






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
个人信息
作者:陈晓栋,中国人民大学硕士研究生
摘要
模型剪枝是一类重要而且应用广泛的模型压缩方法,其通过移除神经网络中的冗余的结构或权重,在尽量保持模型准确度的前提下减少模型的大小,提高模型的计算速度。已有的结构化剪枝方法主要在宽度层面进行剪枝,亦即对隐藏状态大小、注意力头数或注意力维度进行剪枝,但这些方法剪枝出来的模型是不能直接部署的,需要用各个方法自己专用的框架来加载。
人大研究团队提出了一种新的模型剪枝方法,名为 LLM-Streamline。介绍该方法的论文发表在了 ICLR 2025 会议上。该方法通过判断模型层的重要性,并剪去不重要的层来降低模型参数量。这种方法只减少了层数量,所以可以用常用的方法加载模型,且性能相比已有方法高出很多。

论文地址:
https://arxiv.org/pdf/2403.19135
代码仓库:
https://github.com/RUCKBReasoning/LLM-Streamline
LLM-Streamline介绍
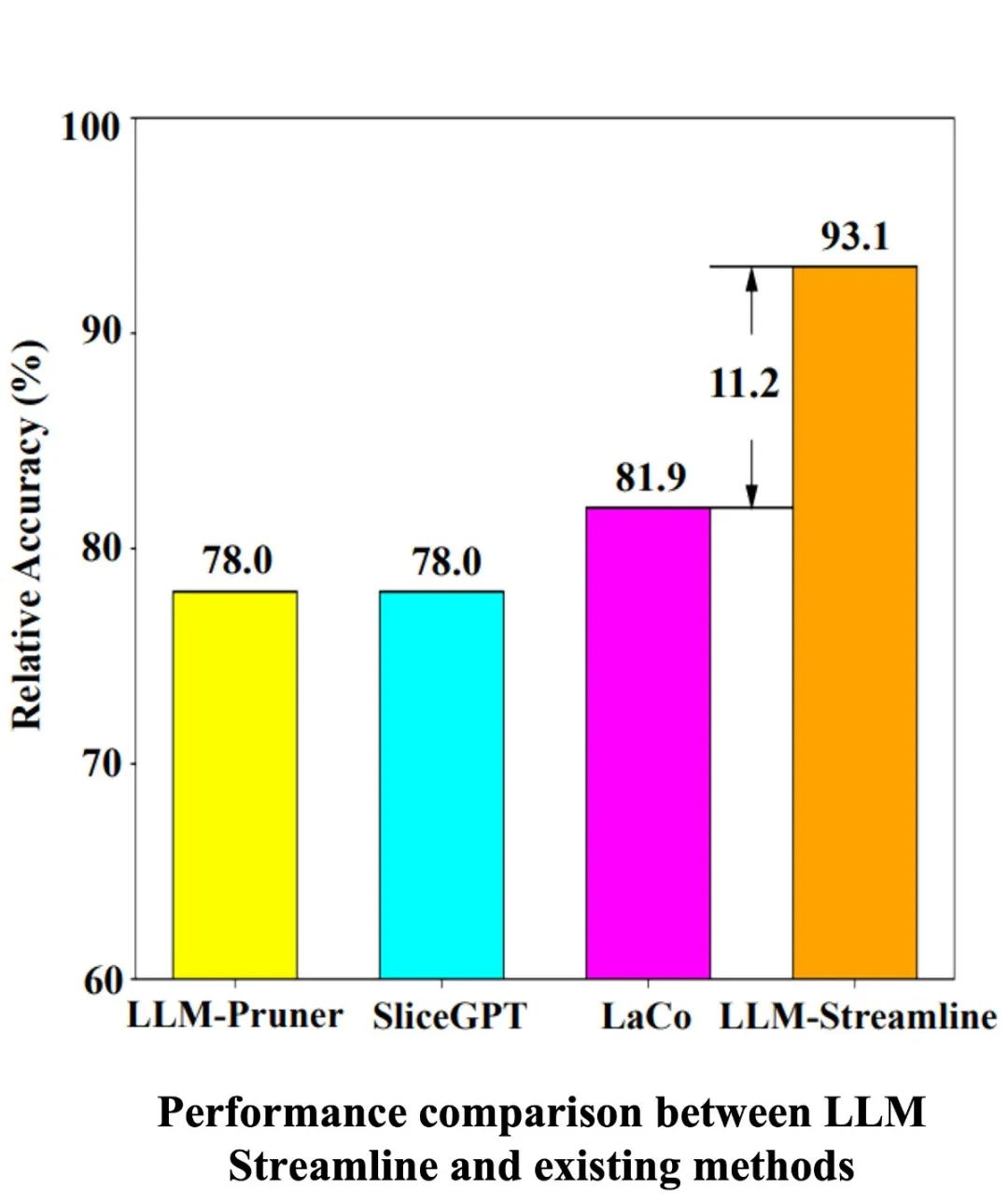
如下图所示,LLM-Streamline 的性能对比已有模型剪枝方法有着明显优势:
如图所示,LLM-Streamline 包括了层剪枝与层替换两个步骤:
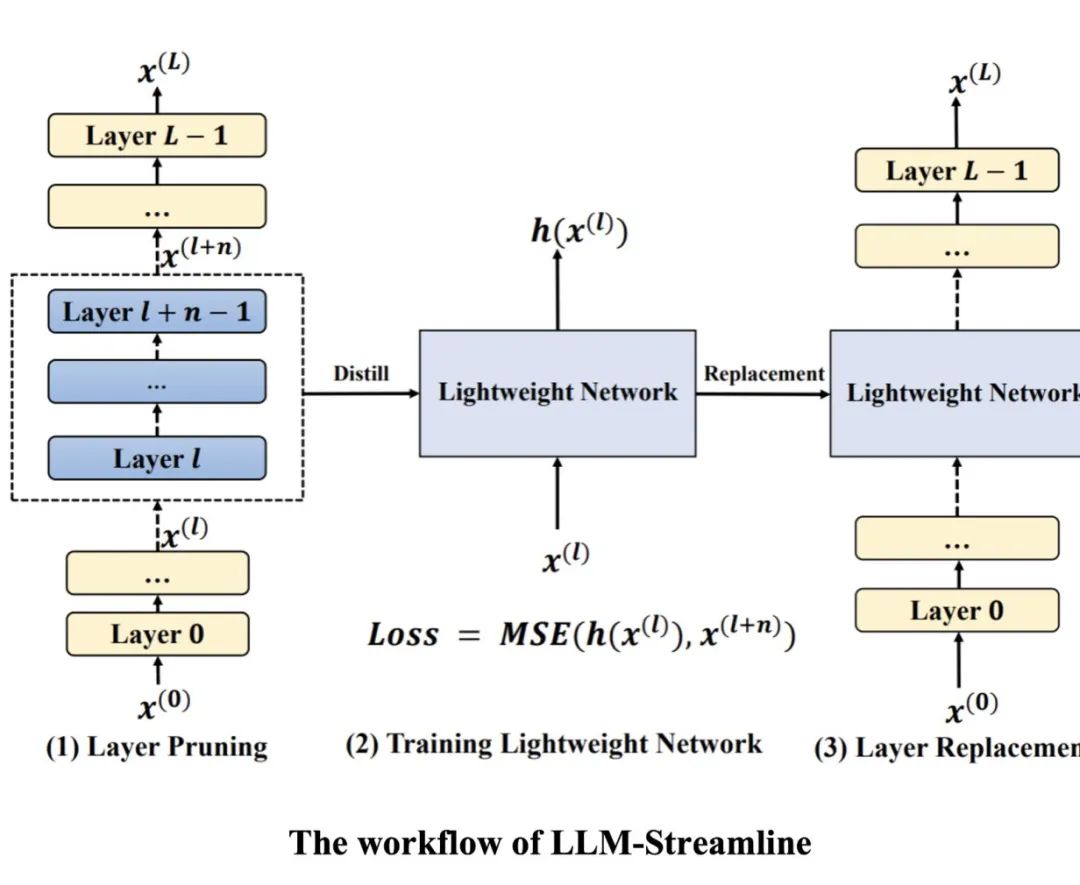
层剪枝阶段会通过输入与输出的余弦相似度来判断各个层的重要性,层替换阶段则训练了一个轻量级蒸馏小模型来弥补剪枝带来的性能损失。此外,团队发现使用准确度来衡量剪枝模型性能的方法有一定局限性,因此,又提出了一个新的指标——稳定性,来衡量剪枝模型的性能。
LLM-Streamline 提出的同期,业内也出现了多种基于层的模型剪枝方法,它们与 LLM-Streamline 的区别如下:
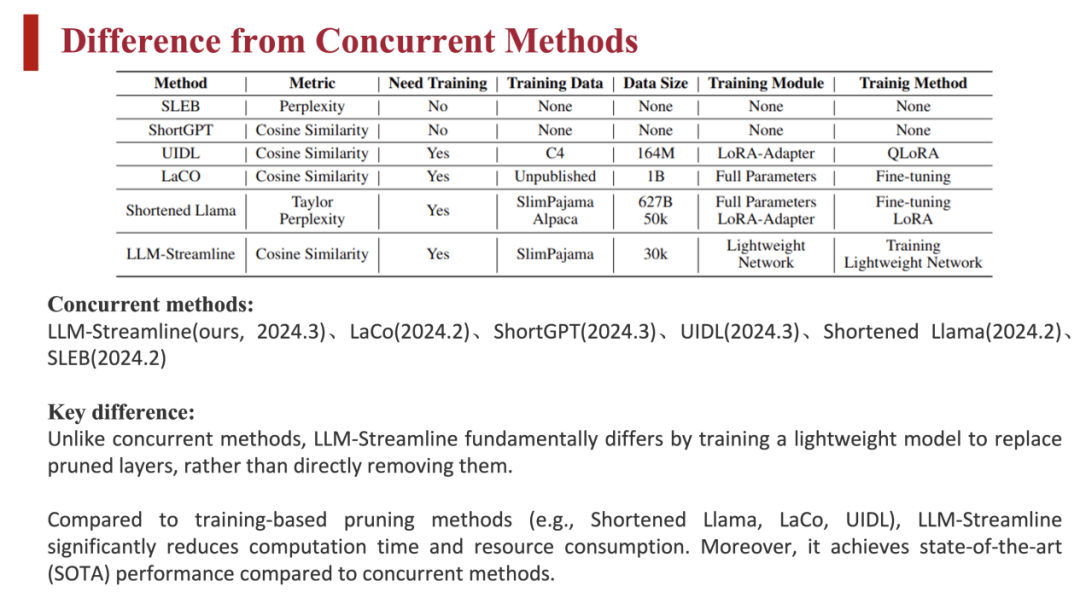
可以看到,其他方法也采用了余弦相似度来剪枝,也有使用困惑度剪枝的。LLM-Streamline 与其他方法的关键区别在于,其他方法都是对层直接剪枝,而前者则增加了层替换步骤来降低性能损失,最终结果会消耗更少的资源达到更好的性能。
该方法进行层剪枝的基本原理如下:

LLM 广泛使用 Pre-Norm 机制,因此只要衡量图中上式里 f() 函数的影响就可以判断层的重要性。该方法使用余弦相似度作为指标,是因为 Pre-Norm 导致模型层越深,隐藏状态规模越大,层点积就越大,导致 bias 增大,这样就不能用欧氏距离或者点积来判断重要性了。而使用困惑度指标时,用来剪枝的数据集会出现过拟合,导致剪枝后的模型对其他数据集泛化性下降。综合而言,选择余弦相似度指标是比较稳定的。
LLM-Streamline 的层替换机制如下:
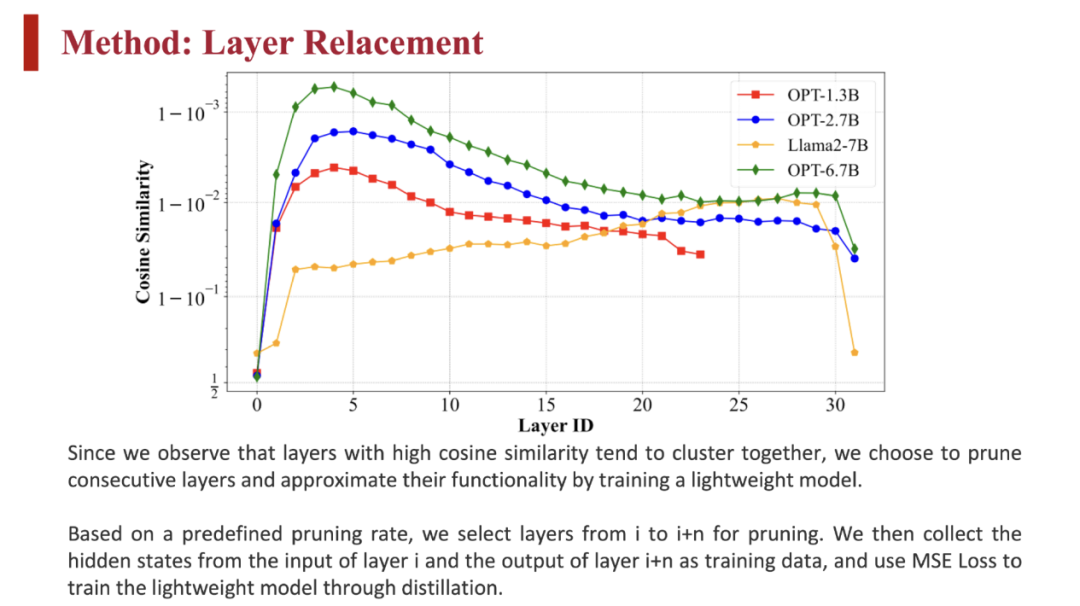
具有高余弦相似度的层倾向于聚集在一起,因此该方法会修剪连续的层。例如,可以根据预定义的修剪率选择从 i 到 i+n 的层进行修剪。从第 i 层的输入和第 i+n 层的输出中收集隐藏状态作为训练数据,并使用 MSE Loss 通过蒸馏来训练一个轻量级模型。
层替换方法与 LoRA 方法对比
过去结构化剪枝方法一般使用 LoRA 方法训练,而相比之下,层替换方法有着以下优势:
1. 更低的 GPU 内存消耗:层替换方法只需要在隐藏状态收集期间对原始模型进行前向传播的成本,并在训练期间仅训练轻量级网络,使其比 LoRA 更节省内存。
2. 更合理的训练方法:层替换方法会训练一个轻量级模型以接近连续修剪层的能力,而 LoRA 直接训练剩余的层。实验证明,用轻量级网络替换修剪层比训练剩余层更简单。
此外,虽然可以使用 SFT Loss 层进行训练,但它需要获取整个模型的概率分布,需要加载整个模型到内存中,而 MSE Loss 方法更节省内存,更适合资源受限的情况。但在资源丰富的场景中,使用 SFT Loss 训练比使用 MSE Loss 收敛得更快。
新的指标:稳定性
人大团队分析了广泛使用的准确度指标在评估剪枝模型性能方面的局限性,并提出了一种新的稳定性指标来更好地评估剪枝模型的性能。
首先,在没有任何训练的情况下对模型进行层剪枝,并在几个分类任务上测试了剪枝模型的性能。团队观察到,与原始模型相比,在某些任务中剪枝模型的性能意外提高了。为了进一步研究这一现象,团队使用混淆矩阵对其进行分析,将所有结果分为四类:
TP:原始模型和剪枝模型都正确回答了问题。
FN:原始模型正确回答了问题,但剪枝模型回答错误。
FP:原始模型回答错误,但剪枝模型回答正确。
TN:原始模型和剪枝模型都回答错误的问题。
另外,团队介绍了分类任务测试中困惑度及其标准差的计算过程,其中 M 表示原始模型,Xi 表示第 i 个样本的问题,Ci,j 表示该问题的第 j 个选项。
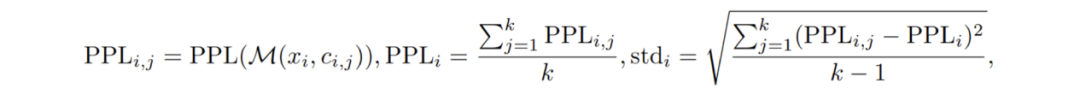
可以观察到 TP 和 TN 样本的困惑度标准差明显高于 FN 和 FP 样本。这表明该模型对 FN和 FP 样本的预测更加不确定。此外,FP 样本占总样本的相当大比例,这表明剪枝后的模型可能会猜测并正确回答很大一部分样本。这种现象表明准确度指标可能高估了剪枝后模型的性能。

因此,团队定义了一个新的稳定性指标来更好地评估剪枝后模型的性能。稳定性既考虑了模型对其预测的信心,也考虑了模型在剪枝前后输出答案的一致性。本质上,这个指标认为模型更加确信的题目才更加反映了模型的能力。
测试对比
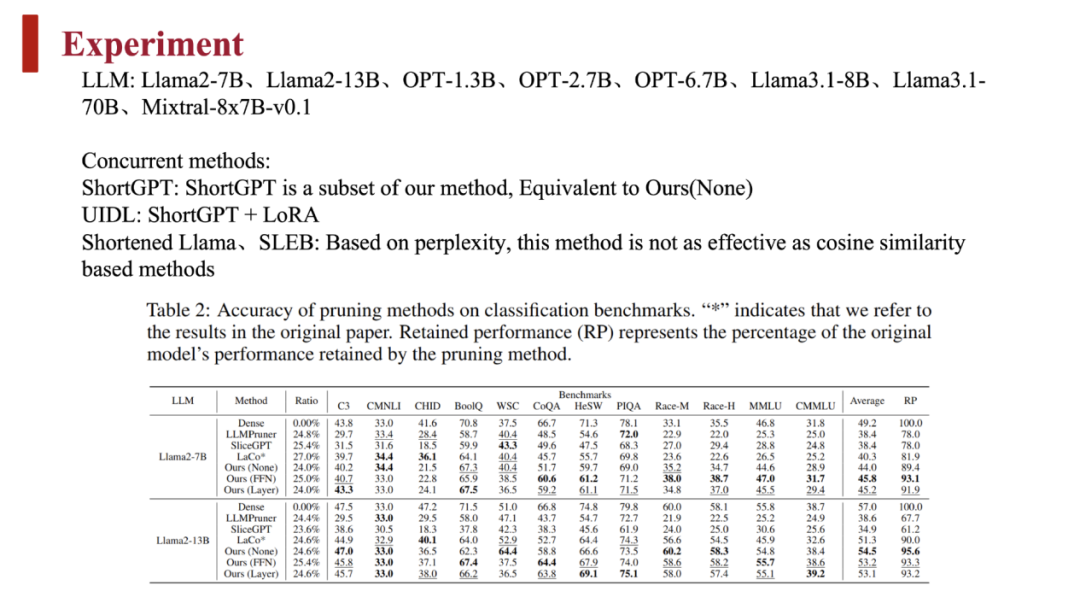
团队对比了 LLM-Streamline 与其他几种剪枝方法在多个模型上的结果,使用了准确度、稳定性指标分别对比,也对比了不同数据量下的结果:
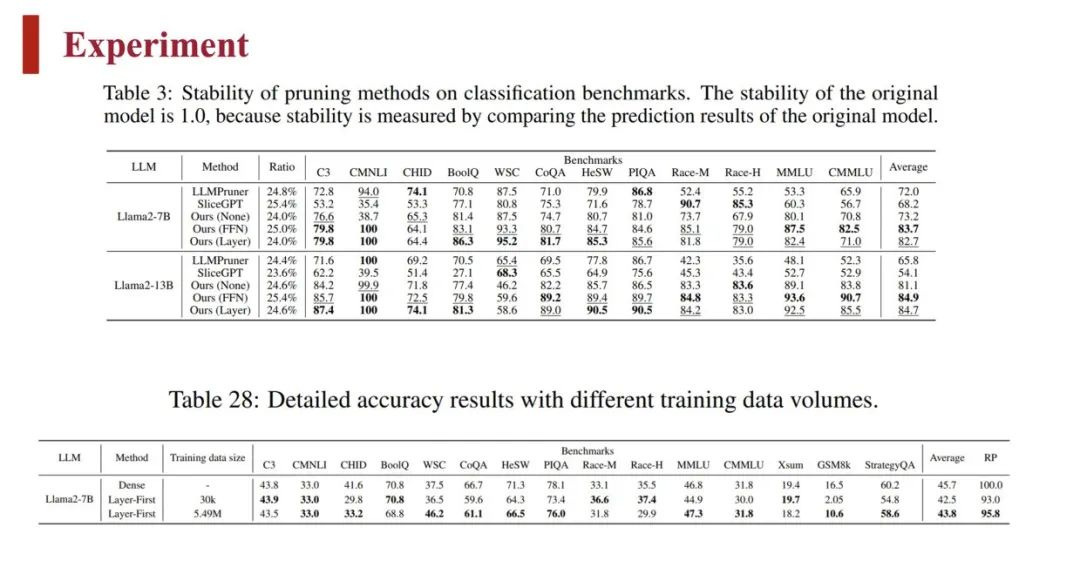
可以看到,数据量增大对分类任务性能影响不大,只会提升模型在较难的生成任务(GSM8k)上的性能。
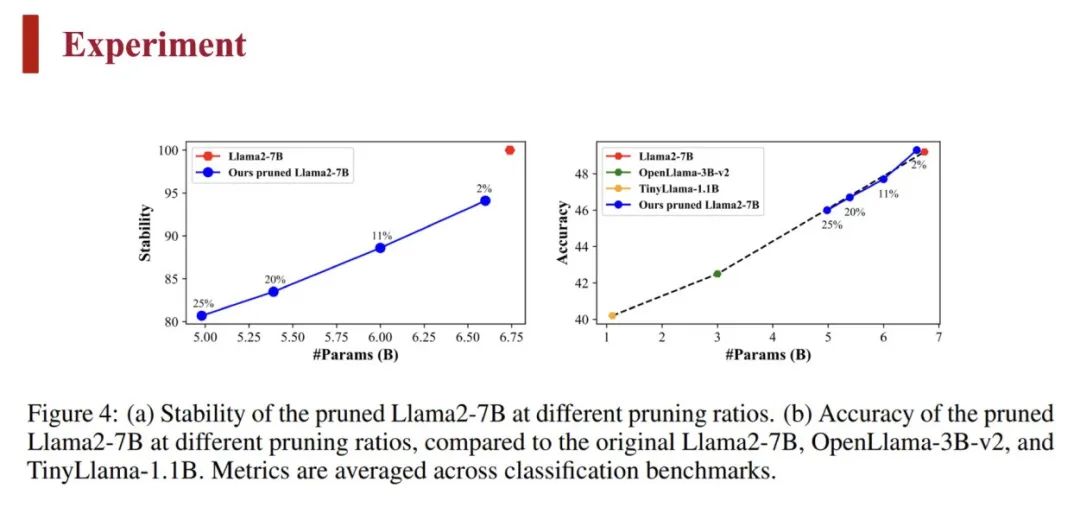
对比剪枝模型与预训练模型可以看到,两者的性能是呈近似线性关系的:
与 LoRA 方法对比发现,LLM-Streamline 的性能更强,且内存消耗量只有不到一半:
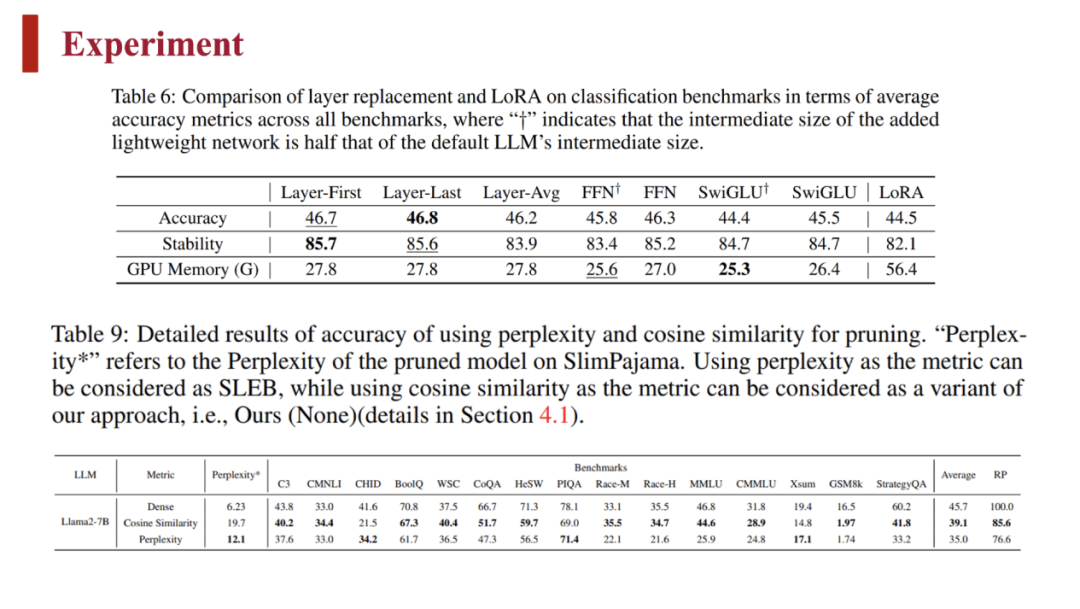
此外,余弦相似度指标要比困惑度指标的表现好很多,如上图表 9 所示。
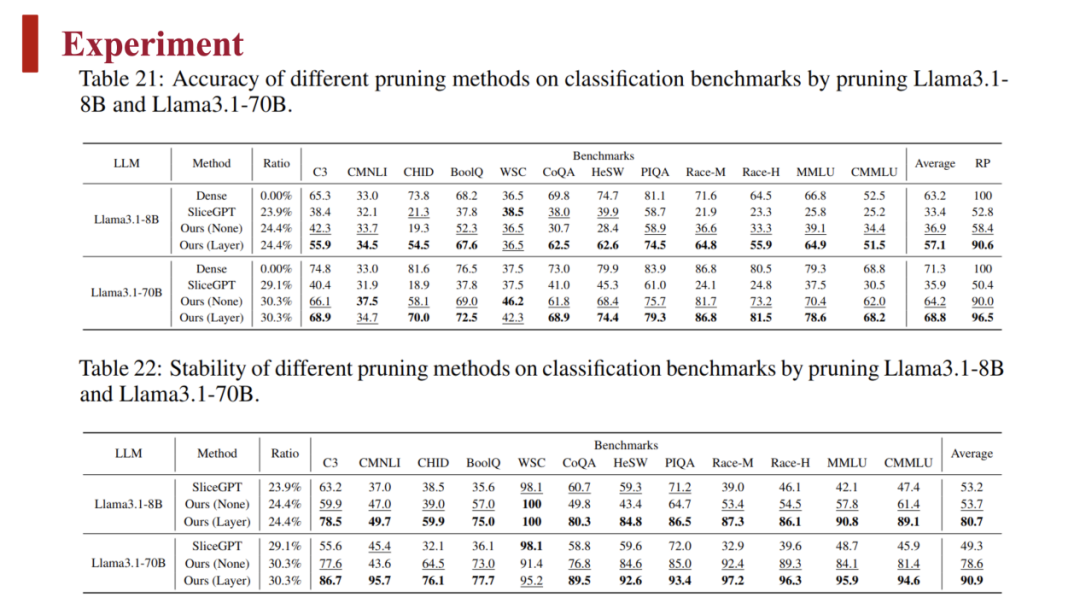
与原始模型Llama3.1-70B相比,该方法可以在降低 30% 的参数量情况下提供非常接近的性能(损失 3% 左右):
近期精彩活动推荐

CVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









