







这几周时间里,我学习到了线性表这一模块的知识。终于体会到了大一没学好指针的痛苦……线性表是十分重要的一块知识,不论如何都一定要学好!!
一、线性表的逻辑结构
1.线性表是0个或多个具有相同类型的数据元素的有限序列。
2.线性表中的数据元素具有相同类型,相邻元素具有前驱和后继关系。
二、线性表的顺序存储结构及实现
1.顺序表: 顺序存储是指用一组地址连续的存储单元依次存储线性表的各个元素。通过数据元素物理存储的相邻关系来反映数据元素之间逻辑上的相邻关系。

设顺序表的每个元素占用 c 个存储单元,则第 i 个元素的存储地址为: LOC ( a i ) = LOC ( a1 ) + ( i - 1 ) × c
2.顺序表的实现:
template <class T>
class SeqList{
private:
T data[100]; // 存放数据元素的数组
int length; // 线性表的长度
public:
SeqList ( ) ; // 无参构造函数
SeqList ( T [ ], int n ) ; // 有参构造函数
~SeqList( ) { } // 析构函数为空
int Length ( ) {return length;} // 求线性表的长度
T Get ( int i ); // 按位查找,取线性表的第 i 个元素
int Locate ( T x ) ; // 按值查找,求线性表中值为 x 的元素序号
void Insert ( int i, T x ) ; // 在线性表中第 i 个位置插入值为 x 的元素
T Delete ( int i ) ; // 删除线性表的第 i 个元素
void PrintList ( ) ; // 遍历线性表,按序号依次输出各元素
};
1).构造函数
- 无参构造函数(构造一个空的顺序表)
SeqList ( ) {length=0;}
- 有参构造函数
SeqList ( T a[],int n ) ; // 有参构造函数
将长度为n的一维数组中的元素依次传入到data中。实现过程:
template <class T>
SeqList<T>:: SeqList(T a[],int n)
{
if (n>100) throw "参数非法";
for (int i=0; i<n; i++)
data[i]=a[i];
length=n;
}
2).插入操作
在表的第i (1≤i≤n+1)个位置,插入一个新元素e。

template <class T>
void SeqList<T>::Insert(int i,T x){
int j;
if (length>=100) throw "上溢"; //如果顺序表已满,抛出上溢异常
if (i<1 || i>length+1) throw "位置"; //如果元素插入位置不存在,抛出位置异常
for (j=length; j>=i; j--)
data[j]=data[j-1]; //从后往前,将最后一个元素至第i个元素(i为插入位置)向后移动一个位置
data[i-1]=x; //将元素x插入到i位置
length++; //将顺序表的长度增加1
}
3).删除操作
template <class T>
T SeqList<T>::Delete(int i){
int j;
T x;
if (length==0) throw "下溢"; //如果顺序表已空,抛出下溢异常
if (i<1 || i>length) throw "位置"; //如果元素删除位置不存在,抛出位置异常
x=data[i-1]; //取出被删除的元素
for (j=i; j<length; j++)
data[j-1]=data[j]; //前移,将下标为i,i+1…n-1的元素依次移到i-1,i,…n-2的位置
length--;
return x; //返回被删除的元素
}
4).查找操作
- 按位置查找
template <class T>
T SeqList<T>::Get(int i)
{
if (i<1 && i>length) throw "查找位置非法";
else return data[i-1];
}
- 按值查找
template <class T>
int SeqList<T>::Locate(T x){
for (int i=0; i<length; i++)
if (data[i]==x)
return i+1 ; //下标为i的元素等于x,返回其序号i+1
return 0; //退出循环,说明查找失败
}
三、线性表的链式存储结构及实现
1.链式存储结构的实现:单链表,双向链表,循环链表等
2.变量的三要素:
1).名字,内存地址,值
2).变量的左值,右值
左值指变量的内存地址
右值:值
在赋值表达式中,赋值号左边需要左值,右边需要右值;如a=a+100
3).指针变量
指针变量的右值本身又是一个左值。

4.在C++中,可以用结构类型来描述单链表的结点 ,由于结点的元素类型不确定,所以采用C++的模板机制。
template <typename T>
struct Node
{
T data;
Node<T> *next; //此处<T>也可以省略
};
5.单链表的实现
template <class T>
class LinkList {
Node<T> *first; // 单链表的头指针 , <T>可以省略。实例化
public:
LinkList ( ) {first=new Node<T>; first -> next= NULL ;}
LinkList ( T a[], int n ) ;
~LinkList ( ) ;
int Length ( ) ;
T Get ( int i ) ;
int Locate ( T x ) ;
void Insert ( int i, T x ) ;
T Delete ( int i ) ;
void PrintList ( ) ;
};
1).单链表的构造
- 头插法
每个插入的结点都插在头结点之后,原来的首元结点之前。
头结点不是首元结点!
尾结点时刻不变。
template <class T>
LinkList<T>:: LinkList(T a[], int n) {
first=new Node<T>; //生成头结点
first->next=NULL;
Node<T> *s;
for (int i=0; i<n; i++){
s=new Node<T>; //①
s->data=a[i]; //②赋值
s->next=first->next; //③先修改尾端
first->next=s; //④再修改近端
}
}

- 尾插法
每个新结点都以尾结点的身份插入,尾结点时刻变化。
插入之前要确认尾结点。从头找太慢,所以可以增加尾指针,指示尾结点位置。
first头指针只能在开头!不能动。
没有必要在刚开始的时候就把尾指针的指针域置空,因为在停止插入前,尾结点时刻变化。
template <class T>
LinkList<T>:: LinkList(T a[], int n) {//若要通过构造函数重载两次分别写头插和尾插,此处可以(T a[], int n,int k)来区分头插与尾插。
first=new Node<T>; //生成头结点 ,一定要写在 Node<T> *r=first,*s=NULL;前面!!!
Node<T> *r=first,*s=NULL; //r是尾指针,记录没有被插之前的地址;因为是尾插,所以s->next为空
for (int i=0; i<n; i++) {
s=new Node<T>; //①定义之后要申请内存
s->data=a[i]; //②为每个数组元素建立一个结点
r->next=s; r=s; //③插入到终端结点之后。r的下一个数是s。此处=s,不是s->next,因为s是尾插。把s赋给r之后,r就在s的位置了(修改尾指针)
}
r->next=NULL; //④单链表建立完毕,将终端结点的指针域置空
}

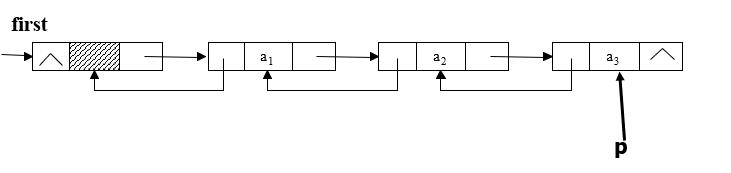
2).不带头结点的单链表的构造
考虑第一个节点与其他结点的插入是否相同。
- 头插法 每个结点插入过程相同
{
first=NULL; //把first赋空
for(int i=0;i<n;i++) {
s=new Node<T>;
s->data=a[i];
s->next=first;
first=s;
}
}
尾插法
插入的第一个结点为头、尾结点且为首元结点。
Node<T> *r;
head=NULL;
if(n<=0) return;
s=new Node<T>;
s->data=a[0];
s->next=head;
head=s;
r=head;
for(int i=1;i<n;i++) {
s=new Node<T>;
s->data=a[i];
r->next=s;
r=s;
}
- 带头结点和不带头结点的单链表

3).单链表的遍历
从首元结点出发开始遍历,首元结点地址:p=first->next。*p是结构体,p是Node类型,若想cout<<*p则要重载运算符,但是cout<<(*p).data对。
template <class T>
LinkList<T>:: PrintList()
{
Node<T> *p;
p=first->next; //工作指针p初始化
while(p) //p不为空时
{
cout<<p->data;
p=p->next; //后移,不能写作p++
}
}
4).单链表中按位置查找
顺序存储支持随机访问,而单链表不支持。因为内存不一定连续,所以只能从头结点开始顺序查找。
template <class T>
T LinkList<T>::Get(int i) {
Node<T> *p; int j;
p=first->next; j=1; //或p=first; j=0;工作指针初始化,计数器初始化
while (p && j<i) {
p=p->next; //工作指针p后移
j++;
}
if (!p) throw "位置"; //若p为空,则第j个元素不存在,抛出位置异常
else return p->data;
}
4).单链表插入
template <class T>
void LinkList<T>::Insert(int i, T x){
Node<T> *p; int j;
p=first ; j=0; //工作指针p初始化,计数器初始化
while (p && j<i-1) { //查找第i-1个节点,并使工作指针p指向该节点
p=p->next; //工作指针p后移
j++;
}
if (!p) throw "位置"; //若查找不成功(P==NULL),说明位置错误,抛出位置异常
else {
Node<T> *s;
s=new Node<T>;
s->data=x; //向内存申请一个结点s,其数据域为x(生成一个元素值为x的新节点s)
s->next=p->next; //将结点s插入到结点p之后
p->next=s;
}
}
- 不带头结点的单链表中插入结点
Insert(int i, T x){
Node<T> *p; int j;
if(i<=0) throw “位置非法”;
if (i==1 ){ s=new Node<T>;s->next=head;head=s;return}
p=first ; j=1; //工作指针p初始化
while (p && j<i-1){
p=p->next; //工作指针p后移
j++;
}
if (!p) throw "位置";
else {
Node<T> *s;
s=new Node<T>;
s->data=x; //向内存申请一个结点s,其数据域为x
s->next=p->next; //将结点s插入到结点p之后
p->next=s;
}
}
5).单链表中结点的删除(删除编号是i的结点)

template <class T>
T LinkList<T>::Delete(int i){
Node<T> *p; int j;
p=first ; j=0; //工作指针p初始化,累加器j清零(注意工作指针p要指向头结点)
while (p && j<i-1) { //查找第i-1个结点,并使p指向该节点
p=p->next;
j++;
}
if (!p || !p->next) throw "位置"; //结点p不存在或结点p的后继结点不存在,抛出异常
else {
Node<T> *q; T x;
q=p->next; x=q->data; //暂存被删结点和被删元素值
p->next=q->next; //摘链,将结点p的后继结点从链表上摘下
delete q; //释放被删结点
return x; //返回被删元素
}
}

6).析构函数
template <class T>
LinkList<T>:: ~LinkList()
{
Node<T> *q; //first:要处理的第一个结点的地址;q:first的后继
while (first)
{
q=first->next;
delete first;
first=q;
}
}
四、顺序表和单链表的比较
1.时间性能比较
若线性表的操作主要是进行查找,很少做插入和删除时,宜采用顺序表做存储结构;
对频繁进行插入和删除的线性表,宜采用链表做存储结构。
2.空间性能比较
当线性表的长度变化不大,易于事先确定其大小时,为了节约存储空间,宜采用顺序表。
五、线性表的其他存储方法
1.循环列表
将单链表或者双链表的头尾结点链接起来。特点:
①首尾相接的链表
②可以从任一节点出发,访问链表中的所有结点。
③判断循链表中尾结点的特点:q->next==first
1).循环链表的定义
template <class T>
struct Node
{
T data;
Node<T> *next;
};
template <class T>
class CycleLinkList{
public:
CycleLinkList( );
CycleLinkList(T a[], int n);
CycleLinkList(T a[], int n,int i);
~CycleLinkList();
int Length();
T Get(int i);
void Insert(int i, T x);
T Delete(int i);
void PrintList();
private:
Node<T> *first;
};
带头结点的循环链表:
2).空表的构造
template <class T>
CycleLinkList<T>:: CycleLinkList( )
{
first=new Node<T>; first->next=first;
}
尾插法构造循环链表
template <class T>
CycleLinkList<T>:: CycleLinkList(T a[ ], int n) {
first=new Node<T>; //生成头结点
Node<T> *r,*s;
r=first; //尾指针初始化
for (int i=0; i<n; i++) {
s=new Node<T>;
s->data=a[i];
r->next=s;
r=s;
}
r->next=first; //单链表建立完毕,将终端结点的指针域指向头结点
}
头插法构造循环链表
template <class T>
CycleLinkList<T>:: CycleLinkList(T a[ ], int n,int k)
{
first=new Node<T>; //生成头结点
first->next=first;
Node<T> *s;
for (int i=1; i<n; i++)
{
s=new Node<T>;
s->data=a[i]; //为每个数组元素建立一个结点
s->next=first->next;//先修改s的指针域(s的后继为first)
first->next=s; //(first的后继为s)
}
}
将非循环的单链表改造成循环的单链表
p=first;
while(p->next)
{
p=p->next;
}
p->next=first
3).非空表的构造
4).循环链表的遍历
不能轻易修改头指针,所以设置工作结点p,p->first指向头结点。首元结点是头结点的后继,p=first->next。而且只有p非空才可以count<<p ->data(但在循环列表中,p不为空)。后移:p=p->next。
5). 按位置查找结点
6).循环链表的析构
2.双向列表(双链表)
给单链表增加一个指向前驱的指针。
first:头指针
last:尾指针
每一个结点都是new来的,头结点的rlink和llink都为空。first(是DNode类型变量,自己始终占四个字节内存)有两个指针域,修改所指向的内存。


设指针p指向双链表中某一结点,则p->llink->rlink = p = p->rlink->llink
1).双向链表p之后插入结点(p存在后继结点)
把一个结点插入到两条单链表,插入顺序不唯一,但一定要正确插入到两条链里面。

q->rlink=p->rlink; //p原来的下一个结点变为现在q的下一个结点(q的rlink要记录的地址是p的rlin)
q->llink=p; //q前一个结点是p
p->rlink=q; //p的下一个结点是q
q->rlink->llink=q; //b的前一个结点是q
处理原则:先处理每个方向的远端指针,再处理近端指针

q->rlink=p->rlink; //p原来的下一个结点变为现在q的下一个结点
p->rlink=q; //p的下一个结点是q
q->llink=p; //q的前一个结点是p
q->rlink->llink=q //b的前一个结点是q
处理原则:先在正向链表上插入,再在逆向链表上插入
- 插入时应考虑的特殊情况
若在空表的表尾插入一个结点:

q->rlink=p->rlink;
p->rlink=q;
q->llink=p;
if(q->rlink)
q->rlink->llink=q;
头插:Append(T data)
template <class T>
void DoubleLink<T>::Append(T data){
Node<T> *s;
s=new Node<T>;
s->data=data;
s->rlink=head->rlink;
head->rlink=s;
s->llink=head;
if (s->rlink)
s->rlink->llink=s;
return;
}
2).双向链表的删除操作
要同时修改两个指针,同时在两个链表中删除(可先正向删,再反向删)。但若是c不存在,则修改一个(前驱)即可。
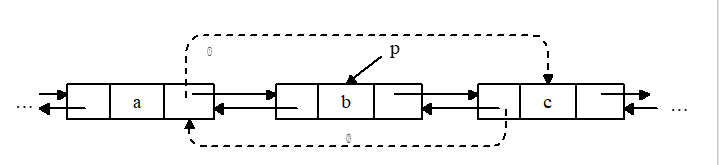
p->llink->rlink=p->rlink;
p->rlink->llink=p->llink;
delete(p);
- 删除造作应考虑的特殊情况
p->llink->rlink=p->rlink;
if(p->rlink)
p->rlink->llink=p->rlink;
delete(p);
3).双向链表的实现
template <class T>
class DoubleLink {
private:
Node<T> *head;
public:
DoubleLink() ;
~DoubleLink();
void Append(T data);
void Display();
void Insert(int locate , T data);
T Get(int locate);
T Delete(int locate);
};
4).双向链表的构造
template <class T>
DoubleLink <T>::DoubleLink(){
head=new Node<T>;
head->rlink=NULL;
head->llink=NULL;
}
5).析构
template <class T>
DoubleLink<T>::~DoubleLink(){
Node<T> *p,*q;
p=head;
while(p)
{
q=p->rlink;
delete p;
p=q;
}
}
6).遍历
template <class T>
void DoubleLink<T>::Display(){
Node <T> *p;
p=head->rlink;
while(p) {
cout<<p->data<<" ";
p=p->rlink;
}
cout<<endl;
return;
}
练习:
远端:距离表尾远
近端:距离表尾近
注意正向链和反向链的表尾不同。

A.①若一开始就修改p->rlink(近端),则p原来的后继就找不到了。所以要先修改远端再修改近端。
B.①修改逆向链近端 √
②若此时修改正向链近端,p原来的后继就找不到了
C.①修改逆向链远端 √
②修改正向链远端 √
③修改正向链近端 √
④修改逆向链近端 X,表示错了
D.√
3.静态列表
六、线性表的应用举例















 3538
3538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









