






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
个人信息
作者:赵望博,达摩院实习生
摘要
过去一年来,由 Sora 模型开始推动的 Diffusion Transformer(DiT)架构在视觉生成领域展现出了强大的能力,得到了包括 Stable Diffusion 3、Flux、Sora、WanX、Movie Gen 等众多视觉模型的应用。但 DiT 架构也面临一些重大挑战,其中最显著的就是运行效率问题。
业内提出了多种方法来解决这一问题,包括高效的 diffusion 采样器、特征缓存、注意力机制以及模型压缩剪枝等。但这些方法都是针对静态不变模型,即图像生成过程使用的模型规模完全不变,导致了潜在的冗余浪费问题。
对此,达摩院研究团队提出了一种名为 Dynamic Diffusion Transformer 的新方法。该方法从 timestep 和空间两个级别入手,根据不同 timestep 和图像复杂度所需的计算量来调整模型计算大小,从而降低计算冗余度,同时基本保持输出效果,实现较好的性能提升。
论文地址:
https://arxiv.org/abs/2410.03456
代码链接:
https://github.com/alibaba-damo-academy/DyDiT
Background
像在其他视觉和语言领域中的Transformer模型一样,Diffusion Transformer也面临显著的生成效率问题。然而,与 ViT 或 LLMs 不同,Diffusion Transformer中的多时间步生成范式本质上引入了额外的计算复杂性。此外,生成任务通常在空间区域上呈现出不平衡的难度,从而进一步加剧了效率问题。
为了提升 Diffusion Transformer 的推理效率。许多高效采样器和免训练加速技术在过去几年被提出,可以无缝地加入Diffusion Transformer来提升效率。同时,与这些技术相正交方案是结合传统的模型压缩技术,例如结构化剪枝,来降低Diffusion Transformer的推理开销。然而,剪枝方法通常在整个扩散过程中的时间步和空间维度上保留一个静态的架构。
如下图所示,原始Diffusion Transformer和剪枝后的Diffusion Transformer都在所有扩散时间步中使用固定的模型宽度,并对每个图像块分配相同的计算成本。这种静态推理范式忽略了不同时间步和空间区域所具有的不同复杂性,导致了显著的效率问题。
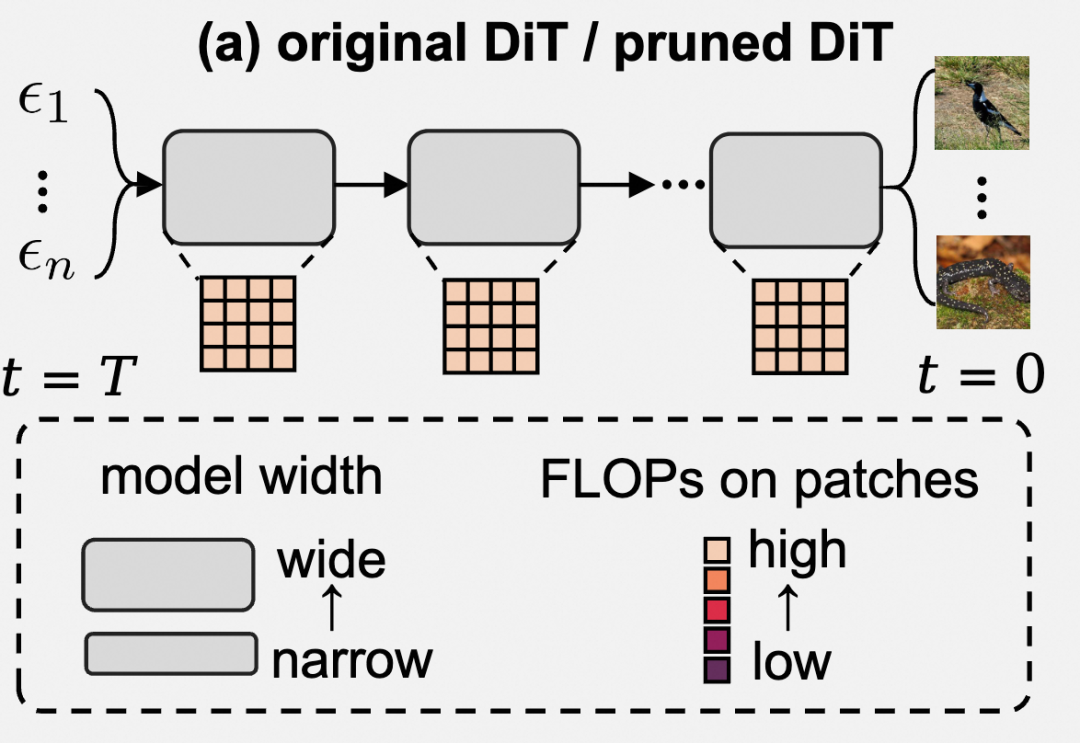
探索 Diffusion Transformer 的冗余问题
在研究新的 Diffusion Transformer 方法之前,首先要研究 Diffusion Transformer 架构中的冗余问题有多大。这里分别从两方面来研究:
第一个实验从 timestep 角度入手,对比经过预训练的一个小模型(DiT-S)与大模型(DiT-XL)在 ImageNet 上不同 timestep 上的损失差异,将它们的差值画成曲线:
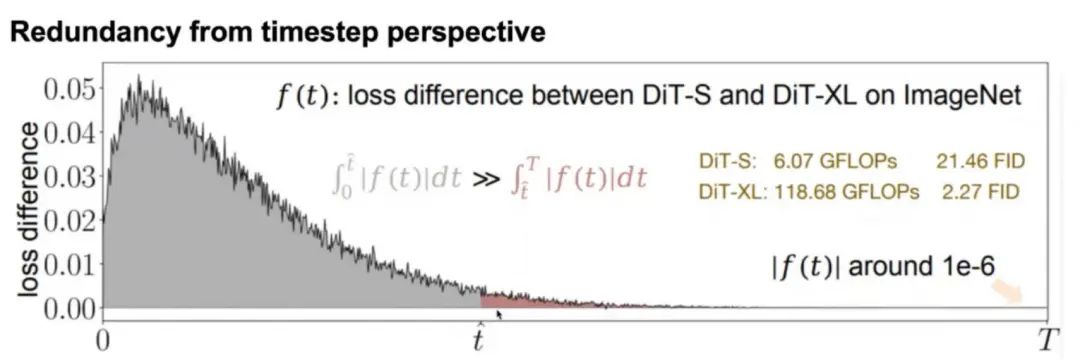
结果发现,T 较大(生成过程中趋于噪声)时差值较小,而 T 较小(生成过程中接近真实图像)时差值较大。这说明不同的 timestep 对应的任务预测难度是不同的,趋于噪声时小模型就能很好地处理,接近真实图像时就需要大模型。但如果一直使用大模型,就会在 T 较大时造成计算冗余。
第二个实验从空间角度入手。这里可视化了模型在不同 timestep 上的损失 map:
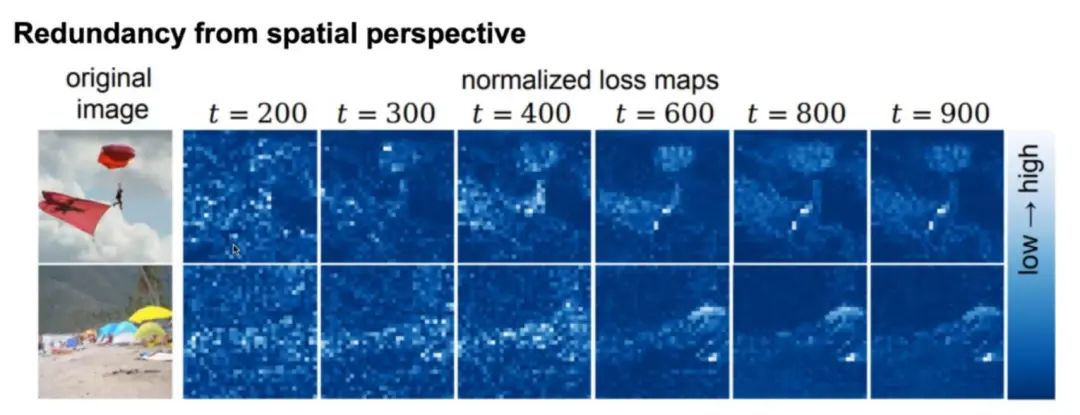
如图所示,白色区域的损失较高,蓝色区域损失较低。可以看到图像不同区域的预测难度是不同的,诸如沙滩、天空等特征接近的区域预测难度较低,而人物、物体等区域预测难度较高。显然,如果对所有区域都使用较大的模型预测,在低难度区域就会带来计算冗余。
在最近的工作中,我们还将Dynamic Diffusion Transformer进行了进一步的升级。主要包括三个部分:
1、验证对于flow-matching(流匹配)的支持。flow-matching的生成机制目前也应用在主流的生成模型中,我们验证了我们方法可以无缝衔接到其中。
2、扩展对模型的支持。目前视频生成模型和文本到图像生成模型在实际应用中十分广泛。我们将我们的方法进行针对性的升级,实现对主流生成模型,例如FLUX的兼容,使其达到了更好的性能效率平衡
3、提出了为Dynamic Diffusion Transformer专门设计的高效微调机制。降低了Dynamic Diffusion Transformer的训练参数量,显著降低显存占用。
提出Dynamic Diffusion Transformer 架构
团队基于上述研究提出了 Dynamic Diffusion Transformer 动态 diffusion transformer 模型架构。该架构的动态性表现在 timestep 和空间两个层面:
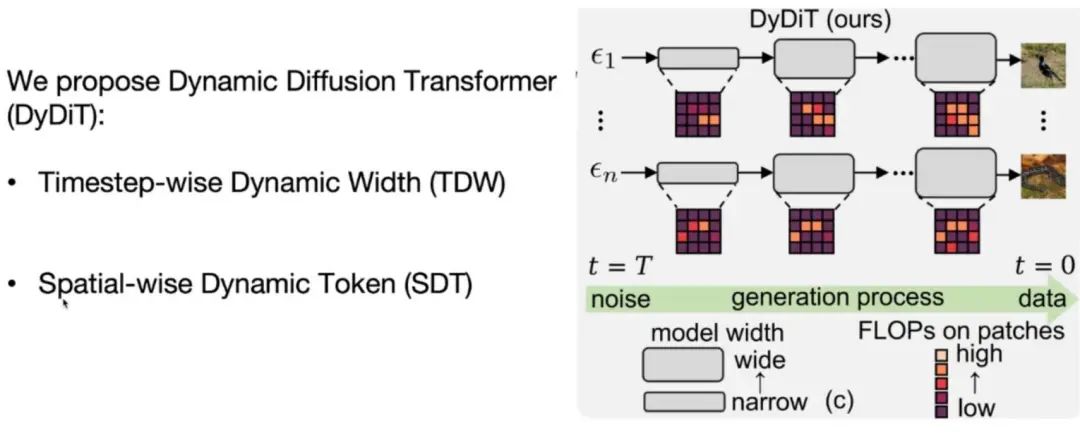
如图所示,该模型在生成过程中的不同步骤和不同图像复杂度上的模型大小是不一样的,从而尽可能降低计算冗余度。
1.Timestep 级别的动态性(TDW)
在 Diffusion Transformer 工作期间,timestep 信息 Et 是嵌入生成流程的,从而让模型知道自己当前处于哪一步。为实现 TDW,可以将 Et 输入两个 Rooter 中,分别是 Rchannel 和 Rhead。它们分别会学习每一步骤需要激活哪些 channel 或 head。根据 Rooter 的计算结果,模型就可以在每一步舍弃不需要计算的 head 和 channel 了。这里的 MHSA 为多头自注意力机制,MLP为多层感知机。每一个 Router 可以通过一层线性层来实现。
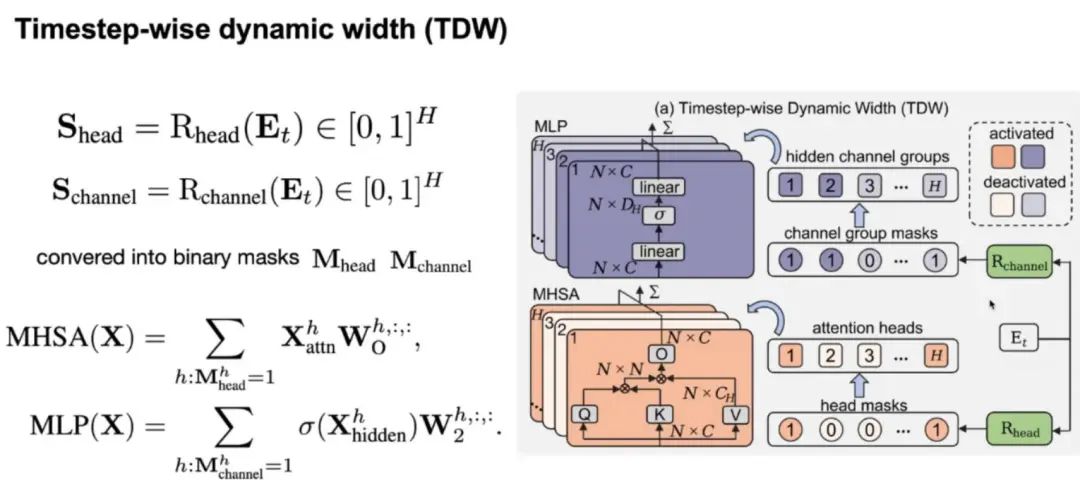
2.空间级别的动态性(SDT)
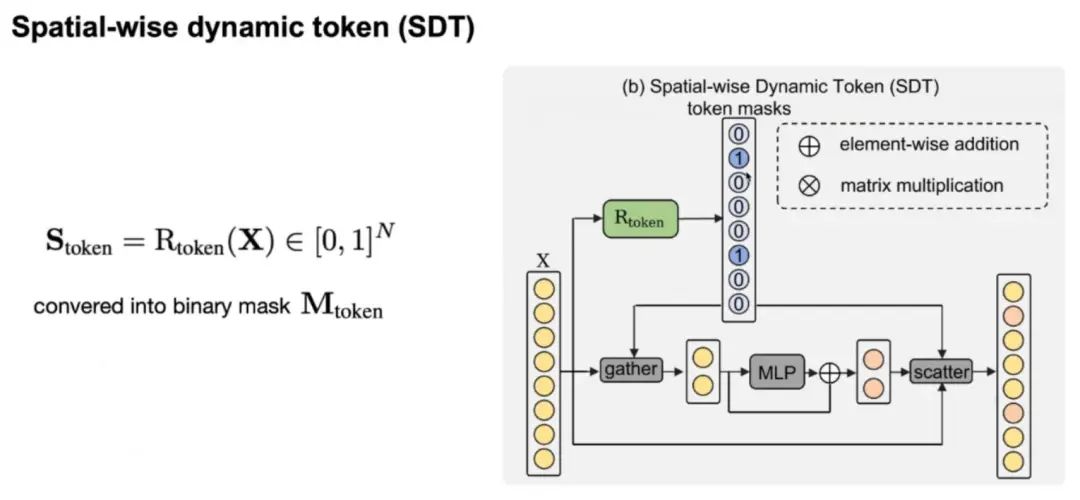
在空间级别,同样需要引入一个 Rooter(Rtoken)来预测每帧图片输入 token 中需要计算的部分,得到一个token mask,mask的值为0代表该 token 不需要计算,而 mask 的值为 1 代表该 token 需要计算。随后我们可以根据 mask 使用gather操作将那些需要计算的 token 取出输入到 MLP 中计算,随后再使用scatter操作将计算结果与原始输入合并。 这里我们只针对 MLP 使用 SDT 而不针对 MHSA 的原因是,我们发现对 MHSA 进行这个操作会对性能影响较大,另外 MHSA 有很多基于稀疏注意力的改进方案,可以即插即用,所以我们这里不对 MHSA 做这个操作。
3.根据计算量节约目标调整训练过程
上述两个方法都存在一个 Mask,可以利用这些 Mask 计算网络当前的整体计算量,再计算原始 Diffusion Transformer 的计算量,对比两个计算量的比值就可以得到动态模型计算量的节约程度:

通过调节上述公式中的 λ 为我们预期的计算量比值,例如0.5,与原始的DiT loss进行训练,模型就可以学习到如何在保证性能的前提下,让计算量符合预期。
4.性能表现
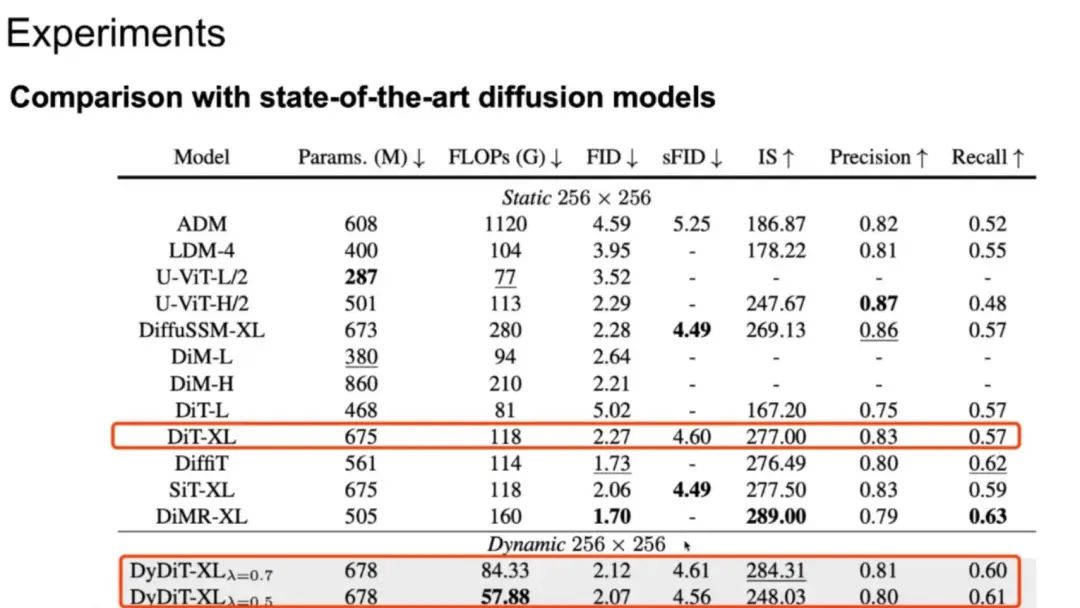
对比发现,将 DiT-XL 模型改进为 DyDiT-XL 动态架构后,模型计算量有了明显下降,同时 FID 得分与原模型基本相当。与其他生成模型对比,动态模型的计算量是最低的,各类指标都有一些优势。
团队也探索了动态架构在不同模型大小上的 Scaling up 能力:
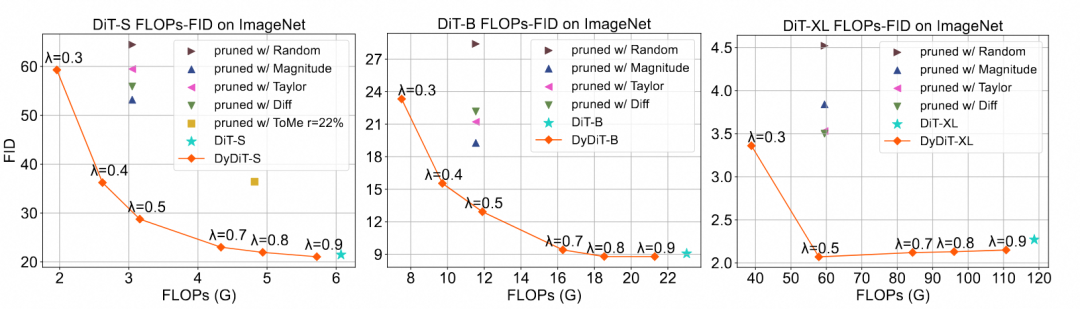
可以看到在较小模型(DiT-S)上,在基本维持输出效果的前提下可以节约的模型计算量是较小的(λ 需设置为 0.9);而在中等模型(DiT-B)上 λ 可以设置为 0.7,较大模型(DiT-XL)上 λ 可以设置为 0.5,节约的计算量较多。这也表明随着模型增大,计算量的冗余度也随之提升。
团队还可视化了不同 timestep 时动态模型激活 head 和 channel 的情况,当接近噪声端时,任务预测难度较小,需要激活的模型资源较少:
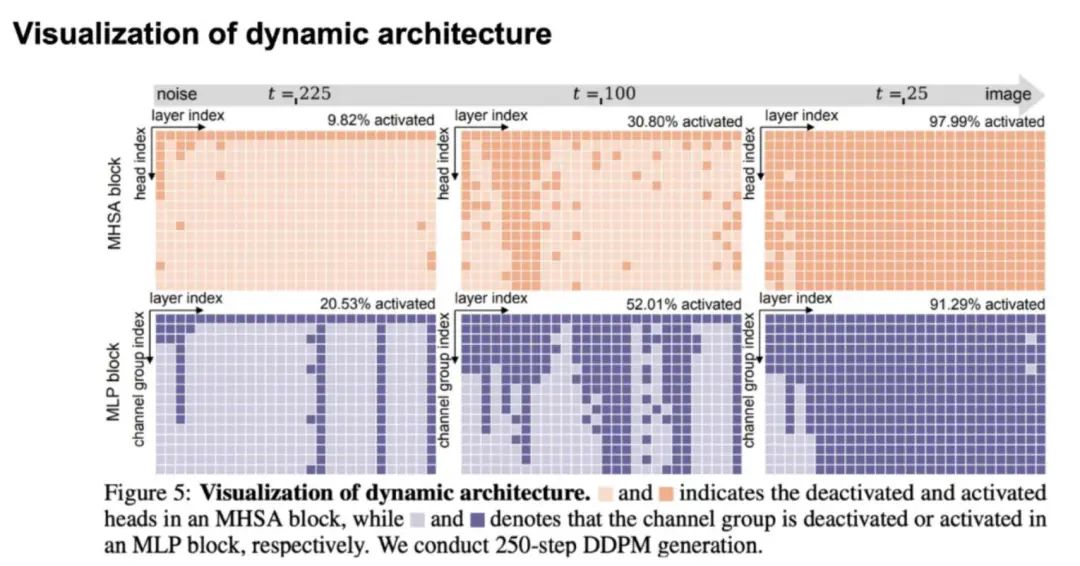
团队也可视化了不同图像区域需要的计算量差异,可以看到简单背景/物体所需的计算量较少:

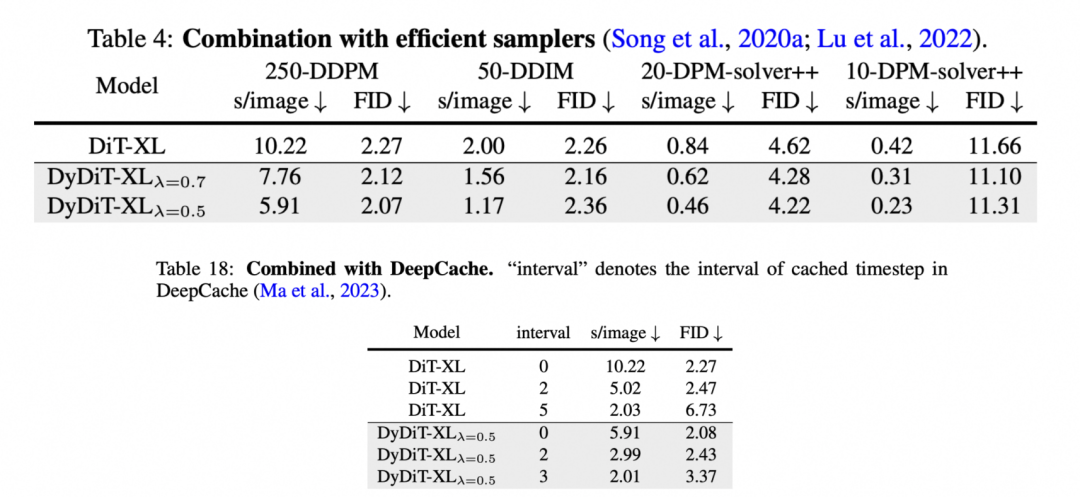
动态方法也可以同其他加速方法,如高效采样器、DeepCache 等方案结合进一步提升性能:
后续工作方向
1、除了基于扩散模型之外,流匹配模型是否存在类似的冗余计算问题?如果存在能否直接应用我们的Dynamic Diffusion Transformer?这些都是值得探索的问题。
2、原始的Diffusion Transformer只是为类别到图像生成而设计的,基于它的变体已经在更复杂的生成任务上展示出来出色的能力,例如视频生成和文本到图像生成上。我们将会把 Dynamic Diffusion Transformer 的设计迁移到更多业界通用的视频生成或者文本到图像生成模型上,提高它在实际应用中的价值。
3、Dynamic Diffusion Transformer目前还依赖于全量参数微调,尽管收敛速度较快,这依然带来了不小的训练开销。如果能够借助于现有的高效微调技术, 则可降低获取动态模型的成本。
目前,达摩院团队已经将后续工作的内容更新到了最新期刊拓展版论文中(https://arxiv.org/abs/2504.06803)。为了促进社区发展,Dynamic Diffusion Transformer和Dynamic Diffusion Transformer支持下的 FLUX 版本的代码和权重也已经在项目仓库中开源。
近期活动推荐

ICVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









