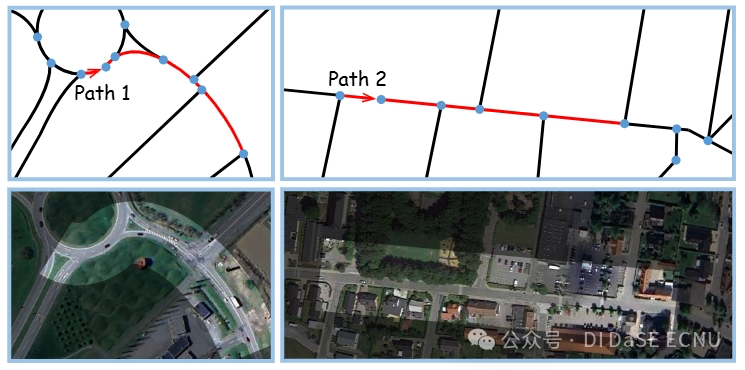
图 5 中的两条路径在路网中表现出相似的结构,都具有的节点度序列。这种单模态数据可能暗示两条路径的旅行时间接近。然而,从它们的图像信息来看,两者存在显著差异。例如,路径1通过一个环形交叉口并沿主干道行驶,通常这样的路径允许较快的行驶速度。而路径2则位于住宅区附近的普通道路,行驶速度通常较慢。
表 4 报告了不同模型对这两条路径估计的旅行时间。模型TrajCL, START 和START+image预测路径2的旅行时间短于路径1,与实际情况相悖。这表明,单一模态数据的信息可能有限,而且简单地将多模态数据拼接在一起,如START+image模型,未能有效地利用图像信息。相比之下,虽然多模态模型 JGRM 的结果与实际旅行时间的相对差异保持一致,但估计值仍有较大偏差。MM-Path 模型则显示出较好的旅行时间估计性能,表明它能有效整合并利用图像信息,从而提供更准确的预测。
结论
本文介绍了一种多模态多粒度路径表征学习框架MM-Path。这是首次尝试将道路网络和图像数据融合于通用的路径表征学习中。首先,框架对道路路径和图像路径分别进行建模,实施多粒度对齐策略,确保精细的局部信息与广泛的全局上下文能够同步。此外,我们开发了一种基于图的跨模态残差融合组件,它能有效整合来自两种模态的信息,同时保持模态间的语义一致性。在两个真实数据集上进行的下游任务测试中,MM-Path超越了所有基线模型,展现了其卓越的性能。
往期精彩文章推荐

AAAI 2025预讲会28位讲者相聚|28篇论文工作+2个团队专场,一起期待2025年的首场预讲会
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









