








虽然笔者是一个测试老人了,但是基本上所有的测试经验都停留在手工测试方面,对于自动化测试方面的实战经验少之又少,可以说,从这个角度来说,就像生活在原始社会,一切靠双手解决问题。
其实,究其原因:
- 一方面是自动化方面不求上进,觉得会手工测试就可以了,自动化就能躲就躲吧;
- 另一方面是,觉得自动化是个慢慢积累的过程,不是那么容易学会的,既然不是那么学会的,那是不是就先不学了…
然后,就一拖再拖,能拖就拖,殊不知,自动化已经逐步成为测试领域必备的生存技能了。
所以,为了顺应测试行业发展的潮流,我就开始了从测试“原始人”到测试“现代人”的转变。
考虑到python语言相对于大部分语言的语法简单,容易上手的特点,再加之python在自动化测试方面的广泛应用,我选择了python语言进行学习。
01、菜鸟是怎样炼成的
这一部分主要讲讲从一无所知到正式入门,Python从零开始学习的步骤.
1、基本语法的学习——打铁还需自身硬
首先,找一个适合零基础的学习网站,粗略过一遍python基本语法,推荐:
- https://www.sharetechnote.com/
- https://www.runoob.com/python/python-tutorial.html
Str、List、dict、set、loop、if等等,这些都是最最基本的语法知识。
需要注意的是,学习教程中的练习实例,一定要一步一步跟着敲下来,这样学习效果最佳。
等到基本语法学的差不多了,就可以直接进入实战阶段了。
需要特别指出的是,没有必要在语法方面反复看,看过一遍基础就可以了,看再多遍也只是纸上谈兵,重要的还是通过实战来巩固前面学习到的知识,也更加深对语法的使用技巧的理解。
2、项目实战——上阵练兵
有了一些语法基础之后,接下来要结合项目,实现一些自动化功能。或者,如果没有合适的项目进行练习,给自己定一个目标作为项目,限定时间,实现一定的功能需求
我学习python的时候,由于项目中有一个几乎是日常需要做的事情,比较适合进行自动化,提高工作效率。
具体需求是这样的。从客户返回的产品日志log中提取关键信息,然后以固定的模板填写excel表格,回传给客户。
再详细一点呢,就是从txt多个文件和excel文件中,提取某些数据的值,填写到表格中,便于做问题定位和分析,其中涉及到平均值、最大值,同时涉及到几种固定的类别。
接下来我就来说说,我是如何完成这个项目的。
第 1 则 -THE FIRST
程序初版面世:
通过日夜奋战,到处求医问药,搞定功能
第一步
最开始,从待处理的txt文件出发,先实现一些特点比较明显的,看起来比较简单的数据处理,比如搜索含有特定的关键字的所有行,然后,取这些行中某一特定位置的值,然后计算这些值的平均值。
大体思路是:
1、 遍历txt文件中所有的行
2、然后通过关键字搜索
3、 搜索到的行,通过一定的字符进行分割,然后存为list
4、按照list下标取值,然后把所有的值加起来求和,再除以个数
虽然我知道这个方法不是最聪明最快的,但是我知道它是我当前的水平能做到的一种方法,至少能实现功能,满足项目需求。
这个阶段学习到的方法是:
open()打开文件
readlines()读取行
find()找到关键字,后来发现find只能找到一次,并且返回值是所在的位置,不方便,随后改为使用if X in Y来实现了
re.split。
这个阶段,用到的基础知识点是list、for循环、str。
第二步
随后,另一个需求随之而来,我上面计算出来的值,得想个办法存下来,等自动化执行完之后,好去统计,然后填表。
因此,我想了一个办法:把重要数据print出来,然后把执行的log保存下来(从网上找的方法),然后人工进行查看和填表。
这个阶段学习到的方法是:
class类
write写文件
第三步
后来发现,这种方法的工作效率貌似有点低,明明是很高大上的自动化,怎么成了半自动化了?
所以,我想到的是,把计算出来的数据,保存成表格,然后去表格里查看,就不用从茫茫执行记录里边去找了。
这个阶段学习到的方法是:
读EXCEL的模块xlrd
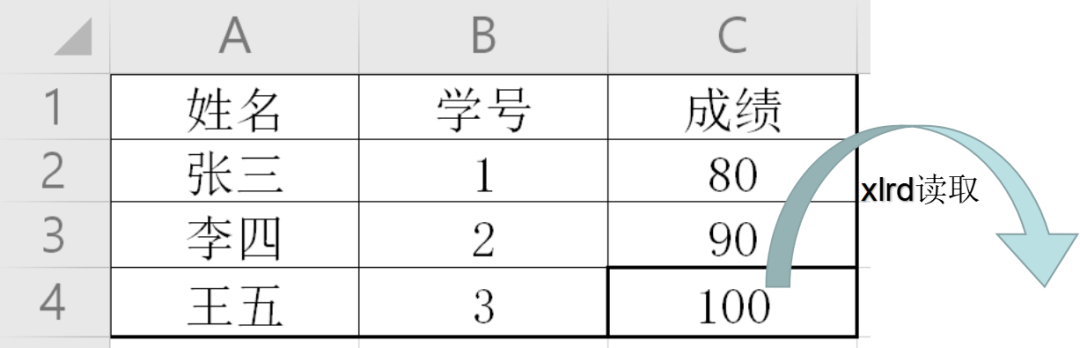
写EXCEL的模块xlwt
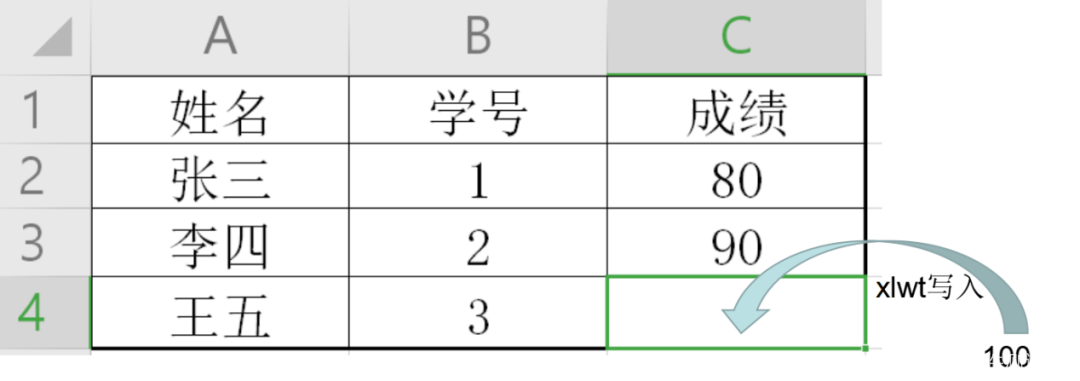
第四步
最初生成的表格,基本上是几个类似的数据就生成一个EXCEL,其他类似的再生成一个EXCEL。所以,如果一旦填写的数据有上百个(这个项目就是这种情况),那差不多也要10几个甚至20多个表格。
因此,我的想法是,能不能把这些生成的数据统统生成到一个表格里,然后再去这个表格里去找我需要的数据。
有了这个想法之后,我的想法就不止停留在了这个层面了。而是,既然我打算自动生成数据到统一的一个表格里边,然后去取数据,再填到我的结果表格里边。
那不如一步到位,通过程序直接把计算出来的结果,填到我创建的结果模板表格里边,实现计算——填表全自动化。
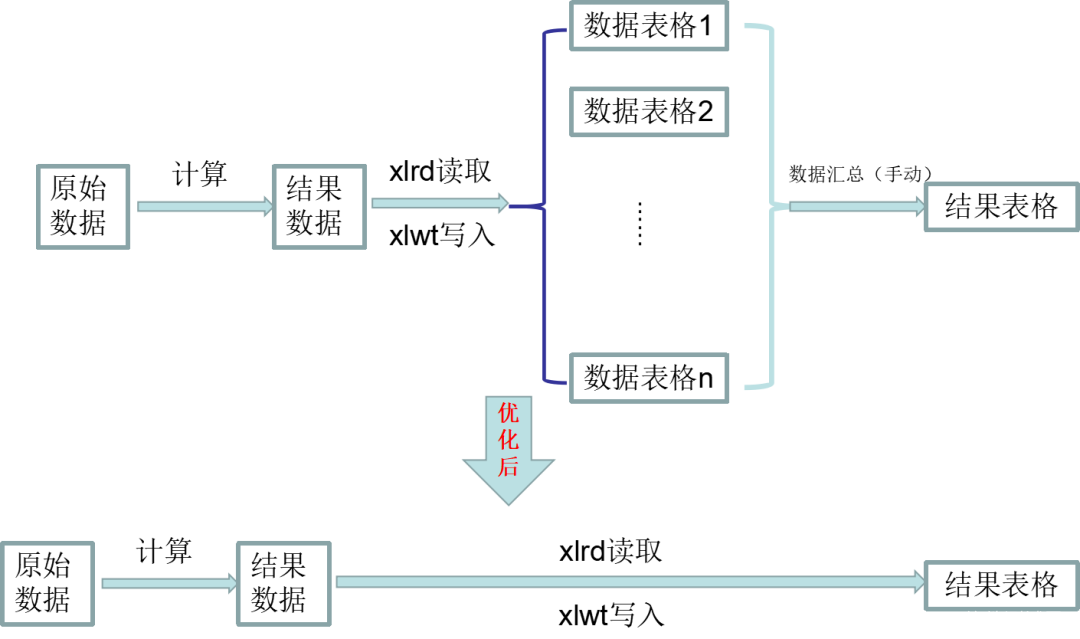
这个阶段用到的主要方法是仍然是读EXCEL的模块xlrd和写EXCEL的模块xlwt,不过,改变了一下这两种方法的用途,原来只用于把txt提取的数据存下来备用,现在直接用于写入最终的结果表格中。
第五步
需要特别指出的是,经过上面几个过程之后,所有的txt部分的需求才终于实现了,但是EXCEL数据读取、计算还没有进行。所以,接下来的主要目标,就是实现EXCEL表格的数据统计。
我首先想到的方法是,获取Excel的单元格的值,然后进行计算。有了之前txt数据的类似的经验,只要解决了如何获取单元格的值,就能实现此功能。
这个阶段,我学习到的方法是cell().value,取单元格的值。
第 2 则 -THE SECOND
程序优化改版:
通过试用和代码审查,优化代码
至此,需要实现的需求都一步一步的通过探索实现了。
但是,由于时间紧迫,第一版代码以自己最容易hold住的方式实现功能,没有特别去思考是否最优方案,所以,此时的代码只能用“水”来形容。
所以,接下来我做的是:
一方面:推广试用
让同事们试用我的代码,发现一些明显的问题,事实证明,实践是检验真理的唯一标准。试用过程中,发现的问题见python学习和工具试用过程中遇到的问题部分
另一方面:代码检视
1)算法优化
在让团队成员试用工具的同时,重新审视自己的代码,寻找优化点。首先是算法方面的优化。
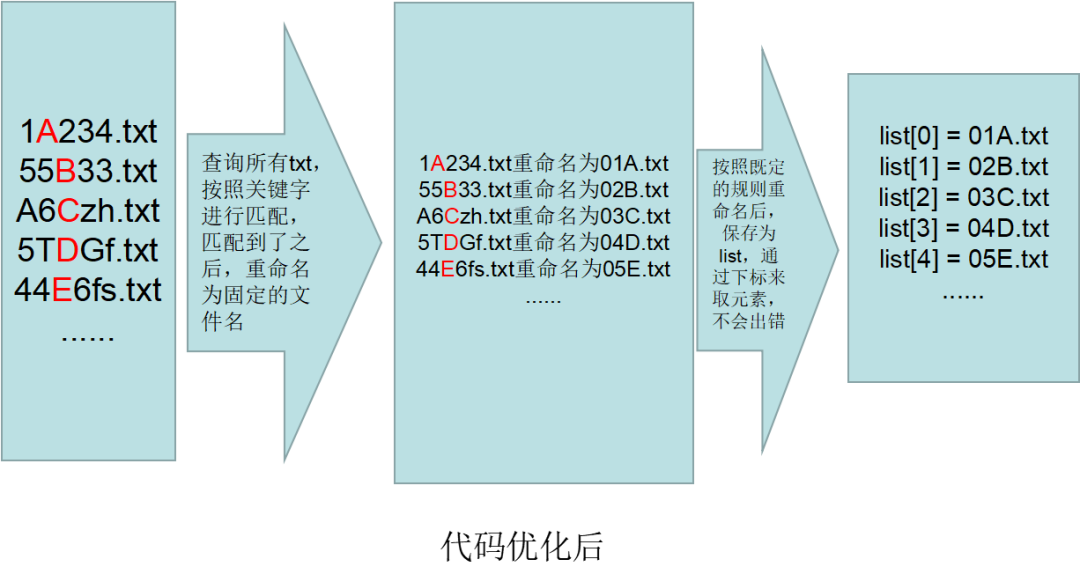
①提取代码逻辑完全相同的复制粘贴的代码,使用for循环进行结构简化。示意图如下:

②对于代码逻辑类似的,可酌情通过自定义函数库,来进行调用,这样可以使代码更加简洁,逻辑更加清晰。
例如,查找文件夹下的文件;通过一定的关键字搜索txt文件的所有行,然后把找到的行切割,然后取出需要的列,形成列表,最后形成dataframe,便于计算平均值等。
import re
def txt_cut(filel,keyws,cutby=r'[|]\s*'):
file = open(str(filel), "r")
txtlines = file.readlines()
data_is_need_num = 0
all_data = []
for line_num in range(len(txtlines)):
cur_line_data = txtlines[line_num]
for i in range(len(keyws)):
if keyws[i] in cur_line_data:
data_is_need_num = data_is_need_num + 1
data_split = re.split(cutby, cur_line_data)
all_data.append(data_split)
if data_is_need_num == 0:
print("没有找到您想找的关键字:")
for i in range(len(keyws)):
print(keyws[i])
file.close()
return all_data
③寻找内置库或者第三方库中是否有更简便的方法,替代代码中一坨代码实现的功能。
例如,计算平均值用mean()替代求和后再除以数量:
df.groupby(“A”).B.mean()
③用dataframe的groupby和value_counts()方法来输出一坨数据中:
max = df.groupby(“A”)[‘B’].apply(lambda x: x.value_counts().head(1))
可以说,代码优化的过程,更是一个各方面飞速进步的过程。
2)效率及易用性优化
除了上面的代码结构和调用的模块方法的优化,审视代码过程中,还识别出了一些执行效率和易用性方面的需求:
① 控制循环中某一分支执行次数,获取到一次数据之后,就停止循环。
time_ex = 0
if (条件1) and (time_ex != 1):
time_ex = 1
语句1
②将log打印信息以一定的颜色输出,方便提示用户一些重要的文件存储信息。
print("\033[0;31m我爱你中国\033[0m")
3)可靠性优化
除了效率和易用性方面,在这个项目过程中,也识别出了可靠性方面的需求。
例如,存放txt文件名的list,优化之前是通过动态获取目标路径下的所有txt,然后通过list下标来取,这种方法最大的问题是,如果目标路径下有多余的txt,则用下标可能取的不对。
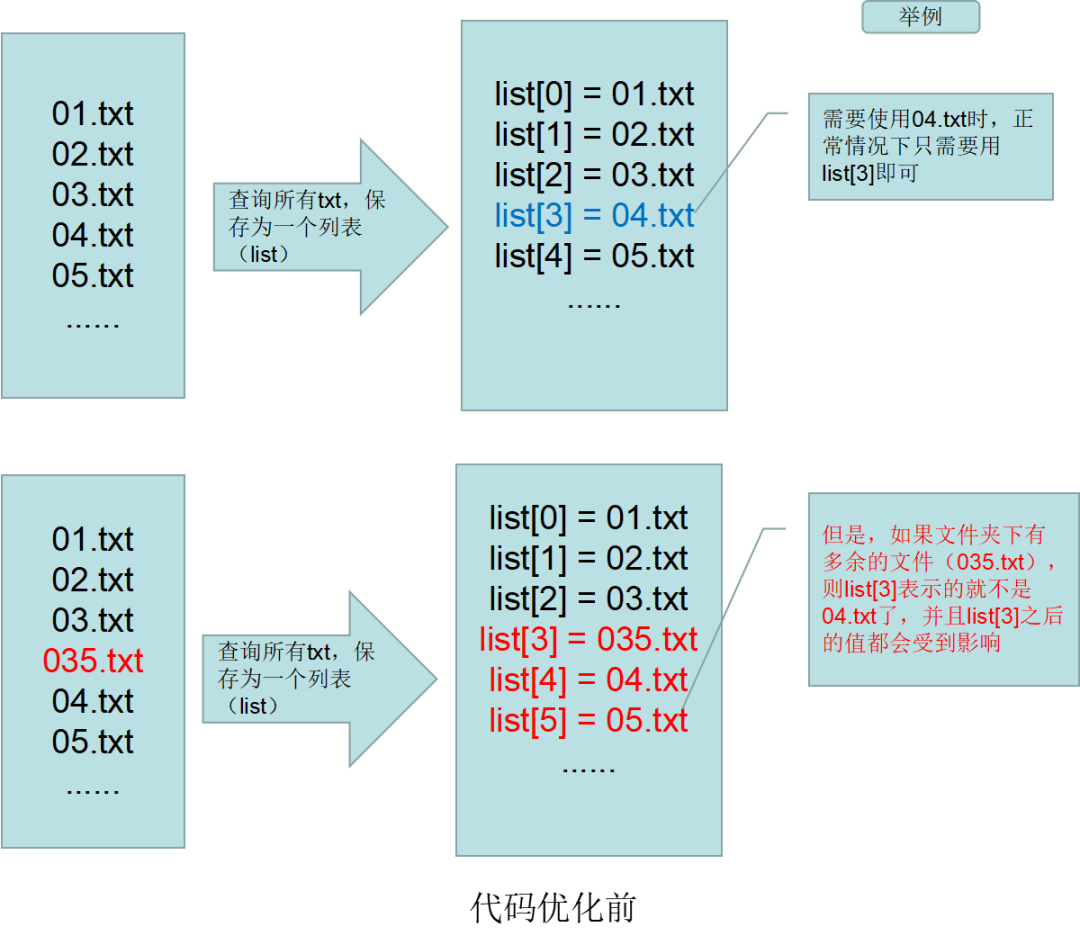
优化后,将待处理的文件,通过文件名进行关键字搜索,如果搜索到,则统一放到新建的文件夹下,并重命名为固定的文件名,这样做可以保证后面调用文件列表的时候,一定是我需要的,不会取错 。
02、python学习和工具试用过程中遇到的问题
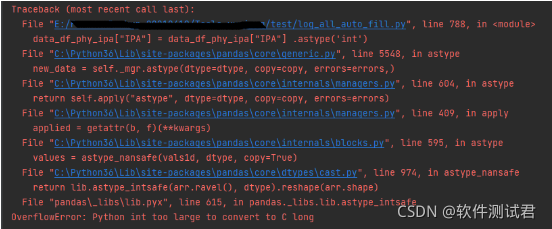
1、int越界
File "pandas\_libs\lib.pyx", line 615, in pandas._libs.lib.astype_intsafe
OverflowError: Python int too large to convert to C long
大体意思就是:溢出错误,Python int太大,无法转换为C long。
python的int是没有上限的,但是C有,如果传入参数大于C语言的int上限就会出错。
解决方案:
把:
data_df_phy_ipa["IPA"] = data_df_phy_ipa["IPA"] .astype('int')
改为:
data_df_phy_ipa["IPA"] = data_df_phy_ipa["IPA"] .astype('int64')
或:
data_df_phy_ipa["IPA"] = data_df_phy_ipa["IPA"] .astype('float')
遇到此类问题,其他参考方案是:
- List item
修改算法,不用这个c写的函数。
- 升级python版本,有的时候这个错误是python2的,将python升级为3。
2、重命名文件或文件夹时,提示已存在,异常结束执行
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件:
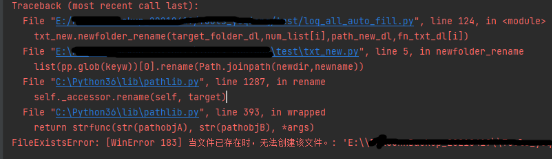
解决方案:
对目标文件夹或文件做判空处理:
if not Path.exists(Path.joinpath(newdir,newname))
3、使用round方法时,提示错误
AttributeError: 'float' object has no attribute 'round'

错误提示:
AttributeError: ‘float’ object has no attribute ‘round’
方案一:
该错误是由于numpy库版本较低导致的,需要更新numpy库至最新版本:
pip install --upgrade numpy
更新时需要保证pip版本比较新,否则会提示pip版本更新较低更新失败:
python3 -m pip install --upgrade pip
F:\Log_Analysis_Auto\0_log_all_auto_fill>pip install --upgrade numpy
Requirement already satisfied: numpy in c:\python36\lib\site-packages (1.19.5)
WARNING: You are using pip version 21.0.1; however, version 21.1 is available.
You should consider upgrading via the 'c:\python36\python3.exe -m pip install --upgrade pip' command.
F:\Log_Analysis_Auto\0_log_all_auto_fill>c:\python36\python3.exe -m pip install --upgrade pip
Requirement already satisfied: pip in c:\python36\lib\site-packages (21.0.1)
Collecting pip
Downloading pip-21.1-py3-none-any.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 328 kB/s
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 21.0.1
Uninstalling pip-21.0.1:
Successfully uninstalled pip-21.0.1
Successfully installed pip-21.1
方案二:
如果方案一解决不了问题,请将如下这种格式的代码:
rb_s2 = df[df['Cell']=='SCC2'].RB.mean().round(2)
修改为:
rb_s2 = round(df[df['Cell']=='SCC2'].RB.mean(),2)
4、提示含有gbk或者utf-8解码错误的报错
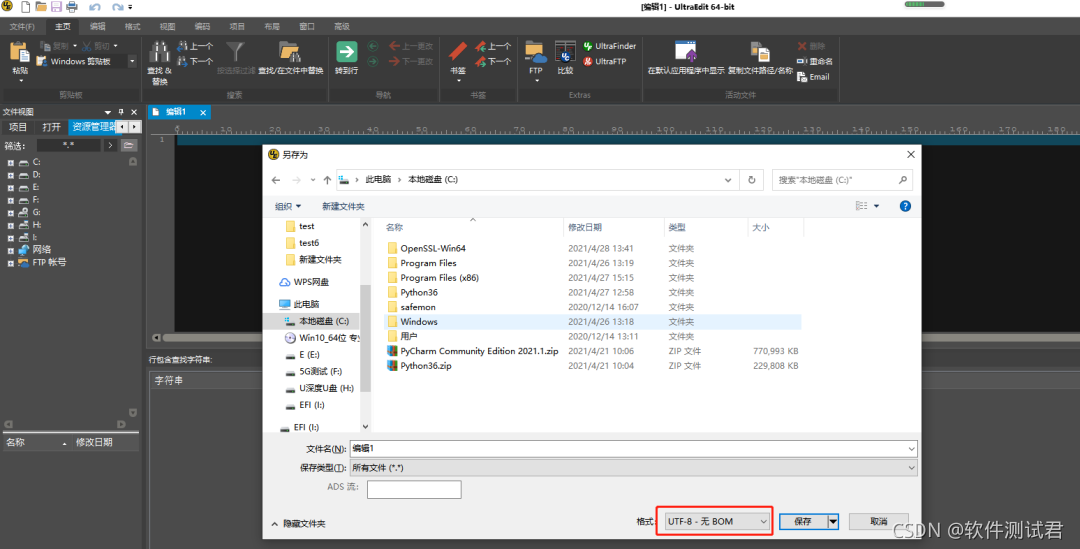
原因:
这种情况是因为txt文件没有存为utf-8 无bom格式。
解决方案:
Ultra edit打开txt文件,然后另存为格式选择“UTF-8-无BOM”。
5、提示无权限Permission denied
PermissionError: [Errno 13] Permission denied:
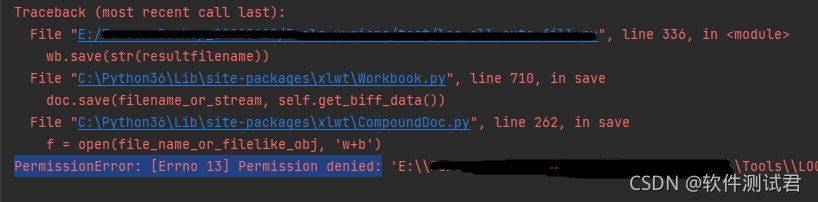
原因:
程序执行完成之前,需要读写的文件不能打开,否则会读写冲突,执行终止。
解决方案:
程序执行过程中,不要打开文件。
6、invalid literal for int() with base 10
报错:
ValueError: invalid literal for int() with base 10
原因:
原因为参数有误,int()函数可以把数字字符串转化成int类型的数字,但是不能传入非数字的字符串。
解决方案:
非数字字符串改成数字字符串。
03、python学习总结
1、处理数据pandas库的dataframe比较强大
数据被DataFrame了之后,就像是操作EXCEL表格中的数据一样,只要你敢想,它就敢做。就我目前用到的DataFrame功能,我总结如下:
统计均值
统计最大值
统计哪个值最多
整列删除
筛选数据
整列合并
DataFrame的功能远远不止这些,感兴趣的小伙伴可以自行学习
2、对于读写EXCEL的方法,有如下的总结:
openpyxl可以处理xlsx文件和XLSM文件,可以写入单页sheet超过65535行,可以同时读写Excel;xlrd、xlwt只能处理xls,最大可以写65535行的表格。
不过,如果EXCEL表格的数据量不是很大时,还是建议使用xlrd、xlwt套装。
04、后记
最后,一些Python学习心得分享给大家,希望对大家有所帮助。
自动化脚本写作,重在实战
潜力是逼出来,有压力才有动力
写代码之前最好先构思好代码逻辑,躺石头过河的笨方法只适合初学者,并且后期维护成本较高,返工的概率也高一些
Python编码选模块很重要,选对模块事半功倍
希望本文能够帮助那些“原始人”快速“进化”为“现代人”,或者对那些已经成为“现代人”有一些启发。
我下一步的计划是,学习和实践Python+Selenium的自动化框架,我将在后续的文章中把我的学习心得分享给大家,敬请关注。
最后: 可以关注公众号:伤心的辣条 ! 进去有许多资料共享!资料都是面试时面试官必问的知识点,也包括了很多测试行业常见知识,其中包括了有基础知识、Linux必备、Shell、互联网程序原理、Mysql数据库、抓包工具专题、接口测试工具、测试进阶-Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架、性能测试、安全测试等。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!
好文推荐
转行面试,跳槽面试,软件测试人员都必须知道的这几种面试技巧!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









