







论文地址:https://arxiv.org/abs/2406.02166
开源代码及模型:
https://github.com/thu-spmi/CAT/blob/master/egs/cv-lang10/readme.md
摘 要
Whistle和Whisper一样,均采用弱监督方式训练ASR基座模型。不同于Whisper采用基于子词(subword based)弱监督,Whistle采用基于音素(phoneme based)弱监督。子词是语言文本的记录符号,而音素则是记录了语言的发音,更适合于作为语音建模单元。本研究初步实验展示了相比于自监督与基于子词的弱监督,基于音素弱监督的Whistle能更高效地学习各语言之间的共同语音表征、有更高的多语言和跨语言ASR准确率、更好地克服灾难性遗忘、以及更快的训练效率。90M、218M、543M参数的Whistle多语言ASR基座模型已开源发布。
背景介绍及研究动机
全球存在超过7000种语言。遗憾的是,由于训练数据的匮乏,仅有极少数语言能够享受到现有语音识别(ASR)技术带来的便利。如何快速且经济高效地为那些尚未得到支持的语言开发ASR系统,是当前语音技术领域面临的重要挑战。多语言和跨语言ASR(Multilingual and Crosslingual Automatic Speech Recognition,MCL-ASR)是应对这一挑战的有效手段。
-
多语言语音识别,旨在将不同语言(即已见语言)的训练数据合并,以共同训练出一个多语言声学模型。
-
跨语言语音识别,则是利用这个多语言模型来识别那些在模型训练过程中未曾见过的新语言(即未见语言)。
从机器学习的视角来看,多语言和跨语言训练是一种执行多任务学习和迁移学习的过程,这种方式有效地促进了不同语言间的统计强度(statistical strength)共享。其显著优势在于,它不仅显著提升了低资源语言(无论是已见还是未见)的ASR性能,还降低了多语言ASR系统的构建及后续维护成本。
近年来,先进行预训练再进行微调的方法越来越受到关注,并且取得了不错的性能。预训练方法主要分为两类,一类是基于自监督学习,另一类是基于监督学习。自监督的预训练,是在多语言的无标注语音数据上进行,其目的是学习通用的语音表征。监督预训练,通过在多语言标注的语音数据上进行模型训练,根据使用的建模单元不同可以进一步分为两个子研究领域。第一种是基于字形或子词的,统称为基于字素转录,它在多种语言之间创建了一个共享的标记集,例如OpenAI开发的Whisper。第二种是在音素转录上训练模型,通常利用国际音标(International Phonetic Alphabet, IPA)符号创建一个通用的音素集。这些方法广泛应用在MCL-ASR研究当中,但是仍然有两个重要研究问题没有得到充分地回答。
研究问题1:在相同的实验条件下,基于音素和基于子词的有监督预训练方法中,哪一种能在MCL-ASR任务中取得更佳的性能呢?从理论角度分析,由于多种语言间存在着发音上的相似性,基于音素的有监督预训练能够更有效地捕捉到多语言间的信息共性。然而,获取精确的音素转录往往既耗时又费力。幸运的是,我们可以利用公开的G2P(grapheme-to-phoneme)工具相对容易地获得带噪的音素转录。而基于子词的有监督预训练需要直接从文本中学习多语言中的共享信息,这使得该方法对大量数据的依赖性较高。目前,尚未有研究通过严格的实验比较过这两类方法。
研究问题2:在相同的实验环境下,有监督预训练和自监督预训练,哪一个方法能获得更好的MCL-ASR效果?利用多语言的无标注音频数据进行表征学习,然后在目标语言的字素或音素标注数据上进行有监督微调。这种方法在大量无标注数据上自监督训练编码器,但缺乏与编码器性能相匹配的解码器。这意味着即便对于已见语言,也至少需要添加线性层才能进行有效的有监督微调。在有监督微调阶段,可以选择基于字素或基于音素的方法进行微调。因此,自监督预训练方法可以和基于音素的和基于子词的有监督预训练方法比较。目前,尚未有研究通过严格的实验比较过这两类方法。
本文基于CommonVoice数据集构建了一个统一的实验环境,用于评估MCL-ASR性能。该实验环境涵盖了10种已见语言(CV-Lang10)及2种未见语言,并同时考量音素错误率(PER)和词错误率(WER)。在这12个语言的数据集上,我们进行了一系列实验,旨在尽可能公平地比较三种方法。这些实验体现了我们为回答上述两个重要问题的研究进展。
我们发展了一种名为Whistle(Weakly phonetic supervision strategy for multilingual and crosslingual speech recognition)的方法,即通过弱音素监督实现数据高效的多语言和跨语言语音识别。这包括完整的数据处理、模型训练和测试流程。实验证明了Whistle在MCL-ASR方面的优势,包括已见语言的语音识别、未见语言的跨语言性能(不同数量的少样本数据)、克服灾难性遗忘以及训练效率。我们开源了Whistle整个流程的代码、模型和数据,详见:
https://github.com/thu-spmi/CAT/blob/master/egs/cv-lang10/readme.md
方法介绍
图1 音素监督、子词监督和自监督下的预训练和微调过程。
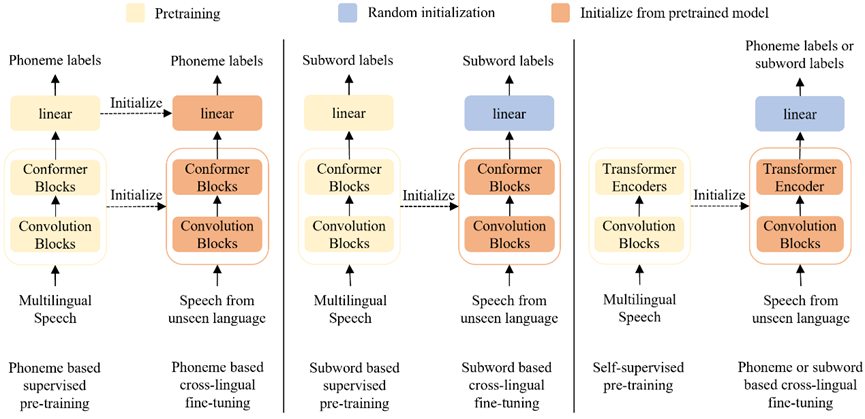
本文在尽可能公平的环境下比较了主流的三种多语言预训练方法,分别是自监督预训练、基于字素(或子词)和基于音素的有监督预训练。图1详细展示了这三种方法在预训练和微调过程中的具体步骤。
基于音素的有监督预训练,通常借助IPA来构建一个通用音素集,作为神经网络模型的输出符号集。由于不同语言间发音相近的音素可以用同一IPA符号表示,这种基于音素的预训练模型促进了不同语言间的信息共享。为了降低对精准人工验证及转录的依赖,本文中我们采用LanguageNet G2P模型来获取IPA音素转录。该模型支持142种语言,音素错误率(PERs)介于7%至45%之间。因此,本文的核心目标是探索使用含有一定噪声的音素转录进行弱监督预训练的效果。从图1左侧部分可以观察到,基于音素的有监督预训练需要利用已见语言的音频数据及其对应的音素标注进行有监督预训练。对于已见语言在没有进行微调的情况下,我们可以直接对模型进行测试。对于未见语言的数据,模型同样能直接进行识别,原因在于未见语言中的大部分音素都已经包含在训练阶段使用的多语言音素集中。如果选择继续进行微调,那么对于未见语言中未出现的音素,我们需要随机初始化其phone embeddings。
基于子词的有监督预训练,通常依赖于多语言文本来构建一个共享符号集,作为模型的词表。然而,字素和子词实际上源自不同语言的书写系统,这些系统并非在所有语言中都通用,这会在一定程度上影响多语言之间的信息共享。直至最近,分词(tokenization)策略仍在积极研究中,需要在粒度与ASR性能之间实现平衡;此外,为跨语言识别添加新语言进一步增加了tokenization设计的复杂性。从图1中间部分可以观察到,基于子词的有监督预训练需要利用已见语言的音频数据及其对应的子词标注进行有监督预训练。对于已见语言同样也可以在没有进行微调的情况下直接进行识别。对于未见语言的数据,由于各个语言书写系统和tokenization的差异较大,通常不能相互共享,所以需要对线性分类层的权重进行随机初始化,再进行基于子词的微调。
自监督预训练方法,利用多语言的无标注音频数据进行表征学习,然后在目标语言的字素或音素标注数据上进行有监督微调。这种方法在大量无标注数据上自监督训练编码器,但缺乏与编码器性能相匹配的解码器。从图1右侧部分可以观察到,即便对于已见语言,自监督预训练模型也至少需要添加线性层才能进行有效的有监督微调。在有监督微调阶段,可以选择基于字素或基于音素的方法进行微调。
多语言和跨语言语音识别的核心,在于促进多语言训练过程中的信息共享,并最大化已训练多语言模型向新语言识别模型的知识转移。从这一视角出发,我们搭建了一个统一的实验环境,对这三种预训练方法在多语言和跨语言语音识别方面的性能进行全面评估。此外,本文提出了一种基于弱音素监督训练的数据高效多语言和跨语言语音识别系统,并且我们开放了所有代码和训练流程。
实验结果
我们利用CAT工具包(https://github.com/thu-spmi/CAT),搭建基于Conformer和CTC的端到端语音识别模型。在英语(en),西班牙语(es),法语(fr),意大利语(it),吉尔吉斯语(ky),荷兰语(nl),俄语(ru),瑞典语(sv),土耳其语(tr)和塔塔尔语(tt)十个语言上训练基于音素的和基于子词多语言模型。我们还用标注文本为每个语言单独训练了4-gram语言模型,用于基于WFST的解码。基于音素的模型的多语言音素词表大小是73。基于子词的模型的多语言子词词表大小是4998。图2展示了子词词表和音素词表中的每一个token在CV-Lang10 数据集上出现的次数。
图2 CV-Lang10训练集中每个音素(上)和子词(下)的出现次数。
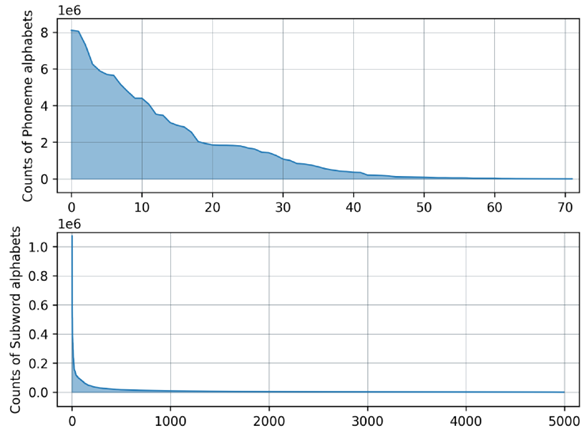
表4 在CV-Lang10数据集上,基于音素的单语模型和多语言预训练模型的词错误率(WERs),与基于子词的多语言预训练模型进行了比较。

从表4中可以看出,在同等模型大小(约90M)条件下,基于音素的预训练模型(M1)在没有微调的情况下,实现平均 6.56的词错误率(WER)。相比单语模型(O1)和基于子词的多语言模型(M4)分别低了6% 和18%。并且,随着模型规模的增加,错误率会继续下降。可以看出,相比训练10个单语模型,训练一个多语言模型并加大模型规模是更好的选择。在相同试验下比较基于音素和基于子词的预训练模型很好地回答了前文提出的研究问题1。一方面,相较于主要用于文本书写的子词,采用音素作为标签在声音分类方面显得更加自然和高效。这是因为音素本质上与语言中的声音有着更直接的联系。另一方面,由图2可以观察到,相较于基于音素的有监督训练,基于子词的有监督训练中的数据不平衡问题更为严重。从机器学习的视角出发,多任务学习在数据不平衡的情况下可能会遭受不利影响,具体表现为高资源语言遭受干扰,而低资源语言则可能未能得到充分的训练。因此,基于子词的有监督预训练需要采取额外的训练策略来缓解数据不平衡的问题,比如精心设计分词方法、人工混合训练数据等措施。
表5 在波兰语上进行基于音素的跨语言微调(FT)的音素错误率(PERs)和词错误率(WERs)。预训练数据集为CV-Lang10。
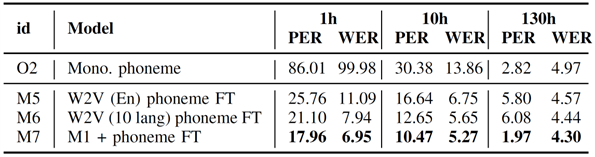
表6 在波兰语上进行基于子词的跨语言微调(FT)的词错误率(WERs)。预训练数据集为CV-Lang10。
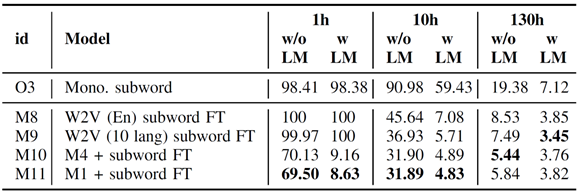
表5和表6展示了使用上述预训练模型在未见语言(波兰语)数据上进行基于音素和基于子词的微调。其中,W2V (10 lang) 是指使用十个语言的多语言音频数据训练的wav2vec 2.0 自监督模型。W2V (En) 是指用英文数据训练的wav2vec 2.0,该模型由fairseq工具包提供。这两个模型大小均为90M。
从表5和表6可以观察到,在仅有1小时波兰语训练数据的低资源场景中,采用音素预训练后音素微调(M7)的方法表现最佳(WER 6.95%)。音素预训练的结果明显优于子词预训练(M11对比M10),这清楚地展示了从多语言数据进行表征学习时音素监督的优势(研究问题1)。当比较音素预训练和wav2vec 2.0预训练时(M7对比M6,M11对比M9),音素预训练显示出明显的优势(研究问题2)。随着数据量的增加,各个模型之间的差异逐渐缩小。
表7 在印尼语上进行基于音素的跨语言微调(FT)的音素错误率(PERs)和词错误率(WERs)。预训练数据集为CV-Lang10。
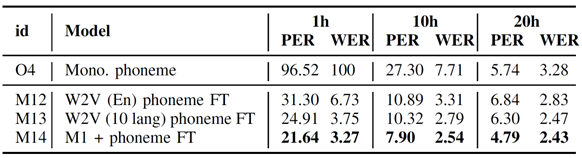
表8 在印尼语上进行基于子词的跨语言微调(FT)的词错误率(WERs)。预训练数据集为CV-Lang10。
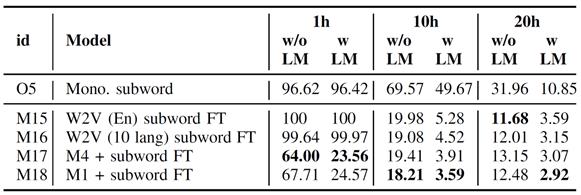
表7和表8展示了在另一个未见语言(印尼语)数据上,分别进行基于音素和基于子词的微调结果。印尼语比波兰语更具有挑战性,因为它与预训练使用的十个语言语言在语言学上差异更大,且可用的数据量也更少。
从表7和表8可以观察到与波兰语相似的结论,使用音素预训练和音素微调的方法在更具挑战性的语言上优势更为显著。随着微调所用数据量的增加,这种行为越来越类似于训练单语的端到端模型,各个训练方法之间的差异逐渐缩小。
图3 使用t-SNE对嵌入进行可视化。(a)来自M1模型的音素嵌入,(b)来自M4模型的子词嵌入。在(a)中,蓝色代表辅音,红色代表元音。

如图3所示,我们采用t-SNE方法将音素预训练模型(M1)的phone-embedding(左图)和子词预训练模型的subword-embeding(右图)投影到二维平面上,直观感受比较十个语言的73个音素和4998个子词的分布情况。
我们在phone-embedding图上标识了IPA音素,其中蓝色代表辅音,红色代表元音。从图中可以观察到,phone-embedding在高维空间中的分布更为均匀,且元音都聚集在图的右下方。subword-embeding在中心区域显得密集而拥挤,并向外围逐渐变稀疏。这表明,基于子词的模型在表征学习方面的平衡性不如基于音素的模型,这可能归因于子词模型中的数据不平衡问题。
表9 测试多语言模型的灾难性遗忘情况,这些模型在CV-Lang10上进行了预训练,并在新语言(波兰语)的10分钟数据上进行了微调。WARD表示CV-Lang10中十个旧语言的平均WER相对退化的词准确度。

表9展示了音素预训练(M1)和子词预训练(M4)模型在经过10分钟波兰语数据微调后,对预训练所用的十个语言进行测试的结果。可以看出,音素预训练模型在波兰语数据上实现了11%的词错误率,在十个预训练语言上的平均词准确率恶化了48%(Word Accuracy Relative Degradation, WARD)。相比之下,子词模型在多语言和跨语言结果上均表现不佳,平均词准确率率恶化达160%。因此我们可以认为基于子词的预训练模型更具潜力成为可持续学习(continual learning)的多语言预训练模型。
表10 基于音素和基于子词的预训练(PT)和微调(FT)的训练效率。

如表10所示,我们比较了不同模型达到收敛所需的训练轮数。在保持批量大小一致的情况下,基于音素的预训练方法比基于子词的预训练方法在训练轮数上减少了24%。此外,在对波兰语全量数据集进行跨语言子词微调时,与基于子词的预训练模型相比,基于音素预训练的模型在微调过程中能够减少12%的轮数。这一结果进一步证实,相较于子词标签,音素标签在声音分类监督中能够提供更高效率。使用子词标签进行声音分类的学习路径更长,且效率较低
结论和展望
从原理上说,基于音素监督的预训练方法在促进不同语言之间的信息共享方面具有明显优势,但目前这种方法并没有受到足够的关注。本文提出了一种名为Whistle的弱音素监督的预训练方法,并对其与基于字素监督的预训练和自监督预训练方法进行了详细比较。初步实验结果显示,无论是在已见语言还是未见语言的语音识别性能上,还是在防止灾难性遗忘以及训练效率等方面,弱音素监督训练都展现出了优异的表现。未来进一步提升Whistle模型规模和训练数据量,有望取得更好的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









