






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
作者简介
唐桢桁,香港科技大学博士后研究员

一、论文概述
(一)研究背景
大型语言模型(LLMs)如GPT-4和Llama3在自然语言处理领域展现出卓越能力,但因其庞大的参数规模(通常在70亿至7500亿之间),训练和推理过程需耗费大量计算资源与能源,引发了可持续计算方面的担忧,这促使研究人员致力于模型压缩研究。同时,LLMs在知识检索、幻觉问题、计算表达能力和推理能力等方面存在诸多复杂现象与挑战,也是研究的重要背景。

(二)研究问题
当前的LLM压缩方法主要关注在一些基本任务上保持性能,但忽视了模型在复杂能力方面的维持。本研究旨在重新审视LLM压缩应保留的能力,提出Lottery LLM假设,并探讨其相关问题,如对于给定LLM和任务,是否存在较小的Lottery LLM在多步推理和外部工具辅助下能达到与原模型相同性能,以及在此过程中关键能力的界定等。
(三)主要贡献
全面综述了LLMs在检索增强生成、多步推理、外部工具利用和计算表达能力等方面的进展,为后续研究提供了系统的知识基础。
创新性地提出Lottery LLM假设,为LLM压缩研究提供了新的理论视角。
基于研究分析,明确了Lottery LLM和KV缓存压缩应具备的关键能力,包括从提示中检索信息、识别外部资源、规划调度、精确近似基本操作和长上下文推理等,弥补了现有方法在能力考量上的不足。
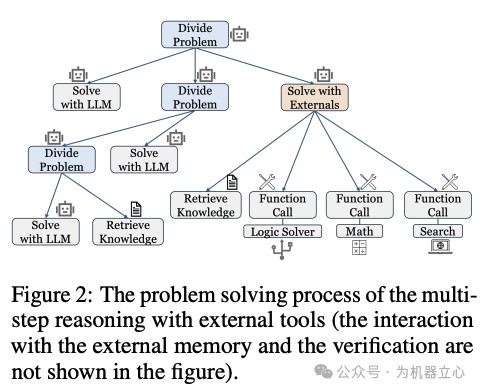
二、方法与理论
(一)模型压缩方法
当前典型的压缩算法包括对LLM参数的剪枝(如Sun等人、Frantar & Alistarh、Dong等人的研究)和量化(如Yao等人、Dettmers & Zettlemoyer、Dong等人的工作),以及KV缓存压缩(Zhang等人、Xiao等人的研究)。这些方法旨在减少模型参数或缓存大小,同时保持在基本语言任务(如Wikitext2、PTB)、常识知识问答任务和基本算术推理任务上的性能,但在实际工业场景和复杂能力维持方面存在缺陷。
(二)Lottery LLM假设相关理论
假设存在原始语言模型(f_{\theta}),对于输入问题(q)和标准答案(\mu),有性能评估指标(P(f_{\theta}(q),\mu))。同时假设存在较小的语言模型(g_{\phi}),在推理算法(\mathcal{A})的辅助下,(\mathcal{A})可涉及对(g_{\phi})的一次或多次调用,并结合外部知识库(\mathcal{D})、外部工具(\mathcal{C})和外部记忆(\mathcal{M})等,使得(P(f_{\theta}(q),\mu)\leq P(\mathcal{A}{g{\phi},\mathcal{D},\mathcal{R},\mathcal{C},\mathcal{M}}(q),\mu))成立。推理算法(\mathcal{A})采用分治策略,如在解决问题时,先判断是否能直接使用外部资源,若可则检索相关知识或工具;若不可则根据问题生成调度计划,分解为子问题并递归求解,最后聚合结果。该假设为研究较小模型在复杂环境下达到与大模型相似性能提供了理论框架,突破了传统仅关注模型参数和简单任务性能的局限,将外部资源和多步推理有机融入模型性能考量体系。
三、实验与结果
(一)实验设计
论文未明确提及特定的大规模系统性实验,但在阐述各研究方向时引用了大量相关研究的实验结果,这些实验涵盖了不同的LLM模型、任务类型和方法,通过对比不同设置下模型的表现来验证相关观点。例如,在算术问题解决实验中,对比了不同模型(如DIRECT Codex、CoT UL2 - 20B、CoT LaMDA - 137B等)在GSM8K、SVAMP等数据集上使用不同方法(如直接推理、思维链推理、PAL方法)的性能;在知识检索和问答任务中,对比了Llama - 3 - Ins8B等模型在有或无检索增强生成(RAG)时在PopQA、NQ等数据集上的准确率。
(二)数据集
文中涉及多种数据集,如用于算术推理的GSM8K、SVAMP、ASDIV、ADDSUB、MULTIARITH,用于问答任务的PopQA、NQ、ASQA,以及用于逻辑推理的PrOntoQA、ProofWriter、FOLIO、LogicalDeduction、AR - LSAT等。这些数据集涵盖了不同领域和难度层次的任务,能够全面检验LLMs在不同方面的能力。
(三)评估指标
根据不同任务采用了相应的评估指标,在算术问题中主要关注准确率,如在各算术数据集上不同模型方法得到的正确解题比例;在问答任务中则以准确率(如PopQA、NQ等数据集上的准确率)和其他相关指标(如ASQA的str - em、hit指标)来衡量模型性能;在逻辑推理任务中,通过比较不同模型在各逻辑推理数据集上的推理准确性(如简单推理与使用Logic - LM辅助推理的对比结果)来评估。
(四)主要实验结果
在算术问题解决方面,PAL方法(利用外部算术计算函数)显著提升了较小LLMs的性能,如在GSM8K数据集上,PAL方法使Llama - 3 - Ins8B模型的准确率达到72.0%,高于其他多数方法和模型组合。
在知识检索和问答任务中,使用RAG技术能大幅提高模型性能,如Llama - 3 - Ins8B模型在有RAG辅助时,在PopQA和NQ数据集上的准确率分别达到59.8%和54.0%,相比无RAG时提升明显。
在逻辑推理任务中,采用如Logic - LM等外部逻辑求解器辅助推理,较弱的LLMs(如GPT - 3.5)在某些情况下能接近甚至超越较强的LLMs(如GPT - 4),如在PrOntoQA数据集上,GPT - 3.5使用Logic - LM后的准确率(85.00)与GPT - 4简单推理的准确率(77.40)相当接近。
四、讨论与启示
(一)主要发现
知识检索方面,LLMs在知识检索性能上与信息流行度相关,且存在幻觉问题。RAG技术虽可缓解幻觉,但引发了模型内部知识存储与外部检索的权衡思考,表明自适应知识检索(如根据知识流行度决定存储位置)可能是优化方向。
外部工具利用上,调用外部工具(如算术计算函数、搜索引擎、逻辑求解器等)可显著增强LLMs性能,不同任务需适配不同工具,且模型需具备识别和调用合适工具的能力。
计算表达能力层面,不同架构的Transformer(基本架构、基于解码的架构、带外部记忆的架构)计算表达能力各异,解码步骤和外部记忆对其有重要影响,长序列处理和模拟图灵机能力是关键因素。
多步推理中,无论是单LLM调用(如采用蒙特卡洛树搜索等算法)还是多次LLM调用(如CoT - SC、Tree - of - Thought、Graph - of - Thought等方法),合理的推理策略都能提升性能,且规划调度和整合知识图谱等技术有助于解决复杂问题。
(二)批判性分析
研究主要基于已有研究结果的综合分析,缺乏自身统一设计的大规模实验验证Lottery LLM假设,可能存在不同实验间的偏差和局限性,影响结论的普适性。
对于关键能力的界定虽有一定理论和实验依据,但各能力之间的相互关系和权重未深入探讨,在实际模型压缩应用中难以精确平衡和优化这些能力。
在考虑外部资源(如知识库、工具)时,未充分研究资源的可靠性、更新频率和兼容性等问题,这些因素可能会干扰模型在实际应用中的性能。
五、局限性与未来工作
(一)局限性
当前的LLM和KV缓存压缩方法大多仅关注少数基本任务的性能指标(如困惑度、常识知识和算术推理),无法全面反映模型在复杂现实场景中的能力,易导致压缩后模型在实际应用中表现不佳。
研究指出在压缩过程中LLMs可能会丢失长上下文检索、生成和推理等高级关键能力,但未深入探究这些能力丢失的具体机制和量化影响,难以针对性地改进压缩方法。
(二)未来工作
设计并开展大规模实验直接验证Lottery LLM假设,精细调整和优化推理算法(\mathcal{A}),深入研究在不同任务和领域下较小模型达到与原始模型相似性能所需的条件和资源配置。
进一步剖析Lottery LLM应具备的关键能力之间的内在联系,构建综合评估体系,确定各能力在不同应用场景下的重要性权重,为模型压缩和能力保留提供更具操作性的指导。
加强对外部资源管理的研究,建立动态、可靠和兼容的外部资源生态系统,确保模型在利用外部资源时的高效性和稳定性,同时探索如何在模型训练和压缩过程中更好地融合外部资源知识。
六、个人思考
(一)优点
研究视角新颖,Lottery LLM假设打破了传统模型压缩仅关注参数和简单任务性能的思维定式,将多步推理和外部工具等因素纳入考量,为LLM压缩研究开辟了新路径,有望引导更高效、实用的模型压缩技术发展。
文献综述全面,系统梳理了LLMs在多个关键领域的研究进展,为读者提供了清晰的领域知识脉络,方便后续研究者快速了解前沿动态并在此基础上深入研究。
(二)缺点
如前文所述,缺乏原创性的大规模实验验证是一大缺陷,使得假设和结论的说服力在一定程度上受限,未来需投入更多精力构建实验体系来夯实理论基础。
在实际应用方面的探讨相对不足,虽然提出了理论和关键能力,但对于如何将这些成果落地到实际的LLM应用系统中,如在特定行业(医疗、金融等)的具体部署和优化,未给出详细的路线图和案例分析。
(三)潜在改进方向
借鉴其他领域成熟的实验设计方法,结合深度学习模型评估的最佳实践,构建一套标准化、可复现的实验框架来验证Lottery LLM假设,同时利用更多样化的数据集和任务场景,增强结果的可信度和泛化性。
与工业界合作,开展实际应用案例研究,针对不同行业的需求和数据特点,探索Lottery LLM在实际业务流程中的压缩和优化策略,如在医疗领域的疾病诊断辅助、金融领域的风险预测等场景下的应用,为产业升级提供技术支持。
(四)对未来相关研究的影响
为LLM压缩研究提供了新的理论基石和研究方向,后续研究可能围绕Lottery LLM假设展开更深入的理论拓展和实验验证,推动模型压缩技术从单纯的参数优化向综合能力保留与提升转变。
促使研究人员更加关注LLMs在复杂任务和现实场景下的性能表现,加强对模型推理能力、知识利用能力和外部资源交互能力的研究,有望促进自然语言处理领域在多模态融合、智能决策等方向的进一步发展,提升AI系统的智能水平和实用性。
注1
Lottery Tickets Hypothesis(彩票假设)为模型压缩领域带来了新的思路与方向。其核心在于探寻模型中那些对最终性能起关键作用的子网络结构,这类似于在彩票中找到中奖号码组合。以下将从其起源、核心思想、在不同模型架构中的体现、与其他相关理论的关联及在实际应用中的意义等方面详细阐述其理论基础。
起源与发展背景:Lottery Tickets Hypothesis最初源于对深度神经网络训练过程的深入观察与思考。在传统的模型训练中,人们往往关注整体网络的参数优化与性能提升,但很少探究是否存在某些特定的子结构或参数子集在决定模型能力方面起着更为关键的作用。随着模型规模的不断扩大和计算资源的紧张,研究人员开始尝试寻找更高效的模型训练与压缩方法,Lottery Tickets Hypothesis应运而生。它试图回答在复杂的神经网络中是否存在一种类似“彩票”的机制,即某些初始化的子网络在经过特定的训练后能够达到与完整网络相近甚至相同的性能。这一假设的出现引发了学界对模型内部结构本质的重新审视,推动了模型压缩、可解释性等多个领域的研究进展。
核心思想:该假设的核心在于认为在一个随机初始化的深度神经网络中,存在着一些子网络(即所谓的“彩票”),这些子网络在初始化时就具有良好的性能潜力。在训练过程中,如果能够恰当地识别并保留这些子网络,即使对原始网络进行大规模的修剪(如去除大部分参数),也能够保持甚至提升模型的性能。其关键在于找到一种有效的方法来识别这些潜在的“中奖彩票”子网络,通常涉及对网络参数的分析、不同训练阶段的观察以及特定的筛选策略。例如,通过在训练初期对参数的重要性进行评估,标记出那些对损失函数下降贡献较大的参数,进而构建出可能的“彩票”子网络。这种思想挑战了传统的模型构建与训练观念,为实现高效的模型压缩提供了理论依据,使得在不显著降低性能的前提下大幅减少模型的计算量和存储需求成为可能。
在不同模型架构中的体现:在卷积神经网络(CNN)中,Lottery Tickets Hypothesis表现为某些特定的卷积核组合或特征图通道可能构成了关键的子网络。例如,在图像分类任务中,研究人员发现部分卷积层中的某些滤波器在提取关键图像特征方面起着主导作用,这些滤波器及其相关的连接可以被视为“彩票”。通过对这些关键滤波器的保留和优化,能够在减少网络参数的同时保持较高的分类准确率。在循环神经网络(RNN)特别是长短期记忆网络(LSTM)和门控循环单元(GRU)中,特定的时间步长上的隐藏状态更新机制以及门控结构的部分参数可能成为“彩票”。对于处理序列数据(如文本、语音)的任务,某些关键时间步的信息处理单元在捕捉序列中的长期依赖关系和语义信息方面具有重要意义,对这些单元的有效识别和利用有助于构建高效的RNN“彩票”子网络,提高序列处理任务的性能并降低模型复杂度。
与其他相关理论的关联:与模型压缩领域的其他理论如剪枝方法紧密相关。传统的剪枝方法通常基于一定的规则(如参数的绝对值大小、梯度信息等)对网络参数进行删除,但往往缺乏对模型性能的有效保障。Lottery Tickets Hypothesis则为剪枝提供了一种更具理论指导的方向,即不是简单地基于规则删除参数,而是寻找那些具有潜在高性能的子网络进行保留和进一步训练。它与神经网络的泛化理论也存在联系,因为能够找到这些“彩票”子网络并使其在压缩后仍保持良好性能,可能暗示了模型在泛化能力方面的某些内在机制。即这些关键子网络可能捕捉到了数据的本质特征和分布规律,从而在不同的数据样本上都能表现出较好的性能,这为深入理解神经网络的泛化能力提供了新的视角和研究线索。
在实际应用中的意义:在实际应用中,Lottery Tickets Hypothesis为解决模型部署中的资源受限问题提供了有力的解决方案。在移动设备、边缘计算等资源紧张的场景下,能够利用这一假设对预训练的大型模型进行压缩,使其适应设备的计算和存储能力,同时保持较高的性能水平。在自然语言处理领域的机器翻译、文本生成任务以及计算机视觉领域的目标检测、图像生成等任务中,通过挖掘和利用“彩票”子网络,可以在不牺牲太多性能的情况下加速模型的推理过程,提高应用的响应速度和效率,促进人工智能技术在实际场景中的更广泛应用和落地。
近期活动推荐

 CVPR 2025结果出炉|一作讲者已开启招募,欢迎新老朋友来预讲会相聚!
CVPR 2025结果出炉|一作讲者已开启招募,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









