







近日,阿里发布了Qwen2-Audio模型。Qwen2-Audio 是一个大型的音频语言模型系列,它能够接受音频信号输入,进行音频分析或直接文本响应,支持语音聊天和音频分析两种交互模式,并且提供了预训练模型Qwen2-Audio-7B和聊天模型Qwen2-Audio-7B-Instruct的版本。
论文地址:https://arxiv.org/abs/2407.10759
评估标准:https://github.com/OFA-Sys/AIR-Bench
开源代码:https://github.com/QwenLM/Qwen2-Audio
Qwen2-Audio 具备下面的几个特点:
-
语音聊天:用户可以使用语音向音频语言模型发出指令,无需通过自动语音识别(ASR)模块。
-
音频分析:该模型能够根据文本指令分析音频信息,包括语音、声音、音乐等。
-
多语言支持:该模型支持超过8种语言和方言,例如中文、英语、粤语、法语、意大利语、西班牙语、德语和日语。
模型效果
官方在一系列基准数据集上进行了实验,包括 LibriSpeech、Common Voice 15、Fleurs、Aishell2、CoVoST2、Meld、Vocalsound 以及 AIR-Benchmark,下面我们将展示一张图表来说明 Qwen2-Audio 相对于竞争对手的表现。在所有任务中,Qwen2-Audio 都显著超越了先前的最佳模型或是 Qwen-Audio。
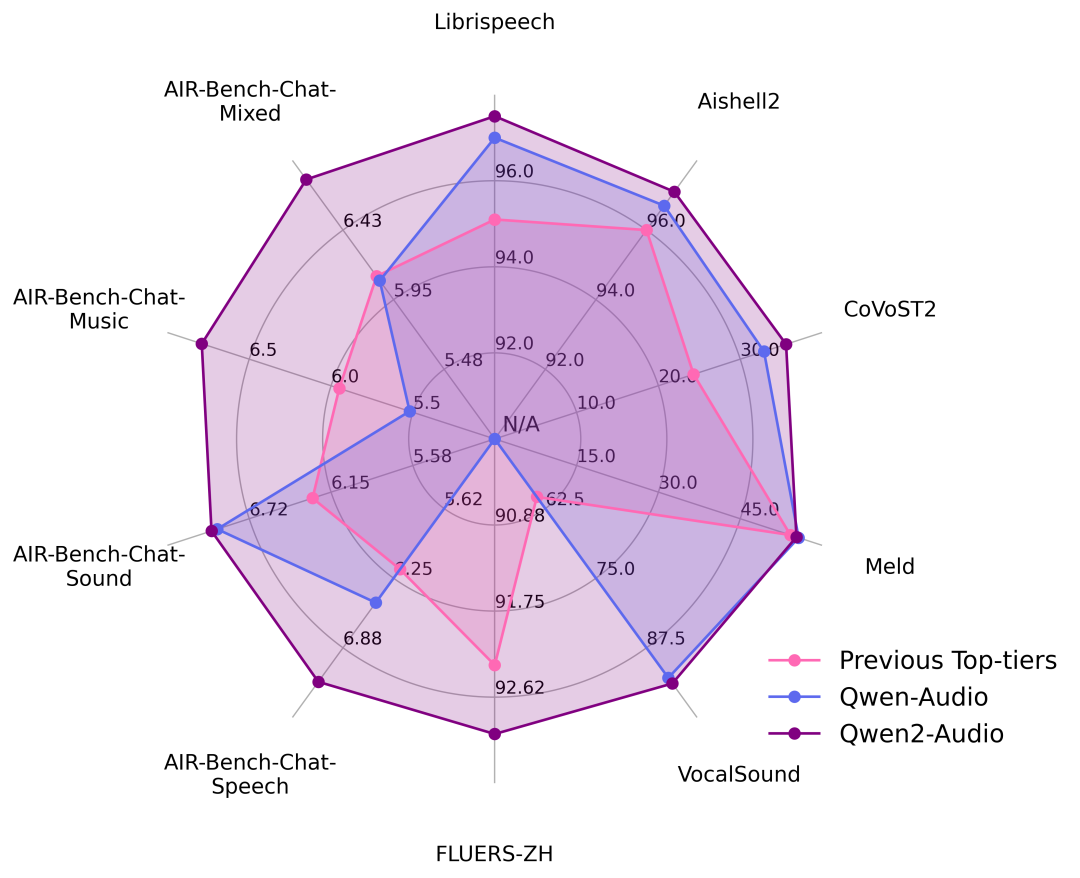
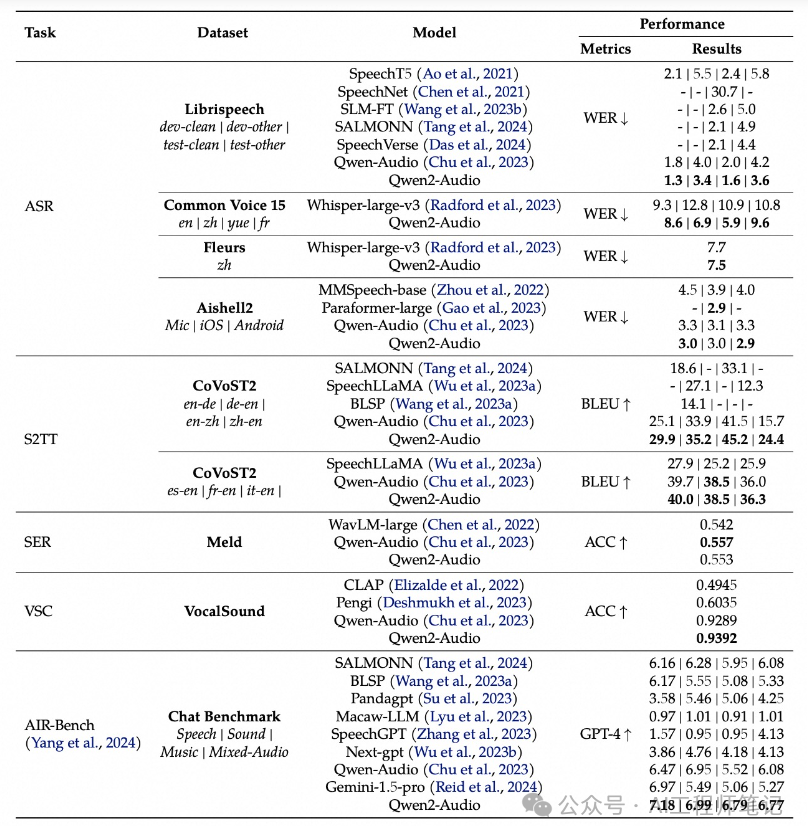
关于数据集的更具体结果列于下表中。
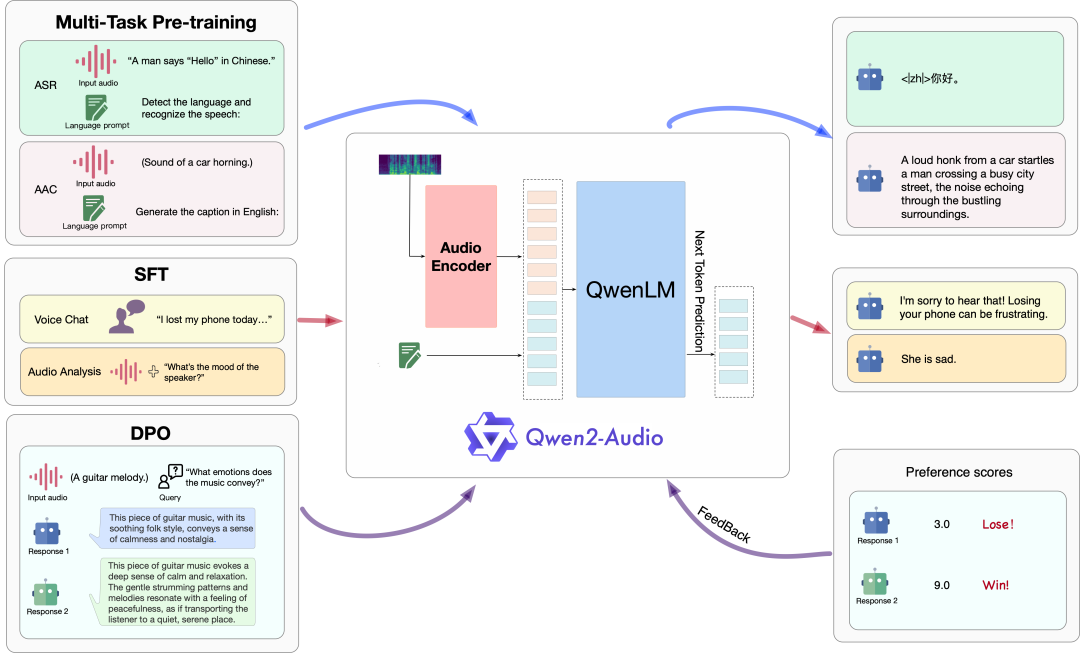
结构与训练范式
下图展示了模型结构及训练方法。具体来说,通义千问团队使用 Qwen 语言模型和音频编码器这两个基础模型,接着依次进行多任务预训练以实现音频与语言的对齐,以及 SFT 和 DPO 来掌握下游任务的能力并捕捉人类的偏好。
使 用
Qwen2-Audio 的代码已在最新的 Hugging face transformers 中,环境安装
pip install git+https://github.com/huggingface/transformers语音聊天推理:


音频分析推理:


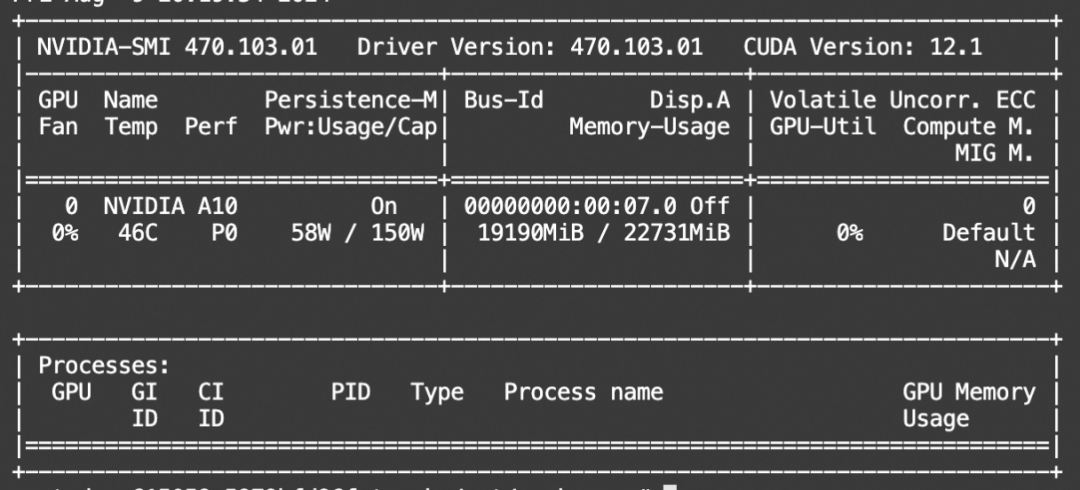
显存占用:
vllm推理





尽管有了对Huggingface的访问限制,但是魔搭modelscope.cn在某种意义上,算是解决了大部分问题。
同时也可直接试用魔搭的在线Demo:
https://modelscope.cn/studios/qwen/Qwen2-Audio-Instruct-Demo

可以直接使用Record,录下自己的音频,然后点Submit就可以了。















 1922
1922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









