







KMP算法
主要题型
KMP是一种主要用于处理两个字符串相匹配的算法。
例如:
在字符串 “BBC ABCDAB ABCDABCDABDE” 之中匹配 “ABCDABD”。
暴力做法
(1)首先B与A进行匹配,不对应,匹配下一个字母,直到找到A与A对应为止。
(2)第一个字母匹配完成之后,匹配第二个字符,发现ABCDAB均可以匹配,但是D与‘ ’不匹配。
(3)整体向后移动一个字符继续寻找可以匹配首字母的位置,重复第二个过程。
在上述的暴力做法当中,第三步每次只向后移动一个位置再次去遍历后续的每个字符在时间方面是特别浪费的,使用KMP算法可以优化这一部分。
KMP算法思想
1、记录要匹配的字符串的前缀以及后缀
2、找出前缀以及后缀相同的部分
3、如果匹配失败,直接将当前字符串移到相同后缀的位置处
通过KMP算法来记录前缀与后缀,每次移动不止会移动一个字符的距离,会每次都移动到相匹配的位置,这样的话就可以节省很多的时间。
前缀与后缀。

例如在样例数据之中:
str1 = “BBC ABCDAB ABCDABCDABDE”
str2 = “ABCDABD”。
在匹配的过程当中,首先如果使用通过暴力的做法
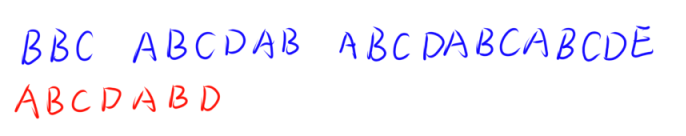
逐个枚举,发现 “ABCDAB” 是可以进行匹配的。
但是最后一个字符 ‘D’ 是无法匹配的。

此时,如果是使用暴力的做法,那么将会将第二个字符串向后延续一个字符,发现无法匹配,直到遍历到下一个 ‘A’ 的位置才可以继续匹配
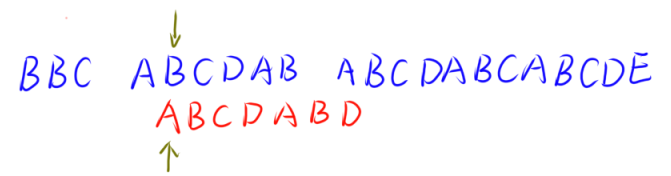
… …
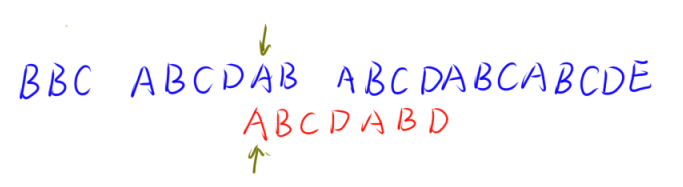
这种方法是特别浪费时间的。
KMP算法思想:
通过 KMP 算法,在我们匹配到 ABCDAB 时,同样最后一个字符是不匹配的。
此时我们通过KMP算法已经记录了前缀与后缀的共有部分。(如上面的那个表格所示)
当前所匹配的字符串 “ABCDAB” 长度为 6 ,所记录的 ne[6] 值为 2,也就是说前缀和后缀所匹配的长度为 2.

那么此时就可以直接平移 len - ne[i] 个长度的位置来使当前的 AB 直接移到下一个 AB 的位置。
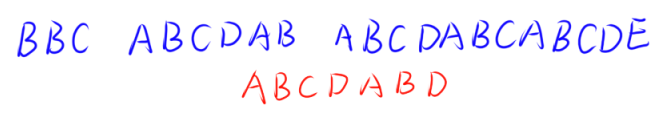
通过KMP算法,可以直接过渡多个单位,那么就可以相比于暴力的做法节省很多的时间。
题目
题目链接
KMP算法:https://www.acwing.com/problem/content/833/
AC代码
学算法就上AcWing!!!
#include <iostream>
using namespace std;
const int N = 100010, M = 10010; //N为模式串长度,M匹配串长度
int n, m;
int ne[M]; //next[]数组,避免和头文件next冲突
char s[N], p[M]; //s为模式串, p为匹配串
int main()
{
cin >> n >> s+1 >> m >> p+1; //下标从1开始
//求next[]数组
for(int i = 2, j = 0; i <= m; i++)
{
while(j && p[i] != p[j+1]) j = ne[j];
if(p[i] == p[j+1]) j++;
ne[i] = j;
}
//匹配操作
for(int i = 1, j = 0; i <= n; i++)
{
while(j && s[i] != p[j+1]) j = ne[j];
if(s[i] == p[j+1]) j++;
if(j == m) //满足匹配条件,打印开头下标, 从0开始
{
//匹配完成后的具体操作
//如:输出以0开始的匹配子串的首字母下标
//printf("%d ", i - m); (若从1开始,加1)
j = ne[j]; //再次继续匹配
}
}
return 0;
}















 3476
3476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









