







目录
10.1 自然语言处理模型
在自然语言处理中,语言模型是一个非常重要的模型,它用于计算“一句话是合理的”的概率。例如,P(我喜欢吃饭)>P(我你哦)。“我喜欢吃饭”为常见句。“我你哦”作为病句,几乎不会出现,其概率应该如何计算呢?“我喜欢吃饭”对应于4个词,w_1=“我”,w_2=“喜欢”,w_3=“吃”,w_4=“饭”,概率记为 P(w_1 w_2 w_3 w_4),即顺序排列的一系列词所对应的联合概率密度分布。需要注意的是,概率和词的顺序有关,即“饭喜欢吃我”对应于概率 P(w_4 w_2 w_3 w_1) 且 P(w_1 w_2 w_3 w_4)≠P(w_4 w_2 w_3 w_1)。P(w_1 w_2 w_3 w_4) 可用贝叶斯定理进行化简,如下式所示。
P(w_1 w_2 w_3 w_4 )=P(w_1 )×P(w_2│w_1 )×P(〖w_3 |w〗_1 w_2 )×P(w_4│w_1 w_2 w_3 )
其中:P(w_1) 表示词 w_1 出现的概率;P(w_2 |w_1) 表示第一个词为 w_1 时,第二个词为 w_2 的概率;P(〖w_3 |w〗_1 w_2) 表示前两个词为 w_1 和 w_2 时,下一个词为 w_3 的概率……依此类推。
不失一般性地,对于由 n 个词构成的句子,语言模型可以写成如下形式。
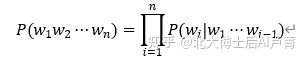
上式在估计概率时有一个明显的缺陷,就是运算量过大。例如,中文有200000个常见词,那么在估计 P(〖w_3 |w〗_1 w_2) 时,w_1、w_2、w_3 各有200000种可能性,因此,需要估计 200000^3 个概率(这几乎是一项不可能完成的工作)。而且,随着句子中词数的增加,P(w_i |w_1⋯w_(i-1) ) 所对应的概率数量将以指数级增长。
为了简化问题,假设一个词的概率仅由其前面的 n-1 个词决定,这种模型称为n-gram模型(n-1 个前面的词和待预测词本身)。假设一个词出现的概率仅受其前一个词的影响,此时模型称为2-gram模型,公式如下。
P(w_1 w_2 w_3 w_4 )=P(w_1)×P(w_2 |w_1)×P(w_3 |w_2)×P(w_4 |w_3)
不失一般性地,2-gram可以写成如下形式。
P(w_1 w_2⋯w_n )=∏_(i=1)^n▒P(w_i |w_(i-1) )
特别地,P(w_1 |w_0 )=P(w_1 )。此时,待估计的概率有 200000^2 个,且不受句子长度的影响,n-gram语言模型具备了可操作性。
那么,概率该如何计算呢?类似于朴素贝叶斯算法,通过数据统计,将频率值作为概率的估计值。例如,估计2-gram模型的相关参数,语料中有以下4句话。

w_1 一共出现了4次,w_2 紧接着 w_1 出现的次数为2次,因此
P(w_2│w_1 )=2/4
同理,可得 P(w_3│w_1 )=1/4。因为在语料中 w_6 从未紧接着 w_1 出现,所以 P(w_6│w_1 )=0。
将语言模型的概率写成公式,具体如下。
P(w_2│w_1 )=(count(〖w_2;w〗_1))/(∑_w▒〖count(w;w_1)〗)
其中,count(w;w_1) 表示 w_1 后面为 w 的次数,∑_w▒ 表示遍历所有的 w_1 后面的那个词。
P(w_6│w_1 )=0 真的准确吗?不一定,很可能因为数据量不够或数据选择有偏差而导致计算错误。由此可知,在直接使用频率作为概率进行估计时,如果有些小概率情况没有在语料中出现,其概率就会直接被计算为0。为了避免出现这个问题,可以使用平滑法,具体如下。
P(w_2│w_1 )=(δ+count(〖w_2;w〗_1))/(δV+∑_w▒〖count(w;w_1)〗)
其中,δ 是人为设置的超参数,V 为词表中的总词数。
用平滑法重新估计概率。因为在本例的语料库中一个有6个词,所以 V=6。将 δ 设为1,有

本节讲解了自然语言处理中语言模型的作用和计算方式。需要注意的是,在真实的自然语言中,n-gram算法有一定的局限性。例如,在“我喜欢吃苹果,它酸甜、营养、解渴”这句话中,决定“解渴”的词并不是它前面的“营养”“酸甜”“它”,而是“苹果”。这就是自然语言处理中的长距离依赖问题。
n-gram模型为了解决长距离依赖问题,只能增大 n 的值,但这会给概率估计造成困难。在n-gram语言模型中,通常取 n=2(n=3 就到达极限了)。
统计语言模型的一个缺点是,缺乏对语义信息的利用。在使用概率进行统计时,词之间是完全独立的。例如,P(西瓜|吃) 和 P(香瓜|吃) 的计算是完全独立的,概率估计无法利用“西瓜”和“香瓜”这两个词的相似性。不过,尽管在一些场景中使用n-gram算法时效果会打折扣,但它仍然是一个可以落地的方法,且实践证明,它的精度损失在可接受范围内。
本节介绍的语言模型是从统计学的角度实现的,虽然简单,但效果有限。接下来,我们将从机器学习的角度讨论如何构建语言模型。
10.2 one-hot编码和embedding技术
语言模型的核心是通过前词预测后词出现的概率,这在机器学习中是一个典型的多分类问题。假设词表中有 V 个词:输入词可以使用one-hot方式进行编码,即每个输入词对应于一个 V 维向量,输入词所对应的向量串联起来就可以作为输入特征;输出也是一个 V 维向量。
例如,使用3-gram模型预测 P(w_3 |w_1 w_2),网络结构如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









