






模型介绍:
这是目前最强大的开源AI绘画模型之一,它不仅可以在普通电脑上运行,而且根据Stability AI社区许可协议提供多种使用权限。现在你可以从Hugging Face下载Stable Diffusion 3.5 Large和Stable Diffusion 3.5 Large Turbo模型,相关代码也已在GitHub开源。

使用教程:
1、注册算力云平台:星海智算
进入星海智算平台,点击【GPU实例】,即可创建实例。
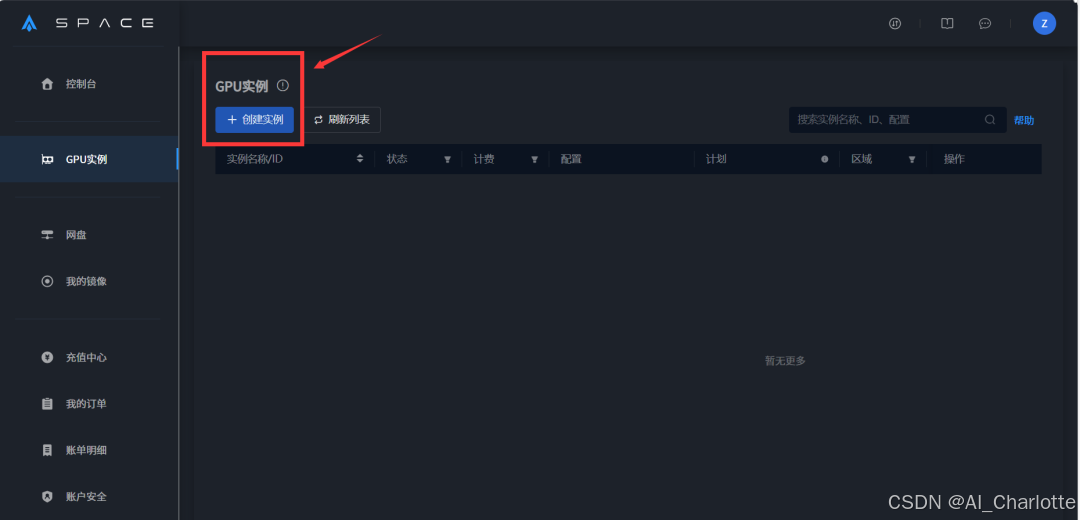
2、在【选择配置】中,可选择不同区域的显卡。
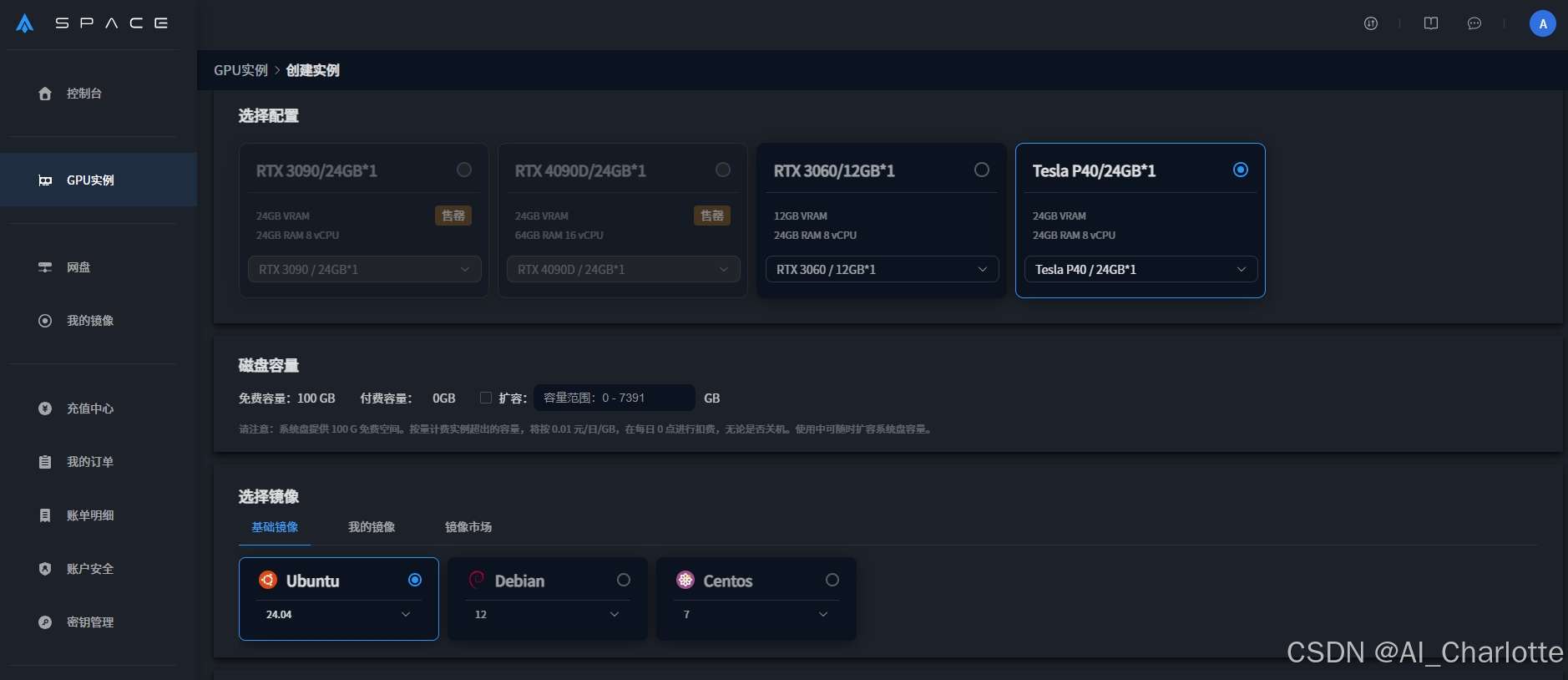
3、在【镜像市场】点击更换镜像,选择木木夕_SD3.5L-网页版镜像,确认后在实例创建页面点击<立即创建>即可。

4、创建成功等待4-5分钟,看到<运行中>即可开始使用,点击应用链接即可跳转到对应的WebUI。

5、待程序打开后呈现的就是Stable Diffusion3.5L-网页版主页面
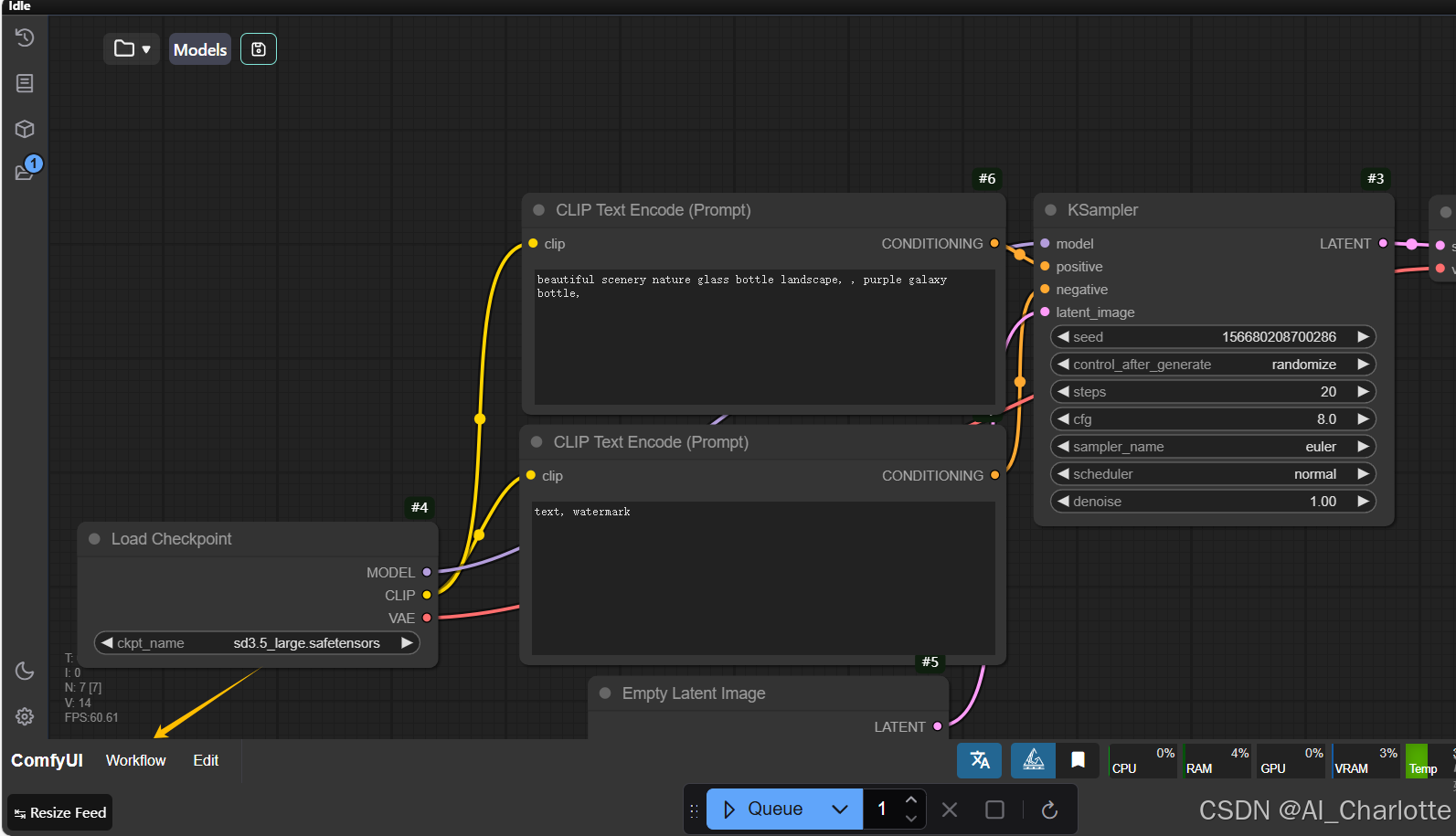
首先,点击左下角的【Workflod】工作流,选择【Browse Templates】浏览模板就可以看到四种不同的工作流类型,我们选择第一种SD3.5L-网页版的文生图工作流,在栏中输入正向提示词,例如输入:
A young woman stands confidently in a minimalist black Dao袍, its loose and flowing design contrasting with the lush peony garden around her. The Dao袍's wide sleeves and open front reveal glimpses of her form, while the deep black fabric absorbs the vibrant colors of the surrounding flowers, creating a striking visual effect.
【一位年轻女子自信地站在一件极简主义的黑色道袍中,宽松飘逸的设计与她周围郁郁葱葱的牡丹园形成鲜明对比。道袍的宽袖和敞开的正面露出她的身材,而深黑色的面料吸收了周围花朵的鲜艳色彩,营造出引人注目的视觉效果。】
点击中间的【Queue】队列按钮就能开始运行了
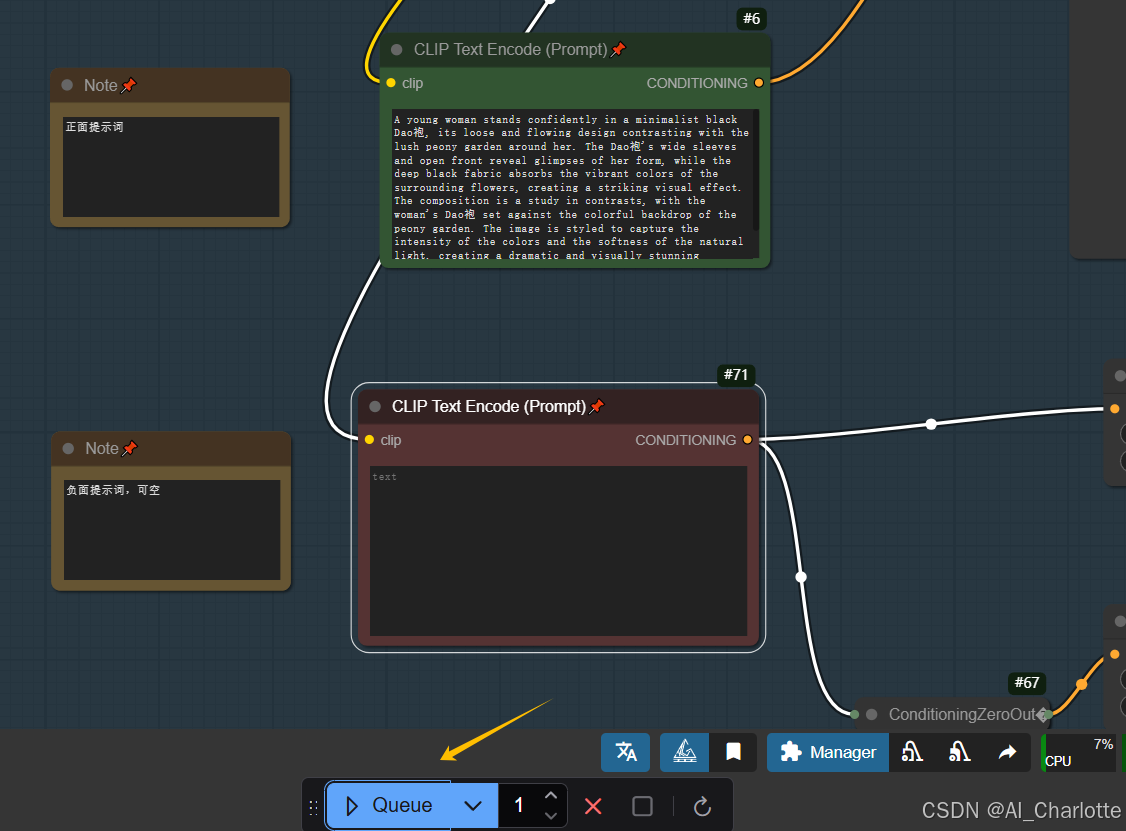
等待一段时间,最右侧就是生成的效果了。
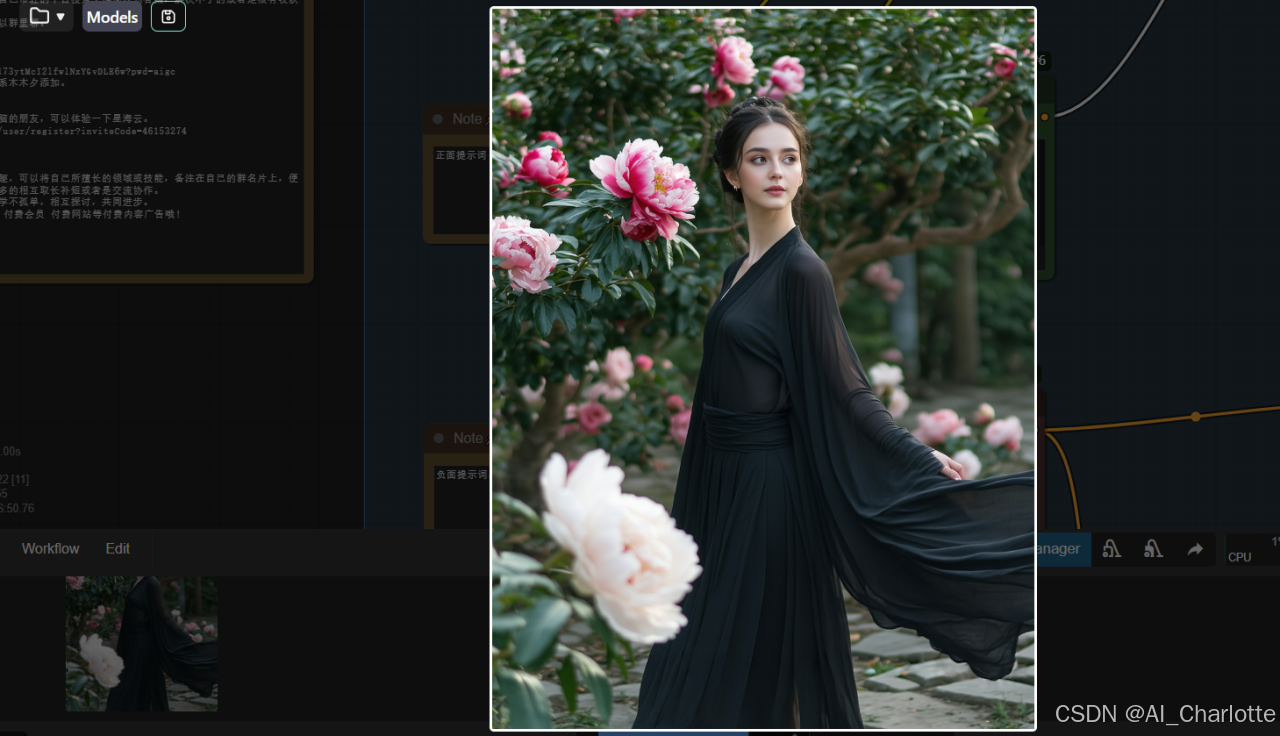
最后,看一下完整的图,Stable Diffusion 3.5L-网页版在图像质量、字体处理、复杂提示理解以及资源效率方面都实现了显著提升。它能够生成更清晰、更细腻的图像,尤其在细节捕捉和整体视觉效果上有质的飞跃。

作品展示:


了解更多详情看下方:![]()

















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









